Cloud Composer 1 | Cloud Composer 2
En esta página, se describe cómo usar KubernetesPodOperator para implementar Pods de Kubernetes desde Cloud Composer en el clúster de Google Kubernetes Engine que forma parte de tu entorno de Cloud Composer y garantizar que este tenga los recursos adecuados.
KubernetesPodOperator inicia los Pods de Kubernetes
en el clúster de tu entorno. En comparación, los operadores de Google Kubernetes Engine ejecutan Pods de Kubernetes en un clúster específico, que puede ser un clúster independiente que no está relacionado con tu entorno. También puedes crear y borrar clústeres
con los operadores de Google Kubernetes Engine.
KubernetesPodOperator es una buena opción si necesitas lo siguiente:
- Dependencias de Python personalizadas que no están disponibles a través del repositorio público de PyPI.
- Dependencias binarias que no están disponibles en la imagen de archivo de trabajador de Cloud Composer.
En esta página, se explica un ejemplo de DAG de Airflow que incluye las siguientes configuraciones de KubernetesPodOperator:
- Configuración mínima: establece solo los parámetros requeridos.
- Configuración de plantilla: utiliza parámetros que puedes agregar a una plantilla con Jinja.
- Configuración de variables secretas: pasa un objeto secreto de Kubernetes al pod.
Configuración de afinidad de pods: Limita los nodos disponibles para programar pods.
Configuración completa: incluye todas las configuraciones.
Antes de comenzar
- Recomendamos usar la versión más reciente de Cloud Composer. Como mínimo, esta versión debe ser compatible como parte de la política de baja y asistencia.
- Asegúrate de que tu entorno tenga recursos suficientes. Iniciar pods en un entorno con escasez de recursos puede causar errores en el trabajador y el programador de Airflow.
Configura los recursos del entorno de Cloud Composer
Cuando creas un entorno de Cloud Composer, debes especificar sus parámetros de rendimiento, incluidos los parámetros de rendimiento del clúster del entorno. Iniciar Pods de Kubernetes en el clúster del entorno puede generar competencia por los recursos del clúster, como CPU o memoria. Debido a que el programador y los trabajadores de Airflow están en el mismo clúster de GKE, los programadores y los trabajadores no funcionarán correctamente si la competencia provoca escasez de recursos.
Para evitar escasez de recursos, realiza una o más de las siguientes acciones:
- Crea un grupo de nodos (recomendado).
- Aumenta la cantidad de nodos de tu entorno
- Especifica el tipo de máquina adecuado
Crear un grupo de nodos
La forma preferida de evitar la escasez de recursos en el entorno de Cloud Composer es crear un nuevo grupo de nodos y configurar los pods de Kubernetes para que se ejecuten solo con recursos de ese grupo.
Console
En la consola de Google Cloud, ve a la página Entornos.
Haz clic en el nombre de tu entorno.
En la página Detalles del entorno, ve a la pestaña Configuración del entorno.
En la sección Recursos > Clúster de GKE, sigue el vínculo para ver los detalles del clúster.
Crea un grupo de nodos como se describe en Agrega un grupo de nodos.
gcloud
Determina el nombre del clúster de tu entorno:
gcloud composer environments describe ENVIRONMENT_NAME \ --location LOCATION \ --format="value(config.gkeCluster)"Reemplaza lo siguiente:
ENVIRONMENT_NAMEpor el nombre del entorno.LOCATIONpor la región en la que se encuentra el entorno
El resultado contiene el nombre del clúster de tu entorno. Por ejemplo, puede ser
europe-west3-example-enviro-af810e25-gke.Crea un grupo de nodos como se describe en Agrega un grupo de nodos.
Aumenta la cantidad de nodos de tu entorno
Si aumentas la cantidad de nodos de tu entorno de Cloud Composer, aumentará la capacidad de procesamiento disponible para tus trabajadores. Este aumento no proporciona recursos adicionales para las tareas que requieren más CPU o RAM de las que proporciona el tipo de máquina especificado.
Para aumentar el recuento de nodos, actualiza tu entorno.
Especifica el tipo de máquina adecuado
Durante la creación de entornos de Cloud Composer, puedes especificar un tipo de máquina. A fin de garantizar que haya recursos disponibles, especifica el tipo de máquina para el tipo de procesamiento que se produce en tu entorno de Cloud Composer.
