Cloud Composer 1 | Cloud Composer 2
本教程介绍如何使用 Cloud Composer 创建在 Dataproc 集群上运行 Apache Hadoop Wordcount 作业的 Apache Airflow DAG(有向无环图)。
目标
- 访问您的 Cloud Composer 环境并使用 Airflow 界面。
- 创建和查看 Airflow 环境变量。
- 创建和运行包含以下任务的 DAG:
- 创建 Dataproc 集群。
- 在集群上运行 Apache Hadoop 字数统计作业。
- 将字数统计结果输出到 Cloud Storage 存储桶。
- 删除集群。
费用
在本文档中,您将使用 Google Cloud 的以下收费组件:
- Cloud Composer
- Dataproc
- Cloud Storage
您可使用价格计算器根据您的预计使用情况来估算费用。
准备工作
确保您的项目中启用了以下 API:
控制台
启用 Dataproc, Cloud Storage API。
gcloud
Enable the Dataproc, Cloud Storage APIs:
gcloud services enable dataproc.googleapis.com
storage-component.googleapis.com 在您的项目中,为任何存储类别和区域创建 Cloud Storage 存储桶,用于存储 Hadoop 字数统计作业的结果。
记下您创建的存储桶的路径,例如
gs://example-bucket。在本教程后面部分,您将为此路径定义 Airflow 变量,并在示例 DAG 中使用该变量。使用默认参数创建 Cloud Composer 环境。等待环境创建操作完成。完成后,相应环境名称左侧将显示绿色对勾标记。
记下您创建了环境的区域,例如
us-central。您将为此区域定义一个 Airflow 变量,并在示例 DAG 中使用该变量在同一区域中运行 Dataproc 集群。
设置 Airflow 变量
设置 Airflow 变量,以便稍后在示例 DAG 中使用。例如,您可以在 Airflow 界面中设置 Airflow 变量。
| Airflow 变量 | 值 |
|---|---|
