How Redbox improved service resilience and availability across clusters with GKE and Anthos multicluster ingress
Guna Vijayaratnam
Customer Engineer, Google Cloud
Lin Meyer
Manager Cloud DevOps, Redbox
Americans are used to seeing movie-stuffed red kiosks at stores around the country. The company that offers these movie kiosks—along with On Demand entertainment—is Redbox.
Redbox started their cloud-native journey by having microservices deployed across one region with another cloud provider and this was primarily on a single Compute cluster in the region. With business demand, they eventually saw the need to move towards a multi-region deployment (east and west) leveraging the same application architecture for their microservices but deploying the applications across the two regions. Most of the traffic originated from the east with a growing volume from the west and as such, a multi-region solution became increasingly important for the business to be able to serve their customer traffic efficiently. Lin Meyer at Redbox shares how they solved this problem.
What were the challenges that traditional multi-cluster solutions couldn't solve?
Redbox was generally able to keep their applications running with a two 9s availability using the single region architecture and were looking to move to a three 9s availability using a multi regional approach. This was primarily driven by availability issues mostly in the evenings and weekends when there was an increased demand for streaming services. They started exploring multi-region/cluster solutions but they quickly noticed a couple of key challenges with the existing toolsets.
Traffic management challenges. While there were approaches to shift traffic from one cluster to another, a lot of the ownership of implementing that was left to the individual operators. There was an expectation on operators of the environment to rely on telemetry to configure traffic management rules in the event of an application or infrastructure failure to route to the available cluster.
Complexity. The options that were currently available with this cloud provider relied on a lot of custom scripting and engineering as well as configuration across various cloud subsystems (including networking, security and compute) In order to achieve the multi cluster topology that the business required.
Why GKE, Anthos and multi-cluster ingress?
Redbox started exploring managed Kubernetes services specifically to address the availability issue back in late 2019. Redbox turned to Kubernetes to see if there was a built-in solution that addressed this multi-region need. They started off by looking at other cloud managed services initially to determine if there was a more elegant way to achieve their multi cluster requirement. Based on their assessment they determined that the current solutions were not going to work for a couple of reasons.
Platform to build other platforms. Through their research they determined that other managed Kubernetes services were a platform that organizations had to build other capabilities onto. An example is the node autoscaling feature. While they had ways to deal with it, it was an expectation of the cluster operator to configure the base cluster with these services. Redbox was looking for a managed service that had these infrastructure level add ons available or easily enabled.
Lack of a dedicated multi cluster/region solution. They determined that they could leverage a DNS service to achieve this capability but it was a lot more DIY and not a dedicated multi-cluster solution which would have led to far more engineering efforts and a potentially more brittle solution. They were ideally looking for a more sophisticated multi-cluster solution.
They started looking at GKE as a possibility and quickly came across the multi-cluster Service (MCS) and multi-cluster Ingress (MCI) services and saw that as a real potential for their multi-region requirements. They were definitely impressed with GKE but MCI and MCS were the key drivers that made them consider GKE.
What did the multi-cluster Ingress and multi-cluster Service get you?
There were several reasons why Redbox decided to go down the MCS path.
Dedicated Service. Unlike the other approaches that required a lot of engineering effort this service was fully managed and removed a lot of complexity and engineering effort from the operator’s point of view. The DevOps team could focus on their service, which they wanted to enable this capability for and the MCS and MCI controller took care of all the underlying details from a networking and load balancing perspective. This level of abstraction was exactly what the Redbox team was looking for.
Declarative Configuration. The fact that the MCS service supported the use of YAML worked very nicely with the rest of the Kubernetes based artifacts. There was no need to click around the console and make updates, which was Redbox’s preferred approach. This also fit very nicely with their CI/CD tool chain as well as they could version control the configuration very easily.
The Redbox team was able to move forward with this service very quickly by enabling a few APIs at the project level and were subsequently able to get their MCS service stood up and accepting traffic in a matter of days. Within the next week, they were able to complete all their failover load tests and within 2 weeks, they had everything stood up and deployed in production.
