ScatterBrain: PoisonPlug의 난독화 도구 그림자 벗기기
Mandiant
서론
2022년부터 Google 위협 인텔리전스 그룹(GTIG)은 POISONPLUG.SHADOW를 사용하는 중국 연계 해커들의 여러 건의 사이버 간첩 활동을 추적해 왔습니다. 이러한 작전들은 GTIG가 "ScatterBrain"이라고 부르는 맞춤형 난독화 컴파일러를 사용하여 유럽과 아시아 태평양(APAC) 지역의 다양한 기관을 공격하는 데 사용됩니다. ScatterBrain은 PWC에서 이전에 분석한 난독화 컴파일러인 ScatterBee의 상당한 진화형으로 보입니다.
GTIG는 POISONPLUG가 중국에 기반을 둔 여러 개별적이지만 관련성이 높은 것으로 추정되는 위협 그룹에서 사용하는 고급 모듈형 백도어라고 평가합니다. 그러나 POISONPLUG.SHADOW의 사용은 APT41과 관련된 그룹으로 더 제한된 것으로 판단됩니다.
GTIG는 현재 세 가지 알려진 POISONPLUG 변종을 추적하고 있습니다.
- POISONPLUG
- POISONPLUG.DEED
- POISONPLUG.SHADOW

Kaspersky에서 처음 소개한 악성 코드 패밀리 이름인 "Shadowpad"로 자주 언급되는 POISONPLUG.SHADOW는 탐지 및 분석을 회피하도록 특별히 설계된 맞춤형 난독화 컴파일러를 사용한다는 점에서 두드러집니다. 그 복잡성은 광범위한 난독화 메커니즘뿐만 아니라 공격자들의 고도로 정교한 위협 전술에 의해 더욱 심화됩니다. 이러한 요소들이 복합적으로 작용하여 분석을 매우 어렵게 만들고, 관련된 위협을 식별, 이해 및 완화하려는 노력을 복잡하게 만듭니다.
이러한 문제에 대처하기 위해 GTIG는 POISONPLUG.SHADOW를 해부하고 분석하기 위해 FLARE 팀과 긴밀하게 협력합니다. 이 파트너십은 이 위협 행위자가 제기하는 정교한 위협을 완화하는 데 필요한 최첨단 리버스 엔지니어링 기술과 포괄적인 위협 인텔리전스 역량을 활용합니다. 우리는 Google과 고객의 보안을 정교한 사이버 간첩 활동으로부터 보호하기 위해 방법론을 발전시키고 혁신을 촉진하여 끊임없이 진화하는 위협 행위자의 전술에 적응하고 대응하는 데 전념하고 있습니다.
개요
이 블로그 게시물에서는 바이너리 분석 프레임워크와 독립적인 완전한 독립형 정적 디오브퍼스케이터 라이브러리 개발로 이어진 ScatterBrain 난독화 도구에 대한 심층 분석을 제시합니다. 우리의 분석은 난독화 컴파일러 자체를 소유하고 있지 않기 때문에 성공적으로 복구한 난독화된 샘플만을 기반으로 합니다. 이러한 제한에도 불구하고 우리는 난독화 도구의 모든 측면과 이를 해독하는 데 필요한 요구 사항을 포괄적으로 추론할 수 있었습니다. 우리의 분석은 또한 ScatterBrain이 지속적으로 진화하고 있으며 시간이 지남에 따라 점진적인 변화가 확인되어 지속적인 개발을 강조한다는 것을 보여줍니다.
이 간행물은 ScatterBrain의 기본 요소들을 탐구하고, 모든 구성 요소와 분석에 대한 어려움을 설명하는 것으로 시작합니다. 그런 다음 각 보호 메커니즘을 전복시키고 제거하는 데 필요한 단계를 자세히 설명하여 디오브퍼스케이터를 완성합니다. 우리의 라이브러리는 ScatterBrain에 의해 생성된 보호된 바이너리를 입력으로 받아 완전한 기능을 갖춘 디오브퍼스케이트된 바이너리를 출력으로 생성합니다.
