Google breaks AI performance records in MLPerf with world's fastest training supercomputer

Naveen Kumar
Principal Engineer
Fast training of machine learning (ML) models is critical for research and engineering teams that deliver new products, services, and research breakthroughs that were previously out of reach. Here at Google, recent ML-enabled advances have included more helpful search results and a single ML model that can translate 100 different languages.
The latest results from the industry-standard MLPerf benchmark competition demonstrate that Google has built the world’s fastest ML training supercomputer. Using this supercomputer, as well as our latest Tensor Processing Unit (TPU) chip, Google set performance records in six out of eight MLPerf benchmarks.
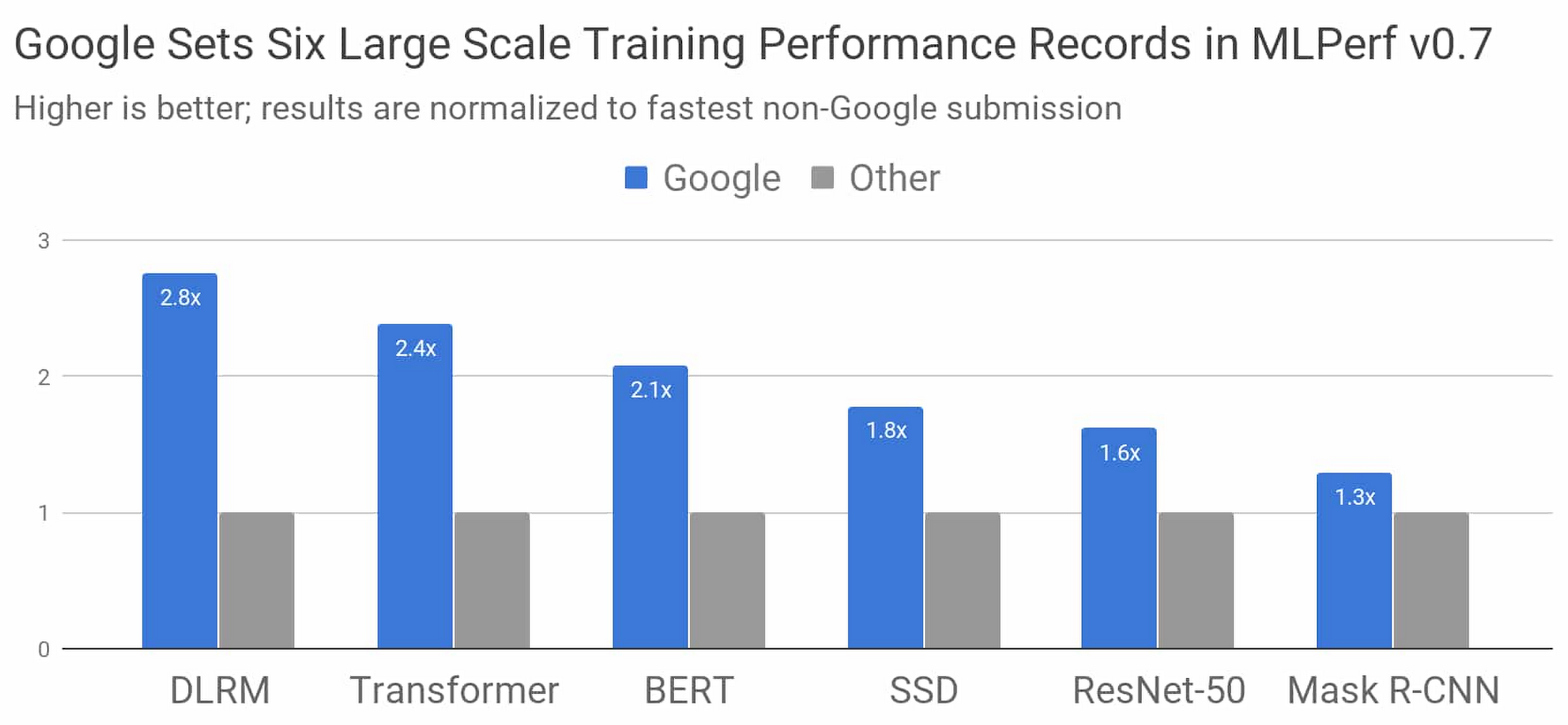
Figure 1: Speedup of Google’s best MLPerf Training v0.7 Research submission over the fastest non-Google submission in any availability category. Comparisons are normalized by overall training time regardless of system size, which ranges from 8 to 4096 chips. Taller bars are better.1
We achieved these results with ML model implementations in TensorFlow, JAX, and Lingvo. Four of the eight models were trained from scratch in under 30 seconds. To put that in perspective, consider that in 2015, it took more than three weeks to train one of these models on the most advanced hardware accelerator available. Google’s latest TPU supercomputer can train the same model almost five orders of magnitude faster just five years later.
