本教程介绍了如何使用在 Compute Engine 上运行的 NVIDIA TensorRT5 GPU 对大规模工作负载运行深度学习推理。
在开始之前,需要了解以下基本内容:
- 深度学习推理是机器学习过程中的一个阶段,该阶段使用经过训练的模型来识别、处理和分类结果。
- NVIDIA TensorRT 是一个经过优化的平台,用于运行深度学习工作负载。
- GPU 用于加快数据密集型工作负载(如机器学习和数据处理)的运行速度。Compute Engine 上提供多种 NVIDIA GPU。本教程使用 T4 GPU,因为 T4 GPU 是专为深度学习推理工作负载设计的。
目标
本教程包含以下过程:
- 使用预先训练的图表准备模型。
- 使用不同的优化模式来测试模型的推理速度。
- 将自定义模型转换为 TensorRT。
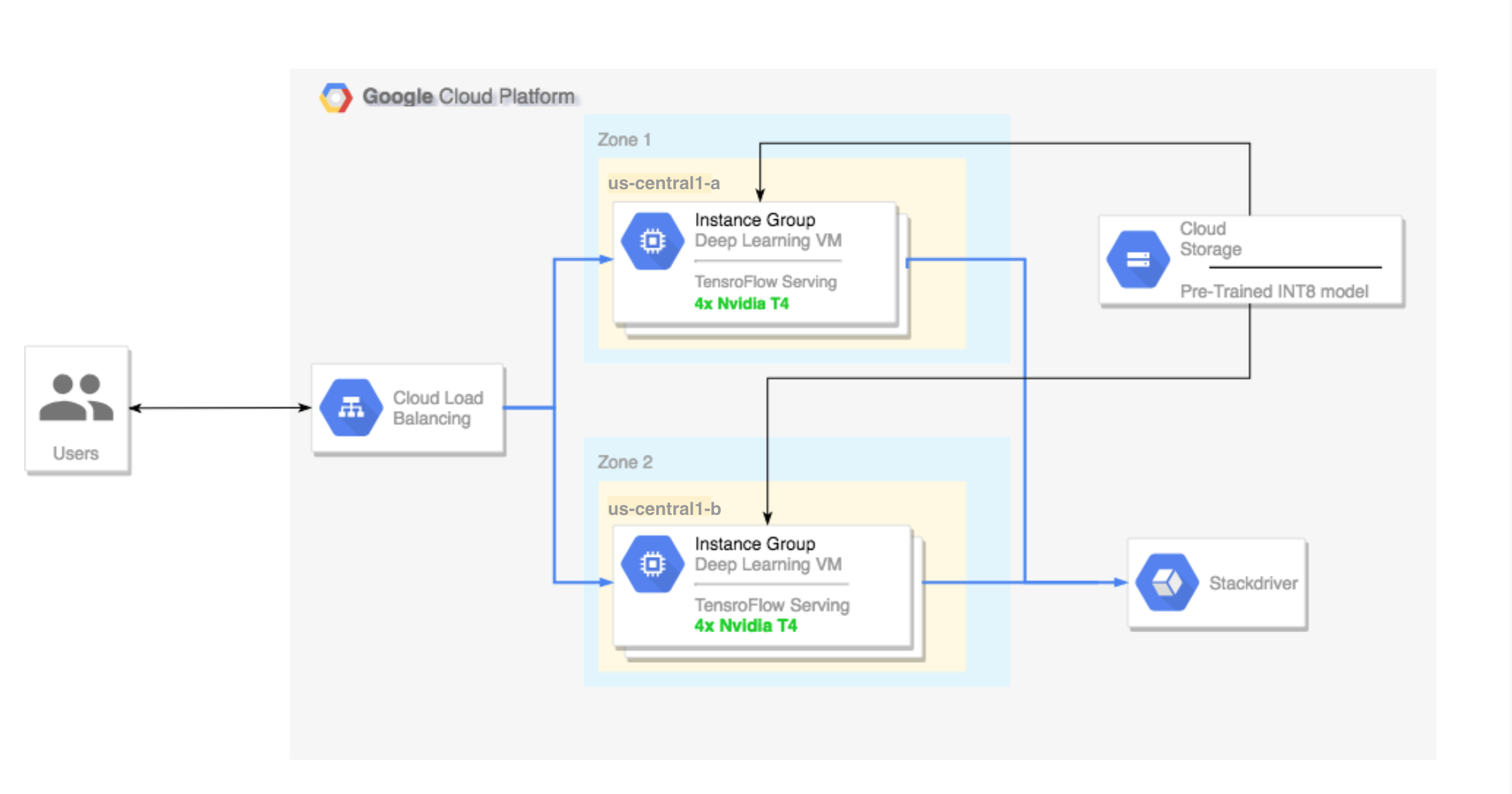
- 设置一个多地区集群,其配置如下:
- 以 Deep Learning VM Image 为基础构建而成。这些映像预安装了 TensorFlow、TensorFlow Serving 和 TensorRT5。
- 启用了自动扩缩功能。本教程中的自动扩缩功能基于 GPU 利用率。
- 启用了负载平衡。
- 启用了防火墙。
- 在多地区集群中运行推理工作负载。
费用
按照本教程操作的费用因教程部分而异。
您可以使用价格计算器计算费用。
如需估算准备模型并以不同的优化速度测试推理速度的费用,请使用以下规范:
- 1 个虚拟机实例:
n1-standard-8(vCPU:8 个,RAM 30GB) - 1 个 NVIDIA T4 GPU
如需估算设置多可用区集群的费用,请使用以下规范:
- 2 个虚拟机实例:
n1-standard-16(16 个 vCPU,60 GB RAM) - 每个虚拟机实例有 4 个 GPU NVIDIA T4
- 每个虚拟机实例有 100 GB SSD
- 1 条转发规则
准备工作
项目设置
- 登录您的 Google Cloud 账号。如果您是 Google Cloud 新手,请创建一个账号来评估我们的产品在实际场景中的表现。新客户还可获享 $300 赠金,用于运行、测试和部署工作负载。
-
在 Google Cloud Console 中的项目选择器页面上,选择或创建一个 Google Cloud 项目。
-
启用 Compute Engine and Cloud Machine Learning API。
-
在 Google Cloud Console 中的项目选择器页面上,选择或创建一个 Google Cloud 项目。
-
启用 Compute Engine and Cloud Machine Learning API。
工具设置
如需在本教程中使用 Google Cloud CLI,请执行以下操作:
- 安装或更新到 Google Cloud CLI 的最新版本。
- (可选)设置默认区域和地区。
准备模型
本部分介绍了如何创建用于运行模型的虚拟机 (VM) 实例,此外还介绍了如何从 TensorFlow 官方模型目录下载模型。
