Presto optional component now available on Dataproc
Tahir Fayyaz
Developer Advocate
Brad Miro
Developer Advocate
Presto is an open source, distributed SQL query engine for running interactive analytics queries against data sources of many types. We are pleased to announce the GA release of the Presto optional component for Dataproc, our fully managed cloud service for running data processing software from the open source ecosystem. This new optional component brings the full suite of support from Google Cloud, including fast cluster startup times and integration testing with the rest of Dataproc.
The Presto release of Dataproc comes with several new features that improve on the experience of using Presto, including supporting BigQuery integration out of the box, Presto UI support in Component Gateway, JMX and logging integrations with Cloud Monitoring, Presto Job Submission for automating SQL commands, and improvements to the Presto JVM configurations.
Why use Presto on Dataproc
Presto provides a fast and easy way to process and perform ad hoc analysis of data from multiple sources, across both on-premises systems and other clouds. You can seamlessly run federated queries across large-scale Dataproc instances and other sources, including BigQuery, HDFS, Cloud Storage, MySQL, Cassandra, or even Kafka. Presto can also help you plan out your next BigQuery extract, transform, and load (ETL) job. You can use Presto queries to better understand how to link the datasets, determine what data is needed, and design a wide and denormalized BigQuery table that encapsulates information from multiple underlying source systems. Check out a complete tutorial of this.
With Presto on Dataproc, you can accelerate data analysis because the Presto optional component takes care of much of the overhead required to get started with Presto. Presto coordinators and workers are managed for you and you can use an external metastore such as Hive to manage your Presto catalogs. You also have access to Dataproc features like initialization actions and component gateway, which now includes the Presto UI.
Here are additional details about the benefits Presto on Dataproc offers:
Better JVM tuning
We’ve configured the Presto component to have better garbage collection and memory allocation properties based on the established recommendations of the Presto community. To learn more about configuring your cluster, check out the Presto docs.
Integrations with BigQuery
BigQuery is Google Cloud’s serverless, highly scalable and cost-effective cloud data warehouse offering. With the Presto optional component, the BigQuery connector is available by default to run Presto queries on data in BigQuery by making use of the BigQuery Storage API. To help get you started out of the box, the Presto optional component also comes with two BigQuery catalogs installed by default: bigquery for accessing data in the same project as your Dataproc cluster, and bigquery_public_data for accessing BigQuery’s public datasets project. You can also add your own catalog when creating a cluster via cluster properties. Adding the following properties to your cluster creation command will create a catalog named bigquery_my_other_project for access to another project called my-other-project:
Note: This is only currently supported on Dataproc image version 1.5 or preview image version 2.0, as Presto version 331 or above is required for the BigQuery connector.
Use an external metastore to keep track of your catalogs
While catalogs can be added to your Presto cluster at creation time, you can also keep track of your Presto catalogs by using an external metastore such as Hive and adding this to your cluster configuration. When creating a cluster, add the following properties:
The Dataproc Metastore, now accepting alpha customers, provides a completely managed and serverless option for keeping your Presto metadata information accessible from multiple Dataproc clusters and lets you share tables between other processing engines like Apache Spark and Apache Hive.
Create a Dataproc cluster with the Presto optional component
You can create a Dataproc cluster by selecting a region with the Presto, Anaconda and Jupyter optional components and component gateway enabled with the following command. You can also include the Jupyter optional component and necessary Python dependencies to run Presto commands from a Jupyter Notebook:
Submit Presto jobs with the gcloud command
You can use Dataproc’s Presto Jobs API to submit Presto commands to your Dataproc cluster. The following example will execute the “SHOW CATALOGS;” Presto command and return the list of catalogs available to you:
You should then see the output:
Query BigQuery public datasets
BigQuery datasets are known as schemas in Presto. To view the full list of datasets, you can use the SHOW SCHEMAS command:
Then, run the SHOW TABLES command to see which tables are in the dataset. For this example, we’ll use the chicago_taxi_trips dataset.
