Scheduling Dataflow pipelines using App Engine Cron Service or Cloud Functions
Mete Atamel
Developer Advocate
Google Cloud Dataflow provides a unified programming model for batch and stream data processing along with a managed service to execute parallel data processing pipelines on Google Cloud Platform.
Once a Dataflow pipeline is created, it can be tested locally using DirectPipelineRunner, and if everything looks good, it can be manually executed as a job in Dataflow Service by triggering DataflowPipelineRunner or BlockingDataflowPipelineRunner with Apache Maven or Dataflow Eclipse Plugin. You can monitor the progress of your submitted job with Dataflow Monitoring Interface from Cloud Platform Console or Dataflow Command-line Interface from gcloud.
Need for scheduling
This is all great for manual execution of pipelines but in a real-world data processing system, everything is automated or scheduled. One question that comes up quite often: "how do you schedule Dataflow pipelines to execute periodically or with some kind of a trigger?"Currently, there's no built-in mechanism in Dataflow to schedule pipelines but there are a couple of options within Cloud Platform that can help with scheduling pipelines, namely App Engine Cron Service and Cloud Functions.
In the rest of this post, I'll outline App Engine Cron Service and Cloud Functions and how they can be used to schedule Dataflow pipelines.
App Engine Cron Service
App Engine Cron Service allows you to configure and run cron jobs at regular intervals. These cron jobs are a little different from regular Linux cron jobs in that they cannot run any script or command. They can only invoke a URL defined as part of your App Engine app via HTTP GET. In return, you don’t have to worry about how or where the cron job is running. App Engine infrastructure takes care of making sure that your cron job runs at the interval that you want it to run.This is a perfect fit for Dataflow scheduling. One solution is that you can configure a Servlet on App Engine to trigger a Dataflow pipeline and then have the App Engine Cron Service invoke that Servlet periodically to execute a Dataflow pipeline.
Note that Cron Service is offered as part of both flavors (standard and flexible environment) of App Engine and you must use flexible environment to schedule Dataflow pipelines. Standard Environment comes with sandbox limits, such as execution time limits and blacklisted JRE classes. Dataflow pipeline execution generally requires uploading of JARs and other resources to Cloud Platform that might hit the time limit, and Dataflow uses blacklisted JRE classes. App Engine Flexible environment is in Beta at the time of writing this post.
Let’s take a look at some of the individual pieces of this solution. Let’s assume that we have a class named ScheduledMinimalWordCount and its run method creates and runs our Dataflow pipeline.
First, we need to create a Servlet that simply calls our pipeline code.
DataflowSchedulingServlet.java
And deploy to App Engine:
Second, we need to create a cron.yaml file (usually next to app.yaml) to configure App Engine Cron Service to call our Servlet’s URL at a regular interval, 30 minutes in this example:
Finally, we need to deploy our cron job to App Engine using gcloud:
That’s it! You can see your cron job under App Engine -> Task Queues -> Cron Jobs from Cloud Platform Console:
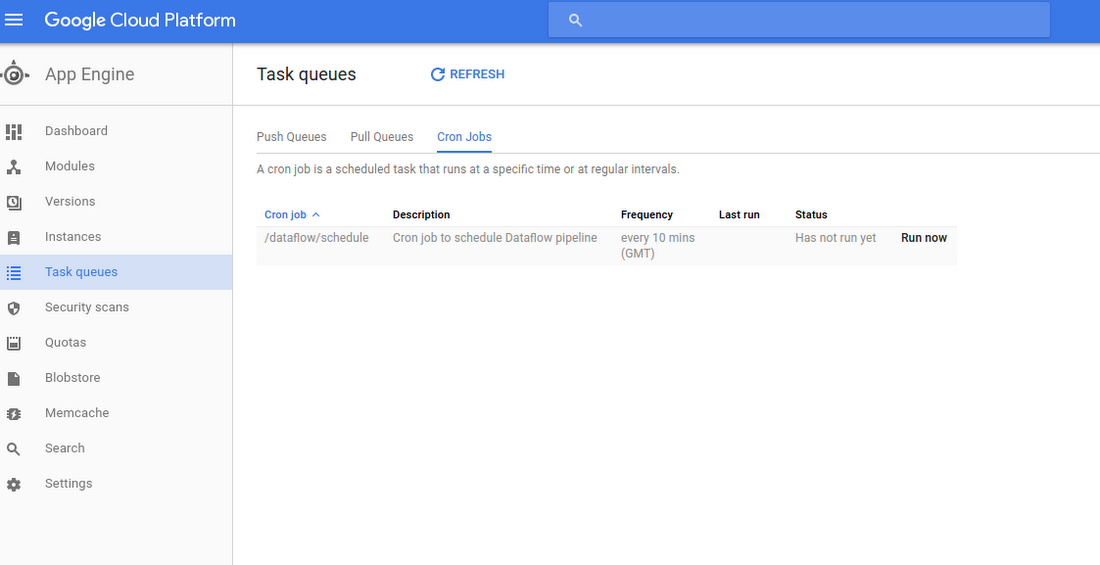
You can also check Dataflow Monitoring Interface to make sure your Dataflow pipeline has been executed.
