Cloud Composer 1 | Cloud Composer 2
En este instructivo, se muestra cómo usar Cloud Composer para crear un DAG (grafo acíclico dirigido) de Apache Airflow que ejecute un trabajo de conteo de palabras de Apache Hadoop en un clúster de Dataproc.
Objetivos
- Accede a tu entorno de Cloud Composer y usa la IU de Airflow.
- Crear y ver variables de entorno de Airflow
- Crea y ejecuta un DAG que incluya las siguientes tareas:
- Crear un clúster de Dataproc
- Ejecuta un trabajo de recuento de palabras de Apache Hadoop en el clúster.
- Envía los resultados del recuento de palabras a un bucket de Cloud Storage.
- Borra el clúster.
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
- Cloud Composer
- Dataproc
- Cloud Storage
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Antes de comenzar
Asegúrate de que las siguientes APIs estén habilitadas en tu proyecto:
Console
Habilita las API de Dataproc, Cloud Storage.
gcloud
Habilita las APIs de Dataproc, Cloud Storage:
gcloud services enable dataproc.googleapis.com
storage-component.googleapis.com En tu proyecto, crea un bucket de Cloud Storage de cualquier clase de almacenamiento y región para almacenar los resultados del trabajo de recuento de palabras de Hadoop.
Toma nota de la ruta del bucket que creaste, por ejemplo,
gs://example-bucket. Definirás una variable de Airflow para esta ruta de acceso y la usarás en el DAG de ejemplo más adelante en este instructivo.Crea un entorno de Cloud Composer con parámetros predeterminados. Espera hasta que se complete la creación del entorno. Cuando hayas terminado, la marca de verificación verde se mostrará a la izquierda del nombre del entorno.
Anota la región en la que creaste tu entorno, por ejemplo,
us-central. Definirás una variable de Airflow para esta región y la usarás en el DAG de ejemplo para ejecutar un clúster de Dataproc en la misma región.
Configura variables de Airflow
Configura las variables de Airflow para usarlas más adelante en el DAG de ejemplo. Por ejemplo, puedes configurar variables de Airflow en la IU de Airflow.
| Variable de Airflow | Valor |
|---|---|
gcp_project
|
El ID del proyecto que usas para este instructivo, como example-project. |
gcs_bucket
|
El URI del bucket de Cloud Storage que creaste para este instructivo, como gs://example-bucket |
gce_region
|
La región en la que creaste el entorno, como us-central1.
Esta es la región en la que se creará tu clúster de Dataproc. |
Ver el flujo de trabajo de ejemplo
Un DAG de Airflow es una colección de tareas organizadas que deseas programar y ejecutar. Los DAG se definen en archivos estándares de Python. El código que se muestra en hadoop_tutorial.py es el código del flujo de trabajo.
Airflow 2
Airflow 1
Operadores
Para organizar las tres tareas en el flujo de trabajo de ejemplo, el DAG importa los siguientes tres operadores de Airflow:
DataprocClusterCreateOperator: crea un clúster de Dataproc.DataProcHadoopOperator: Envía un trabajo de conteo de palabras de Hadoop y escribe los resultados en un bucket de Cloud Storage.DataprocClusterDeleteOperator: Borra el clúster para evitar que se generen cargos continuos de Compute Engine.
Dependencias
Las tareas que deseas ejecutar se organizan de una manera que refleje sus relaciones y dependencias. Las tareas de este DAG se ejecutan de forma secuencial.
Airflow 2
Airflow 1
Programación
El nombre del DAG es composer_hadoop_tutorial, y este se ejecuta una vez al día. Debido a que la start_date que se pasa a default_dag_args se configura como yesterday, Cloud Composer programa el flujo de trabajo para que comience inmediatamente después de que se suba el DAG al bucket del entorno.
Airflow 2
Airflow 1
Sube el DAG al bucket del entorno
Cloud Composer almacena los DAG en la carpeta /dags del bucket de tu entorno.
Sigue estos pasos para subir el DAG:
En tu máquina local, guarda
hadoop_tutorial.py.En la consola de Google Cloud, ve a la página Entornos.
En la lista de entornos, en la columna Carpeta de DAG de tu entorno, haz clic en el vínculo DAGs.
Haz clic en Subir archivos.
Selecciona
hadoop_tutorial.pyen tu máquina local y haz clic en Abrir.
Cloud Composer agrega el DAG a Airflow y lo programa de forma automática. Los cambios en el DAG tardan de 3 a 5 minutos.