Then submit a Presto SQL query against the table taxi_trips using this code:
You can also submit jobs using Presto SQL queries saved in a file. Create a file called taxi_trips.sql and add the following code to the file:
Then, submit this query to the cluster by running the following query:
Submit Presto SQL queries using Jupyter Notebooks
Using Dataproc Hub or the Jupyter optional component, with ipython-sql, you can execute Presto SQL queries from a Jupyter Notebook. In the first cell of your notebook, run the following command:
Now, run ad hoc Presto SQL queries from your notebook:
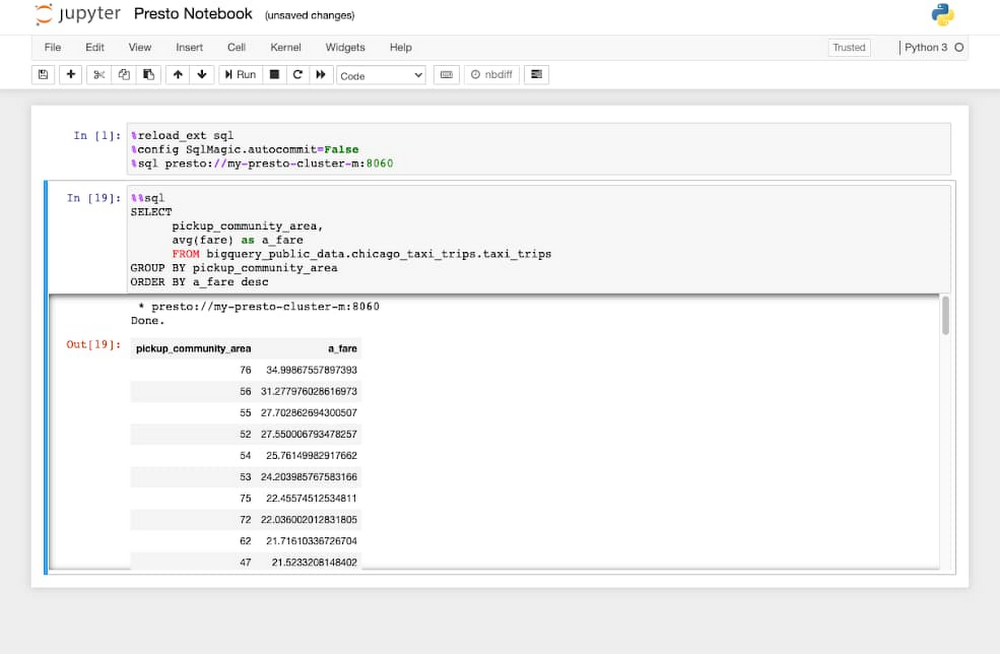
Access the Presto UI directly from the Cloud Console
You can now access the Presto UI without needing to SSH into the cluster, thanks to Component Gateway, which creates a link that you can access from the cluster page in Cloud Console. With the Presto UI, you can monitor the status of your collaborators and workers, as well as the status of your Presto jobs.
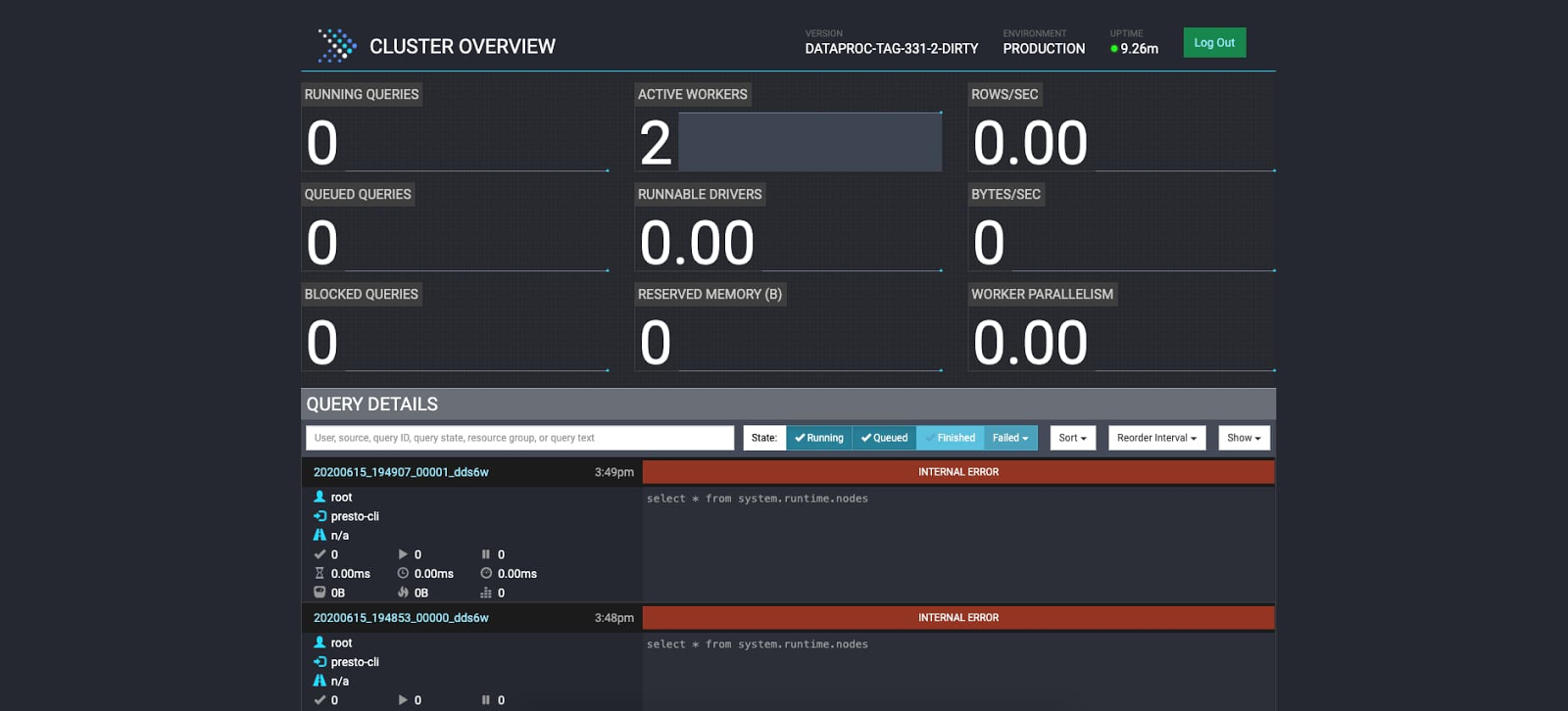
Logging, monitoring and diagnostic tarball integrations
Presto jobs are now integrated into Cloud Monitoring and Cloud Logging to better track their status.
