Itaú Unibanco: How we built a CI/CD Pipeline for machine learning with online training in Kubeflow
Cristiano Breuel
Strategic Cloud Engineer, Google
Vinicius Caridá
Advanced Analytics Manager, Itaú Unibanco
Itaú Unibanco is the largest private sector bank in Brazil, with a mission to put its customers at the center of everything they do as a key driver of success. As a result, one of its projects is AVI (Itaú Virtual Assistant), a digital customer service tool that uses natural language processing, built with machine learning, to understand customer questions and respond in real time.
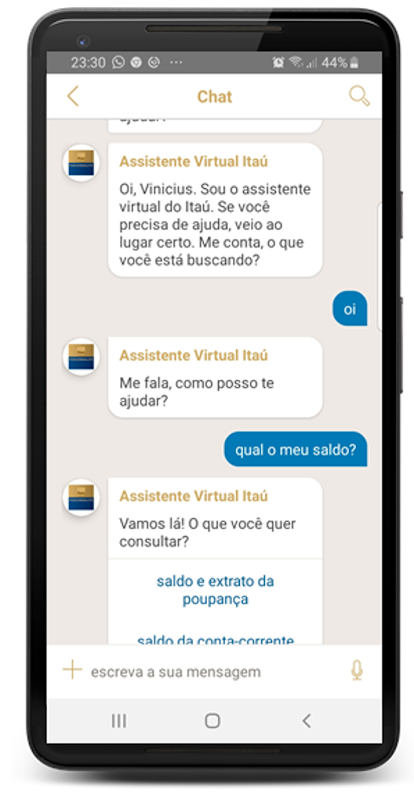
AVI helps about a million customers per month. It answers all but 2% of customer questions, and answers those questions correctly 85% of the time. In instances where AVI is not best suited to help a customer, it transitions to a live agent transparently, and in the same channel.
To help continually improve and evolve AVI, as well as Itaú’s other projects that use machine learning, they needed an efficient strategy for machine learning model deployment. However, they quickly found that building a robust tool that helps their data scientists deploy, manage and govern ML models in production proved challenging. As a result, the team began working with Google Cloud to create a CI/CD pipeline based on the open source project Kubeflow, for online machine learning training and deployment. Here’s how they did it.
How Itaú built their pipeline
A machine learning project lifecycle mainly comprises four major stages, executed iteratively:
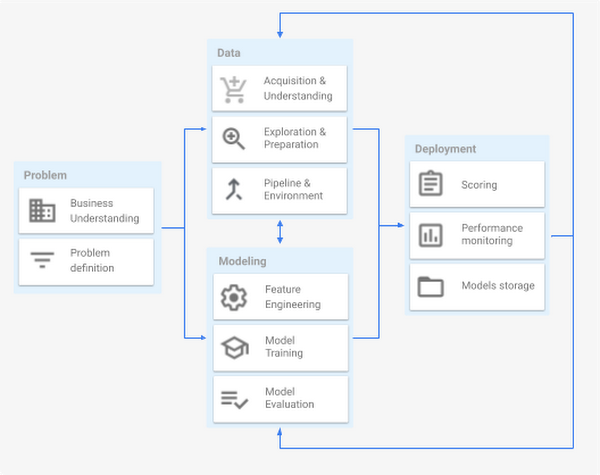
Once a data scientist has a set of well-performing machine learning models, they need to operationalize them for other applications to consume. Depending on the business requirements, predictions are produced either in real time or on a batch basis. For the AVI project, two business requirements were essential: (1) the ability to have multiple models in production (whether using different techniques or models trained using distinct data), and (2) the ability to retrain the production model with new data.
Although the data science and machine learning features are well cared for by the AVI multidisciplinary team, both model training and deployment are still not fully automated at Itaú. Additionally, internal change management procedures can mean it takes up to one week to retrain and deploy new models. This has made ML initiatives hard to scale for Itaú. Once the CI/CD pipeline is integrated with the AVI platform, the bank hopes that training and deployment will take hours instead of days, or even faster by using GPU or TPU hardware.
Some of the main requirements for this deployment pipeline and serving infrastructure include:
The Itaú team may work with several ML model architectures in parallel. Each of these models is called a “technique” in the team’s internal jargon.
Promoting a new technique to production should be an automated process, triggered by commits to specific branches.
It should be possible to re-train each model on new data in the production environment, triggered by the front-end used by agent managers.
Several versions of the same or different models could be served simultaneously, for A/B test purposes or to serve different channels.
