Patterns for better insights and troubleshooting with hybrid cloud logs
Meenaxi Gunjati
Customer Engineer
Tinu Anand Chandrasekar
Customer Engineer, Google Cloud
Hybrid and multi-cloud environments produce a boundless array of logs including application and server logs, logs related to cloud services, APIs, orchestrators, gateways and just about anything else running in the environment. Due to this high volume, logging systems may become slow and unmanageable when you urgently need them to troubleshoot an issue, and even harder to use them to get insights.
Google Cloud's operations suite plays a vital role in any application modernization framework and is essential to assuring a reliable and secure application, providing monitoring, logging and alerting — the baseline of SRE and Google’s holistic approach to operations.
As customer engineers, we see many organizations with hybrid and multi-cloud applications who want to integrate logs and metrics from various sources into a single console. Metrics of all critical services can be collected not just for daily operations but also to measure internal and external SLIs, SLOs and SLAs of modern applications.
Improving customer operations
We recently worked with two customers - a large media-processing customer and a large telecom provider -- that have applications running on Google Cloud, other clouds and on-premises. Each customer faced issues with their logs:
Customer 1, large media-process company: their existing logging environment was too slow to effectively support real-time troubleshooting using system and application logs from across all their environments, and
Customer 2, large telecom provider: they did not feel they were getting valuable insights from the many terabytes of network logs they were ingesting per day. These insights did not need to be real-time.
Both customers used self-managed, popular open source products for ingesting, storage and retrieval. But as the volume of their logs grew, the cost of their infrastructure and operational overhead to support logs rose too. They shared other characteristics:
Both setups required SSD storage as well as large VMs for ingestion pipelines, storage and retrieval.
Both faced risk due to dependencies on a single resource for elements of their log management.
And finally, both had data pipeline queues piling up, which for one of them meant they were not getting the logs when they needed them most, when application/infrastructure failures impacted the SLA of their products and services.
They needed to reduce costs, reduce failures and determine the volume of logs they need to ingest and store to get analytical insights from them. We looked at different patterns and proposed the following two options:
Customer 1: Route system and application logs from their hybrid and multi-cloud services to Cloud Logging for real-time troubleshooting at scale, reducing cost and operational burden.
Customer 2: Route their network logs directly to BigQuery, so they could manage costs and get better insights from their data.
Let’s take a deeper look at the two patterns:
Pattern 1: Cloud Logging for resource management and troubleshooting
This pattern fits well in the scenarios where the primary objective is to troubleshoot based on real time logs. Here the main focus is on important logs & metrics, while logs that are not needed for real-time troubleshooting are sampled and filtered as needed. Customer 1 had a large volume of logs, so scale and timely ingestion were critical for troubleshooting problems. To help them meet their objective, we proposed the following pattern:
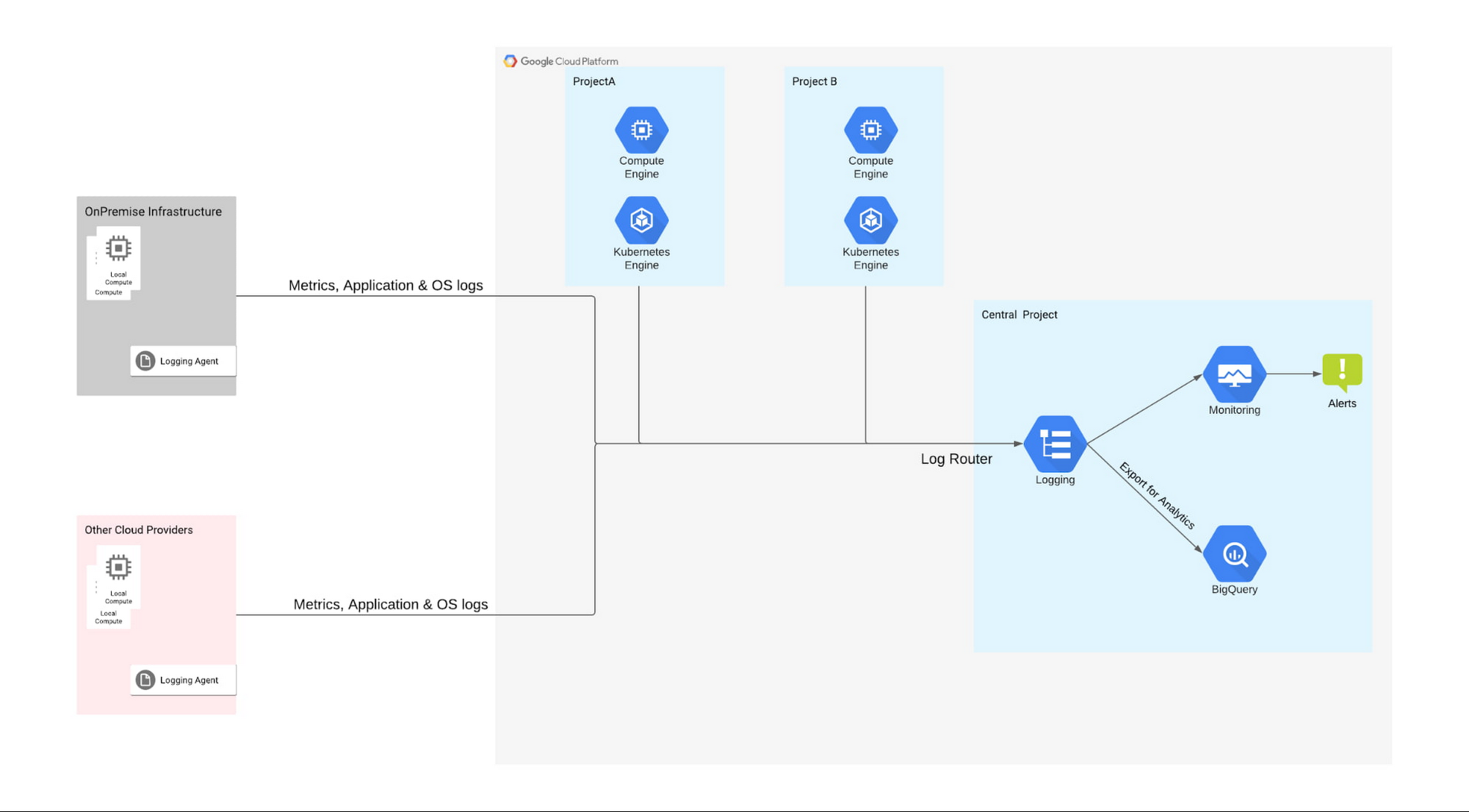
In this pattern, the customer uses Cloud Logging to collect the logs from Google Cloud, other clouds and VMs. Google Cloud resources such as Google Kubernetes Engine (GKE), Compute Engine with the Ops Agent, and Cloud Storage automatically send logs to Cloud Logging, while logging agents such as fluentd and stanza brings in application and system logs from other sources such as other clouds and on-prem systems (Additionally, partner tools such as BlueMedora can be used to bring logs from a wide range of other sources including Azure Kubernetes Service).
Logging agents collect and send the logs using Cloud Logging API to the Logs Router, where you can apply filters to capture only the important logs. Our customer’s hybrid deployment was generating 20 TB of logs every day, so we identified logs which were not important for real-time troubleshooting (in their case detailed network logs and debug logs) and applied filters at both the agent and Logs Router level. Further, we advised them that they could export their network logs to BigQuery or other third party tools for future analysis for deriving patterns and insights.
This pattern suited the customer’s requirements as their use case was primarily focused on troubleshooting and detailed network logs were only needed for analytics. It had the following advantages
Fully managed so they could focus on app development
Cost effective with combination of Cloud Logging and BigQuery
Provided the basis for future self healing operations with logs-based metrics
Pattern 2: BigQuery for log analytics in hybrid and multi-cloud scenarios
This pattern fits well in Customer 2’s scenario where logs volumes are high and leveraged primarily for analytics. In this customer’s case, they wanted deeper insights into their network logs.