Configuración de KubernetesPodOperator
Para continuar con este ejemplo, coloca todo el archivo kubernetes_pod_operator.py en la carpeta dags/ de tu entorno o agrega el código relevante KubernetesPodOperator a un DAG.
Las siguientes secciones explican cada configuración de KubernetesPodOperator en el ejemplo. Para obtener información sobre cada variable de configuración, consulta la referencia de Airflow.
Airflow 2
Airflow 1
Configuración mínima
Para crear un KubernetesPodOperator, solo se requieren el name del Pod, el namespace en el que se ejecutará el Pod, el image para usarlo y el task_id.
Cuando colocas el siguiente fragmento de código en un DAG, la configuración utiliza los valores predeterminados en /home/airflow/composer_kube_config. No es necesario modificar el código para que la tarea pod-ex-minimum se realice correctamente.
Airflow 2
Airflow 1
Configuración de la plantilla
Airflow admite el uso de plantillas de Jinja.
Debes declarar las variables obligatorias (task_id, name, namespace y image) con el operador. Como se muestra en el siguiente ejemplo, puedes crear plantillas de todos los demás parámetros con Jinja, incluidos cmds, arguments, env_vars y config_file.
Airflow 2
Airflow 1
Sin cambiar el DAG ni tu entorno, la tarea ex-kube-templates falla debido a dos errores. Los registros muestran que esta tarea falla porque no existe la variable adecuada (my_value). El segundo error, que puedes obtener después de corregir el primer error, muestra que la tarea falla porque core/kube_config no se encuentra en config.
Para corregir ambos errores, sigue los pasos que se detallan en este artículo.
Para configurar my_value con gcloud o la IU de Airflow:
IU de Airflow
En la IU de Airflow 2, haz lo siguiente:
Ve a la IU de Airflow.
En la barra de herramientas, selecciona Administrador > Variables.
En la página Variable de lista, haz clic en Agregar un registro nuevo.
En la página Agregar variable, ingresa la siguiente información:
- Key:
my_value - Val:
example_value
- Key:
Haz clic en Guardar.
En la IU de Airflow 1, haz lo siguiente:
Ve a la IU de Airflow.
En la barra de herramientas, selecciona Administrador > Variables.
En la página Variables, haz clic en la pestaña Crear.
En la página Variable, ingresa la siguiente información:
- Key:
my_value - Val:
example_value
- Key:
Haz clic en Guardar.
gcloud
Para Airflow 2, ingresa el siguiente comando:
gcloud composer environments run ENVIRONMENT \
--location LOCATION \
variables set -- \
my_value example_value
En Airflow 1, ingresa el siguiente comando:
gcloud composer environments run ENVIRONMENT \
--location LOCATION \
variables -- \
--set my_value example_value
Reemplaza lo siguiente:
ENVIRONMENTpor el nombre del entorno.LOCATIONpor la región en la que se encuentra el entorno
Para hacer referencia a un config_file personalizado (un archivo de configuración de Kubernetes), anula la opción de configuración kube_config de Airflow por una configuración válida de Kubernetes:
| Sección | Clave | Valor |
|---|---|---|
core |
kube_config |
/home/airflow/composer_kube_config |
Espera unos minutos a que se actualice tu entorno. Luego, vuelve a ejecutar la tarea ex-kube-templates y verifica que la tarea ex-kube-templates se complete con éxito.
Configuración de variables secretas
Un secreto de Kubernetes es un objeto que contiene datos sensibles. Puedes pasar secretos a los Pods de Kubernetes mediante KubernetesPodOperator.
Los secretos deben estar definidos en Kubernetes o el pod no se iniciará.
En este ejemplo, se muestran dos formas de usar los Secrets de Kubernetes: como una variable de entorno y como un volumen activado por el Pod.
El primer secreto, airflow-secrets, se establece en una variable de entorno de Kubernetes llamada SQL_CONN (en lugar de en una variable de entorno de Airflow o Cloud Composer).
El segundo secreto, service-account, activa service-account.json, un archivo con un token de cuenta de servicio, en /var/secrets/google.
Los secretos se ven de la siguiente forma:
Airflow 2
Airflow 1
El nombre del primer secreto de Kubernetes se define en la variable secret.
Este secreto específico se llama airflow-secrets. Se expone como una variable de entorno, según lo determina el deploy_type. La variable de entorno que establece, deploy_target, es SQL_CONN. Por último, el key del secreto que se almacena en deploy_target es sql_alchemy_conn.
El nombre del segundo secreto de Kubernetes se define en la variable secret.