创建虚拟机实例。 本教程是使用
tf-ent-2-10-cu113创建的。如需了解最新的映像版本,请参阅 Deep Learning VM Image 文档中的选择操作系统。export IMAGE_FAMILY="tf-ent-2-10-cu113" export ZONE="us-central1-b" export INSTANCE_NAME="model-prep" gcloud compute instances create $INSTANCE_NAME \ --zone=$ZONE \ --image-family=$IMAGE_FAMILY \ --machine-type=n1-standard-8 \ --image-project=deeplearning-platform-release \ --maintenance-policy=TERMINATE \ --accelerator="type=nvidia-tesla-t4,count=1" \ --metadata="install-nvidia-driver=True"
选择模型。本教程使用 ResNet 模型。此 ResNet 模型根据 TensorFlow 中的 ImageNet 数据集进行训练。
要将 ResNet 模型下载到虚拟机实例,请运行以下命令:
wget -q http://download.tensorflow.org/models/official/resnetv2_imagenet_frozen_graph.pb
将 ResNet 模型的位置保存在
$WORKDIR变量中。 将MODEL_LOCATION替换为包含所下载模型的工作目录。export WORKDIR=MODEL_LOCATION
运行推理速度测试
本部分包括以下过程:
- 设置 ResNet 模型。
- 以不同的优化模式运行推理测试。
- 查看推理测试的结果。
测试过程概述
TensorRT 可以提高推理工作负载的执行速度,但量化过程的提升最为显著。
模型量化是您用来降低模型权重精确率的过程。例如,如果模型的初始权重是 FP32,您可以将精确率降低到 FP16、INT8 甚至是 INT4。在模型的速度(权重精确率)与准确率之间正确取舍权衡非常重要。幸运的是,TensorFlow 包含的功能就能实现这样的权衡,可测量准确性与速度,或测量其他指标,如吞吐量、延迟时间、节点转换率和总训练时间。
过程
设置 ResNet 模型。如需设置模型,请运行以下命令:
git clone https://github.com/tensorflow/models.git cd models git checkout f0e10716160cd048618ccdd4b6e18336223a172f touch research/__init__.py touch research/tensorrt/__init__.py cp research/tensorrt/labellist.json . cp research/tensorrt/image.jpg ..