In this blog post we’ll look at some of the details of the competition, how our submissions achieve such high performance, and what it all means for your model training speed.
MLPerf models at-a-glance
MLPerf models are chosen to be representative of cutting-edge machine learning workloads that are common throughout industry and academia. Here’s a little more detail on each MLPerf model in the figure above:
DLRM represents ranking and recommendation models that are core to online businesses from media to travel to e-commerce
Transformer is the foundation of a wave of recent advances in natural language processing, including BERT
BERT enabled Google Search’s “biggest leap forward in the past five years”
ResNet-50 is a widely used model for image classification
SSD is an object detection model that’s lightweight enough to run on mobile devices
Mask R-CNN is a widely used image segmentation model that can be used in autonomous navigation, medical imaging, and other domains (you can experiment with it in Colab)
In addition to the industry-leading results at maximum scale above, Google also provided MLPerf submissions using TensorFlow on Google Cloud Platform that are ready for enterprises to use today. You can read more about those submissions in this accompanying blog post.
The world’s fastest ML training supercomputer

The supercomputer Google used for this MLPerf Training round is four times larger than the Cloud TPU v3 Pod that set three records in the previous competition. The system includes 4096 TPU v3 chips and hundreds of CPU host machines, all connected via an ultra-fast, ultra-large-scale custom interconnect. In total, this system delivers over 430 PFLOPs of peak performance.
