How Grasshopper uses BigQuery and Cloud Dataflow for their real-time financial data app
Reza Rokni
Senior Developer Advocate, Dataflow
Sachar de Vries
Head of Infrastructure at Grasshopper
For the past year, we’ve been working with Grasshopper, a proprietary trading firm based in Singapore, to scale its custom-built data processing platform. Grasshopper’s technology powers their use of time-series data in financial markets, providing information to evaluate liquidity or liquidity risks in those markets. The firm uses Google Cloud Platform (GCP) extensively to store, process and analyze large volumes of real-time market and trading data globally. It specifically uses BigQuery and Cloud Dataflow to make near real-time trading decisions and develop trading strategies. Solace PubSub+ event brokers move events dynamically and in real time, to and from BigQuery via Cloud Dataflow.
Grasshopper’s primary goal in adopting GCP was to improve and scale its quantitative research capabilities by creating a research infrastructure accessible to team members that doesn’t limit their work. The firm needed reliable, accurate and stable data processing pipelines.
Grasshopper’s small team has to use technology strategically. Grasshopper designed Ahab, an Apache Beam-based Java application, as a high-performance data processing pipeline that uses real-time market data to calculate the value of the order book—a dynamic list of buy and sell orders that dictates stock pricing—from real-time market data received from multiple stock exchanges. The order book is the foundation for many trading and analytics applications. Ahab then ingests the end result to BigQuery, GCP’s fully managed data processing and analysis tool, utilizing the tool’s availability and scalability.
Before Ahab, Grasshopper relied on a solution developed in-house on Cassandra. The operational burden to maintain this technology stack, add new features and scale fast enough to meet future needs was extremely difficult to manage, particularly without a dedicated team to handle both the required infrastructure and applications. Grasshopper shifted to GCP to design and build Ahab, allowing the firm’s data engineering team to focus on data science rather than infrastructure maintenance.
Grasshopper’s quantitative analysts (known as quants) rely on the ability to process huge amounts of data in a precise and accurate way, to interact with rapidly changing financial markets. This allows for their trading research platforms to scale according to market conditions. For example, when markets are more volatile and produce more market data, the analysts have to be able to adjust accordingly. This solution allows the team to know that the data is reliable, correct and scalable, without having to worry about capacity or performance limitations.