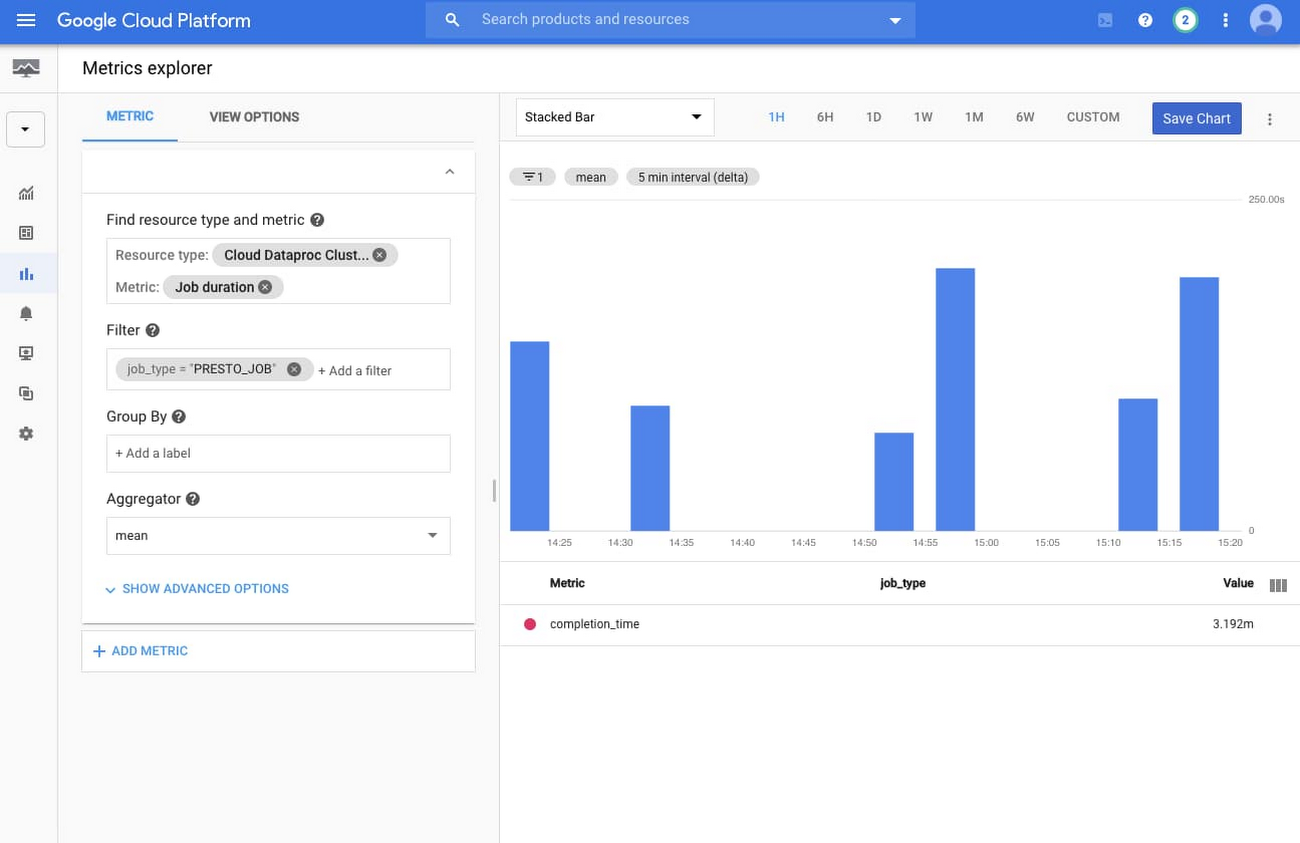
By default, Presto job information is not shown in the main cluster monitoring page for Dataproc clusters. However, you can easily create a new dashboard using Cloud Monitoring and the metrics explorer.