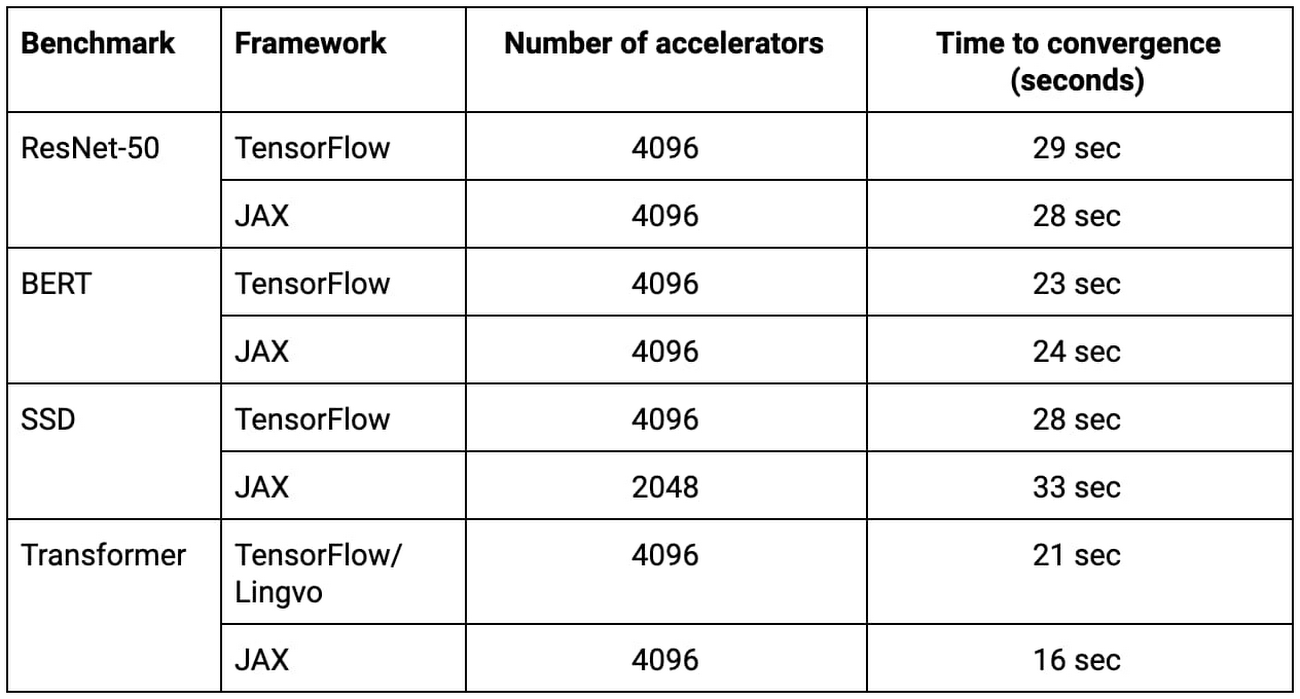
Table 1: All of these MLPerf submissions trained from scratch in 33 seconds or faster on Google’s new ML supercomputer.2
Training at scale with TensorFlow, JAX, Lingvo, and XLA
Training complex ML models using thousands of TPU chips required a combination of algorithmic techniques and optimizations in TensorFlow, JAX, Lingvo, and XLA. To provide some background, XLA is the underlying compiler technology that powers all of Google’s MLPerf submissions, TensorFlow is Google’s end-to-end open-source machine learning framework, Lingvo is a high level framework for sequence models built using TensorFlow, and JAX is a new research-focused framework based on composable function transformations. The record-setting scale above relied on model parallelism, scaled batch normalization, efficient computational graph launches, and tree-based weight initialization.
All of the TensorFlow, JAX, and Lingvo submissions in the table above—implementations of ResNet-50, BERT, SSD, and Transformer—trained on 2048 or 4096 TPU chips in under 33 seconds each.
TPU v4: Google’s fourth-generation Tensor Processing Unit chip
Google’s fourth-generation TPU ASIC offers more than double the matrix multiplication TFLOPs of TPU v3, a significant boost in memory bandwidth, and advances in interconnect technology. Google’s TPU v4 MLPerf submissions take advantage of these new hardware features with complementary compiler and modeling advances. The results demonstrate an average improvement of 2.7 times over TPU v3 performance at a similar scale in the last MLPerf Training competition. Stay tuned, more information on TPU v4 is coming soon
