Automate identity document processing with Document AI

Laurent Picard
Developer Advocate
How many times have you filled out forms requesting personal information? It's probably too many times to count. When online and signed in, you can save a lot of time thanks to your browser’s autofill feature. In other cases, you often have to provide the same data manually, again and again. The first Document AI identity processors are now generally available and can help you solve this problem.
In this post, you’ll see how to…
Process identity documents with Document AI
Create your own identity form autofiller
Use cases
Here are a few situations that you've probably encountered:
Financial accounts: Companies need to validate the identity of individuals. When creating a customer account, you need to present a government-issued ID for manual validation.
Transportation networks: To handle subscriptions, operators often manage fleets of custom identity-like cards. These cards are used for in-person validation, and they require an ID photo.
Identity gates: When crossing a border (or even when flying domestically), you need to pass an identity check. The main gates have streamlined processes and are generally well equipped to scale with the traffic. On the contrary, smaller gates along borders can have manual processes – sometimes on the way in and the way out – which can lead to long lines and delays.
Hotels: When traveling abroad and checking in, you often need to show your passport for a scan. Sometimes, you also need to fill out a longer paper form and write down the same data.
Customer benefits: For benefit certificates or loyalty cards, you generally have to provide personal info, which can include a portrait photo.
In these examples, the requested info – including the portrait photo – is already on your identity document. Moreover, an official authority has already validated it. Checking or retrieving the data directly from this source of truth would not only make processes faster and more effective, but also remove a lot of friction for end users.
Identity processors
Processor types
Each Document AI identity processor is a machine learning model trained to extract information from a standard ID document such as:
Driver license
National ID
Passport

Note: an ID can have information on both sides, so identity processors support up to two pages per document.
Availability
Generally available as of this week, you can use two US identity processors in production:

Currently available in Preview:
The Identity Doc Fraud Detector, to check whether an ID document has been tampered with
Three French identity processors
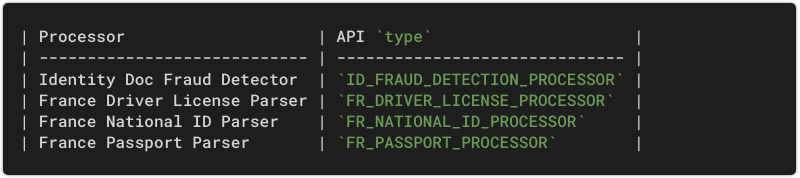
Notes:
More identity processors are in the pipe.
To request access to processors in Preview, please fill out the Access Request Form.
Processor creation
You can create a processor:
Manually from Cloud Console (web admin UI)
Programmatically with the API
Processors are location-based. This helps guarantee where processing will occur for each processor.
Here are the current multi-region locations:

Once you've created a processor, you reference it with its ID (PROCESSOR_ID hereafter).
Note: To manage processors programmatically, see the codelab Managing Document AI processors with Python.
Document processing
You can process documents in two ways:
Synchronously with an online request, to analyze a single document and directly use the results
Asynchronously with a batch request, to launch a batch processing operation on multiple or larger documents
Online requests
Example of a REST online request:
The method is named process.
The input document here is a PNG image (base64 encoded).
This request is processed in the European Union.
The response is returned synchronously.