ScatterBrain의 내부 작동 방식을 자세히 설명하고 디오브퍼스케이터를 공유함으로써 효과적인 대응책 개발에 대한 귀중한 통찰력을 제공하기를 바랍니다. 우리의 블로그 게시물은 클라이언트를 위한 난독화 처리 경험을 바탕으로 의도적으로 철저하게 작성되었으며, 여기서 우리는 최신 난독화 기술에 대한 이해가 크게 부족하다는 것을 관찰했습니다. 마찬가지로, 분석가들은 표준 바이너리 분석 도구가 이를 고려하도록 설계되지 않았기 때문에 상대적으로 단순한 난독화 방법조차 이해하는 데 어려움을 겪는 경우가 많습니다. 따라서 우리의 목표는 이러한 부담을 완화하고 일반적으로 볼 수 있는 보호 메커니즘에 대한 집단적 이해를 높이는 데 도움을 주는 것입니다.
난독화 컴파일러에 대한 일반적인 질문은 해당 주제에 대한 소개 및 개요를 제공하는 이전 연구를 참조하십시오.
ScatterBrain 난독화 도구
서론
ScatterBrain은 생성하는 바이너리의 분석을 크게 복잡하게 만드는 여러 작동 모드 및 보호 구성 요소를 통합하는 정교한 난독화 컴파일러입니다. 최신 바이너리 분석 프레임워크와 방어 도구를 무력화하도록 설계된 ScatterBrain은 정적 및 동적 분석을 모두 방해합니다.
-
보호 모드: ScatterBrain은 세 가지 고유한 모드로 작동하며, 각 모드는 적용되는 보호의 전체 구조와 강도를 결정합니다. 이러한 모드를 통해 컴파일러는 공격의 특정 요구 사항에 따라 난독화 전략을 조정할 수 있습니다.
- 보호 구성 요소: 컴파일러는 다음과 같은 주요 보호 구성 요소를 사용합니다.
- 선택적 또는 전체 제어 흐름 그래프(CFG) 난독화: 이 기술은 프로그램의 제어 흐름을 재구성하여 분석하고 탐지 규칙을 생성하는 것을 매우 어렵게 만듭니다.
- 명령어 변형: ScatterBrain은 프로그램의 동작을 변경하지 않고 실제 기능을 모호하게 하기 위해 명령어를 변경합니다.
- 완전한 import 보호: ScatterBrain은 바이너리의 import 테이블에 대한 완전한 보호를 사용하므로 바이너리가 기본 운영 체제와 상호 작용하는 방식을 이해하는 것이 매우 어렵습니다.
이러한 보호 메커니즘은 분석가가 난독화된 바이너리의 기능을 해체하고 이해하는 것을 극도로 어렵게 만듭니다. 결과적으로 ScatterBrain은 생성하는 위협을 해체하고 완화하려는 사이버 보안 전문가에게 엄청난 장애물이 됩니다.
작동 모드
모드는 ScatterBrain이 주어진 바이너리를 난독화된 표현으로 변환하는 방식을 나타냅니다. 실제 핵심 난독화 메커니즘 자체와는 다르며, 보호를 적용하는 전체 전략에 관한 것입니다. 우리의 분석은 또한 공격 체인의 특정 단계에서 다양한 보호 모드를 적용하는 일관된 패턴을 밝혀냈습니다.
- 선택적: 개별적으로 선택된 함수 그룹이 보호되고 바이너리의 나머지 부분은 원래 상태로 유지됩니다. 선택된 함수 내의 import 참조도 난독화됩니다. 이 모드는 공격 체인의 드로퍼 샘플에만 엄격하게 사용되는 것으로 관찰되었습니다.
- 완전: 코드 섹션 전체와 모든 import가 보호됩니다. 이 모드는 기본 백도어 페이로드 내에 포함된 플러그인에만 적용되었습니다.
- 완전 "헤더 없음": 이는 추가 데이터 보호 및 PE 헤더 제거가 추가된 완전 모드의 확장입니다. 이 모드는 최종 백도어 페이로드에만 독점적으로 사용되었습니다.
선택적
선택적 보호 모드를 사용하면 난독화 도구 사용자가 보호할 바이너리 내의 개별 함수를 선택적으로 지정할 수 있습니다. 개별 함수를 보호하는 것은 함수를 원래 시작 주소(원래 컴파일러 및 링커에서 생성)에 유지하고 첫 번째 명령어를 난독화된 코드로 대체하는 것을 포함합니다. 생성된 난독화는 이 시작점에서 적용된 보호의 종료 경계를 나타내는 지정된 "끝 표시"까지 선형으로 저장됩니다. 이 전체 범위가 보호된 함수를 구성합니다.
보호된 함수에 대한 호출 사이트의 디스어셈블리는 다음과 같을 수 있습니다.
