Anthos in depth: Toward a service-based architecture
Chris Crall
Product Manager, Anthos Service Mesh
Two weeks ago, we announced many new advancements we are making to Anthos, including new capabilities that let you better run and manage loosely coupled microservices anywhere you need them. Today, we’re diving deeper into this world of services, and how we have been helping customers on their journey to this model.
At a high level, the main benefit of a service-based architecture is the speed with which it lets you roll out changes with minimum disruption. With their smaller, independent components, microservices-based architectures enable faster development and deployment, increased choice of technologies, and more autonomous teams, so you can quickly roll out new and upgraded products to your customers.
But as your usage of microservices increases, you often face additional challenges and you may need to adopt more modern deployment and management practices. With Anthos Service Mesh, you can:
Better understand what is happening with your services
Set policies to control those services
Secure the communication between services
All of this is done without changes to your application code.
Let’s take a deeper look at how Anthos Service Mesh works, and how you can use it to adopt a more efficient service-based architecture.
Better monitoring and SLOs
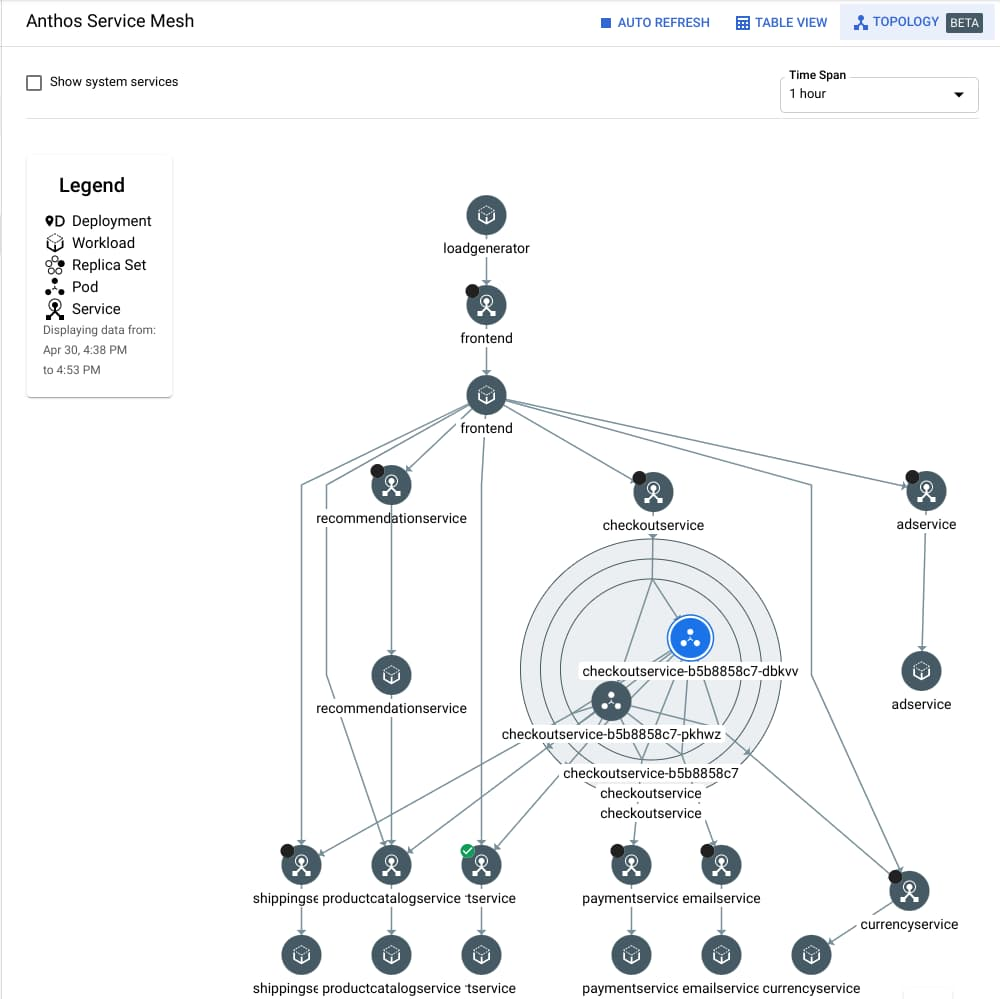
Many of you come to us for help implementing Site Reliability Engineering (SRE) principles in your organization. Anthos Service Mesh can help you do this, beginning with monitoring, so they can see which services are communicating, how much traffic is being sent, and response times and error rates. Simply having this initial baseline information is a major improvement for many customers’ operations. For example, the topology graph below shows the connections between services. The focus on the checkout service even shows the pods comprising the service.
Once you have monitoring in place, you can use Anthos Service Mesh to implement service level objectives (SLOs). Setting SLOs (for example, 99% availability over a one week rolling window) and having alerts on those SLOs lets your staff be proactive and catch issues before your customers become aware of them. You can send alerts (i.e., email, page, and UI warnings) to the team when your SLOs are not being met or you’ve exceeded your error budgets. This is an indicator that deployments should be frozen or slowed until stability and reliability are under control.
This “cartservice” screenshot below shows the golden signals associated with this service, its health, and links to the infrastructure on which it’s running.