运行测试。此命令需要一些时间才能完成。
python -m research.tensorrt.tensorrt \ --frozen_graph=$WORKDIR/resnetv2_imagenet_frozen_graph.pb \ --image_file=$WORKDIR/image.jpg \ --native --fp32 --fp16 --int8 \ --output_dir=$WORKDIR
其中:
$WORKDIR是下载 ResNet 模型的目录。--native参数是要测试的不同量化模式。
查看结果。测试完成后,您可以比较每种优化模式的推理结果。
Predictions: Precision: native [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus'] Precision: FP32 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: FP16 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: INT8 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus', u'lakeside, lakeshore']
如需查看完整结果,请运行以下命令:
cat $WORKDIR/log.txt
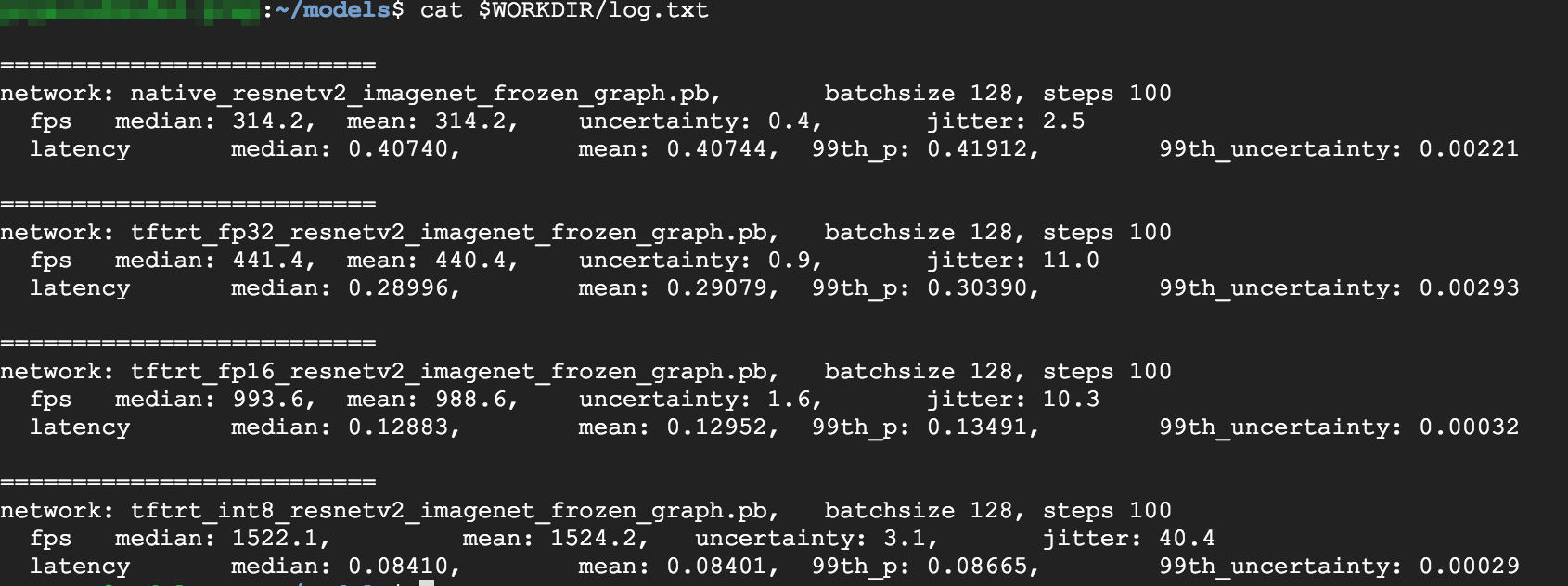
从结果中,您可以看到 FP32 和 FP16 是相同的。这表示如果您能够熟练运用 TensorRT,便可以立即开始使用 FP16。INT8 显示的结果稍微逊色。
此外,您还可以看到使用 TensorRT5 运行模型会显示以下结果:
- 使用 FP32 优化可将吞吐量提高 40%:从 314 fps 提高到 440 fps。同时,延迟时间缩短约 30%,从 0.40 毫秒变成 0.28 毫秒。
- 使用 FP16 优化而非原生 TensorFlow 图,可将速度提升 214%:从 314 fps 提升到 988 fps。同时,延迟时间缩短至 0.12 毫秒,几乎降低至四分之一。
- 使用 INT8,您可以观察到速度提升 385%(从 314 fps 提升到 1524 fps),而延迟时间缩短为 0.08 毫秒。
将自定义模型转换为 TensorRT
您可以使用 INT8 模型进行此转换。
下载模型。如需将自定义模型转换为 TensorRT 图,您需要一个已保存的模型。若要获取已保存的 INT8 ResNet 模型,请运行以下命令:
wget http://download.tensorflow.org/models/official/20181001_resnet/savedmodels/resnet_v2_fp32_savedmodel_NCHW.tar.gz tar -xzvf resnet_v2_fp32_savedmodel_NCHW.tar.gz
