Now you can train TensorFlow machine learning models faster and at lower cost on Cloud TPU Pods

Zak Stone
Senior Product Manager for Cloud TPUs, Google Brain Team
Data scientists, machine learning (ML) engineers, and ML researchers can’t be maximally productive if they have to wait days or weeks for their model training runs to complete.
The MLPerf benchmarking effort measures the time it takes for common ML problems to train to a given accuracy, and we contributed both GPU and TPU submissions to MLPerf 0.5, the initial version of this industry-wide benchmark contest. However, real-world ML challenges are much larger than the current MLPerf training tasks, so MLPerf does not yet reflect the systems' performance on very large problems.
As a case study that we believe is more representative of ML training performance in larger-scale settings, we train ResNet-50 v1.5, one of the MLPerf models, on the well-known ImageNet image classification dataset, but we focus on the steady-state training performance observed when processing a much larger collection of images. We have seen broadly similar scaling performance in other ML application domains, including machine translation, speech recognition, language modeling, GAN training, reinforcement learning, etc.
Performance comparison
GCP provides a full spectrum of machine learning accelerators, and here we focus on Cloud TPU Pods and on Google Cloud VMs with NVIDIA Tesla V100 GPUs attached. Cloud TPU Pods, now available in alpha, are tightly-coupled supercomputers built with hundreds of Google’s custom Tensor Processing Unit (TPU) chips and dozens of host machines, all linked via an ultrafast custom interconnect.
To ensure that anyone can fully reproduce the results described below today, we use well-optimized, open-source TensorFlow 1.12 implementations of ResNet-50 v1.5 (GPU version, TPU version). To simulate a larger-scale ML training scenario (imagine eBay training on tens or hundreds of millions of product images), we run a warm-up epoch on both the GPU and TPU systems before starting our measurements; this excludes one-time setup costs and evaluation costs and ensures that caches are fully filled. All of the systems shown train ResNet-50 to the same quality score of 76% top-1 accuracy. Further details are available on our methodology page.
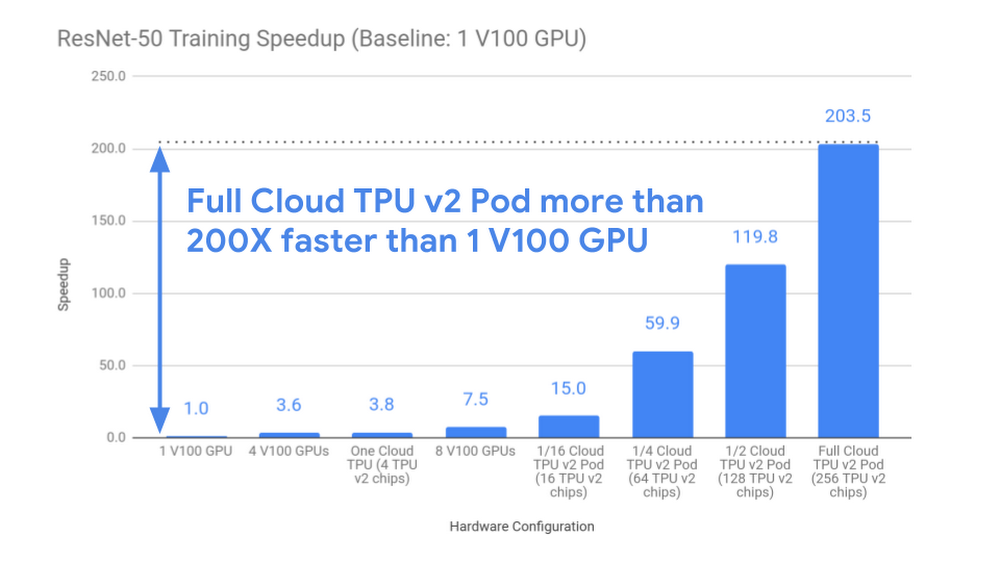
Our results demonstrate that Cloud TPU Pods deliver near-linear speedups for this large-scale training task; the largest Cloud TPU Pod configuration tested (256 chips) delivers a 200X speedup over an individual V100 GPU (see chart below). So instead of waiting for more than 26 hours if you used a single state-of-the-art GPU, a full Cloud TPU v2 pod delivers the same result in 7.9 minutes of training time.
