BigQuery explained: An overview of BigQuery's architecture
Rajesh Thallam
Solutions Architect, Generative AI Solutions
Google BigQuery was released to general availability in 2011 and is Google Cloud's enterprise data warehouse designed for business agility. Its serverless architecture allows it to operate at scale and speed to provide incredibly fast SQL analytics over large datasets. Since its inception, numerous features and improvements have been made to improve performance, security, reliability, and making it easier for users to discover insights.
In this first post, we will look at how data warehouses change business decision making, how BigQuery solves problems with traditional data warehouses, and dive into a high-level overview of BigQuery architecture and how to quickly get started with BigQuery.
How does a Data Warehouse drive business decisions?
A data warehouse consolidates data from disparate sources and performs analytics on the aggregated data to add value into the business operations by providing insights. Data warehouses are the custodians of the most important business data in the enterprise for the last two decades. As enterprises are increasingly becoming data driven, data warehouses play an increasingly critical role in their digital transformation journey. As per Gartner, data warehouses often form the foundation of enterprises analytics strategy. Data warehouse use-cases have gone beyond traditional operational reporting. Today, enterprises need to:
- Have a 360⁰ view of their businesses: Data is valuable. As cost of storage and data processing reduce, enterprises want to process, store, and analyze all relevant datasets, both internal and external to their organization.
- Be situationally aware of and responsive to real-time business events: Enterprises need to gain insights from real time events and not wait for days or weeks to analyze data. The data warehouse needs to reflect the present state of business at all times
- Reduce time to insights: Enterprises need to get up and running fast without waiting days or months. for hardware or software to be installed or configured.
- Make insights available to business users to enable data driven decision making across the enterprise: In order to embrace a data-driven culture, enterprises need to democratize access to data.
- Secure their data and govern its use: Data needs to be secure and accessible to the right stakeholders inside and outside of the enterprise.
As enterprises look to expand their usage of the traditional data warehouses with growing data volumes, they face tremendous challenges as their cost continues to spiral out of control due to higher TCO (Total Cost of Ownership). Traditional data warehouses were not designed to handle the explosive growth in data and certainly not built for emerging data processing patterns.
BigQuery—Cloud Data Warehouse
Google BigQuery was designed as a “cloud-native" data warehouse. It was built to address the needs of data driven organizations in a cloud first world.
BigQuery is GCP’s serverless, highly scalable, and cost effective cloud data warehouse. It allows for super-fast queries at petabyte scale using the processing power of Google’s infrastructure. Because there’s no infrastructure for customers to manage, they can focus on uncovering meaningful insights using familiar SQL without the need for a database administrator. It’s also economical because they pay only for the processing and storage they use.
Where does BigQuery fit in the data lifecycle?
BigQuery is part of Google Cloud’s comprehensive data analytics platform that covers the entire analytics value chain including ingesting, processing, and storing data, followed by advanced analytics and collaboration. BigQuery is deeply integrated with GCP analytical and data processing offerings, allowing customers to set up an enterprise ready cloud-native data warehouse.
At each stage of the data lifecycle, GCP provides multiple services to manage data. This means customers can select a set of services tailored to their data and workflow.

Ingesting data into BigQuery
BigQuery supports several ways to ingest data into its managed storage. The specific ingestion method depends on the origin of the data. For example, some data sources in GCP, like Cloud Logging and Google Analytics, support direct exports to BigQuery.
BigQuery Data Transfer Service enables data transfer to BigQuery from Google SaaS apps (Google Ads, Cloud Storage), Amazon S3, and other data warehouses (Teradata, Redshift).
Streaming data, such as logs or IoT device data, can be written to BigQuery using Cloud Dataflow pipelines, Cloud Dataproc jobs, or directly using the BigQuery stream ingestion API.
BigQuery Architecture
BigQuery’s serverless architecture decouples storage and compute and allows them to scale independently on demand. This structure offers both immense flexibility and cost controls for customers because they don’t need to keep their expensive compute resources up and running all the time. This is very different from traditional node-based cloud data warehouse solutions or on-premise massively parallel processing (MPP) systems. This approach also allows customers of any size to bring their data into the data warehouse and start analyzing their data using Standard SQL without worrying about database operations and system engineering.
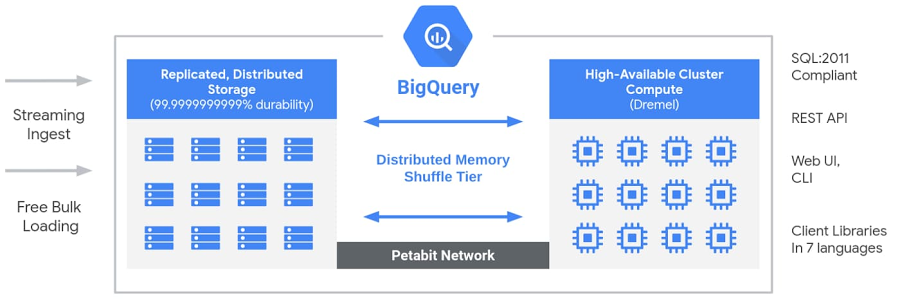
BigQuery Architecture
Under the hood, BigQuery employs a vast set of multi-tenant services driven by low-level Google infrastructure technologies like Dremel, Colossus, Jupiter and Borg.
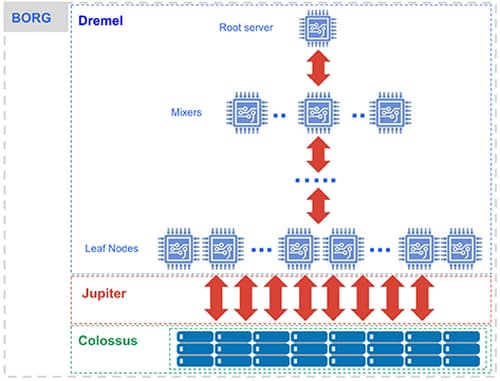
BigQuery: Under the hood [source]

