What makes TPUs fine-tuned for deep learning?
Kaz Sato
Developer Advocate, Google Cloud
The Tensor Processing Unit (TPU) is a custom ASIC chip—designed from the ground up by Google for machine learning workloads—that powers several of Google's major products including Translate, Photos, Search Assistant and Gmail. Cloud TPU provides the benefit of the TPU as a scalable and easy-to-use cloud computing resource to all developers and data scientists running cutting-edge ML models on Google Cloud. At Google Next ‘18, the most recent installment of our annual conference, we announced that Cloud TPU v2 is now generally available (GA) for all users, including free trial accounts, and the Cloud TPU v3 is available in alpha.
But many people ask me "what's the difference between a CPU, a GPU, and a TPU?" So we've created a demo site that is home to a presentation and animation that answer this question.
In this post, I'd like to highlight some specific parts of the site’s content.
How neural networks work
Before we start comparing CPU, GPU, and TPU, let's see what kind of calculation is required for machine learning—specifically, neural networks.
For example, imagine that we're using single layer neural network for recognizing a hand-written digit image, as shown in the following diagram:
If an image is a grid of 28 x 28 grayscale pixels, it could be converted to a vector with 784 values (dimensions). The neuron that recognizes a digit "8" takes those values and multiply by the parameter values (the red lines above).
The parameter works as "a filter" to extract a feature from the data that tells the similarity between the image and shape of "8", just like this:
This is the most basic explanation of data classification by neural network. Multiplying data by their respective parameters (the coloring of dots above), and adding them all (the collected dots at right). If you get the highest result, you found the best match between input data and its corresponding parameter, and it's most likely the correct answer.
In short, neural networks require massive amount of multiplications and additions between data and parameters. We often organize these multiplications and additions into a matrix multiplication, which you might have encountered in high-school algebra. So the problem is how you can execute large matrix multiplication as fast as possible with less power consumption.
How a CPU works
So, how does a CPU approach this task? The CPU is a general purpose processor based on the von Neumann architecture. That means a CPU works with software and memory, like this:
The greatest benefit of CPU is its flexibility. With its Von Neumann architecture, you can load any kind of software for millions of different applications. You could use a CPU for word processing in a PC, controlling rocket engines, executing bank transactions, or classifying images with a neural network.
But, because the CPU is so flexible, the hardware doesn't always know what would be next calculation until it reads the next instruction from the software. A CPU has to store the calculation results on memory inside CPU (so called registers or L1 cache) for every single calculation. This memory access becomes the downside of CPU architecture called the von Neumann bottleneck. Even though the huge scale of neural network calculations means that these future steps are entirely predictable, each CPU's Arithmetic Logic Units (ALU, the component that holds and controls multipliers and adders) executes them one by one, accessing the memory every time, limiting the total throughput and consuming significant energy.
How a GPU works
To gain higher throughput than a CPU, a GPU uses a simple strategy: why not have thousands of ALUs in a processor? The modern GPU usually has 2,500–5,000 ALUs in a single processor that means you could execute thousands of multiplications and additions simultaneously.
This GPU architecture works well on applications with massive parallelism, such as matrix multiplication in a neural network. Actually, you would see order of magnitude higher throughput than CPU on typical training workload for deep learning. This is why the GPU is the most popular processor architecture used in deep learning at time of writing.
But, the GPU is still a general purpose processor that has to support millions of different applications and software. This leads back to our fundamental problem, the von Neumann bottleneck. For every single calculation in the thousands of ALUs, GPU need to access registers or shared memory to read and store the intermediate calculation results. Because the GPU performs more parallel calculations on its thousands of ALUs, it also spends proportionally more energy accessing memory and also increases footprint of GPU for complex wiring.
How a TPU works
When Google designed the TPU, we built a domain-specific architecture. That means, instead of designing a general purpose processor, we designed it as a matrix processor specialized for neural network work loads. TPUs can't run word processors, control rocket engines, or execute bank transactions, but they can handle the massive multiplications and additions for neural networks, at blazingly fast speeds while consuming much less power and inside a smaller physical footprint.
The key enabler is a major reduction of the von Neumann bottleneck. Because the primary task for this processor is matrix processing, hardware designer of the TPU knew every calculation step to perform that operation. So they were able to place thousands of multipliers and adders and connect them to each other directly to form a large physical matrix of those operators. This is called systolic array architecture. In case of Cloud TPU v2, there are two systolic arrays of 128 x 128, aggregating 32,768 ALUs for 16 bit floating point values in a single processor.
Let's see how a systolic array executes the neural network calculations. At first, TPU loads the parameters from memory into the matrix of multipliers and adders.
Then, the TPU loads data from memory. As each multiplication is executed, the result will be passed to next multipliers while taking summation at the same time. So the output will be the summation of all multiplication result between data and parameters. During the whole process of massive calculations and data passing, no memory access is required at all.
This is why the TPU can achieve a high computational throughput on neural network calculations with much less power consumption and smaller footprint.
The benefit: the cost reduces to one fifth
So what's the benefit you could get with this TPU architecture? The answer is cost. The following is the pricing of Cloud TPU v2 in August 2018, at the time of writing:
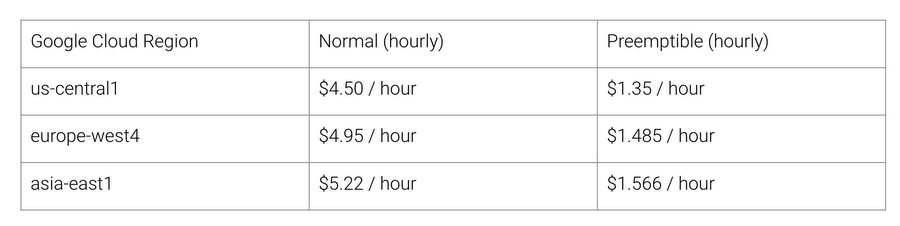
Cloud TPU v2 pricing, as of August, 2018
Stanford University publishes DAWNBench, which is a benchmark suite for deep learning training and inference. You can find various different combinations of tasks, models, and computing platforms and their respective benchmark results.
At the time DAWNBench contest closed on April 2018, the lowest training cost by non-TPU processors was $72.40 (for training ResNet-50 at 93% accuracy with ImageNet using spot instance). With Cloud TPU v2 pre-emptible pricing, you can finish the same training at $12.87. It's less than 1/5th of non-TPU cost. This is the power of domain specific architecture for neural network.
Learn more
Interested in Cloud TPU? Please go to cloud.google.com/tpu to try it today.
Acknowledgements
Special thanks to BIRDMAN who authored the awesome animations. Also, thanks to Zak Stone and Cliff Young for valuable feedback on this content.