.text:180001000 sub rsp, 28h
.text:180001004 mov rcx, cs:g_Imagebase
.text:18000100B call PROTECTED_FUNCTION ; call to protected func
.text:180001010 mov ecx, eax
.text:180001012 call cs:ExitProcess그림 1: 보호된 함수 호출의 디스어셈블리
보호된 함수의 시작:
.text:180001039 PROTECTED_FUNCTION
.text:180001039 jmp loc_18000DF97 ; jmp into obfuscated code
.text:180001039 sub_180001039 endp
.text:000000018000103E db 48h ; H. ; garbage data
.text:000000018000103F db 0FFh
.text:0000000180001040 db 0C1h그림 2: 보호된 함수 내부의 디스어셈블리
"끝 표시"는 두 세트의 패딩 명령어, int3 명령어 및 단일 multi-nop 명령어로 구성됩니다.
END_MARKER:
.text:18001A95C CC CC CC CC CC CC CC CC CC CC 66
66 0F 1F 84 00 00 00 00 00
.text:18001A95C int 3
.text:18001A95D int 3
.text:18001A95E int 3
.text:18001A95F int 3
.text:18001A960 int 3
.text:18001A961 int 3
.text:18001A962 int 3
.text:18001A963 int 3
.text:18001A964 int 3
.text:18001A965 int 3
.text:18001A966 db 66h, 66h ; @NOTE: IDA doesn't disassemble properly
.text:18001A966 nop word ptr [rax+rax+00000000h]
; -------------------------------------------------------------------------
; next, original function
.text:18001A970 ; [0000001F BYTES: COLLAPSED FUNCTION
__security_check_cookie. PRESS CTRL-NUMPAD+ TO EXPAND]그림 3: 끝 표시의 디스어셈블리 목록
완전
완전 모드는 바이너리의 .text 섹션 내의 모든 함수를 보호하며, 모든 보호 기능이 단일 코드 섹션에 직접 통합됩니다. 보호된 영역을 나타내는 끝 표시는 없습니다. 대신 모든 함수가 균일하게 보호되어 추가 섹션 구분 없이 포괄적인 적용 범위를 보장합니다.
이 모드는 일종의 디오브퍼스케이션 도구가 필요합니다. 선택적 모드는 선택된 함수만 보호하고 다른 모든 것은 원래 상태로 두는 반면, 이 모드는 난독화를 고려하지 않고는 출력 바이너리를 분석하는 것을 매우 어렵게 만듭니다.
완전 "헤더 없음"
이 완전 모드는 코드 보호와 함께 추가 데이터 난독화를 추가하기 위해 완전 접근 방식을 확장합니다. 이는 가장 포괄적인 보호 모드이며 공격 체인의 최종 페이로드에만 독점적으로 제한되는 것으로 관찰되었습니다. 여기에는 다음 속성이 통합되어 있습니다.
-
보호된 바이너리의 전체 PE 헤더가 제거됩니다.
-
사용자 지정 로딩 로직(로더)이 도입됩니다.
-
보호된 바이너리의 진입점이 됩니다.
-
보호된 바이너리가 작동하는지 확인하는 역할을 합니다.
-
초기 메모리 영역과 별개의 메모리 영역 내에 최종 페이로드를 매핑하는 옵션이 포함됩니다.
-
메타데이터는 해시와 유사한 무결성 검사를 통해 보호됩니다.
-
메타데이터는 로더에서 초기화 시퀀스의 일부로 활용됩니다.
-
import 보호에는 재배치 조정이 필요합니다.
-
"import 수정 테이블"을 통해 수행됩니다.
로더의 진입 루틴은 여러 jmp 명령어를 삽입하여 둘을 연결함으로써 바이너리의 원래 진입점과 대략적으로 병합됩니다. 다음은 헤더 없음 모드로 보호된 바이너리에 대해 디오브퍼스케이터를 실행한 후의 진입점 모습입니다.

그림 4: 디오브퍼스케이트된 로더 진입점
로더의 메타데이터는 보호된 바이너리의 .data 섹션에 저장됩니다. 이는 미리 정의된 상수와 비트 단위 XOR 연산을 적용하는 메모리 스캔을 통해 찾을 수 있습니다. 이러한 상수의 사용은 메타데이터를 찾는 것뿐만 아니라 무결성을 검증하는 이중 목적도 수행합니다. 로더는 데이터를 이러한 상수와 XOR 연산했을 때 예상되는 패턴과 일치하는지 확인하여 메타데이터가 변경되거나 변조되지 않았음을 보장합니다.