Compute is Dremel, a large multi-tenant cluster that executes SQL queries.
- Dremel turns SQL queries into execution trees. The leaves of the tree are called slots and do the heavy lifting of reading data from storage and any necessary computation. The branches of the tree are ‘mixers’, which perform the aggregation.
- Dremel dynamically apportions slots to queries on an as-needed basis, maintaining fairness for concurrent queries from multiple users. A single user can get thousands of slots to run their queries.
Storage is Colossus, Google’s global storage system.
- BigQuery leverages the columnar storage format and compression algorithm to store data in Colossus, optimized for reading large amounts of structured data.
- Colossus also handles replication, recovery (when disks crash) and distributed management (so there is no single point of failure). Colossus allows BigQuery users to scale to dozens of petabytes of data stored seamlessly, without paying the penalty of attaching much more expensive compute resources as in traditional data warehouses.
Compute and storage talk to each other through the petabit Jupiter network.
- In between storage and compute is ‘shuffle’, which takes advantage of Google’s Jupiter network to move data extremely rapidly from one place to another.
BigQuery is orchestrated via Borg, Google’s precursor to Kubernetes.
- The mixers and slots are all run by Borg, which allocates hardware resources.
There’s great emphasis at Google on continuously making these technologies better. BigQuery users get the benefit of continuous improvements in performance, durability, efficiency, and scalability, without downtime and upgrades associated with traditional technologies. If you’re interested in more details on BigQuery architecture, look at this article for a more complete topological map of BigQuery.
How can you get started with BigQuery?
You can start using BigQuery simply by loading data and running SQL commands. There’s no need to build, deploy, or provision clusters; no need to size VMs, storage, or hardware resources; no need to setup disks, define replication, configure compression and encryption, or any other setup or configuration work necessary to build a traditional data warehouse..
To help you get started with BigQuery, BigQuery sandbox gives you free access to the power of BigQuery, which offers free 10GB of storage and 1TB per month of query data analyzed. Watch this episode of BigQuery Spotlight to see how to set up a BigQuery sandbox, allowing you to run queries without needing a credit card.

BigQuery Spotlight: Using the BigQuery Sandbox
You can access BigQuery in multiple ways:
- Using the GCP console
- Using the command line tool
bq - Making calls to the BigQuery REST API
- Using the variety of client libraries such as Java, .NET or Python
Let’s try it out now. Navigate to BigQuery web UI on Google Cloud Console, copy and paste the following query, and then hit the “Run” button.
The query processes ~30GB of StackOverflow posts available from 2008 to 2016 in public BigQuery datasets, to find the number of posts with at least one answer posted, grouped by year and month.
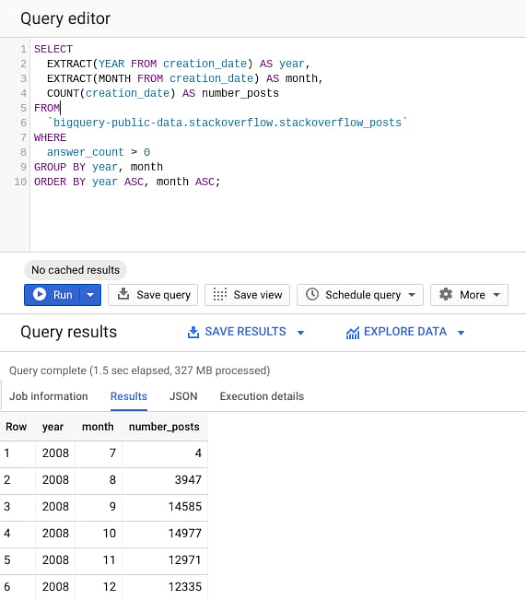
As evident from the query results, it takes less than 2s to analyze 28GB of data and return the results. BigQuery engine is smart to read only the columns required to execute the query and process only 327MB of data out of the entire 28GB dataset.
Users are able to seamlessly scale to dozens of petabytes because BigQuery engineers have already deployed the resources required to reach this scale. Therefore, scaling is simply a matter of using BigQuery more, rather than provisioning larger clusters. Of course, you need to keep the best practices and usage quotas in mind, and we will discuss these later in this series.
Using BigQuery with large datasets
For a demo of what BigQuery can do with a really large dataset, watch this talk by Jordan Tigani analyzing ~1PB dataset in BigQuery within a few seconds, with the improvements made over the years to improve BigQuery performance.

Modern Data Warehousing with BigQuery (Cloud Next '19)
What’s Next?
In this article, we reviewed where BigQuery fits in the data lifecycle, what makes BigQuery fast and scalable, and how to get started with BigQuery.
- Get started with the BigQuery sandbox
- Try this codelab with your BigQuery Sandbox to query github data using BigQuery
In this upcoming series of posts, we will look at the BigQuery storage and ingestion options, basic and advanced querying, visualizing query results, securing your data, managing costs and BigQuery best practices for optimization and performance along with new BigQuery features.
Stay tuned. Thank you for reading! Have a question or want to chat? Find me on Twitter or LinkedIn.
Thanks to Yuri Grinshsteyn and Alicia Williams for helping with the post.
The complete BigQuery Explained series
- BigQuery explained: An overview of BigQuery's architecture
- BigQuery explained: Storage overview, and how to partition and cluster your data for optimal performance
- BigQuery explained: How to ingest data into BigQuery so you can analyze it
- BigQuery explained: How to query your data
- BigQuery explained: Working with joins, nested & repeated data
- BigQuery explained: How to run data manipulation statements to add, modify and delete data stored in BigQuery