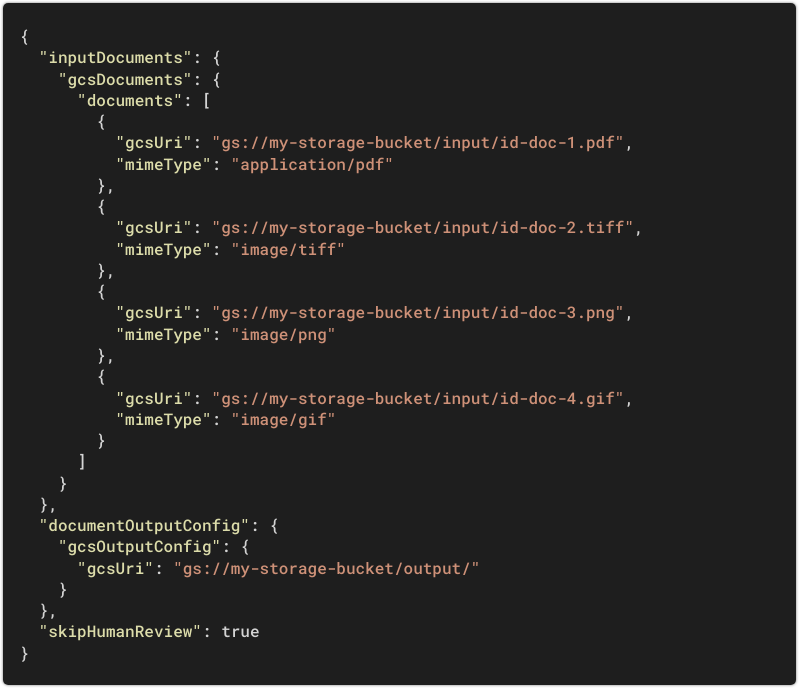
Batch requests
Example of a REST batch request:
The method is named batchProcess.
The batchProcess method launches the batch processing of multiple documents.
This request is processed in the United States.
The response is returned asynchronously; output files will be stored under
my-storage-bucket/output/.

Interfaces
Document AI is available through the usual Google Cloud interfaces:
The RPC API (low-latency gRPC)
The REST API (JSON requests and responses)
Client libraries (gRPC wrappers, currently available for Python, Node.js, and Java)
Cloud Console (web admin UI)
Note: With the client libraries, you can develop in your preferred programming language. You'll see an example later in this post.
Identity fields
A typical REST response looks like the following:
The
textandpagesfields include the OCR data detected by the underlying ML models. This part is common to all Document AI processors.The
entitieslist contains the fields specifically detected by the identity processor.
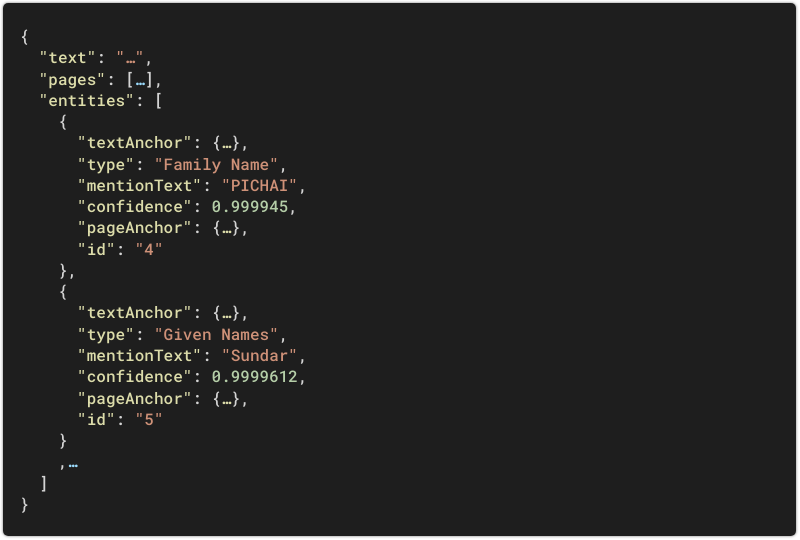
Here are the detectable identity fields:
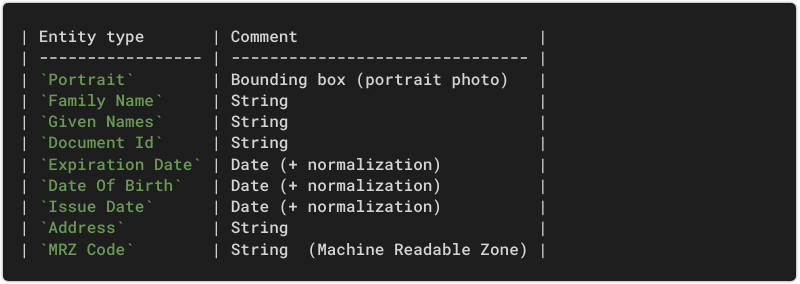
Please note that Address and MRZ Code are optional fields. For example, a US passport contains an MRZ but no address.
