Enhanced models and features now available in new languages on Speech-to-Text
Calum Barnes
Product Manager, Cloud Speech
From call analytics to automated video subtitles, speech interfaces are changing the way people interact with their surroundings and enabling new business opportunities. Speech recognition technology is at the heart of these transformations and is bringing these ideas to life.
At Google Cloud, we’re committed to ensuring that this exciting technology is as inclusive as possible. With that in mind, we’re announcing new features, models, and languages for our speech-to-text system as we strive to make our products and features more widely available and useful for more organizations across the globe.
Google Cloud Speech-to-Text is an API that allows users to submit short, long, or streaming audio that contains speech and receive back the transcription. We have long been recognized for our industry-leading speech recognition quality, and our capabilities power thousands of different solutions, including Contact Center AI and Video Transcription.
Our updates include seven brand new languages, expansion of the enhanced telephony model to three new locales, speech adaptation for 68 new locales, speaker diarization to 10 new locales, and automatic punctuation to 18 new locales. These advancements bring our speech technology to over 200 million speakers for the first time, and unlock additional features and improve accuracy for more than 3 billion speakers globally.
Expanding language support
Since introducing Speech-to-Text, we have continuously strived to bring high-quality speech recognition to more languages. Today, we are expanding the wide array of supported languages from 64 to 71 (120 to 127 in total locales) with seven new languages: Burmese, Estonian, Uzbek, Punjabi, Albanian, Macedonian, and Mongolian.

Sourcenext, the maker of portable voice translator Pocketalk, is one of the organizations taking advantage of Google Cloud Speech-to-Text’s comprehensive language support.
“The extensive language capabilities of Google Cloud Speech-to-Text has made our product, Pocketalk, possible,” said Hajime Kawatake, Operating Officer, Technology Strategy, Sourcenext Corporation. “The sheer breadth of languages offered increases the quality of product as our customers are able to receive the highly accurate and reliable speech to speech translations anywhere in the world.”
Enhanced telephony models
In April 2018, Google launched the enhanced telephony model for US English to provide the highest quality transcription for customers with less than pristine audio data from phone and video calls. At the time, it performed 62% better on telephony than our base models, and now it’s helping Contact Center AI transform call center experiences for customers and agents. Today, Speech-to-Text is releasing support for three new locales: UK English, Russian, and US Spanish.

One of the first users of these features is Voximplant, a cloud communications platform with a number of enterprise customers in Russia, that instantly realized the exceptional accuracy of the new telephony models.
“We partnered with Google Cloud because we wanted to innovate our voice platform with Google’s AI technology,” said Alexey Aylarov, CEO, Voximplant. “Since we often receive audio from low bandwidth telephone networks, the enhanced telephony models have been a game-changer, delivering increased accuracy in both person-to-person and person-to-virtual agent conversations. We are delighted to see Google Cloud’s commitment to bringing high-quality models to even more users and locales.”
Speech adaptation
Speech adaptation allows users to customize Google’s powerful pre-built speech models in real time. With speech adaptation, you can do things like recognize proper nouns or specific product names. You can also give the API hints about how it wants information returned, greatly improving the quality of speech recognition for their specific use cases.
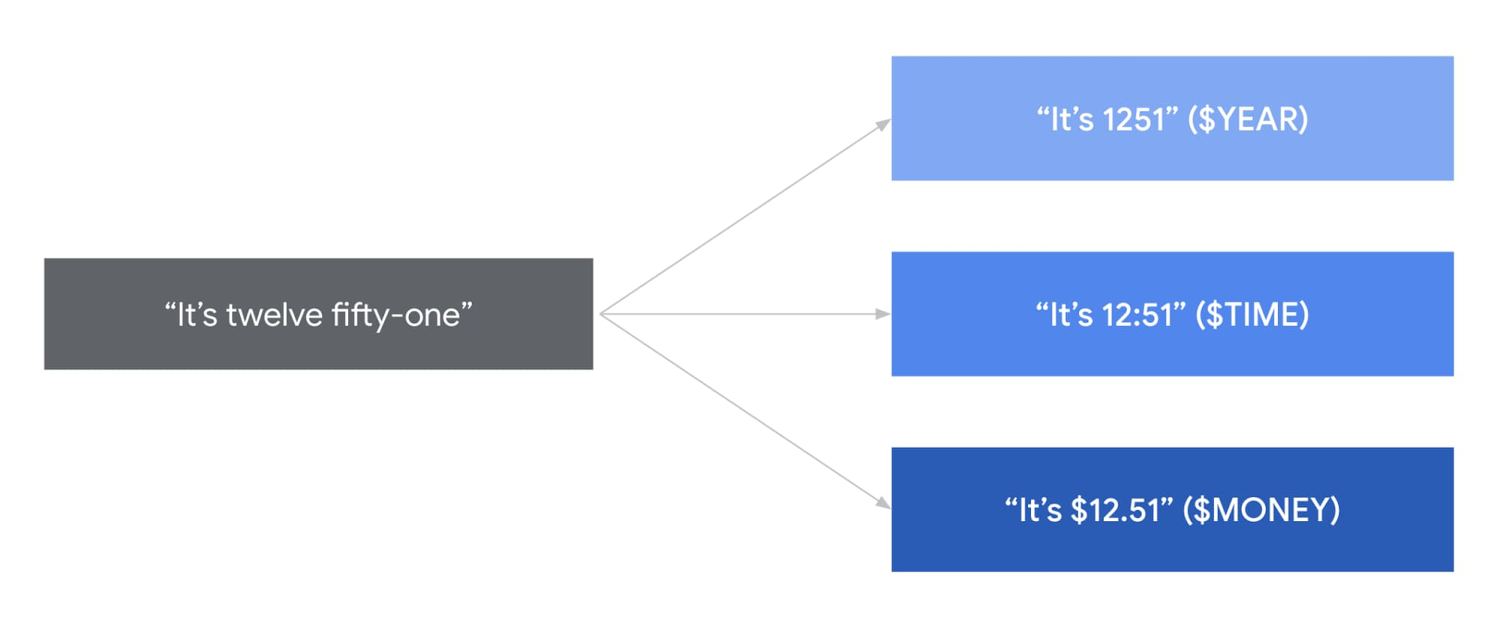
Today we’re making our latest evolution of this technology, boost based speech adaptation, available in 68 new locales. Boosting gives users granular control over how much to influence the speech model towards their most important terms. We’re also adding more of our popular numeric classes in a number of new languages. To see what classes are supported in each language, take a look at our class support documentation. Boost based adaptation is available in 68 new locales:
French
German
Spanish
Japanese
Mandarin
Speaker diarization
Diarization is the ability to automatically attribute individual words and sentences to different speakers in an audio file, allowing users to understand not just what was said but who said it. This helps our users easily add subtitles or captions to audio or video, in addition to many other use cases. Today users can do this in 10 new locales:
UK English
Spanish
Japanese
Mandarin
Automatic punctuation
Punctuation is a key enabler for accurate transcription, helping users increase the accuracy of speech translation in both languages. Automatic punctuation provides users with transcripts that attempt to mimic how a given user might have written down what they said. This helps improve transcript readability and can make dictation a breeze. We’re announcing support in 18 new locales:
German
French
Japanese
Swedish
These new languages and features will help billions of speakers across the world use our voice-based interfaces and high-quality speech recognition. Are you ready to innovate in how you manage speech and transform your organization with Speech-to-Text? Check out our product page or contact sales today.