使用 TFTools 将模型转换为 TensorRT 图。如需使用 TFTools 转换模型,请运行以下命令:
git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/dlvm/tools python ./convert_to_rt.py \ --input_model_dir=$WORKDIR/resnet_v2_fp32_savedmodel_NCHW/1538687196 \ --output_model_dir=$WORKDIR/resnet_v2_int8_NCHW/00001 \ --batch_size=128 \ --precision_mode="INT8"
现在,
$WORKDIR/resnet_v2_int8_NCHW/00001目录中有一个 INT8 模型。为了确保一切设置都正确,请尝试运行推理测试。
tensorflow_model_server --model_base_path=$WORKDIR/resnet_v2_int8_NCHW/ --rest_api_port=8888
将模型上传到 Cloud Storage。必须执行此步骤,模型才能用在下一部分设置的多地区集群中。如需上传模型,请完成以下步骤:
归档模型。
tar -zcvf model.tar.gz ./resnet_v2_int8_NCHW/
上传归档。 将
GCS_PATH替换为 Cloud Storage 存储桶的路径。export GCS_PATH=GCS_PATH gsutil cp model.tar.gz $GCS_PATH
如果需要,您可以通过以下网址从 Cloud Storage 获取 INT8 冻结图:
gs://cloud-samples-data/dlvm/t4/model.tar.gz
设置一个多地区集群
创建集群
现在,您已在 Cloud Storage 平台上创建了一个模型,可以创建一个集群了。
创建实例模板。实例模板是用于创建新实例的资源。请参阅实例模板。 将
YOUR_PROJECT_NAME替换为您的项目 ID。export INSTANCE_TEMPLATE_NAME="tf-inference-template" export IMAGE_FAMILY="tf-ent-2-10-cu113" export PROJECT_NAME=YOUR_PROJECT_NAME gcloud beta compute --project=$PROJECT_NAME instance-templates create $INSTANCE_TEMPLATE_NAME \ --machine-type=n1-standard-16 \ --maintenance-policy=TERMINATE \ --accelerator=type=nvidia-tesla-t4,count=4 \ --min-cpu-platform=Intel\ Skylake \ --tags=http-server,https-server \ --image-family=$IMAGE_FAMILY \ --image-project=deeplearning-platform-release \ --boot-disk-size=100GB \ --boot-disk-type=pd-ssd \ --boot-disk-device-name=$INSTANCE_TEMPLATE_NAME \ --metadata startup-script-url=gs://cloud-samples-data/dlvm/t4/start_agent_and_inf_server_4.sh- 此实例模板包含由元数据参数指定的启动脚本。
- 对使用此模板的每个实例进行创建时,运行此启动脚本。
- 此启动脚本会执行以下步骤:
- 安装监控代理,以监控实例上的 GPU 使用情况。
- 下载模型。
- 启动推理服务。
- 在启动脚本中,
tf_serve.py包含推理逻辑。此示例包含一个基于 TFServe 软件包创建的非常小的 Python 文件。 - 要查看启动脚本,请参阅 startup_inf_script.sh。
- 此实例模板包含由元数据参数指定的启动脚本。
创建一个托管实例组 (MIG)。必须有此托管实例组才能在特定地区中设置多个运行中实例。这些实例是根据上一步生成的实例模板创建的。
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export INSTANCE_TEMPLATE_NAME="tf-inference-template" gcloud compute instance-groups managed create $INSTANCE_GROUP_NAME \ --template $INSTANCE_TEMPLATE_NAME \ --base-instance-name deeplearning-instances \ --size 2 \ --zones us-central1-a,us-central1-b
确认 Google Cloud Monitoring 页面上有一些指标。
在 Google Cloud Console 中,转到 Monitoring 页面。
如果导航窗格中显示 Metrics Explorer,请点击 Metrics Explorer。否则,请选择 Resources,然后选择 Metrics Explorer。
搜索
gpu_utilization。
如果有数据进入,您应该会看到如下内容:
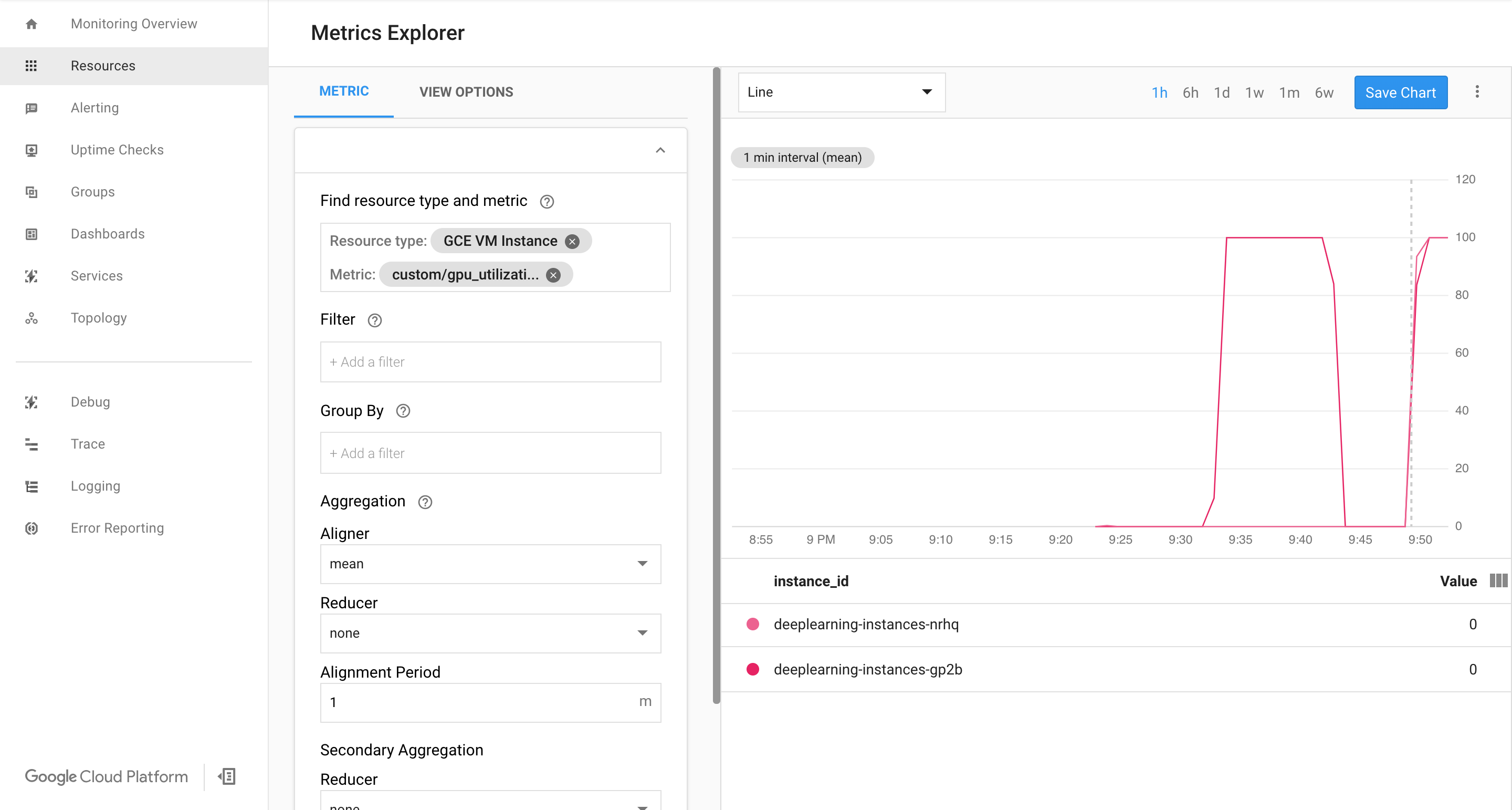


启用自动扩缩功能
为托管实例组启用自动扩缩功能。
export INSTANCE_GROUP_NAME="deeplearning-instance-group" gcloud compute instance-groups managed set-autoscaling $INSTANCE_GROUP_NAME \ --custom-metric-utilization metric=custom.googleapis.com/gpu_utilization,utilization-target-type=GAUGE,utilization-target=85 \ --max-num-replicas 4 \ --cool-down-period 360 \ --region us-central1