Fraud detection
Available in preview, the Identity Doc Fraud Detector helps detect tampering attempts. Typically, when an identity document does not "pass" the fraud detector, your automated process can block the attempt or trigger a human validation.
Here is an example of signals returned:

Sample demo
You can process a document live with just a few lines of code.
Here is a Python example:
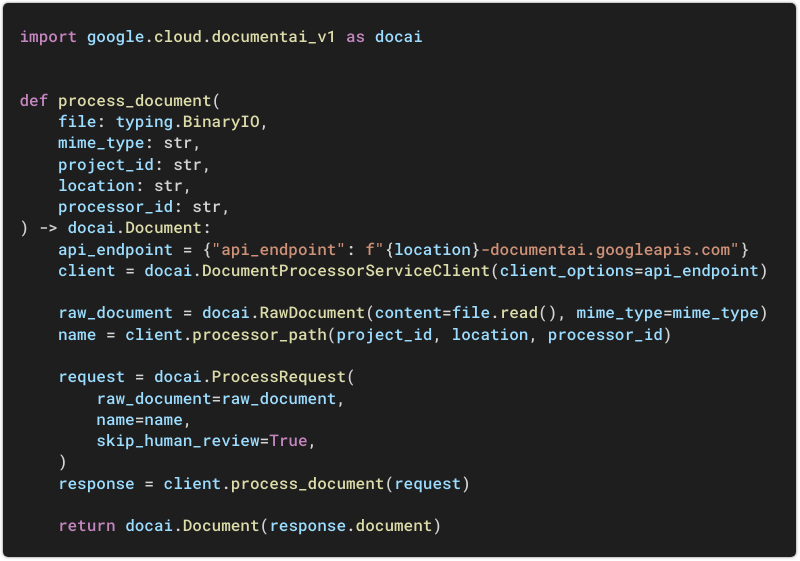
This function uses the Python client library:
The input is a
file(any format supported by the processor).clientis an API wrapper (configured for processing to take place in the desired location).process_documentcalls the APIprocessmethod, which returns results in seconds.The output is a structured
Document.
You can collect the detected fields by parsing the document entities:
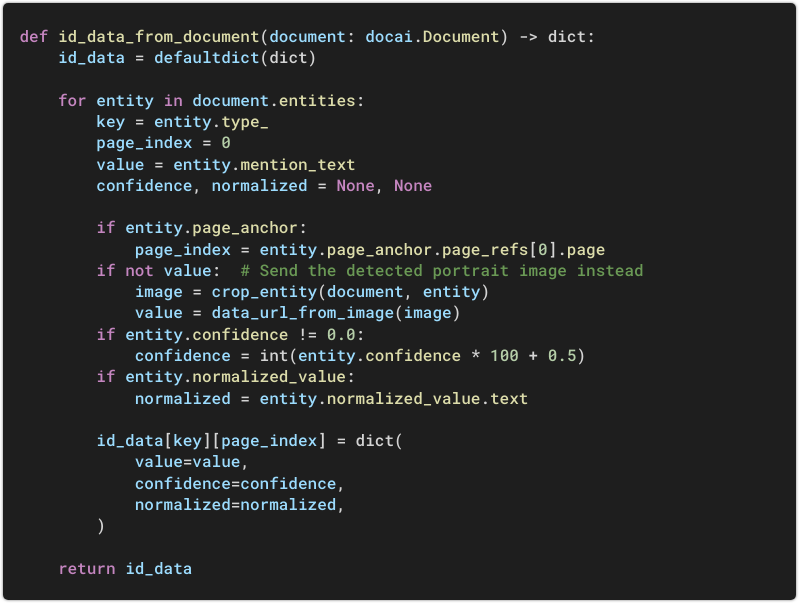
Note: This function builds a mapping ready to be sent to a frontend. A similar function can be used for other specialized processors.