Cost comparison
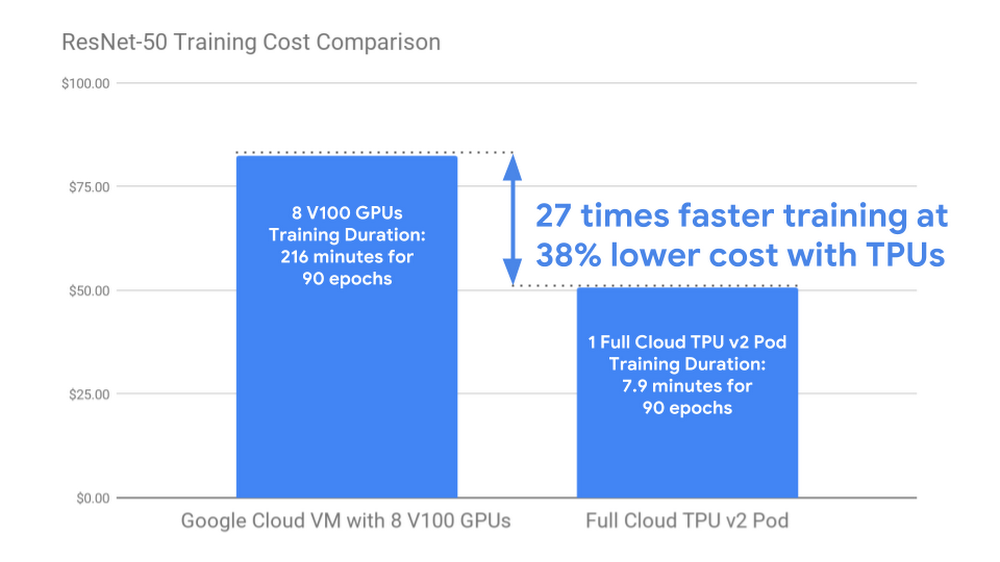
Reducing the cost of ML training enables a broader group of ML practitioners to explore a wider range of model architectures and hyperparameters and to train cutting-edge ML models on larger, more representative datasets. As shown below, training ResNet-50 on a full Cloud TPU v2 Pod costs almost 40% less than training the same model to the same accuracy on an n1-standard-64 Google Cloud VM with eight V100 GPUs attached. On top of those savings, the full Cloud TPU Pod completes the training task 27 times faster.
Qualitative takeaways
Cloud TPUs were designed from the ground up for machine learning. Cloud TPUs excel at synchronous training, which makes it much easier to reproduce results during model development, and the Cloud TPU software stack transparently distributes ML models across multiple TPU devices in a Cloud TPU Pod to help you scale. Furthermore, all Cloud TPUs are integrated with Google Cloud’s high-speed storage systems to ensure that data input pipelines can keep up with the TPUs. There’s no need to manage parameter servers, deal with complicated custom networking configurations, or set up exotic storage systems to achieve unparalleled training performance in the cloud. The same code that runs on a single Cloud TPU can run on a full pod or on mid-sized “slices” in between.
Cloud TPU Pods take us one step closer to our goal of making high-performance machine learning more interactive and accessible for everyone. You can iterate in minutes and train ultralarge production models in hours or days instead of weeks. As a result, Cloud TPUs make it easier, faster, and more cost-effective to develop and deploy cutting-edge machine learning models.
Getting started
You can get started with Cloud TPUs by following our quickstart guide, and you can also request access to the Cloud TPU Pods that are available in alpha today. For more guidance on determining whether to try out an individual Cloud TPU or an entire Cloud TPU Pod, check out our documentation here.