Este secreto específico se llama service-account. Se expone como un volumen, según lo determina el deploy_type. La ruta de acceso del archivo que deseas activar, deploy_target, es /var/secrets/google. Por último, el key del secreto almacenado en deploy_target es service-account.json.
Esta es la configuración del operador:
Airflow 2
Airflow 1
Si no realizas ningún cambio en el DAG ni en tu entorno, la tarea ex-kube-secrets falla. Si observas los registros, la tarea falla debido a un error Pod took too long to start. Este error se produce porque Airflow no puede encontrar el secreto especificado en la configuración, secret_env.
gcloud
Para configurar el secreto con gcloud, haz lo siguiente:
Obtén información sobre tu clúster de entorno de Cloud Composer.
Ejecuta el siguiente comando:
gcloud composer environments describe ENVIRONMENT \ --location LOCATION \ --format="value(config.gkeCluster)"Reemplaza lo siguiente:
ENVIRONMENTpor el nombre del entornoLOCATIONes la región en la que se encuentra el entorno de Cloud Composer.
El resultado de este comando usa el siguiente formato:
projects/<your-project-id>/zones/<zone-of-composer-env>/clusters/<your-cluster-id>.Para obtener el ID del clúster de GKE, copia el resultado después de
/clusters/(termina en-gke).Para obtener la zona, copia el resultado después de
/zones/.
Conéctate a tu clúster de GKE con el siguiente comando:
gcloud container clusters get-credentials CLUSTER_ID \ --project PROJECT \ --zone ZONEReemplaza lo siguiente:
CLUSTER_IDpor el ID del clúster de GKEPROJECTpor el ID del proyecto de Google Cloud.ZONEpor la zona en la que se ubica tu GKE.
Crea secretos de Kubernetes
Ejecuta el siguiente comando para crear un secreto de Kubernetes que establezca el valor de
sql_alchemy_connentest_value:kubectl create secret generic airflow-secrets \ --from-literal sql_alchemy_conn=test_valueEjecuta el siguiente comando para crear un secreto de Kubernetes que establezca el valor de
service-account.jsonen una ruta local del archivo de claves de una cuenta de servicio llamadokey.json:kubectl create secret generic service-account \ --from-file service-account.json=./key.json
Después de configurar los secretos, vuelve a ejecutar la tarea
ex-kube-secretsen la IU de Airflow.Verifica que la tarea
ex-kube-secretsse realice correctamente.
Configuración de afinidad de Pods
Si configuras el parámetro affinity en el KubernetesPodOperator, puedes controlar en qué nodos se programan los pods (por ejemplo, puedes especificar un grupo de nodos en particular). En este ejemplo, el operador solo se ejecuta en grupos de nodos llamados pool-0 y pool-1. Los nodos de tu entorno de Cloud Composer 1 se encuentran en default-pool, por lo que los Pods no se ejecutan en los nodos de tu entorno.
Airflow 2
Airflow 1
Con la configuración actual de este ejemplo, la tarea falla. Si observas los registros, la tarea falla porque los grupos de nodos pool-0 y pool-1 no existen.
Para asegurarte de que los grupos de nodos de values existan, realiza cualquiera de los siguientes cambios de configuración:
Si creaste un grupo de nodos anteriormente, reemplaza
pool-0ypool-1con los nombres de tus grupos de nodos y vuelve a subir el DAG.Crea un grupo de nodos con el nombre
pool-0opool-1. Puedes crear ambos, pero la tarea necesita solo uno para tener éxito.Reemplaza
pool-0ypool-1condefault-pool, que es el grupo predeterminado que utiliza Airflow. A continuación, vuelve a subir el DAG.
Después de realizar los cambios, espera unos minutos hasta que se actualice tu entorno.
Luego, vuelve a ejecutar la tarea ex-pod-affinity y verifica que la tarea ex-pod-affinity se realice de forma correcta.
Configuración completa
En este ejemplo, se muestran todas las variables que puedes configurar en KubernetesPodOperator. No es necesario modificar el código para que la tarea ex-all-configs se realice correctamente.
Para obtener detalles sobre cada variable, consulta la referencia KubernetesPodOperator de Airflow.
Airflow 2
Airflow 1
Información sobre el proveedor de Kubernetes de CNCF
GKEStartPodOperator y KubernetesPodOperator se implementan dentro del proveedor de apache-airflow-providers-cncf-kubernetes.
Para ver las notas de la versión fallidas del proveedor de Kubernetes de CNCF, consulta el sitio web del proveedor de Kubernetes de CNCF.