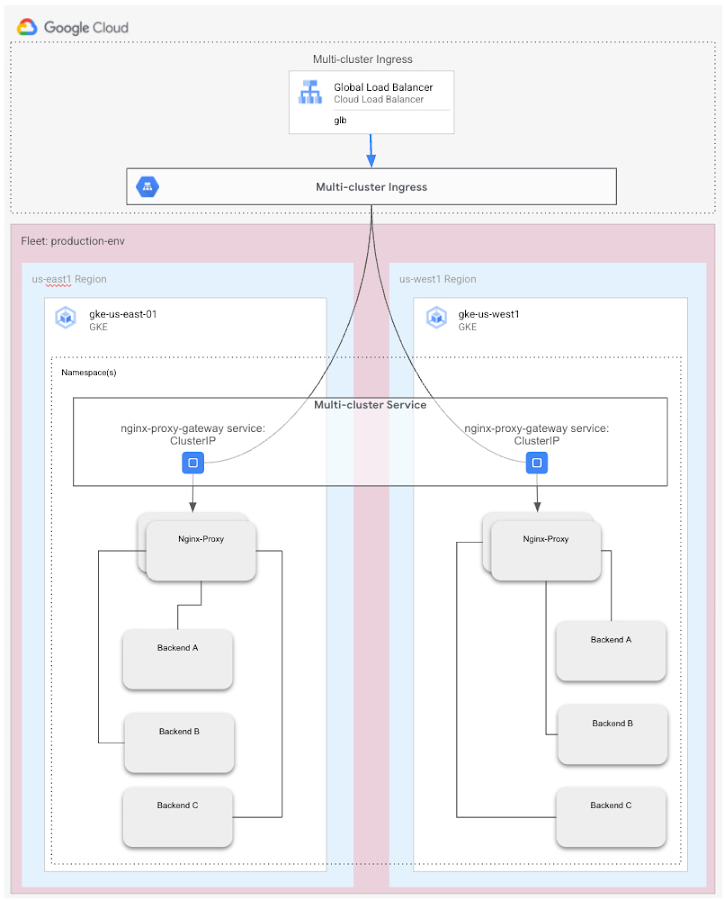
What benefits are you seeing from this deployment?
The Redbox team has currently been using this service for about two years in production. To date, here are some key benefits that they are seeing.
Availability. This service has significantly improved application availability and uptime. They are now able to achieve a four 9s availability for their services by simply leveraging the MCS service. The MCI service has seamlessly handled the failover from one cluster to another in the event of an issue providing virtually no disruption for their end user applications.
Simplified Deployment. By supporting MCS services as native Kubernetes objects, the DevOps team can now include the declarative configuration of services for multi-region deployment as part of their standard configuration deployment process.
Regular Maintenance. An added benefit of the MCS service is that the DevOps team can now perform scheduled maintenance on the regional clusters without taking any downtime. For example they currently run Istio in each cluster and typically an upgrade of Istio requires a cluster upgrade and also application restarts. With MCS, they can now perform these maintenance activities without taking any downtime as MCS continues to guarantee application availability. This has contributed to a much higher uptime.
Inter-service communication. MCS has also dramatically improved the data path for inter-service communication. Redbox currently runs multiple environments that are segregated by data category (PCI and non-PCI). By deploying a single GKE fleet for the PCI and non-PCI clusters and subsequently leveraging MCS to expose the services in a multi-regional manner, PCI services can now talk to non-PCI services through their MCS endpoints. This allows MCS to function as a Service Registry for multi-cluster services with the service endpoint discovery and invocation handled seamlessly. It also presents a more efficient data path by connecting from one service to another without having to traverse through an internal or external load balancer.
Summary
At Redbox we knew we needed to modernize our infrastructure and deployment platform to meet the needs of our DVD kiosk rental business and rapidly growing digital streaming services. When looking at options for faster, safer deployments we found Google Kubernetes Engine and opted to use Multi Cluster Ingress and Multi Cluster Services to host our customer facing applications across multiple GCP regions. With GKE and MCI we have been able to continue our digital transformation to the cloud, getting new features and products to our customer’s faster than ever. MCI has enabled us to do this with excellent reliability and response times by routing traffic to the closest available cluster at a moment’s notice.
To learn more about Anthos and MCI, please visit https://cloud.google.com/anthos



