In diesem Dokument wird beschrieben, wie Sie eine verwaltete Instanzgruppe (MIG, Managed Instance Group) anhand der Bereitstellungskapazität eines externen Application Load Balancers oder eines internen Application Load Balancers skalieren. Dies bedeutet, dass das Autoscaling VM-Instanzen in der Gruppe hinzufügt oder entfernt, wenn der Load-Balancer angibt, dass die Gruppe einen konfigurierbaren Teil ihrer Fülle erreicht hat. Fülle wird dabei durch die Zielkapazität des ausgewählten Balancing-Modus der Backend-Instanzgruppe definiert.
Sie können eine MIG auch anhand ihrer CPU-Auslastung oder anhand von Monitoringmesswerten skalieren.
Beschränkungen
Sie können eine verwaltete Instanzgruppe automatisch anhand der Bereitstellungskapazität eines externen Application Load Balancers und eines internen Application Load Balancers skalieren. Andere Arten von Load-Balancern werden nicht unterstützt.
Hinweise
- Prüfen Sie die Einschränkungen für Autoscaling.
- Grundlagen von Autoscaling
-
Richten Sie die Authentifizierung ein, falls Sie dies noch nicht getan haben.
Bei der Authentifizierung wird Ihre Identität für den Zugriff auf Google Cloud-Dienste und APIs überprüft.
Zur Ausführung von Code oder Beispielen aus einer lokalen Entwicklungsumgebung können Sie sich so bei Compute Engine authentifizieren.
Wählen Sie den Tab für die Verwendung der Beispiele auf dieser Seite aus:
Console
Wenn Sie über die Google Cloud Console auf Google Cloud-Dienste und -APIs zugreifen, müssen Sie die Authentifizierung nicht einrichten.
gcloud
-
Installieren Sie die Google Cloud CLI und initialisieren Sie sie mit folgendem Befehl:
gcloud init
- Legen Sie eine Standardregion und -zone fest.
REST
Verwenden Sie die von der gcloud CLI bereitgestellten Anmeldedaten, um die REST API-Beispiele auf dieser Seite in einer lokalen Entwicklungsumgebung zu verwenden.
Installieren Sie die Google Cloud CLI und initialisieren Sie sie mit folgendem Befehl:
gcloud init
-
Anhand der HTTP(S)-Load-Balancing-Kapazität skalieren
Compute Engine unterstützt den Lastenausgleich innerhalb der Instanzgruppen. Sie können das Autoscaling zusammen mit dem Load-Balancing verwenden. Dazu richten Sie es so ein, dass es anhand der Last der Instanzen erfolgt.
Ein externer oder interner HTTP(S)-Load-Balancer verteilt Anfragen gemäß seiner URL-Zuordnung an Backend-Dienste. Der Load-Balancer kann einen oder mehrere Backend-Dienste haben, die jeweils Instanzgruppen- oder NEG-Backends (Network Endpoint Group) unterstützen. Wenn Back-Ends Instanzgruppen sind, bietet der HTTP(S)-Load-Balancer zwei Balancing-Modi: UTILIZATION und RATE. Mit UTILIZATION können Sie ein maximales Ziel für die durchschnittliche Backend-Auslastung von Instanzen in der Instanzgruppe angeben. Mit RATE müssen Sie eine Zielanzahl von Anfragen pro Sekunde pro Instanz oder pro Gruppe angeben. (Nur zonale Instanzgruppen unterstützen die Angabe einer maximalen Rate für die gesamte Gruppe. Regional verwaltete Instanzgruppen bieten keine Unterstützung für die Definition einer maximalen Rate pro Gruppe.)
Der von Ihnen angegebene Balancing-Modus und die Zielkapazität definieren die Bedingungen, unter denen Google Cloud bestimmt, wann eine Back-End-VM voll ausgelastet ist. Google Cloud versucht, Traffic an fehlerfrei arbeitende VMs mit freier Kapazität zu senden. Sind alle VMs bereits ausgelastet, wird die Zielauslastung oder -rate überschritten.
Wenn Sie dem Instanzgruppen-Backend eines HTTP(S)-Load-Balancers ein Autoscaling zuweisen, wird die verwaltete Instanzgruppe so skaliert, dass ein Teil der Load-Balancing-Bereitstellungskapazität erhalten bleibt.