Grasshopper’s team built Ahab to meet several goals:
To transport data from its on-premises environment to GCP;
To persist the vast volumes of market data received into BigQuery in query-able form so that Grasshopper’s traders can analyze and transform the data based on their needs;
To confirm the feasibility of using Apache Beam to calculate the order books in real time and store them on a daily basis from financial market data feeds; and
Ultimately, to allow traders to improve their probability of success when the strategies are deployed.
Here’s an overview of how Ahab works to gather and process data:
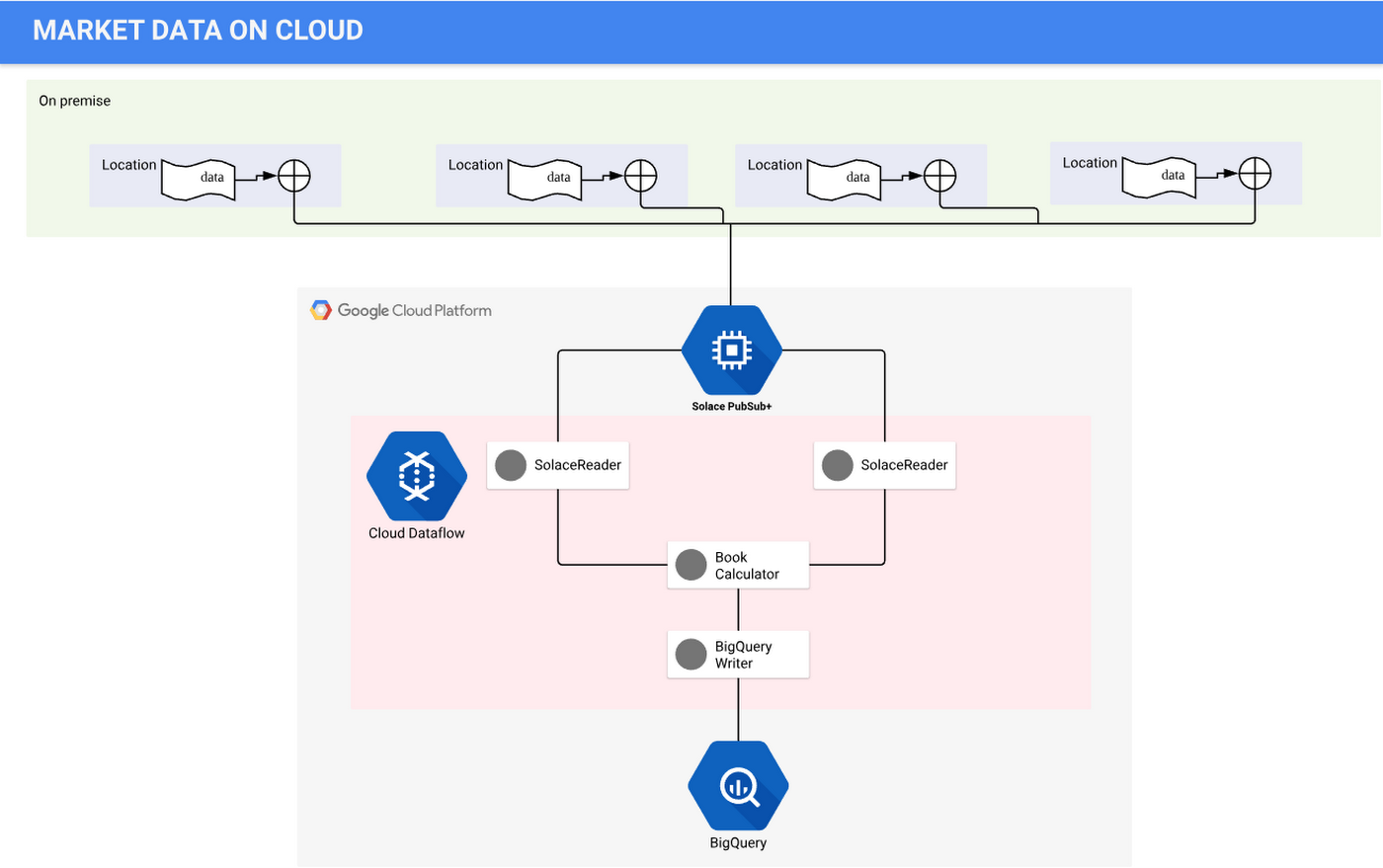
Gathering source data from financial markets
Grasshopper uses data sourced from its co-located environment, where the stock exchange allocates rack space so financial companies can connect to that platform in the most efficient, lowest-latency way. Grasshopper has been using Solace PubSub+ appliances at the co-located data centers for low-latency messaging in the trading platform. Solace PubSub+ software running in GCP natively bridges the on-premises Solace environment and the GCP project. Market data and other events are bridged from on-premises Solace appliances to Solace PubSub+ event brokers running in GCP as a lossless, compressed stream. Some event brokers are on-premises, while others are on GCP, creating a hybrid cloud event mesh and allowing orders published to the on-prem brokers to flow easily to the Solace cloud brokers. The SolaceIO connector consumes this market data stream and makes it available for further processing with Apache Beam running in Cloud Dataflow. The processed data can be ingested into Cloud Bigtable, BigQuery and other destinations, processing in a pub/sub manner.
The financial market data arrives into Grasshopper’s environment in the form of deltas, which represent updates to an existing order book. Data needs to be processed in sequence for any given symbol, which requires using some advanced functions in Apache Beam, including keyed state and timers.
This financial data comes with specific financial industry processing requirements:
- Data updates must be processed in the correct order and processing for each instrument is independent.
- If there is a gap in the deltas, a request must be sent to the data provider to provide a snapshot, which represents the whole state of an order book.