Finalize your app:
Define your user experience and architecture
Implement your backend and its API
Implement your frontend with a mix of HTML + CSS + JS
Add a couple of features: file uploads, document samples, or webcam captures
That's it; you've built an identity form autofiller
Here is a sample web app in action:

Here is the processing of a French national ID, dropping images from the client:
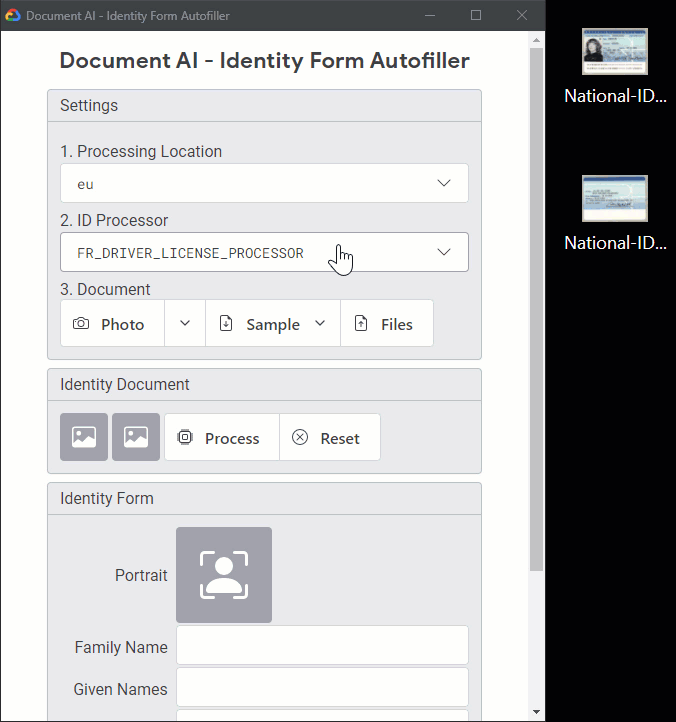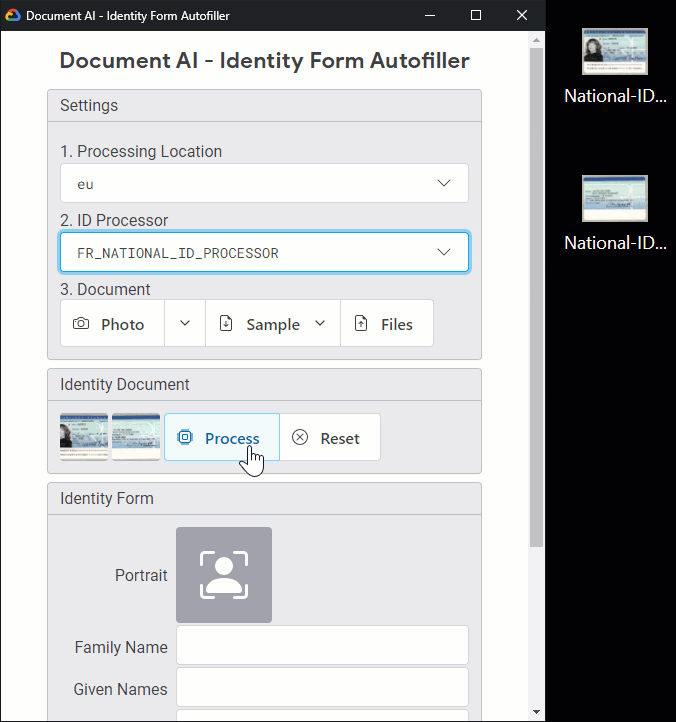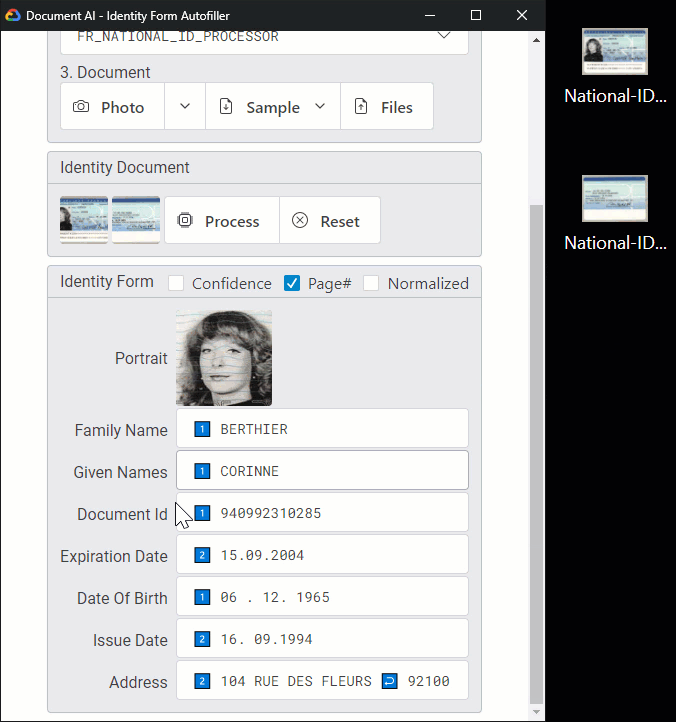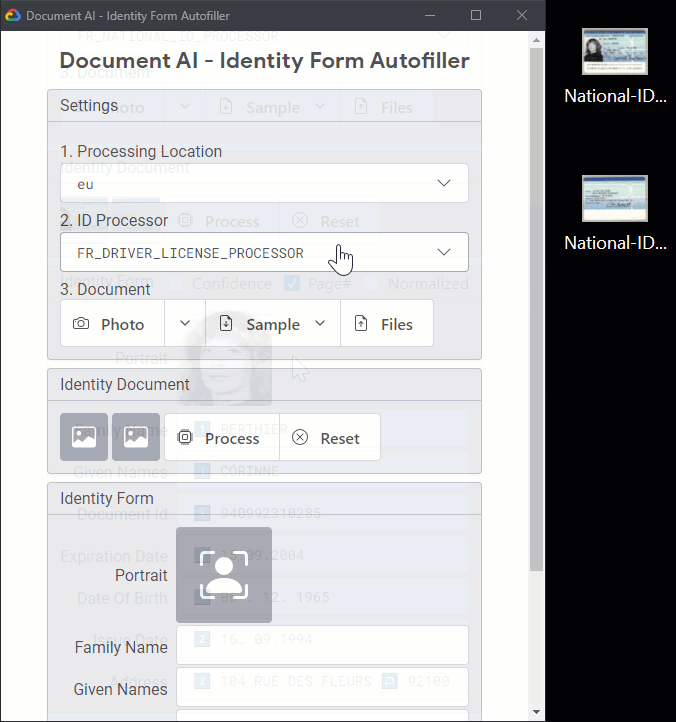