Angenommen, die Load-Balancing-Bereitstellungskapazität einer verwalteten Instanzgruppe ist als 100 Anfragen pro Sekunde pro Instanz definiert. Wenn Sie ein Autoscaling mit der HTTP(S)-Load-Balancing-Richtlinie erstellen und dafür ein Zielauslastungsniveau von 0,8 oder 80 % festlegen, werden der verwalteten Instanzgruppe Instanzen hinzugefügt oder daraus entfernt, um eine Bereitstellungskapazität von 80 % oder 80 RPS pro Instanz aufrechtzuerhalten.
Das folgende Diagramm zeigt, wie das Autoscaling mit einer verwalteten Instanzgruppe und einem Back-End-Dienst interagiert:
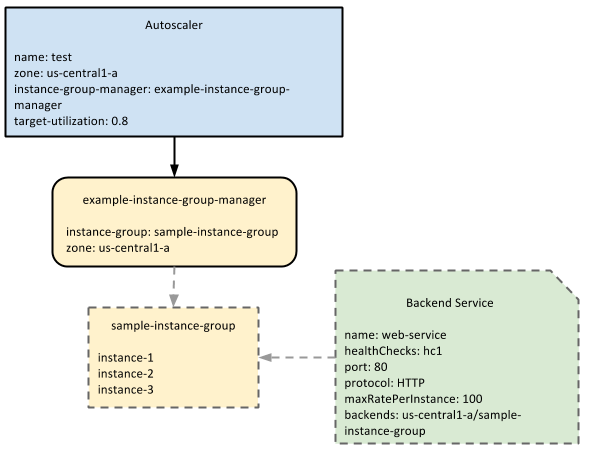
maxRatePerInstance gemessen.
Anwendbare Load-Balancing-Konfigurationen
Sie können für die Load-Balancing-Bereitstellungskapazität eine von drei Optionen festlegen. Beim erstmaligen Erstellen des Back-Ends haben Sie die Wahl zwischen der maximalen Back-End-Auslastung, der maximalen Anzahl von Anfragen pro Sekunde und Instanz sowie der maximalen Anzahl von Anfragen pro Sekunde für die gesamte Gruppe. Das Autoscaling kann nur mit der maximalen Back-End-Auslastung und der maximalen Anzahl von Anfragen pro Sekunde und Instanz verwendet werden, weil der Wert dieser Einstellungen durch Hinzufügen oder Entfernen von Instanzen gesteuert werden kann. Wenn Sie beispielsweise festlegen, dass ein Back-End 10 Anfragen pro Sekunde und Instanz verarbeitet, und wenn das Autoscaling so konfiguriert ist, dass 80 % dieser Rate aufrechterhalten werden, dann werden vom Autoscaling unter Umständen Instanzen hinzugefügt oder entfernt, wenn sich die Anzahl der Anfragen pro Sekunde und Instanz ändert.
Das Autoscaling kann nicht mit der maximalen Anzahl von Anfragen pro Gruppe verwendet werden, weil diese Einstellung von der Anzahl der Instanzen in der Instanzgruppe unabhängig ist. Der Load-Balancer sendet fortlaufend die maximale Anzahl von Anfragen pro Gruppe an die Instanzgruppe – unabhängig von der Anzahl der Instanzen in der Gruppe.
Wenn Sie beispielsweise festlegen, dass das Back-End maximal 100 Anfragen pro Gruppe und Sekunde verarbeiten soll, sendet der Load-Balancer weiter 100 Anfragen pro Sekunde an die Gruppe, unabhängig davon, ob die Gruppe 2 oder 100 Instanzen enthält. Da dieser Wert nicht angepasst werden kann, funktioniert das Autoscaling nicht mit einer Load-Balancing-Konfiguration, die auf der maximalen Anzahl von Anfragen pro Sekunde und Gruppe beruht.
Autoscaling anhand der Load-Balancing-Bereitstellungskapazität aktivieren
Console
- Öffnen Sie in der Google Cloud Console die Seite Instanzgruppen.
- Wenn Sie eine Instanzgruppe haben, wählen Sie sie aus und klicken Sie auf Bearbeiten. Wenn Sie keine Instanzgruppe haben, klicken Sie auf Instanzgruppe erstellen.
- Wählen Sie unter Autoscaling-Modus die Option Ein: Der Gruppe Instanzen hinzufügen und daraus entfernen aus, um Autoscaling zu aktivieren.
- Geben Sie die minimale und maximale Anzahl von Instanzen an, die das Autoscaling in dieser Gruppe erstellen soll.
- Klicken Sie unter Messwerte für Autoscaling auf Messwert hinzufügen.