- Deltas must meanwhile be queued while Ahab waits for the snapshot response.
- Ahab also needs to produce its own regular snapshots so that clients can query the state of the order book at any time in the middle of the day without applying all deltas since the start-of-day snapshot. To do this, it needs to keep track of the book state.
- The data provider needs to be monitored so that connections to it and subscriptions to real-time streams of market data can be refreshed if necessary.
How Grasshopper’s financial data pipeline works
There are two important components to processing this financial data: reading data from the source and using stateful data processing.
Reading data from the source
Grasshopper uses SolaceIO, an Apache Beam read connector, as the messaging bus for market data publication and subscriptions. The team at Grasshopper uses Solace topics streaming into Solace queues to ensure that no deltas are lost and no gaps occur. Queues (and topics) provide guaranteed delivery semantics, such that if message consumers are slow or down, Solace stores the messages till the consumers are online, and delivers the messages to the available consumers. The SolaceIO code uses checkpoint marks to ensure that messages in the queues transition from Solace to Beam in a guaranteed delivery and fault-tolerant manner—with Solace waiting for message acknowledgements before deleting them. Replay is also supported when required.
Using stateful data processing
Grasshopper uses stateful processing to keep an order book's state for the purpose of snapshot production. The firm uses timely processing to schedule snapshot production and to also check data provider availability. One of this project’s more challenging areas was retaining the state of the market financial instrument across time window boundaries.
The keyed state API in Apache Beam let Grasshopper’s team store information for an instrument within a fixed window, also known as a keyed-window state. However, data for the instruments needs to propagate forward to the next window. Our Cloud Dataflow team worked closely with Grasshopper’s team to implement a workflow that let it have the fixed time windows flow into a global window and makes use of the timer API to ensure the Grasshopper team retained the necessary data order.
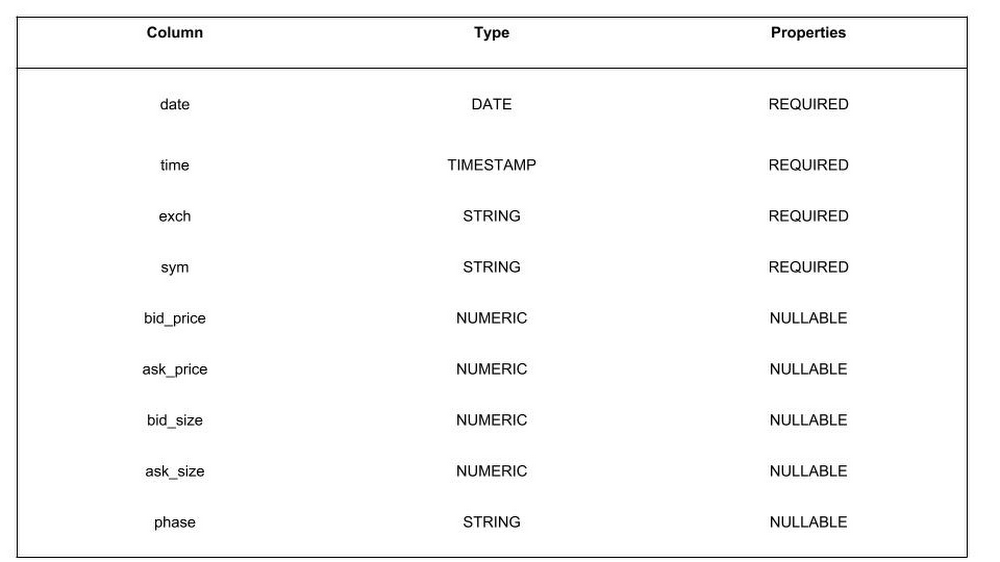
The data processed with Apache Beam is written to BigQuery in day-partitioned tables, which can then be used for further analysis. Here’s a look at some sample data:
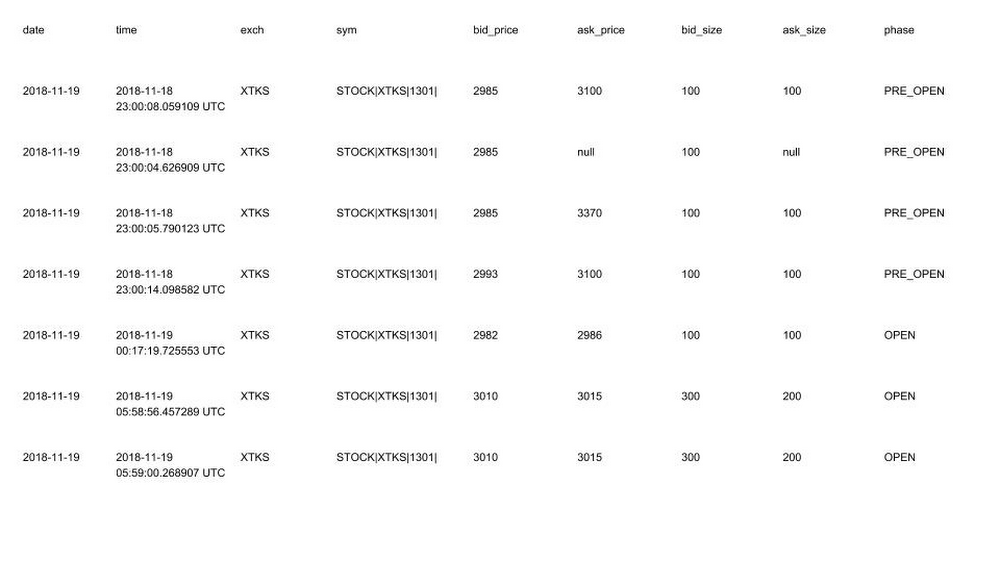
Sample user acceptance testing data:
For deployment and scheduling, Grasshopper uses Docker and Google Cloud Repositories to build, deploy and run the Cloud Dataflow jobs, using Nomad for job scheduling. The firm is also in the process of experimenting with Beam templates as an alternate deployment method.
Tips for building fast data processing pipelines
Throughout the process of building the Ahab application, Grasshopper’s team learned some valuable lessons. Here are some tips:
- Increase throughput by dividing up topic subscriptions across more queues and more SolaceIO sources. Dataflow will also spin up more resources with its auto-scaling feature when needed.
- Use available tools to track the order book status. Since keyed state in Beam aligns to the “group by” key (in this case, the instrument), and window of time, Grasshopper uses the global window to keep track of the order book state. Employ panes to trigger incremental processing of deltas; use a bag state plus sorting to deal with out-of-order arrival of deltas within panes when in the global window.
- Rely on templates to separate pipeline graph construction and execution, simplifying deployment. Apache Beam’s ValueProvider isn’t an applicative functor; Grasshopper had to write its own implementation to combine multiple ValueProviders.
- Include all the data you need up front, as display data is set at pipeline construction time and cannot be deferred.
- Co-locate the Cloud Dataflow job coordinator and those teams working on the data pipeline in order to improve throughput, since watermark processing is centralized. Watermarks provide the foundation for enabling streaming systems to emit timely, correct results when processing data.
- Generate BigQuery schemas automatically with protocol buffers.
- Use class variables with get-or-init to share connections across Apache Beam PTransform bundles and even across different instances in the same Java VM. Interesting annotations include DoFn.Setup, DoFn.StartBundle.
- Note that fusion, an optimization technique, can lead sources to fuse with downstream transforms, delaying checkpoint mark finalization. Try GroupByKey to prevent fusion.
- Use a counting source to trigger some pipeline setup work.
These tools have helped Grasshopper researchers think big about their data possibilities. “Grasshopper researchers’ imaginations aren’t limited by what the infrastructure can do. We’ve resolved their data reliability, data accuracy and stability issues by using GCP,” says Tan T. Kiang, Grasshopper’s CTO. “Internal users can now all work with this data with the knowledge that it’s reliable and correct.”
To learn more, check out this example of how to spin up a GCP environment with SolaceIO and Cloud Dataflow. Learn more about using GCP for data analytics.