custom.googleapis.com/gpu_utilization是指标的完整路径。该示例指定级别 85,这意味着只要 GPU 利用率达到 85,平台就会在我们的组中创建一个新实例。测试自动扩缩功能。要测试自动扩缩功能,您需要执行以下步骤:
- 通过 SSH 连接到实例。请参阅连接到实例。
使用
gpu-burn工具向 GPU 添加负载,让 GPU 利用率达到 100% 并保持 600 秒:git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/third_party/gpu-burn git checkout c0b072aa09c360c17a065368294159a6cef59ddf make ./gpu_burn 600 > /dev/null &
查看 Cloud Monitoring 页面。观察自动扩缩功能。集群通过添加另一个实例来纵向扩容。
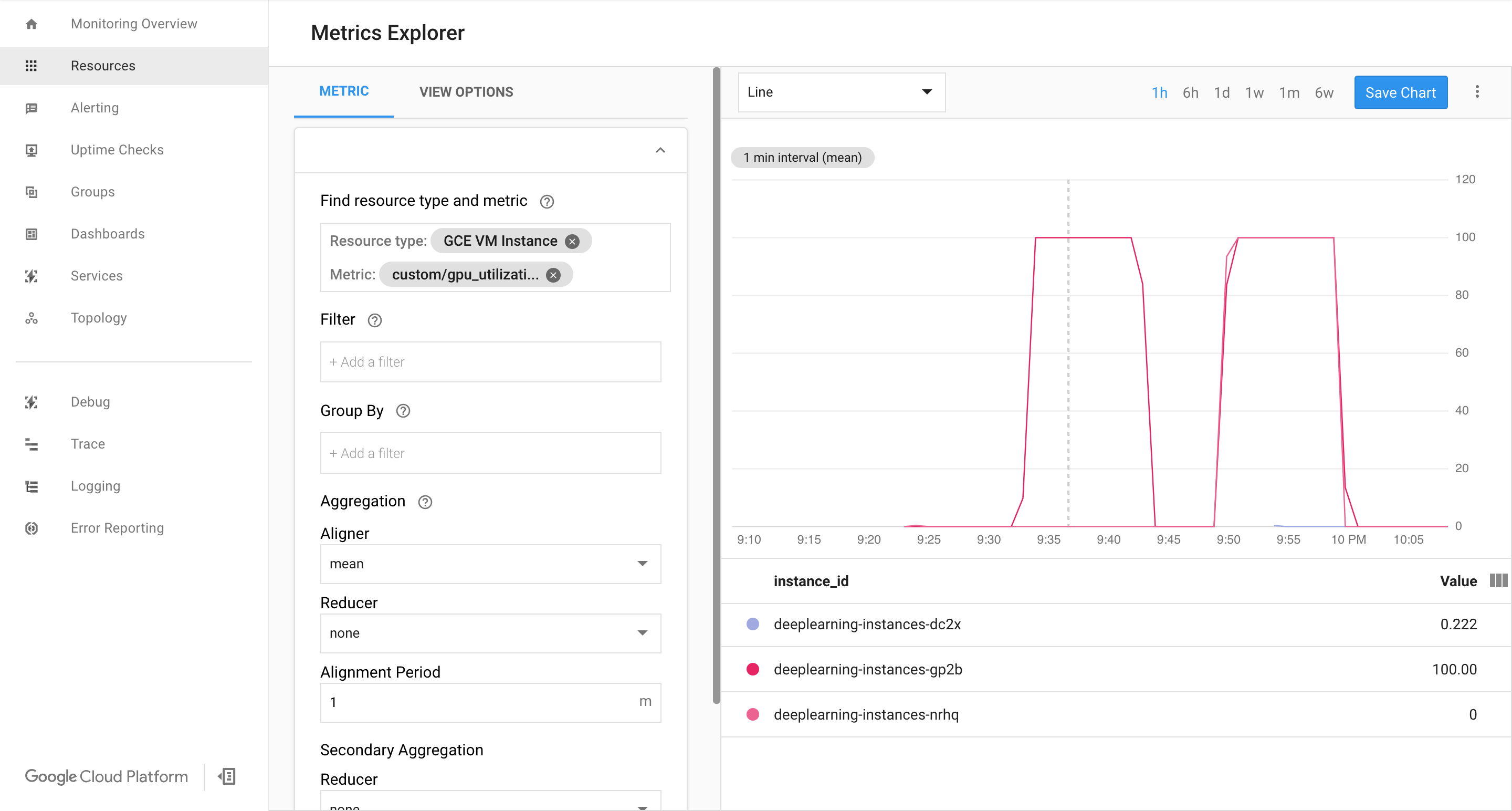
在 Google Cloud Console 中,转到实例组页面。
点击
deeplearning-instance-group管理的实例组。点击监控标签。
此时,您的自动扩缩逻辑应该会尝试启动尽可能多的实例以减少负载,但运气不佳:
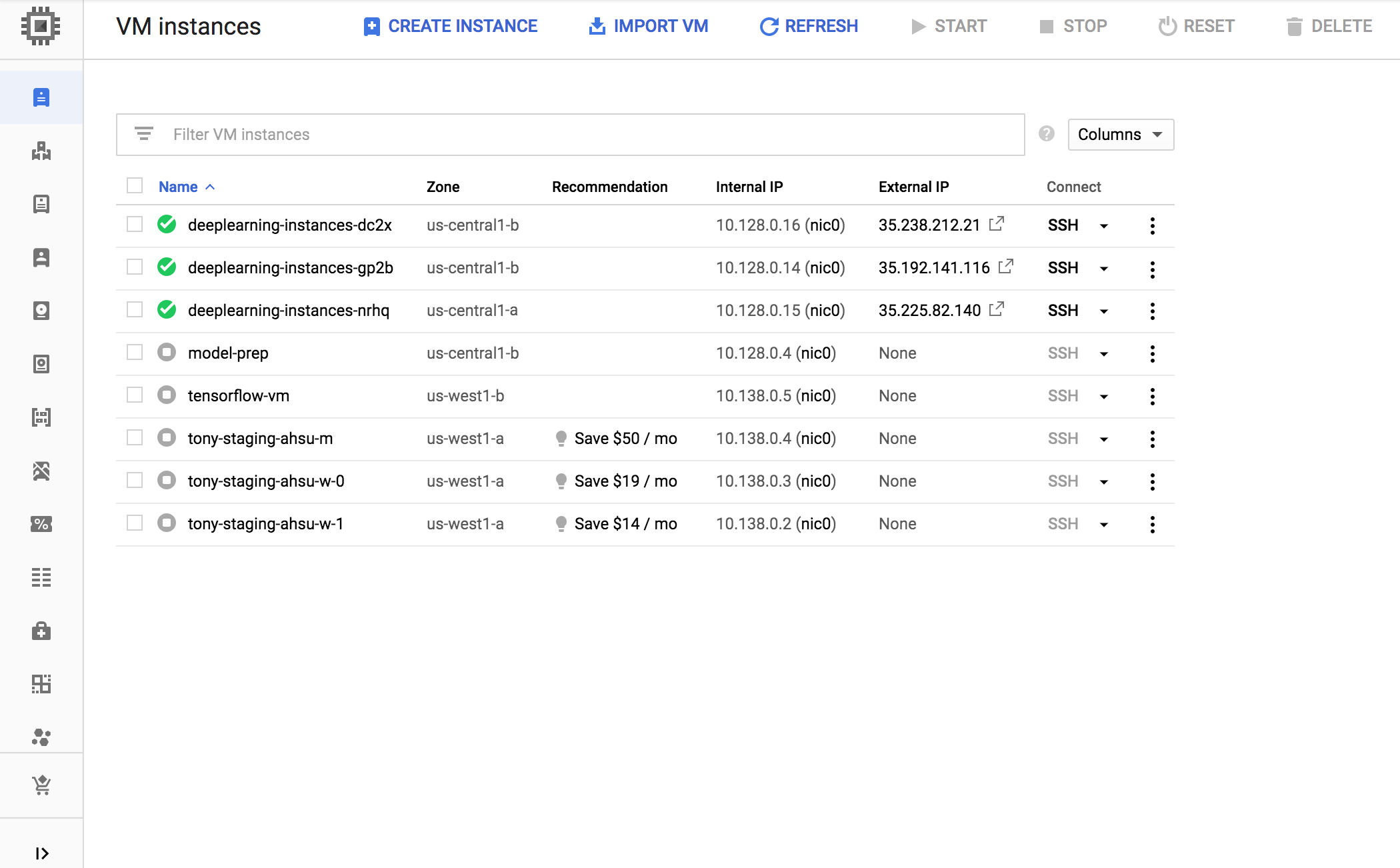
此时,您可以停止对实例进行满负载测试,并观察系统如何缩减。
设置负载平衡器
回顾一下,到目前为止您拥有:
- 一个经过训练的模型,已使用 TensorRT5 (INT8) 进行优化
- 一组托管实例。这些实例已根据 GPU 利用率启用自动扩缩
现在,您可以创建在实例前的负载平衡器。
创建健康检查。健康检查用于确定后端的特定主机是否可以处理流量。
export HEALTH_CHECK_NAME="http-basic-check" gcloud compute health-checks create http $HEALTH_CHECK_NAME \ --request-path /v1/models/default \ --port 8888
创建包含实例组和健康检查的后端服务。
创建健康检查。
export HEALTH_CHECK_NAME="http-basic-check" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services create $WEB_BACKED_SERVICE_NAME \ --protocol HTTP \ --health-checks $HEALTH_CHECK_NAME \ --global
将实例组添加到新的后端服务。
