MLPerf benchmark establishes that Google Cloud offers the most accessible scale for machine learning training

Urs Hölzle
SVP, Cloud Infrastructure
Today marks the debut of the MLPerf 0.5 benchmark results. These tests have been designed, adopted, and promoted by many industry leaders, and the results show Google Cloud’s TPUs (Tensor Processing Units) and TPU Pods as leading systems for training machine learning models at scale, based on competitive performance across several MLPerf tests. Google Cloud customers can easily use Cloud TPUs at accessible prices today.
MLPerf benchmarks measure performance for training workloads across cloud providers and on-premise hardware platforms. MLPerf is designed to establish metrics that help you make informed decisions on how to choose the right infrastructure for your machine learning workloads. Google is a core contributor to the MLPerf benchmark suite, along with many other companies and academic institutions. Each organization conducts its own testing and submits its own results for publication, contributing to a broad survey of machine learning infrastructure available today.
For data scientists, ML practitioners, and researchers, building on-premise GPU clusters for training is capital-intensive and time-consuming—it’s much simpler to access both GPU and TPU infrastructure on Google Cloud. We’re pleased to see that MLPerf benchmark results provide evidence that GCP offers the ideal platform to train machine learning models at any scale.
Understanding the time-to-accuracy results
In our MLPerf submission, we benchmarked accelerators available on our Google Cloud infrastructure, with a focus on our latest Cloud TPUs (versions 2 and 3, both on GCP), and also on our state-of-the-art TPU v3 Pods. We submitted results for ResNet-50, an industry-standard image classification network; NMT, a neural machine translation model; and SSD, a single-shot object detector[1,2,3,4,5,6,7,8,9,10,11,12].
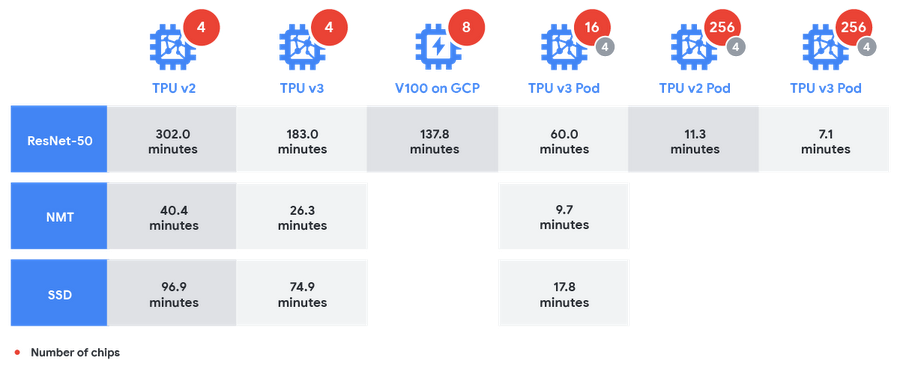
The graphic below shows absolute training times, comparing NVIDIA’s submitted results on a DGX-2 machine (containing 16 V100 GPUs) with results using 1/64th of a TPU v3 Pod (16 TPU v3 chips used for training and 4 TPU v2 chips used for evaluation). The comparison ranges across image classification (ResNet-50), object detection (SSD), and neural machine translation (NMT).
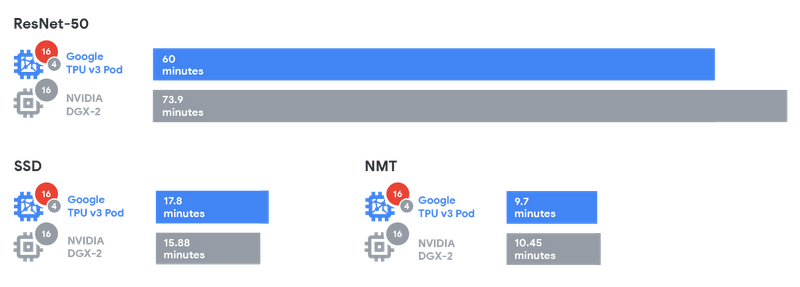
In summary, Google’s Cloud TPUs and TPU Pods deliver always-available, high-performance training across multiple workloads, ranging from image understanding to language translation. For example, it’s possible to achieve a 19% speed-up with a TPU v3 Pod on a chip-to-chip basis versus the current best-in-class on-premise system when tested on ResNet-501.
Making high performance compute accessible to everyone
eBay has been using Cloud TPU Pods for months and has seen a massive reduction in training time:
“An important ML task that took more than 40 days to run on our in-house systems completed in just four days on a fraction of a TPUv2 Pod, a 10X reduction in training time,” explains Shuai Zheng, eBay Research Scientist. “This is a game changer—the dramatic increase in training speed not only allows us to iterate faster but also allows us to avoid large up-front capital expenditures.”