Cloud Functions (experimental)
If you're part of the Alpha testing program for Cloud Functions, there's an alternative approach with some interesting characteristics, though we don't recommend relying on it for production jobs just yet.Cloud Functions enable you to write Node.js functions to respond to events in your cloud environment. They're fully managed, just write your function and deploy, no need to worry about infrastructure. They respond to a number of different triggers (Pub/Sub messages, Cloud Storage changes, HTTP invocations) which makes them quite useful for different scenarios.
Another approach for Dataflow scheduling is to write a Cloud Function to execute Dataflow pipeline that can have any of the Cloud Function triggers (Pub/Sub, Cloud Storage, plain HTTP) to kickstart the Dataflow pipeline. In order to get this working, we need to do a few things.
First, Dataflow pipelines are usually written in Java with Dataflow SDK, and we need to create an executable JAR for Node.js to call. For this example, we'll use a WordCount.java example that comes with Dataflow. There are many ways to create a jar from this sample. For example, if you’re an Eclipse user, you can simply right click on the file and export it to an executable JAR.
Second, we need the create a Node.js module for our Cloud Function:
Then, we need a way to call our executable JAR from our Node.js module. We can do this with spawn in Node.js. Here’s how our module looks now:
Note that the Node.js spawn command uses a local Java runtime folder to execute the JAR. This is needed because Cloud Functions run on Google Compute Engine VMs, and those VMs don't have Java installed, so we need to provide our own Java runtime folder along with the Cloud Function code.Finally, we can deploy our function. Make sure that your Node.js module is named as index.js and all Java dependencies (WordCount.jar and jre1.8.0_77) are in the same folder. During deployment, we need to specify a bucket name for Cloud Function to store its local data. We also need to specify the trigger the function can use. In our example, let’s use a simple HTTP trigger:
We can check that the function is deployed with:
Last but not least, we can trigger our function with a simple HTTP request:
This HTTP request will trigger our function, which in turn triggers our Dataflow pipeline. We can check that our Dataflow pipeline is indeed executed from Dataflow Monitoring Interface:
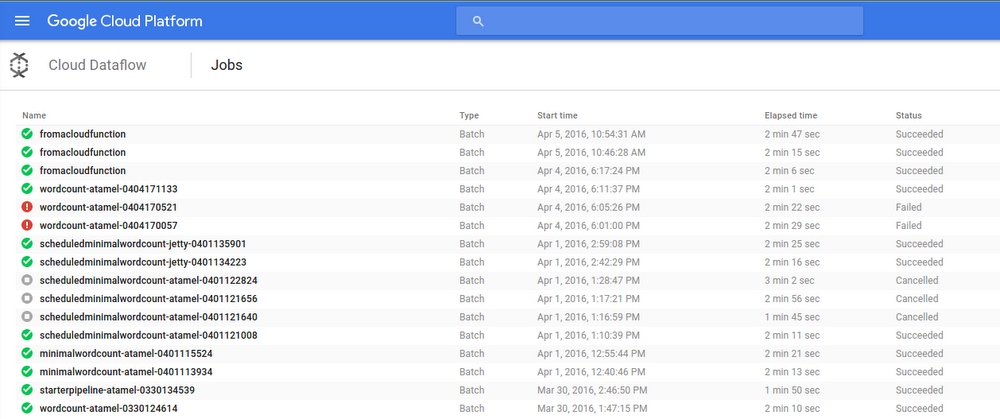
You can get even more sophisticated by creating a Cloud Function to get triggered from a Pub/Sub topic, and any system that can send messages to that topic can kickstart your Dataflow pipeline!
Even though there's no built-in mechanism in Dataflow, App Engine Cron Service is a straightforward way of scheduling pipelines. If you feel adventurous, you always have Cloud Functions for more flexibility and triggers on scheduling pipelines.