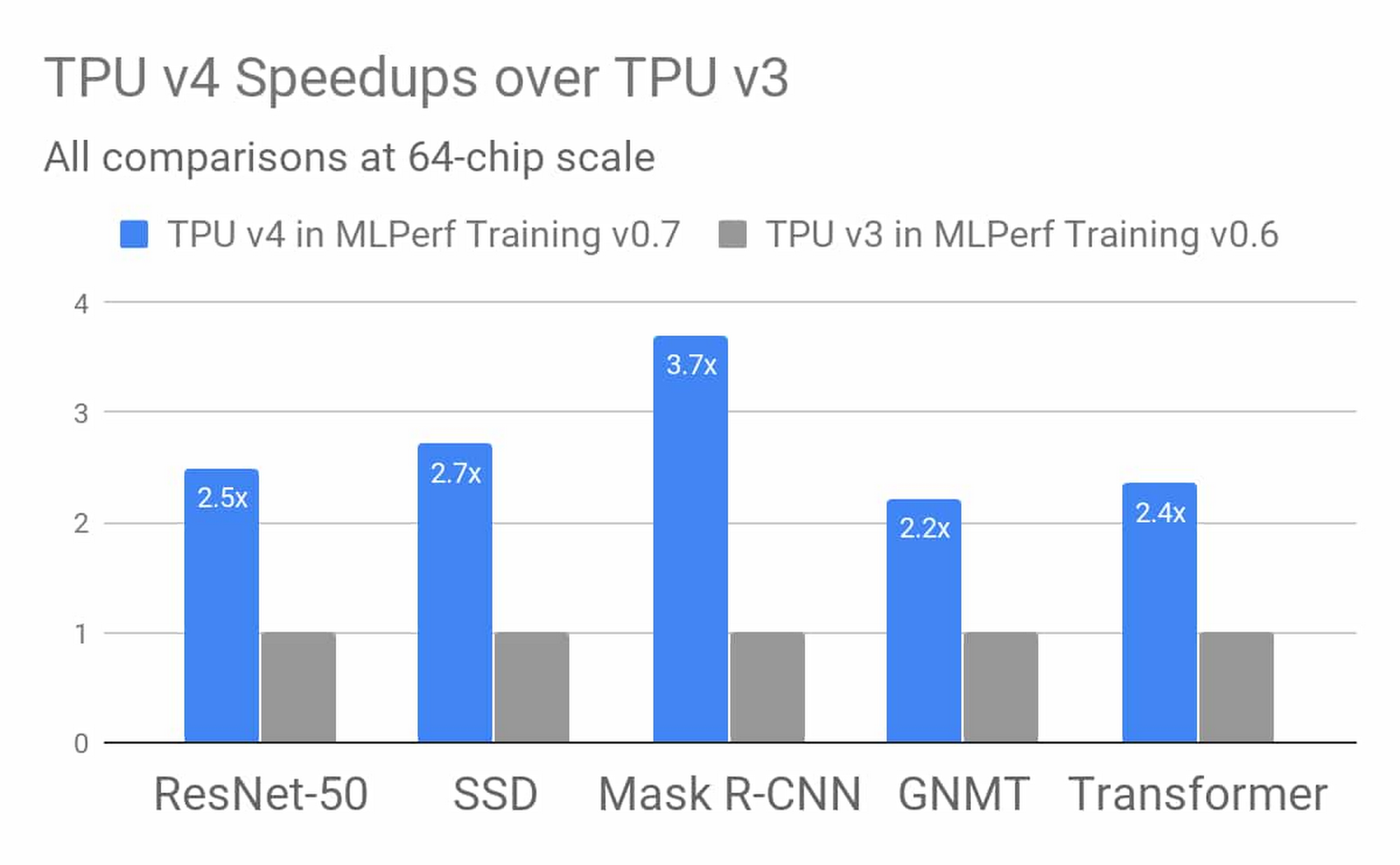
Figure 2: TPU v4 results in Google’s MLPerf Training v0.7 Research submission show an average improvement of 2.7 times over comparable TPU v3 results from Google’s MLPerf Training v0.6 Available submission at the identical scale of 64 chips. Improvements are due to hardware innovations in TPU v4 as well as software improvements.3
Rapid, ongoing progress
Google’s MLPerf Training v0.7 submissions demonstrate our commitment to advancing machine learning research and engineering at scale and delivering those advances to users through open-source software, Google’s products, and Google Cloud.
You can use Google’s second-generation and third-generation TPU supercomputers in Google Cloud today. Please visit the Cloud TPU homepage and documentation to learn more. Cloud TPUs support TensorFlow and PyTorch, and a JAX Cloud TPU Preview is also available.
1. All results retrieved from www.mlperf.org on July 29, 2020. MLPerf name and logo are trademarks. See www.mlperf.org for more information. Chart compares results: 0.7-70 v. 0.7-17, 0.7-66 v. 0.7-31, 0.7-68 v. 0.7-39, 0.7-68 v. 0.7-34, 0.7-66 v. 0.7-38, 0.7-67 v. 0.7-29.
2. All results retrieved from www.mlperf.org on July 29, 2020. MLPerf name and logo are trademarks. See www.mlperf.org for more information. Table shows results: 0.7-68, 0.7-66, 0.7-68, 0.7-66, 0.7-68, 0.7-65, 0.7-68, 0.7-66.
3. All results retrieved from www.mlperf.org on July 29, 2020. MLPerf name and logo are trademarks. See www.mlperf.org for more information. Figure compares results 0.7-70 v. 0.6-2.