- Setzen Sie den Messwerttyp auf HTTP-Load-Balancing-Auslastung.
Geben Sie die HTTP-Load-Balancing-Zielauslastung ein. Dieser Wert wird als Prozentsatz behandelt. Bei einer HTTP-Load-Balancing-Auslastung von beispielsweise 60 % geben Sie den Wert
60ein.Sie können die Wartezeit verwenden, um den Initialisierungszeitraum festzulegen, der dem Autoscaling mitteilt, wie lange Ihre Anwendung zur Initialisierung benötigt. Wenn Sie einen genauen Initialisierungszeitraum angeben, verbessern Sie die Autoscaling-Entscheidungen. Beim horizontalen Skalieren werden so beispielsweise Daten von VMs ignoriert, die noch initialisiert werden, da diese möglicherweise nicht die normale Nutzung Ihrer Anwendung darstellen. Die Standardinitialisierungszeit beträgt 60 Sekunden.
Speichern Sie die Änderungen.
gcloud
Mit dem Unterbefehl set-autoscaling aktivieren Sie das Autoscaling zum Skalieren der Bereitstellungskapazität. Durch den folgenden Befehl wird z. B. ein Autoscaling erstellt, das die verwaltete Zielinstanzgruppe so skaliert, dass 60 % der Bereitstellungskapazität aufrechterhalten werden. Neben dem Parameter --target-load-balancing-utilization ist beim Erstellen eines Autoscalings auch der Parameter --max-num-replicas erforderlich:
gcloud compute instance-groups managed set-autoscaling example-managed-instance-group \
--max-num-replicas 20 \
--target-load-balancing-utilization 0.6 \
--cool-down-period 90
Sie können das Flag --cool-down-period verwenden, um den Initialisierungszeitraum festzulegen, der dem Autoscaling mitteilt, wie lange Ihre Anwendung zur Initialisierung benötigt. Wenn Sie die Initialisierungsphase genau definieren, verbessern Sie die Autoscaling-Entscheidungen. Beim horizontalen Skalieren werden so beispielsweise Daten von VMs ignoriert, die noch initialisiert werden, da diese möglicherweise nicht die normale Nutzung Ihrer Anwendung darstellen. Die Standardinitialisierungszeit beträgt 60 Sekunden.
Mit dem Unterbefehl instance-groups managed describe können Sie prüfen, ob das Autoscaling erfolgreich erstellt wurde:
gcloud compute instance-groups managed describe example-managed-instance-group
Eine Liste der verfügbaren gcloud-Befehle und Flags finden Sie in der Referenz zu gcloud.
REST
Verwenden Sie zum Erstellen eines Autoscalings die Methode autoscalers.insert für eine zonale MIG oder die Methode regionAutoscalers.insert für eine regionale MIG.
Im folgenden Beispiel wird ein Autoscaling für eine zonale MIG erstellt:
POST https://compute.googleapis.com/compute/v1/projects/PROJECT_ID/zones/ZONE/autoscalers/
Der Text Ihrer Anfrage muss die Felder name, target und autoscalingPolicy enthalten. loadBalancingUtilization muss durch autoscalingPolicy definiert sein.
Sie können das Feld coolDownPeriodSec verwenden, um den Initialisierungszeitraum festzulegen, der dem Autoscaling mitteilt, wie lange Ihre Anwendung zur Initialisierung benötigt. Wenn Sie die Initialisierungsphase genau definieren, verbessern Sie die Autoscaling-Entscheidungen. Beim horizontalen Skalieren werden so beispielsweise Daten von VMs ignoriert, die noch initialisiert werden, da diese möglicherweise nicht die normale Nutzung Ihrer Anwendung darstellen. Die Standardinitialisierungszeit beträgt 60 Sekunden.
{
"name": "example-autoscaler",
"target": "zones/us-central1-f/instanceGroupManagers/example-managed-instance-group",
"autoscalingPolicy": {
"maxNumReplicas": 20,
"loadBalancingUtilization": {
"utilizationTarget": 0.8
},
"coolDownPeriodSec": 90
}
}
Weitere Informationen zum Aktivieren des Autoscalings auf Grundlage der Load-Balancing-Bereitstellungskapazität finden Sie in der Anleitung Globales Autoscaling eines Webdienstes mithilfe von Compute Engine.
Nächste Schritte
- Autoscalings verwalten
- Mehr über die Faktoren des Autoscalings erfahren
- Mehr über das Skalieren von Gruppen mit mehreren Autoscaling-Signalen erfahren