gcp_project
|
您在本教程中使用的项目的项目 ID,例如 example-project。 |
gcs_bucket
|
您为本教程创建的 URI Cloud Storage 存储桶,例如 gs://example-bucket |
gce_region
|
您在其中创建了环境的区域,例如 us-central1。这是将创建 Dataproc 集群的区域。 |
查看示例工作流程
Airflow DAG 是您要安排和运行的有序任务的集合。DAG 在标准 Python 文件中定义。hadoop_tutorial.py 中显示的代码是工作流代码。
Airflow 2
Airflow 1
运算符
为了编排示例工作流中的三项任务,DAG 导入以下三个 Airflow 运算符:
DataprocClusterCreateOperator:用于创建 Dataproc 集群。DataProcHadoopOperator:提交 Hadoop Wordcount 作业并将结果写入 Cloud Storage 存储桶。DataprocClusterDeleteOperator:删除集群,以避免持续产生 Compute Engine 费用。
依赖项
您可以反映任务之间的关系和依赖关系来组织要运行的任务。此 DAG 中的任务会按顺序运行。
Airflow 2
Airflow 1
调度
此 DAG 的名称为 composer_hadoop_tutorial,此 DAG 每天运行一次。由于传入 default_dag_args 的 start_date 设置为 yesterday,因此 Cloud Composer 会安排工作流在 DAG 上传到环境存储桶后立即启动。
Airflow 2
Airflow 1
将该 DAG 上传到环境的存储桶
Cloud Composer 将 DAG 存储在环境存储桶的 /dags 文件夹中。
如需上传 DAG,请执行以下操作:
在本地机器上,保存
hadoop_tutorial.py。在 Google Cloud 控制台中,前往环境页面。
在环境列表的 DAGs 文件夹列中,点击环境对应的 DAGs 链接。
点击上传文件。
在本地机器上选择
hadoop_tutorial.py,然后点击打开。