Note: For documents with multiple pages, you can use a PDF or TIFF container. In this example, the two uploaded PNG images are merged by the backend and processed as a TIFF file.
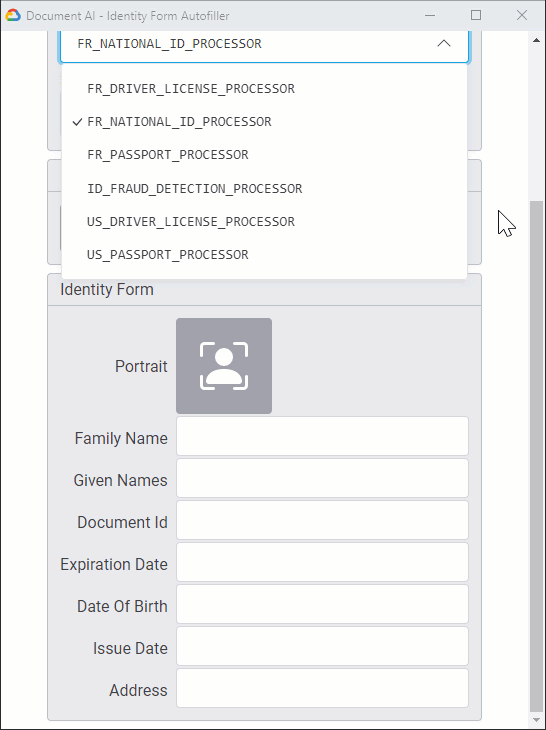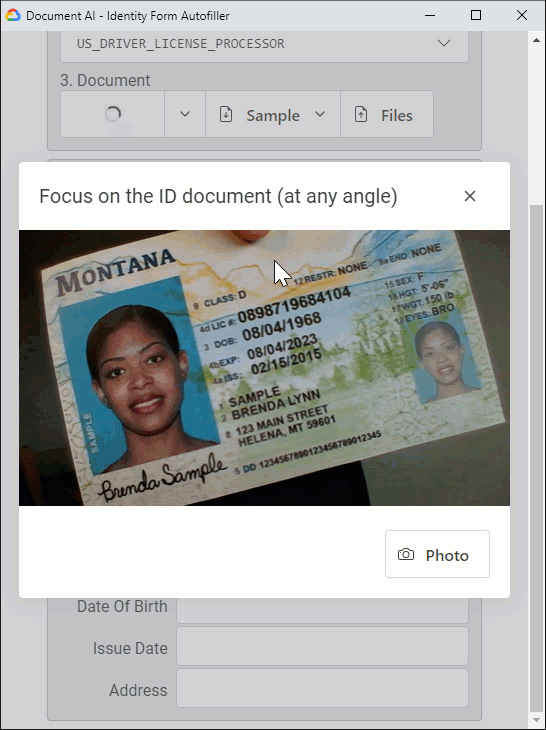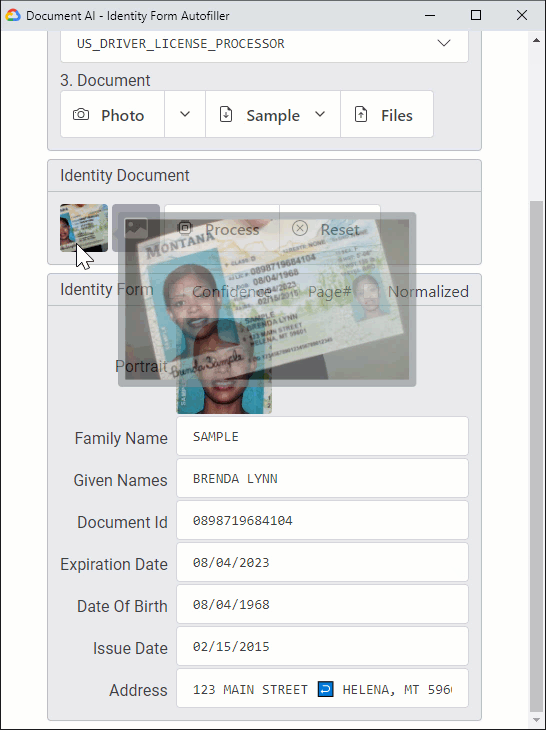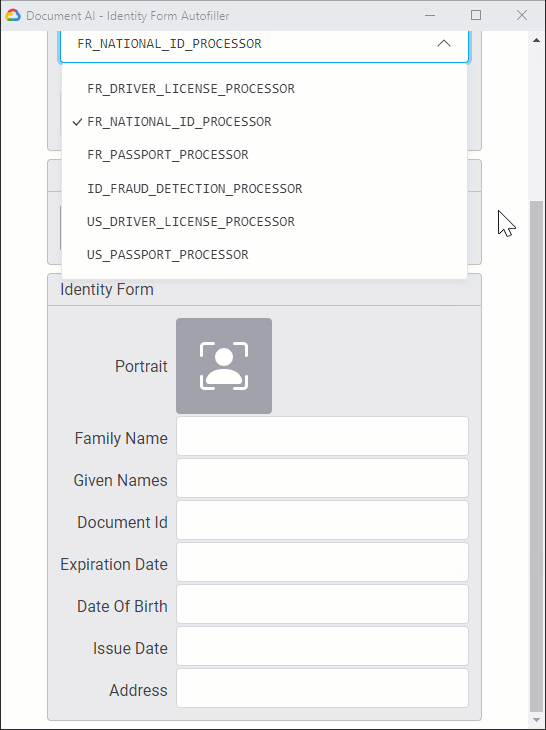
And this is the processing of a US driver license, captured with a laptop 720p webcam:
Notes:
Did you notice that the webcam capture is skewed and the detected portrait image straight? That's because Document AI automatically deskews the input at the page level. Documents can even be upside down.
Some fields (such as the dates) are returned with their normalized values. This can make storing and processing these values a lot easier – and less error-prone – for developers.
The source code for this demo is available in our Document AI sample repository.
More
Stay tuned; the family of Document AI processors keeps growing and growing.