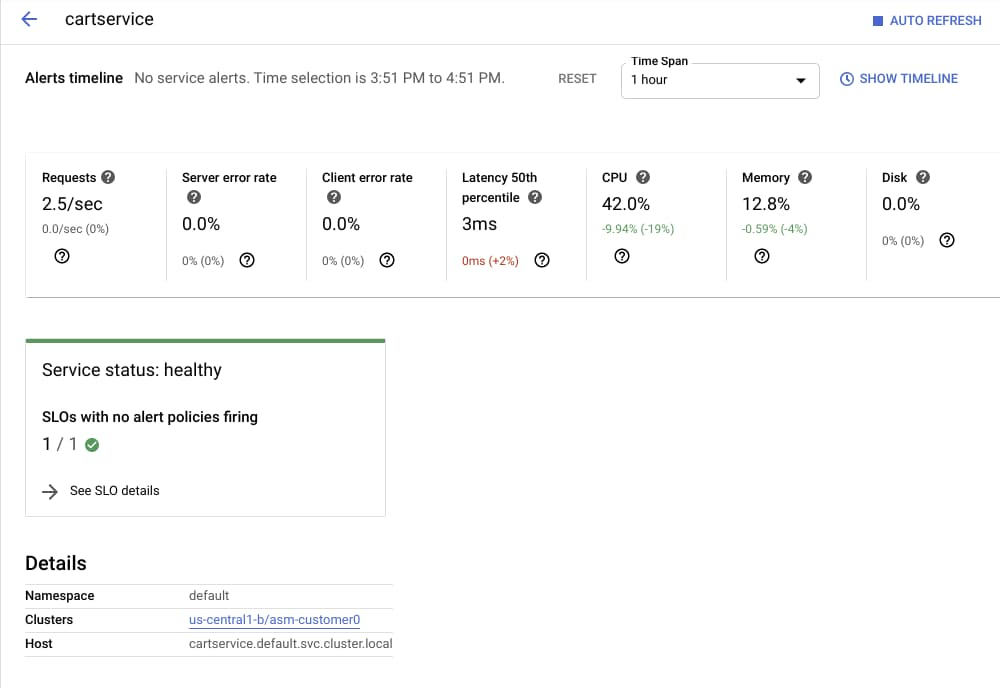
Through monitoring, SLOs and alerts, your team will have much more information about—and control over—the health and well-being of your services, which in turn makes your products more reliable and performant for your customers.
For example, co-location provider and Google Cloud partner Equinix uses Anthos and Anthos Service Mesh to give their customers visibility into their environments, so they can make better deployment decisions.
"At Equinix, giving our customers the best performance is our top priority. With Anthos and network insights from Equinix Cloud Exchange Fabric, we can build a service mesh that gives access to rich information about the performance of our customers’ applications,” said Yun Freund, SVP, Platform Architecture and Engineering. “This provides us with metrics we can use to recommend where customers should run their workloads for the best end-to-end user experience."
Security with policies, encryption and authentication
For many of you, particularly those in regulated industries like financial services and healthcare, there can be no compromises when it comes to security. Anthos Service Mesh lets you reduce the risk of data breaches by setting policies that ensure that any and all communications to and from your workloads are encrypted, mutually authenticated and authorized. This also helps protect against insider threats.
But implementing, maintaining and updating strict policies using traditional rules and IP based parameters can be difficult. It’s even harder to enforce those policies while your deployments are scaling up and down—especially if they’re based on technologies like containers and serverless that span hybrid and multi-cloud environments.
Anthos Service Mesh lets you implement context-aware application security using parameters such as identity, the service in question, as well as the context of the incoming request. You can also do all of this without depending on network primitives such as IP addresses. In this way, Anthos Service Mesh can help you adopt defense-in-depth and zero trust security strategies, on your way to implementing best practices such as BeyondCorp and BeyondProd.
Anthos Service Mesh also provides Mesh CA, a fully-managed certificate authority to issue certificates for your microservices, enabling a "zero trust" security posture based on mTLS. Mesh CA is now generally available for workloads running on Anthos GKE.
Traffic management
Finally, you can deploy Anthos Service Mesh to help you achieve safer, more controlled release processes, as well as gain more control over how traffic flows between your services. Anthos Service Mesh contains a number of traffic capabilities to allow you to fine tune the traffic in your mesh. For example, you can use the built-in canary capabilities to route a small percentage of traffic to new versions before rolling them out for all your users. Or you can take advantage of various load-balancing capabilities or location-based routing to control traffic. Other policies such as retries to enhance reliability, or even fault injection to test resilience, can help you roll out new products, while ensuring your customers have the best possible experience.
In the second half of this year Anthos Service Mesh will also integrate with Traffic Director, a managed configuration and traffic control plane for your service mesh. Traffic Director powers the traffic management fundamentals of the service mesh (like service discovery, endpoint registration, health checking and load balancing) and enables powerful DevOps use cases like blue/green deployments and circuit breaking while still using declarative, open-source Istio APIs.
Managed by Google
While Anthos Service Mesh is based on the open-source Istio service mesh, it is offered as a managed service. You get all the benefits of service mesh without having to monitor, manage and upgrade the underlying software.
Included as part of the managed offering, you get service mesh dashboards that give you all of the monitoring and SLO capabilities above, as well as telemetry, logging and tracing into a single tool. All these capabilities are generally available (GA) and fully supported. They give your application teams a set of out-of--the-box, powerful operations dashboards without having to depend on multiple open-source projects that you would in turn have to commit to deploy and maintain.
And because all these Anthos Service Mesh components, including Traffic Director, Mesh CA and the Anthos Services telemetry dashboards, are managed services, you don't need to worry about installing, upgrading or maintaining these components—Google's SREs are on the job.
What’s next for Anthos Service Mesh?
The next frontier for Anthos Service Mesh is to make it easier for you to join virtual machines to the mesh, and not just containers. We are actively working on making it easy to add new and existing VMs to your mesh, so you can use all of the features listed above with your VM-based workloads.
Later this week, we are hosting a webinar where you will be able to learn how the newest Anthos features will help you to build resilient applications and enable you to follow SRE and security best practices no matter where your applications run. You can register for this webinar on May 8, 2020 here.