Architecture
Itaú has a hybrid and multi-cloud IT strategy based on open source software and open standards to guarantee maximum portability and flexibility. This created a natural alignment with Google Cloud, which is also committed to open source and hybrid/multi-cloud. Therefore, the architecture was planned around open source platforms, tools and protocols, including Kubeflow, Kubernetes, Seldon Core, Docker, and Git. The goal was to have a single overall solution that could be deployed on GCP or on-premises, according to the needs and restrictions of each team inside the company.
This is the high-level, conceptual view of the architecture:
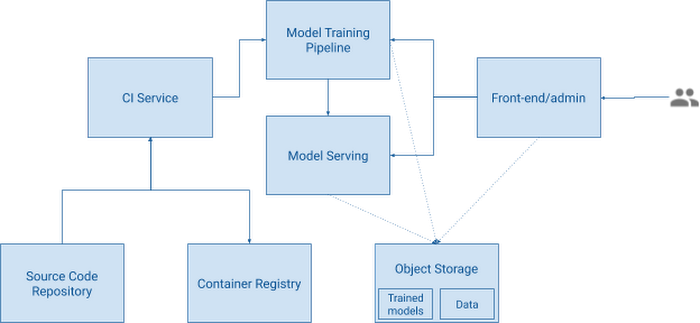
Models start their lives as code in the source repository, and data in object storage. A build is triggered in the CI server, producing new container images with the model code packaged for training. The CI process also compiles and uploads a pipeline definition to the training platform, and triggers a new training run with the latest data. At the end of the training pipeline, if everything runs well, a new trained model is written to object storage, and a new serving endpoint is started. The front-end server of the customer service application will use these API endpoints to obtain model predictions from a given input. Service administrators use the same application to manage training example data and classes. These users can trigger the training of a new model version with a new dataset. This is accomplished by triggering a new run of the training pipeline, with no need to reload or re-compile source code.
For this project, the concrete architecture was instantiated with the following components:
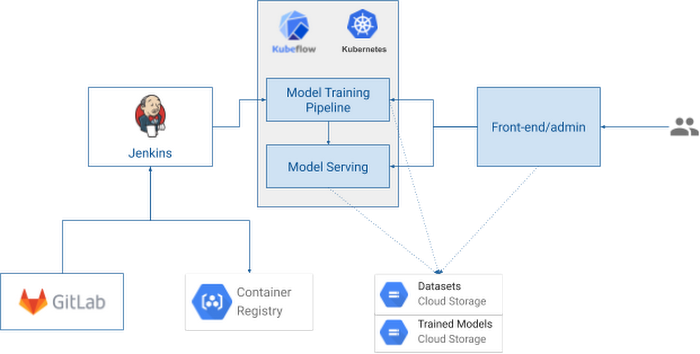
Itaú’s centralized infrastructure teams have selected Jenkins and GitLab as their standard tools for integration and source control, respectively, so these tools were used to build the integrated pipeline. For the container registry and object storage, the cloud-native solutions Container Registry and Cloud Storage were used, since they should be easy to replace with on-premises equivalents without many changes. The core of the system is Kubeflow, the open source platform for ML training and serving that runs on Kubernetes, the industry standard open source container orchestrator. Itaú tested the platform with two flavors of Kubernetes: Origin, the open source version of RedHat OpenShift, used by Itaú in its private cloud, and Google Kubernetes Engine (GKE), for easier integration and faster development. Kubeflow runs well on both.
The centerpiece of the pipeline is Kubeflow Pipelines (KFP), which provides an optimized environment to run ML-centric pipelines, with a graphical user interface to manage and analyze experiments. Kubeflow Pipelines are used to coordinate the training and deployment of all ML models.
Implementation
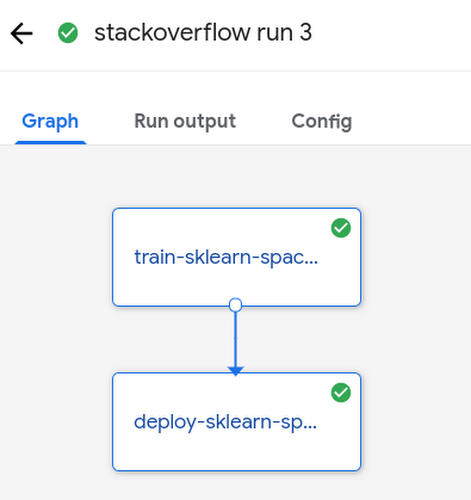
In the simplest case, each pipeline should train a model and deploy an endpoint for prediction. This is what such a pipeline looks like in Kubeflow Pipelines:
Since this platform will potentially manage several ML models, Itaú agreed on a convention of repository structure that must be followed for each model:
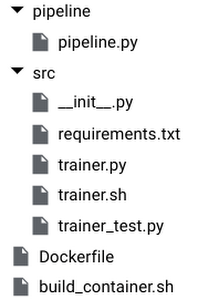
The root of each directory should contain a Dockerfile, to build the image that will train the model, and an optional shell script to issue the docker build and push commands. The src subdirectory contains all source code, including a script called trainer.sh that will initiate the training process. This script should receive three parameters, in the following order: path to the training data set, path to the evaluation data set, and output path where the trained model should be stored.