To create a chart for all Presto jobs on your cluster, select the resource type Cloud Dataproc Cluster and metric Job duration. Then apply the filter to only show job_type = PRESTO_JOB and use the aggregator mean.
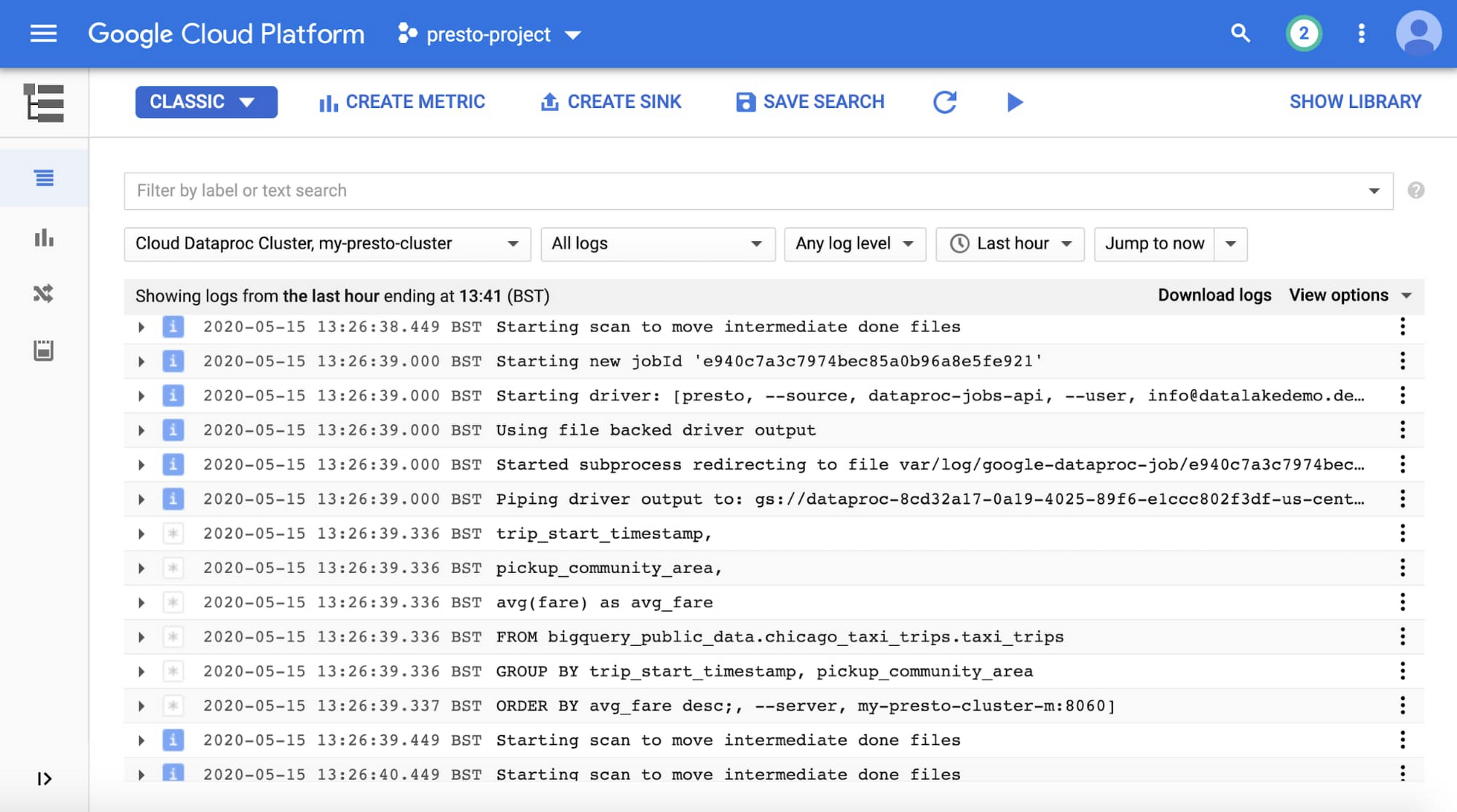
In addition to Cloud Monitoring, Presto server and job logs are available in Cloud Logging, as shown here:
Last, Presto config and log information will also now come bundled in your Dataproc diagnostic tarball. You can download this by running the following command:
To get started with Presto on Cloud Dataproc, check out this tutorial on using Presto with Cloud Dataproc. And use the Presto optional component to create your first Presto on Dataproc cluster.