Versión 6.0.0
En la versión 6.0.0 del paquete del proveedor de Kubernetes de CNCF, se usa la conexión kubernetes_default de forma predeterminada en KubernetesPodOperator.
Si especificaste una conexión personalizada en la versión 5.0.0, el operador aún la usará. Para volver a usar la conexión kubernetes_default, es posible que desees ajustar tus DAG según corresponda.
Versión 5.0.0
Esta versión presenta algunos cambios incompatibles con versiones anteriores en comparación con la versión 4.4.0. Las más importantes, que debes tener en cuenta, están relacionadas con la conexión kubernetes_default, que no se usa en la versión 5.0.0.
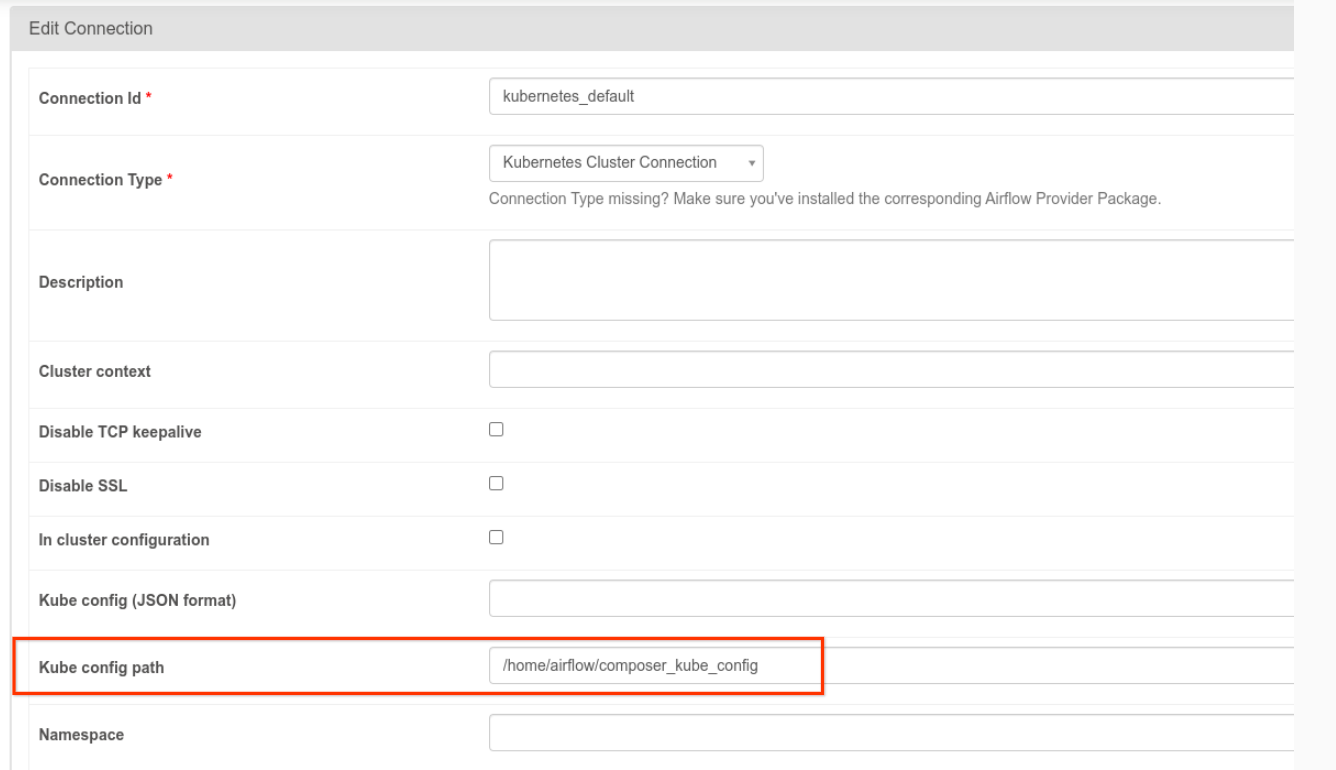
- Se debe modificar la conexión
kubernetes_default: la ruta de configuración de Kube debe configurarse como/home/airflow/composer_kube_config(consulta la Figura 1) o, como alternativa, se debe agregarconfig_filea la configuración deKubernetesPodOperator(como se presentó a continuación).