The pipeline directory contains pipeline.py, the definition of the Kubeflow Pipeline that will perform the training and deployment of the model. We’ll take a better look at this definition later.
Container Images
Each step in a KFP pipeline is implemented as a container image. For our minimum viable product (MVP), Itaú created three container images:
- Model trainer (sklearn_spacy_text_trainer)
- Model deployment script (serving_deployer)
- Model serving with Seldon Core (pkl_server)
The model trainer image is built from the model source code tree, with the Dockerfile shown in the file structure above. The other two images are more generic, and can be reused for multiple models, receiving the specific model code as runtime parameters.
The model trainer and deployer containers are built by simple shell scripts from their respective Dockerfiles. The model serving container is built with the s2i utility, which automatically assembles a container from the source code tree, using the Seldon Python 3.6 base image. The shell script below shows how that’s accomplished:
Pipeline definition
A pipeline in Kubeflow Pipelines is defined with a Python-based domain specific language (DSL), which is then compiled into a yaml configuration file. There are two main sections to a pipeline definition: (1) definition of operators and (2) instantiation and sequencing of those operators.
For this sample pipeline, an operator was defined for the trainer container and one for the deployer. They are parameterized to receive relevant dynamic values such as input data path and model endpoint name:
The pipeline itself declares the parameters that will be customizable by the user in the KFP UI, then instantiates the operations with relevant parameters. Note that there is no explicit dependency between the train and deploy operations, but since the deploy operation relies on the output of the training as an input parameter, the DSL compiler is able to infer that dependency.
Pipeline build and deploy
A commit to the main branch will trigger a build in Jenkins. The build script will execute the following steps:
- Build the containers
- Compile the KFP pipeline definition
- Upload the new pipeline to KFP
- Trigger a run of the new pipeline to train the model (this step is optional, depending on what makes sense for each model and the team’s workflow)
The sample script below executes steps 2 and 3, receiving a descriptive pipeline name as an argument:
Pipeline run
Whenever the training dataset is changed, a user can trigger a model training from the administration UI. Training a model is simply a matter of placing the new data in the right location and starting a new run of the pipeline that is deployed to Kubeflow. If successful, the pipeline will train the model and start a new serving endpoint to be called by the front-end.
This REST call will return a run ID parameter, which can be used by the UI back end to poll for the run status and update the user when it’s done, or there is an error.
Model prediction serving
The final step of the pipeline is, of course, serving model predictions. Since most of our models are created with Scikit Learn, Itaú leveraged Seldon Core, a bundled component of Kubeflow, to implement the serving endpoints. Seldon Core lets you implement just a simple predict method and takes care of all the plumbing for exposing a REST endpoint, with optional advanced orchestration features.
Since the serving API tends to change infrequently, we opted to implement a generic class that can serve any model serialized to a PKL file. The deployment definition parameterizes a storage location with the PKL file and bundled model source code, which is then unpacked and used for serving by the container. The Python code that achieves this is listed below:
This serving code is deployed for each endpoint by a shell script in the deployer container. The script takes in the location of the trained model, name and version for the endpoint, generates the necessary configuration and deploys it to Kubernetes:
Conclusion
With this relatively simple architecture and very little custom development, Itaú was able to build a CI/CD pipeline for machine learning that can accelerate the pace of innovation while simplifying production maintenance for AVI and other teams. It should be fairly easy to replicate and adapt it to many organizations and requirements, thanks to the openness and flexibility of tools like Kubeflow and Kubeflow Pipelines.
Acknowledgments
This work was created by a joint team between Google Cloud and Itaú Unibanco:
- Cristiano Breuel (Strategic Cloud Engineer, Google Cloud)
- Eduardo Marreto (Cloud Consultant, Google Cloud)
- Rogers Cristo (Data Scientist, Itaú Unibanco)
- Vinicius Caridá (Advanced Analytics Manager, Itaú Unibanco)