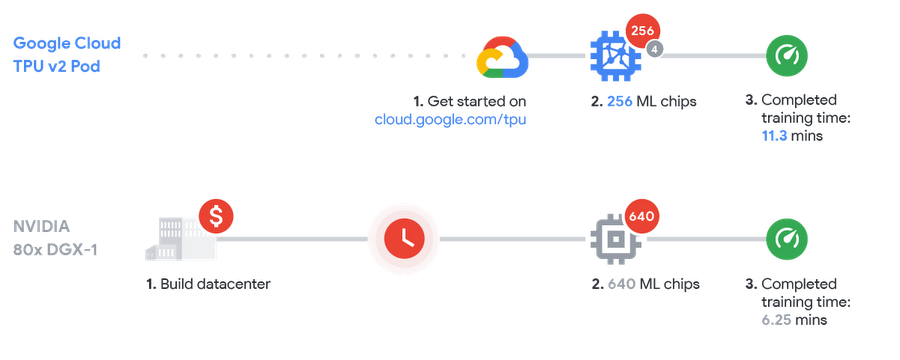
Conclusion
Cloud TPUs and TPU Pods excel at many machine learning training workloads, from image training to language translation. As machine learning continues to become more and more central to their businesses, enterprises are turning to the cloud for the high performance and low cost of training of ML models. The MLPerf results reveal a 19% TPU performance advantage on a chip-to-chip basis, and even greater speedups and cost savings are possible when working with more realistic ML production workloads. For a detailed analysis of performance and cost in a training scenario with much larger inputs than MLPerf uses, see our companion blog post.
Head over to MLPerf.org for the full set of benchmark results. To find out more about Cloud TPUs, read our documentation. You can learn how to get started with individual Cloud TPUs (you can decide between v2 and v3 here), or learn how to use Cloud TPUs via Cloud ML Engine here, or try out Cloud TPUs for free right in your browser using a Colab notebook here.
Cloud TPUv2 Pods are currently available in alpha. If you’re interested in using Cloud TPU Pods, you can request access here.
1. 19% speedup with a 16-chip TPU v3 system compared to the 16-chip DGX-2 on-premise system from NVIDIA.
[*] All results herein are for MLPerf Training v0.5 Closed Division. All results are retrieved from "https://mlperf.org/results" on 12/12/2018. MLPerf is a trademark.
[1] ResNet-50 v1.5 result by Google on TPUv2.8 (4 chips) using TF 1.12. Result id: 0.5.2.1.
[2] SSD result by Google on TPUv2.8 (4 chips) using TF 1.12. Result id: 0.5.2.2.
[3] NMT result by Google on TPUv2.8 (4 chips) using TF 1.12. Result id: 0.5.2.4.
[4] ResNet-50 v1.5 result by Google on TPUv2.512 + TPUv2.8 (260 chips) using TF 1.12. Result id: 0.5.3.1.
[5] ResNet-50 v1.5 result by Google on TPUv3.8 (4 chips) using TF 1.12. Result id: 0.5.4.1.
[6] SSD result by Google on TPUv3.8 (4 chips) using TF 1.12. Result id: 0.5.4.2.
[7] NMT result by Google on TPUv3.8 (4 chips) using TF 1.12. Result id: 0.5.4.4.
[8] 8x Volta V100 result by Google on 8x Volta V100 (8 chips) using TF 1.12 and cuDNN 7.4. Result id: 0.5.5.1.
[9] ResNet-50 v1.5 result by Google on TPUv3.32 + TPUv2.8 (20 chips) using TF 1.12. Result id: 0.5.26.1.
[10] SSD result by Google on TPUv3.32 + TPUv2.8 (20 chips) using TF 1.12. Result id: 0.5.26.2.
[11] NMT result by Google on TPUv3.32 + TPUv2.8 (20 chips) using TF 1.12. Result id: 0.5.26.4.
[12] ResNet-50 v1.5 result by Google on TPUv3.512 + TPUv2.8 (260 chips) using TF 1.12. Result id: 0.5.27.1.
[13] ResNet-50 v1.5 result by NVIDIA on DGX-2 (16 chips) using ngc18.11_MXNet, cuDNN 7.4. Result id: 0.5.18.1.
[14] SSD result by NVIDIA on DGX-2 (16 chips) using ngc18.11_pyTorch and cuDNN 7.4. Result id: 0.5.19.2.
[15] NMT result by NVIDIA on DGX-2 (16 chips) using ngc18.11_pyTorch and cuDNN 7.4. Result id: 0.5.19.4.
[16] ResNet-50 v1.5 result by NVIDIA on 80x DGX-1 (640 chips) using ngc18.11_MXNet and cuDNN 7.4. Result id: 0.5.17.1.