- Modifica el código de una tarea con KubernetesPodOperator de la siguiente manera:
KubernetesPodOperator(
# config_file parameter - can be skipped if connection contains this setting
config_file="/home/airflow/composer_kube_config",
# definition of connection to be used by the operator
kubernetes_conn_id='kubernetes_default',
...
)
Para obtener más información sobre la versión 5.0.0, consulta las Notas de la versión del proveedor de Kubernetes de CNCF
Soluciona problemas
Sugerencias para solucionar problemas de error de pod
Además de verificar los registros de tareas en la IU de Airflow, también verifica los siguientes registros:
El resultado del programador y los trabajadores de Airflow:
En la consola de Google Cloud, ve a la página Entornos.
Sigue el vínculo de los DAG de tu entorno.
En el bucket de tu entorno, sube un nivel.
Revisa los registros de la carpeta
logs/<DAG_NAME>/<TASK_ID>/<EXECUTION_DATE>.
Registros detallados de Pods en la consola de Google Cloud, en las cargas de trabajo de GKE. Estos registros incluyen el archivo YAML de definición de pod, los eventos de los pods y sus detalles.
Códigos de retorno distintos de cero cuando también se usa el GKEStartPodOperator
Cuando se usa KubernetesPodOperator y GKEStartPodOperator, el código de retorno del punto de entrada del contenedor determina si la tarea se considera exitosa o no. Los códigos de retorno distintos de cero indican un error.
Un patrón común cuando se utiliza KubernetesPodOperator y GKEStartPodOperator es ejecutar una secuencia de comandos de shell como punto de entrada de contenedor para agrupar varias operaciones dentro de este.
Si escribes una secuencia de comandos de este tipo, recomendamos que incluyas el comando set -e en la parte superior de la secuencia de comandos para que sus comandos con error finalicen la secuencia y propaguen el error a la instancia de tarea de Airflow.
Tiempos de espera de los pods
El tiempo de espera predeterminado de KubernetesPodOperator es de 120 segundos, lo que puede provocar que el tiempo de espera se agote antes de que se descarguen las imágenes más grandes. Para aumentar el tiempo de espera, puedes modificar el parámetro startup_timeout_seconds cuando creas el KubernetesPodOperator.
Cuando se agota el tiempo de espera de un Pod, el registro específico de la tarea está disponible en la IU de Airflow. Por ejemplo:
Executing <Task(KubernetesPodOperator): ex-all-configs> on 2018-07-23 19:06:58.133811
Running: ['bash', '-c', u'airflow run kubernetes-pod-example ex-all-configs 2018-07-23T19:06:58.133811 --job_id 726 --raw -sd DAGS_FOLDER/kubernetes_pod_operator_sample.py']
Event: pod-name-9a8e9d06 had an event of type Pending
...
...
Event: pod-name-9a8e9d06 had an event of type Pending
Traceback (most recent call last):
File "/usr/local/bin/airflow", line 27, in <module>
args.func(args)
File "/usr/local/lib/python2.7/site-packages/airflow/bin/cli.py", line 392, in run
pool=args.pool,
File "/usr/local/lib/python2.7/site-packages/airflow/utils/db.py", line 50, in wrapper
result = func(*args, **kwargs)
File "/usr/local/lib/python2.7/site-packages/airflow/models.py", line 1492, in _run_raw_task
result = task_copy.execute(context=context)
File "/usr/local/lib/python2.7/site-packages/airflow/contrib/operators/kubernetes_pod_operator.py", line 123, in execute
raise AirflowException('Pod Launching failed: {error}'.format(error=ex))
airflow.exceptions.AirflowException: Pod Launching failed: Pod took too long to start
También es posible que se agote el tiempo de espera de los pods cuando la cuenta de servicio de Composer carece de los permisos de IAM necesarios para realizar la tarea solicitada. Si deseas verificar esto, revisa los errores en el nivel del pod mediante los Paneles de GKE para ver los registros de tu carga de trabajo específica o usa Cloud Logging.
No se pudo establecer una nueva conexión
La actualización automática está habilitada de forma predeterminada en los clústeres de GKE. Si un grupo de nodos está en un clúster que se está actualizando, es posible que veas el siguiente error:
<Task(KubernetesPodOperator): gke-upgrade> Failed to establish a new
connection: [Errno 111] Connection refused
Para verificar si tu clúster se está actualizando, en la consola de Google Cloud, ve a la página Clústeres de Kubernetes y busca el ícono de carga junto al nombre del clúster de tu entorno.