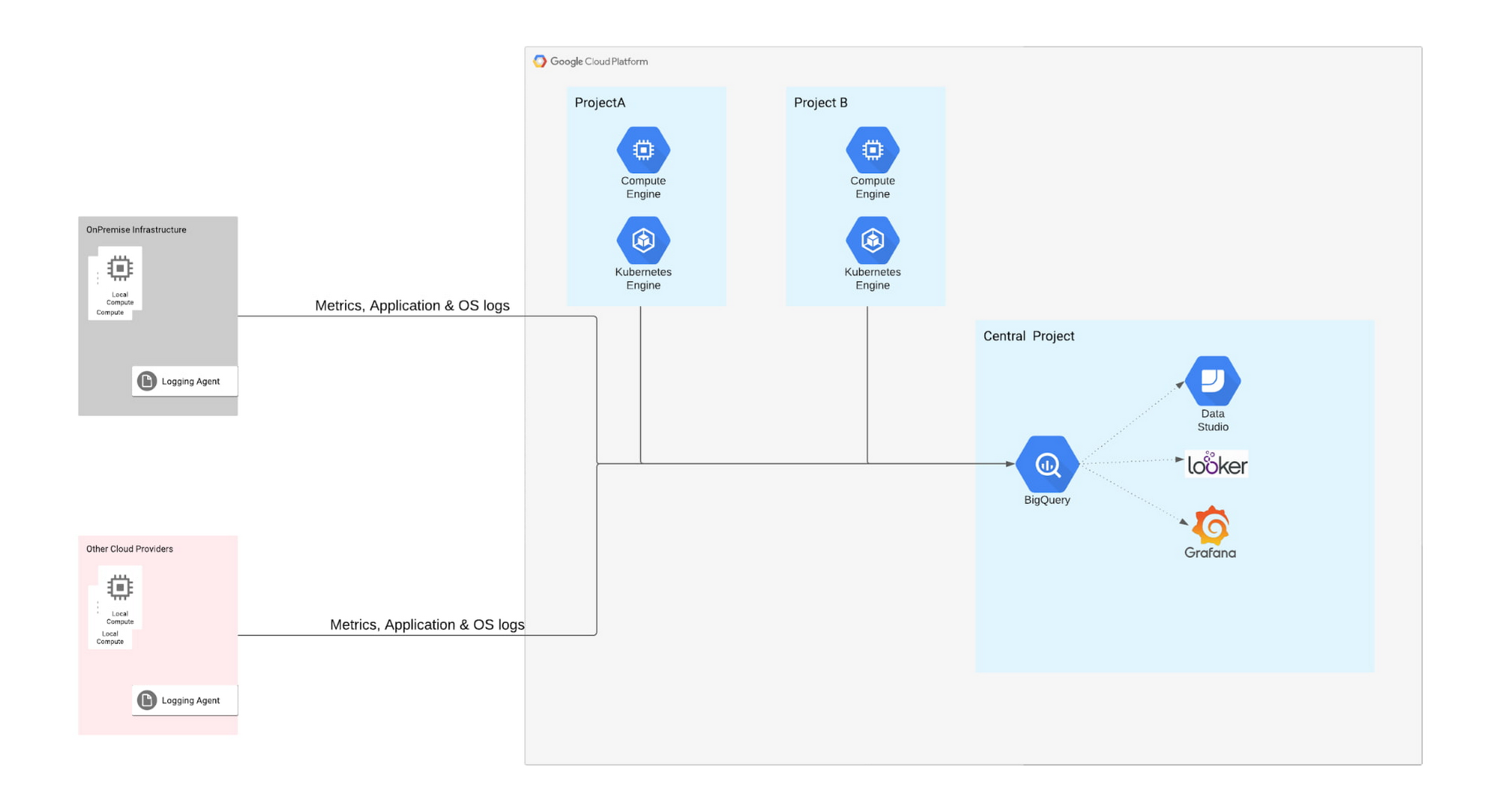
This pattern is recommended for customers that need to run models for anomaly detection, pattern recognition, etc., specifically related to their network logs. Network logs tend to be high volume, and since these logs were primarily used for analytics, the customer did not really benefit from capabilities like sorting, filtering, dashboarding, etc. This is where BigQuery was useful, with low costs, built-in AI/ML, and global scale. Google's fully managed data warehouse and analytical engine performed queries on terabytes of logs in tens of seconds making it ideal for the customer’s advanced analytics needs.
In this pattern, the Log Collector agent uses an output plugin that configures BigQuery as a destination for storing the logs collected from hybrid cloud, other cloud providers and from Google Cloud. Using the plugin, the customer can directly load logs into BigQuery in near-real-time from many servers. BigQuery automatically creates the schema for incoming logs, giving the customer more control over defining the schema and data format for the metrics. Once the logs are in BigQuery, the customer can make use of Looker to perform basic RegEx and build machine learning models on top of it. The customer can also visualize their log data by creating a dashboard that's updated frequently using Data Studio, Looker or any visualization tool.
This pattern provides the following advantages:
A cost-effective solution for high-volume networking logs
Built-in analytics engine for log insights
Use of the BigQuery API to display data to a dashboard and consume analytical insights
Final Thoughts
Google Cloud’s operations suite is easy to use right out of the box for Google Cloud users, but as we demonstrate for our customers everyday, it supports a variety of other use cases. As shown in the two patterns above, if you did need to troubleshoot with a subset of the logs and need analytical capabilities with another subset of your logs, you can use the Cloud Logging API to send the first part of your logs to Cloud Logging and the other part of your logs directly to BigQuery!
Furthermore, there is work ongoing to simplify many of these tasks. For example, we recently released the preview of Log Analytics, which automatically imports logs from Google Cloud services into BigQuery, and gives you the ability to analyze that data directly from the Cloud Logging interface.
Get started today
If you want to achieve the maximum benefit from your logs without the cost and operational overhead, set up time with your account team today or click here to contact our sales team.
If you have any questions or topics that you want to discuss with the operations community at Google Cloud, please visit our Google Cloud Community site.