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services add-backend $WEB_BACKED_SERVICE_NAME \ --balancing-mode UTILIZATION \ --max-utilization 0.8 \ --capacity-scaler 1 \ --instance-group $INSTANCE_GROUP_NAME \ --instance-group-region us-central1 \ --global
设置转发网址。负载平衡器需要知道哪个网址可以转发到后端服务。
export WEB_BACKED_SERVICE_NAME="tensorflow-backend" export WEB_MAP_NAME="map-all" gcloud compute url-maps create $WEB_MAP_NAME \ --default-service $WEB_BACKED_SERVICE_NAME
创建负载平衡器。
export WEB_MAP_NAME="map-all" export LB_NAME="tf-lb" gcloud compute target-http-proxies create $LB_NAME \ --url-map $WEB_MAP_NAME
将外部 IP 地址添加到负载均衡器。
export IP4_NAME="lb-ip4" gcloud compute addresses create $IP4_NAME \ --ip-version=IPV4 \ --network-tier=PREMIUM \ --global
找到分配的 IP 地址。
gcloud compute addresses list
设置转发规则,告知 Google Cloud 将所有请求从公共 IP 地址转发到负载均衡器。
export IP=$(gcloud compute addresses list | grep ${IP4_NAME} | awk '{print $2}') export LB_NAME="tf-lb" export FORWARDING_RULE="lb-fwd-rule" gcloud compute forwarding-rules create $FORWARDING_RULE \ --address $IP \ --global \ --load-balancing-scheme=EXTERNAL \ --network-tier=PREMIUM \ --target-http-proxy $LB_NAME \ --ports 80创建全局转发规则后,可能需要几分钟来传播配置。
启用防火墙
检查您是否设有允许从外部源连接到虚拟机实例的防火墙规则。
gcloud compute firewall-rules list
如果您没有允许这些连接的防火墙规则,则必须予以创建。如需创建防火墙规则,请运行以下命令:
gcloud compute firewall-rules create www-firewall-80 \ --target-tags http-server --allow tcp:80 gcloud compute firewall-rules create www-firewall-8888 \ --target-tags http-server --allow tcp:8888
运行推理
您可以使用以下 Python 脚本将图片转换为可以上传到服务器的格式。
from PIL import Image import numpy as np import json import codecs
img = Image.open("image.jpg").resize((240, 240)) img_array=np.array(img) result = { "instances":[img_array.tolist()] } file_path="/tmp/out.json" print(json.dump(result, codecs.open(file_path, 'w', encoding='utf-8'), separators=(',', ':'), sort_keys=True, indent=4))运行推理。
curl -X POST $IP/v1/models/default:predict -d @/tmp/out.json
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
删除转发规则。
gcloud compute forwarding-rules delete $FORWARDING_RULE --global
删除 IPV4 地址。
gcloud compute addresses delete $IP4_NAME --global
删除负载平衡器。
gcloud compute target-http-proxies delete $LB_NAME
删除转发网址。
gcloud compute url-maps delete $WEB_MAP_NAME
删除后端服务。
gcloud compute backend-services delete $WEB_BACKED_SERVICE_NAME --global
删除健康检查。
gcloud compute health-checks delete $HEALTH_CHECK_NAME
删除托管实例组。
gcloud compute instance-groups managed delete $INSTANCE_GROUP_NAME --region us-central1
删除实例模板。
gcloud beta compute --project=$PROJECT_NAME instance-templates delete $INSTANCE_TEMPLATE_NAME
删除防火墙规则。
gcloud compute firewall-rules delete www-firewall-80
gcloud compute firewall-rules delete www-firewall-8888