BigLake: unifying data lakes and data warehouses across clouds
Justin Levandoski
Director, Engineering
Gaurav Saxena
Group Product Manager
The volume of valuable data that organizations have to manage and analyze is growing at an incredible rate. This data is increasingly distributed across many locations, including data warehouses, data lakes, and NoSQL stores. As an organization’s data gets more complex and proliferates across disparate data environments, silos emerge, creating increased risk and cost, especially when that data needs to be moved. Our customers have made it clear; they need help.
That’s why today, we’re excited to announce BigLake, a storage engine that allows you to unify data warehouses and lakes. BigLake gives teams the power to analyze data without worrying about the underlying storage format or system, and eliminates the need to duplicate or move data, reducing cost and inefficiencies.
With BigLake, users gain fine-grained access controls, along with performance acceleration across BigQuery and multicloud data lakes on AWS and Azure. BigLake also makes that data uniformly accessible across Google Cloud and open source engines with consistent security.
BigLake extends a decade of innovations with BigQuery to data lakes on multicloud storage, with open formats to ensure a unified, flexible, and cost-effective lakehouse architecture.
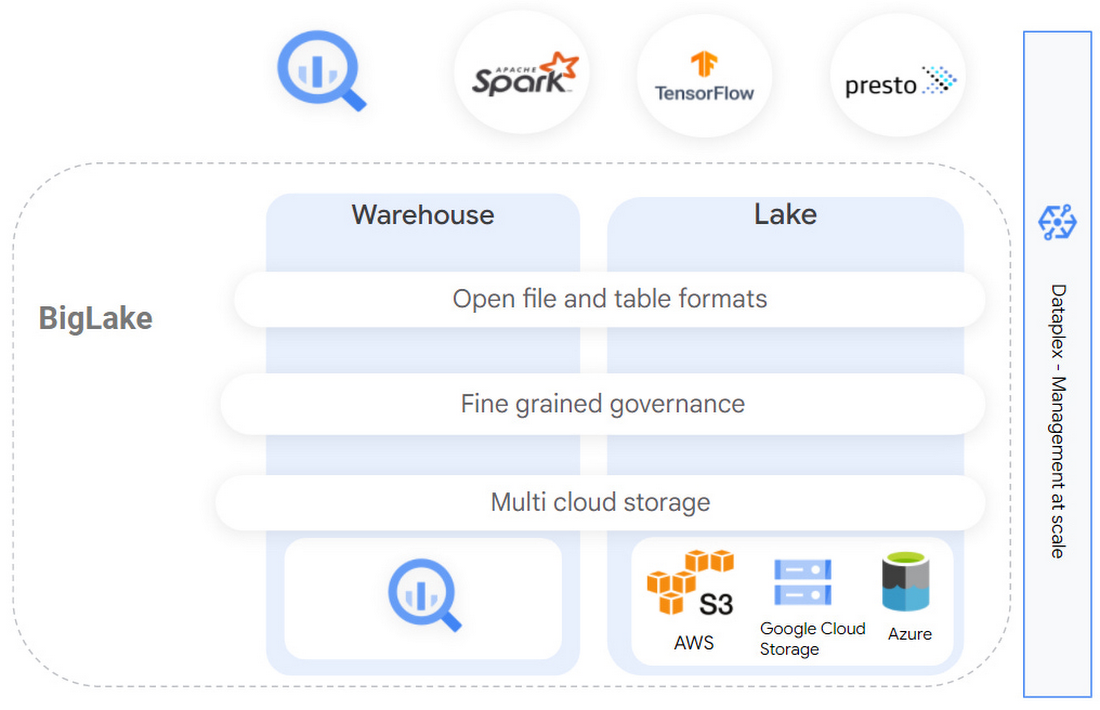
BigLake enables you to:
Extend BigQuery to multicloud data lakes and open formats such as Parquet and ORC with fine-grained security controls, without needing to set up new infrastructure.
Keep a single copy of data and enforce consistent access controls across analytics engines of your choice, including Google Cloud and open-source technologies such as Spark, Presto, Trino, and Tensorflow.
Achieve unified governance and management at scale through seamless integration with Dataplex.
Bol.com, an early customer using BigLake, has been accelerating analytical outcomes while keeping their costs low:
“As a rapidly growing e-commerce company, we have seen rapid growth in data. BigLake allows us to unlock the value of data lakes by enabling access control on our views while providing a unified interface to our users and keeping data storage costs low. This in turn allows quicker analysis on our datasets by our users.”—Martin Cekodhima, Software Engineer, Bol.com
Extend BigQuery to unify data warehouses and lakes with governance across multicloud environments
By creating BigLake tables, BigQuery customers can extend their workloads to data lakes built on Google Cloud Storage (GCS), Amazon S3, and Azure data lake storage Gen 2. BigLake tables are created using a cloud resource connection, which is a service identity wrapper that enables governance capabilities. This allows administrators to manage access control for these tables similar to BigQuery tables, and removes the need to provide object store access to end users.
Data administrators can configure security at the table, row or column level on BigLake tables using policy tags. For BigLake tables defined over Google Cloud Storage, fine grained security is consistently enforced across Google Cloud and supported open-source engines using BigLake connectors. For BigLake tables defined on Amazon S3 and Azure data lake storage Gen 2, BigQuery Omni enables governed multicloud analytics by enforcing security controls. This enables you to manage a single copy of data that spans BigQuery and data lakes, and creates interoperability between data warehousing, data lake, and data science use cases.

Open interface to work consistently across analytic runtimes spanning Google Cloud technologies and open source engines
Customers running open source engines like Spark, Presto, Trino, and Tensorflow through Dataproc or self managed deployments can now enable fine-grained access control over data lakes, and accelerate the performance of their queries. This helps you build secure and governed data lakes, and eliminate the need to create multiple views to serve different user groups. This can be done by creating BigLake tables from a supported query engine like Spark DDL, and using Dataplex to configure access policies. These access policies are then enforced consistently across the query engines that access this data - greatly simplifying access control management.
Achieve unified governance & management at scale through seamless integration with Dataplex
BigLake integrates with Dataplex to provide management-at-scale capabilities. Customers can logically organize data from BigQuery and GCS into lakes and zones that map to their data domains, and can centrally manage policies for governing that data. These policies are then uniformly enforced by Google Cloud and OSS query engines. Dataplex also makes management easier by automatically scanning Google Cloud storage to register BigLake table definitions in BigQuery, and makes them available via Dataproc Metastore. This helps end users discover these BigLake tables for exploration and querying using both OSS applications and BigQuery.
Taken together, these capabilities enable you to run multiple analytic runtimes over data spanning lakes and warehouses in a governed manner. This breaks down data silos and significantly reduces the infrastructure management, helping you to advance your analytics stack and unlock new use cases.
What’s next?
If you would like to learn more about BigLake, please visit our website. Alternatively, get started with BigLake today by using this quickstart guide, or contact the Google Cloud sales team.