Cloud Spanner doubles the number of updates per transaction
Rajeshwar Vanka
Senior Software Engineer
We are excited to announce that Cloud Spanner now supports 40,000 mutations per commit, double the existing limit at no additional cost. Cloud Spanner is a globally replicated, highly available, externally consistent ACID-compliant database. Customers across multiple sectors, including financial services and gaming, rely on externally consistent inserts, updates and deletes at scale to deliver fast and accurate experiences.
A mutation represents a sequence of inserts, updates, and deletes that Spanner applies atomically to different rows and tables in a Spanner database. Cloud Spanner places limits on the number of mutations that can be included in a single transaction to ensure fast and consistent writes. Previously, queries were limited to 20,000 mutations per transaction, whether you were using DML via SQL or the lower-level Mutation API. We’ve doubled this limit to 40,000 to simplify batch updates and deletes. This is available to all customers of Cloud Spanner today. The size limit for each transaction remains unchanged at 100MB.
What are mutations?
Mutations are changes to values in the database. Cloud Spanner provides multiple ways to update data
- Standalone DML statements in transactions
- Batch DML statements to reduce the number of calls (and hence, round-trip latency) to the Spanner front-end
- Partitioned DML to automatically divide a large update into multiple transactions
- The programmatic Mutation API to change one or more cells at a time. A cell is an intersection of a row and a column. The API computes the cells to be updated from the user-provided rows and columns.
Mutations across these approaches aggregate into the same mutations per transaction limit mentioned above. In the case of PartitionedDML, the mutation limit is not applied to the query itself, but Spanner enforces this limit when it creates the multiple transactions. For the other approaches, the user takes the responsibility. A single transaction may contain a combination of standalone and batch DML statements, in addition to programmatic API calls. Remember though, changes made with DML statements are visible to the subsequent statements.
The DML or Mutation API describes the primary table that is impacted by the mutation. Interleaved tables and indexes on the affected columns also need to be updated as part of this transaction. These additional locations are referred to as effectors. You can think of effectors as those tables that are affected by the mutations, in addition to the target of the mutation. The mutation limit includes the changes to these effectors.
Change streams watch updates in Spanner tables and write records of what changed elsewhere in the database in the same transaction. These writes are not included in the mutation limit.
How can I estimate mutation counts?
Spanner returns the mutation counts as part of the commit response message for a transaction. You can also estimate the number of mutations in a transaction by counting the number of unique cells updated across all the tables, including secondary indexes, as part of the transaction. Remember that a cell is the intersection of a row and column, like in a spreadsheet. A table that contains R rows and C columns, has R * C cells. Inserting a new row counts as C mutations since there are C cells in each row. Similarly, updating a single column counts as R mutations.
More formally, if a commit consists of inserts to a primary table and one or more secondary indexes, the formula for calculating the number of mutations per commit is as follows.
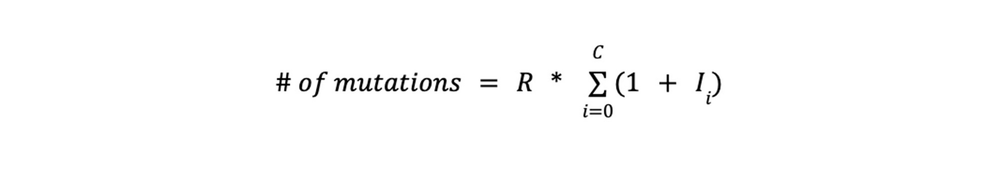
where R = number of rows/objects being inserted,
C = number of columns updated as part of the transaction.
Ii = number of secondary indexes on the current column.
In other words, for each row, the update writes C cells in the primary table and one cell for each of the secondary indexes hanging off of the columns. For example, if an update touches 4 columns (regardless of the number of columns in the row) over 10 rows and two of those columns have secondary indexes, plugging into the formula above,
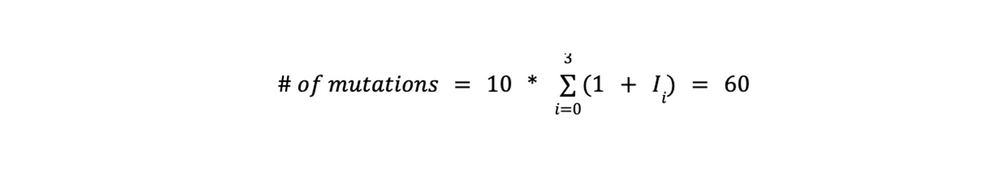
where Ii is 1 for each of the 2 columns with secondary indexes and 0 for others. 4 * 10 + 2 * 10 = 60 mutations.
Deletes are counted differently when it comes to logically adjacent cells. These are cells that are placed next to each other in table ordering and memory. Most common examples are logically adjacent cells are:
- Columns in a single row
- Consecutive rows
- Interleaved tables
Deletion of these cells count as a single mutation. So, deleting an entire row counts as one mutation. Deletions of cells that are not placed together, are still counted the same as insertions above. This means deletions of secondary indexes and foreign keys will count as one per cell. Deleting a column counts as R mutations, not including index deletions/changes.
Is there a cost to using larger mutations?
Transactions with more mutations involve more work. Since Spanner scales horizontally, much of this work can be distributed across multiple nodes. If this additional work causes instances to run hot, it may impact tail latencies for your application. Larger transactions need more memory and more compute cycles to write the additional bytes to disk. Mutations that are spread across the key space span multiple database splits. The transactions are guaranteed to be externally consistent but may take longer to complete. Account for these factors when constructing your transactions and scale up your instances to handle the additional load. Luckily Spanner can scale up or down in minutes without downtime and the compute capacity is prorated.
Tip: When the number of mutations in a transaction is doubled, the transaction size doubles as well if no other changes are made.
Mutations spread out across the key space or involving many indexes require coordination between the nodes (to maintain consistency). More specifically, different portions of the key space may be in different Paxos groups. In Spanner, each Paxos group achieves consensus through quorum. Reaching quorum in multiple Paxos groups takes time and the transaction will need to abort if any one of the Paxos groups is unable to reach quorum. Transactions with more mutations are more likely to include more Paxos groups.
To summarize, large mutations are more resource intensive and can have measurably higher latencies. You can ameliorate these effects by reducing the size of the transaction and reducing the key-range of the mutations.
What’s next?
Congratulations! You learnt the different ways to write mutations, how to count them and how to compose transactions such that you can do more work in each transaction. Here are some things you should consider.
- If your application would benefit from the larger 40,000 mutation limit, increase the number of mutations in each transaction.
- Monitor the CPU usage and latencies to ensure that your instances are able to handle the additional load.
- Add more nodes, reduce transaction size and/or key space range for the transaction to improve these metrics.
You can get started today for free with a 90-day trial or for as low as $65 USD per month.