Cloud Composer 会将此 DAG 添加到 Airflow,并自动安排此 DAG。DAG 会在 3 到 5 分钟内发生更改。
探索 DAG 运行作业
查看任务状态
当您将 DAG 文件上传到 Cloud Storage 中的 dags/ 文件夹时,Cloud Composer 会解析该文件。成功完成后,工作流的名称会显示在 DAG 列表中,并且工作流会加入队列以立即运行。
如需查看任务状态,请转到 Airflow 网页界面并点击工具栏中的 DAGs。

如需打开 DAG 详情页面,请点击
composer_hadoop_tutorial。此页面包含工作流任务和依赖项的图形表示。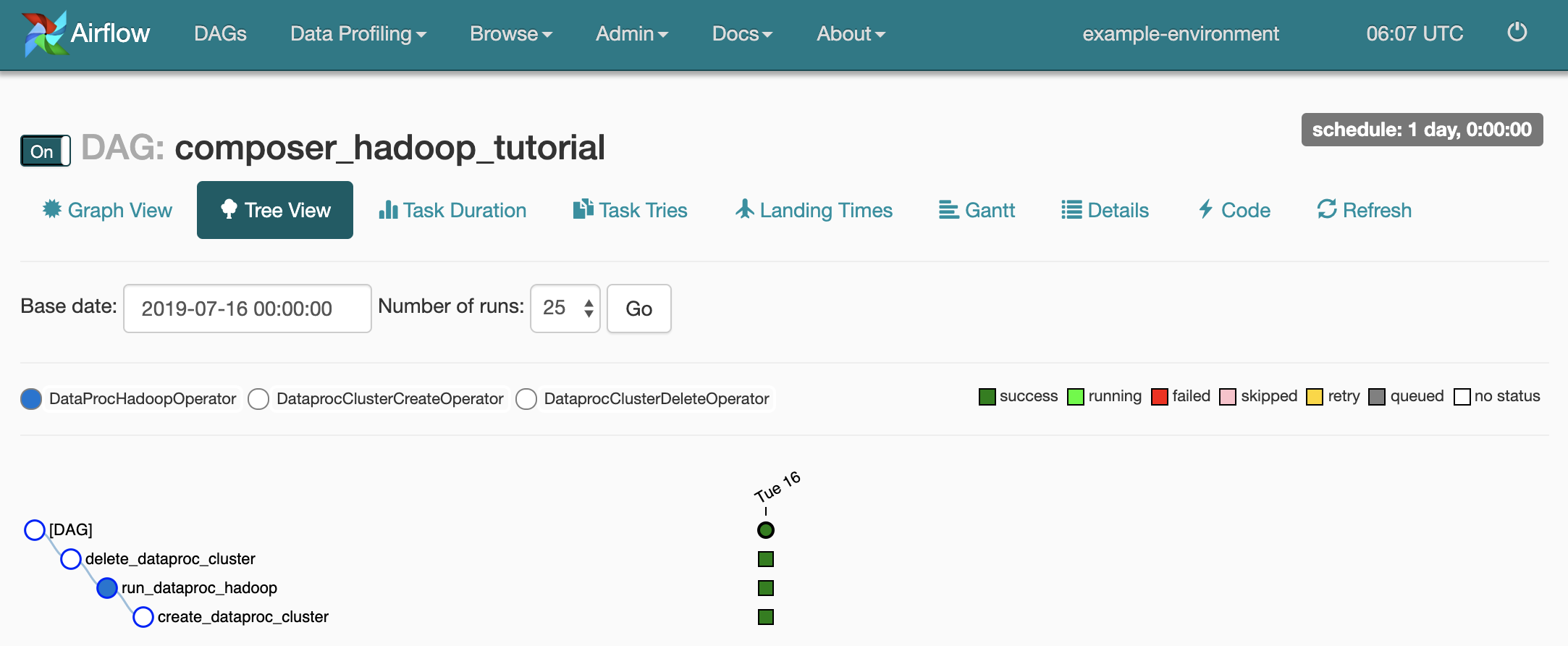
如需查看每个任务的状态,请点击 Graph View,然后将鼠标悬停在每个任务对应的图形上。
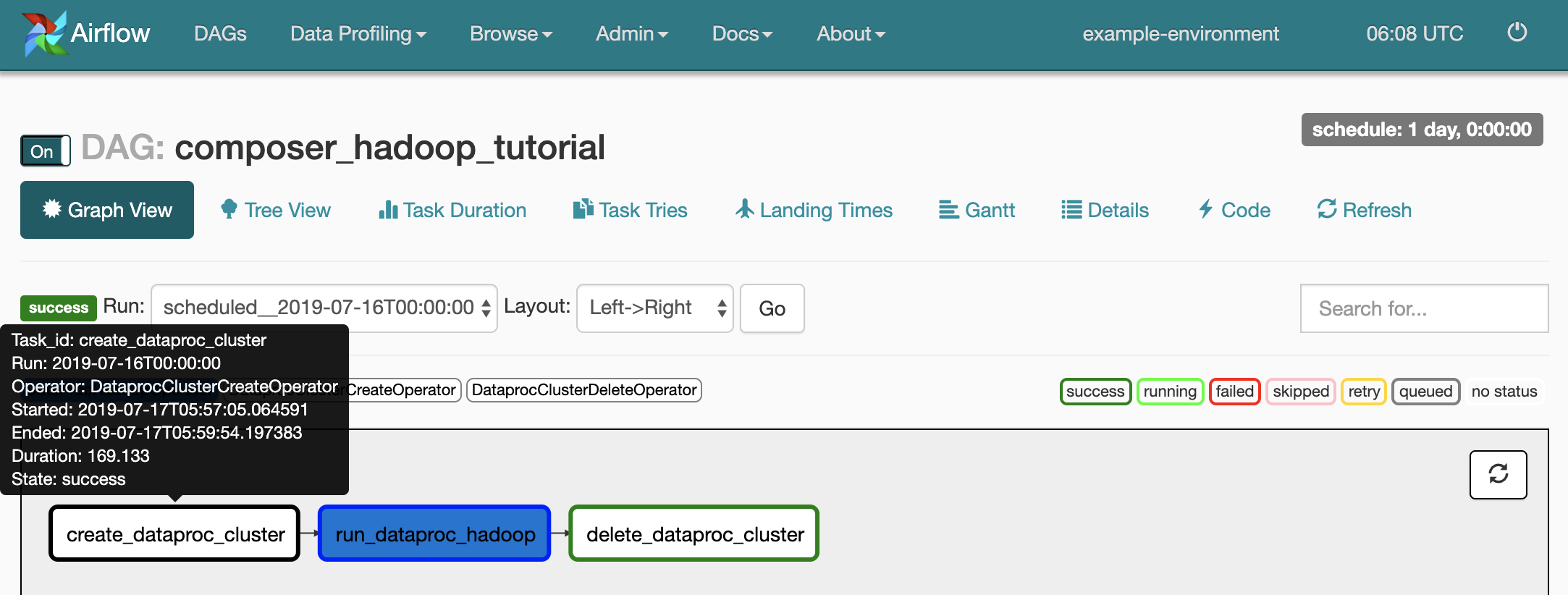
再次将工作流加入队列
如需从 Graph View 重新运行工作流,请执行以下操作:
- 在 Airflow 界面的“Graph View”中,点击
create_dataproc_cluster图形。 - 如需重置三个任务,请点击 Clear,然后点击 OK 进行确认。
- 在“Graph View”中,再次点击
create_dataproc_cluster。 - 如需将工作流重新加入队列,请点击 Run。
查看任务结果
您还可以转到以下 Google Cloud 控制台页面,查看 composer_hadoop_tutorial 工作流的状态和结果:
Dataproc 集群:用于监控集群的创建和删除。请注意,由工作流创建的集群是临时的:该集群仅在工作流期间存在,并会在最后一个工作流任务中被删除。
Dataproc 作业:查看或监控 Apache Hadoop wordcount 作业。点击作业 ID 以查看作业日志输出。
Cloud Storage 浏览器:可在您为本教程创建的 Cloud Storage 存储桶的
wordcount文件夹中查看 Wordcount 的结果。
清理
删除本教程中使用的资源:
删除 Cloud Composer 环境,包括手动删除该环境的存储桶。
删除 Cloud Storage 存储桶(用于存储 Hadoop 字数统计作业的结果)。