Explore las ejecuciones del DAG
Ver el estado de la tarea
Cuando subes el archivo DAG a la carpeta dags/ en Cloud Storage, Cloud Composer analiza el archivo. Cuando se completa correctamente, el nombre del flujo de trabajo aparece en la lista del DAG y el flujo de trabajo se pone en cola para ejecutarse de inmediato.
Para ver el estado de la tarea, ve a la interfaz web de Airflow y haz clic en DAGs en la barra de herramientas.
Para abrir la página de detalles del DAG, haz clic en
composer_hadoop_tutorial. En esta página, se incluye una representación gráfica de las dependencias y tareas del flujo de trabajo.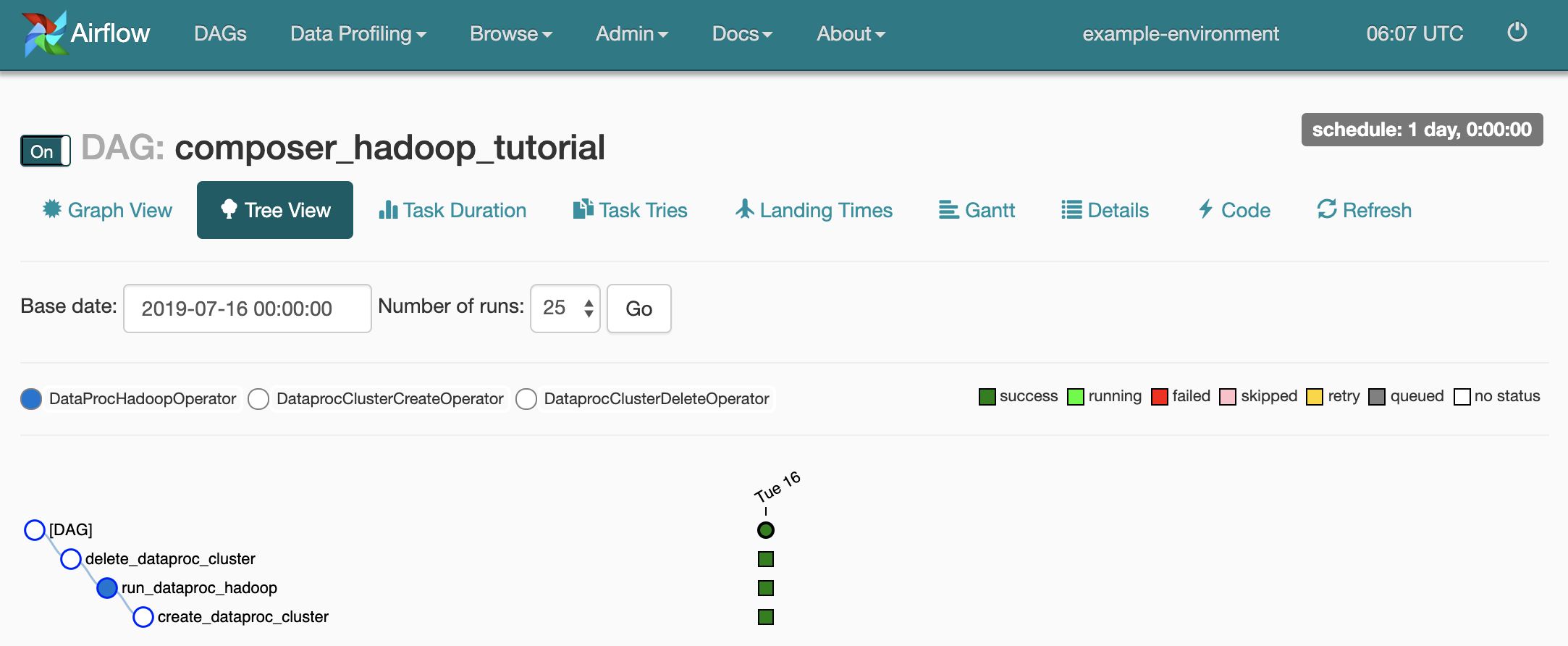
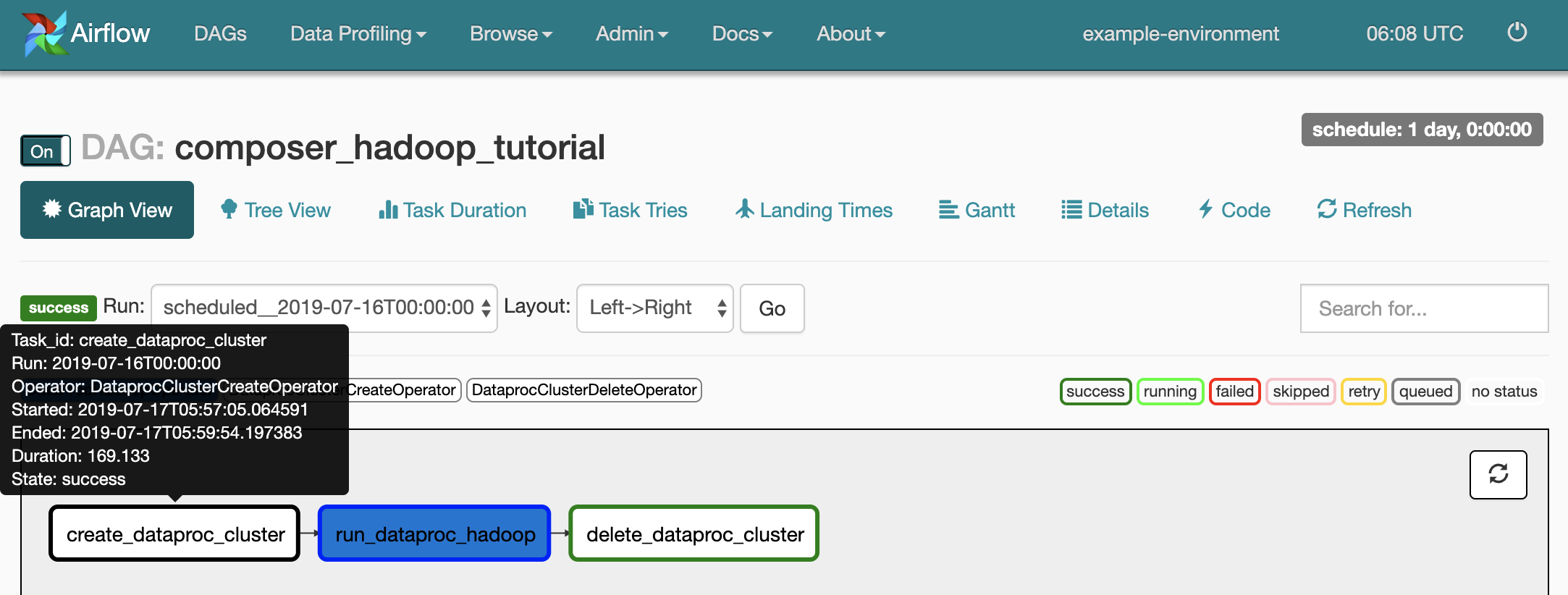
Para ver el estado de cada tarea, haz clic en Vista del gráfico (Graph View) y, luego, desplaza el mouse sobre el gráfico para ver cada tarea.
Vuelve a poner el flujo de trabajo en cola
Para volver a ejecutar el flujo de trabajo desde la Vista del gráfico (Graph View), sigue estos pasos:
- En la Vista del gráfico (Graph View) de la IU de Airflow, haz clic en el gráfico
create_dataproc_cluster. - Para restablecer las tres tareas, haz clic en Borrar (Clear) y, luego, en Aceptar para confirmar.
- Vuelve a hacer clic en
create_dataproc_clusteren la Vista del gráfico (Graph View). - Para volver a poner en cola el flujo de trabajo, haz clic en Ejecutar (Run).
Ver los resultados de la tarea
También puedes verificar el estado y los resultados del flujo de trabajo de composer_hadoop_tutorial
en las siguientes páginas de la consola de Google Cloud:
Clústeres de Dataproc: Para supervisar la creación y eliminación de clústeres. Ten en cuenta que el clúster que crea el flujo de trabajo es efímero: solo existe durante el flujo de trabajo y se borra como parte de la última tarea del flujo de trabajo.
Trabajos de Dataproc: Para ver o supervisar el trabajo de recuento de palabras de Apache Hadoop. Haz clic en el ID del trabajo para ver el resultado del registro de trabajos.
Navegador de Cloud Storage: Para ver los resultados del recuento de palabras en la carpeta
wordcountdel bucket de Cloud Storage que creaste para este instructivo.
Limpieza
Borra los recursos que se usaron en este instructivo:
Borra el entorno de Cloud Composer, lo que incluye borrar de forma manual el bucket del entorno.
Borra el bucket de Cloud Storage que almacena los resultados del trabajo de recuento de palabras de Hadoop.