그림 5: .data 섹션 내부에서 로더의 메타데이터를 식별하기 위한 메모리 스캔
메타데이터에는 다음 정보가 순서대로 포함됩니다.
- Import 수정 테이블 (Import 보호 섹션에서 자세히 설명)
- 무결성 해시 상수
.data섹션의 상대 가상 주소(RVA).data섹션 시작 부분에서 import 수정 테이블까지의 오프셋- 수정 테이블의 크기(바이트)
- 백도어가 있는 메모리 주소에 대한 전역 포인터
- 백도어에 특정한 암호화되고 압축된 데이터
- 백도어 구성 및 플러그인

그림 6: 로더의 메타데이터
핵심 보호 구성 요소
명령어 디스패처
명령어 디스패처는 바이너리(또는 개별 함수)의 자연스러운 제어 흐름을 보호된 바이너리의 실행을 동적으로 안내하는 고유한 디스패처 루틴으로 끝나는 분산된 기본 블록으로 변환하는 핵심 보호 구성 요소입니다.

그림 7: 제어 흐름 명령어 디스패처가 유도하는 흐름
각 디스패처에 대한 호출 직후에는 일반적으로 호출의 반환 주소가 될 위치에 32비트 인코딩된 변위가 배치됩니다. 디스패처는 이 변위를 디코딩하여 실행할 다음 명령어 그룹의 대상 대상을 계산합니다. 보호된 바이너리는 이러한 디스패처를 수천 개 또는 수만 개까지 쉽게 포함할 수 있으므로 수동 분석이 사실상 불가능합니다. 또한 각 디스패처에서 사용하는 동적 디스패치 및 디코딩 로직은 모든 바이너리 분석 프레임워크에서 사용하는 CFG 재구성 방법을 효과적으로 방해합니다.
디코딩 로직은 각 디스패처마다 고유하며 add, sub, xor, and, or 및 lea 명령어의 조합을 사용하여 수행됩니다. 그런 다음 디코딩된 오프셋 값은 디스패처 호출의 예상 반환 주소에서 빼거나 더하여 최종 대상 주소를 결정합니다. 이 계산된 주소는 다음 명령어 블록으로 실행을 지시하며, 마찬가지로 고유하게 디코딩하고 후속 명령어 블록으로 점프하는 디스패처로 끝나 이 프로세스를 반복적으로 계속하여 프로그램 흐름을 제어합니다.
다음 스크린샷은 IDA Pro에서 구성된 디스패처 인스턴스의 모습을 보여줍니다. 명령어 디스패처 내에도 있는 분산된 주소를 확인하십시오. 이는 난독화 도구가 자연스럽게 선행 명령어를 따르는 폴스루 명령어를 반대 조건을 사용하는 조건부 분기 쌍으로 변환한 결과입니다. 이렇게 하면 항상 하나의 분기가 선택되어 효과적으로 무조건 점프를 생성합니다. 또한 이러한 분기를 분리하기 위해 no-op 역할을 하는 mov 명령어가 삽입되어 제어 흐름을 더욱 모호하게 만듭니다.

그림 8: 명령어 디스패처 및 모든 구성 요소의 예
모든 디스패처의 핵심 로직은 다음 네 단계로 분류할 수 있습니다.
- 실행 컨텍스트 보존
- 각 디스패처는 난독화 프로세스 중에 단일 작업 레지스터(예: 스크린샷에 표시된
RSI)를 선택합니다. 이 레지스터는 스택과 함께 의도된 디코딩 작업 및 디스패치를 수행하는 데 사용됩니다. RFLAGS레지스터는 차례로 디코딩 시퀀스를 수행하기 전에pushfq및popfq명령어를 사용하여 보호됩니다.
- 각 디스패처는 난독화 프로세스 중에 단일 작업 레지스터(예: 스크린샷에 표시된
- 인코딩된 변위 검색
- 각 디스패처는 해당 호출 명령어의 반환 주소에 있는 32비트 인코딩된 변위를 검색합니다. 이 인코딩된 변위는 다음 대상 주소를 결정하는 기초 역할을 합니다.
- 디코딩 시퀀스
xor,sub,add,mul,imul,div,idiv,and,or및not과 같은 산술 및 논리 명령어로 구성된 고유한 디코딩 시퀀스를 사용합니다. 이러한 가변성은 두 디스패처가 동일하게 작동하지 않도록 보장하여 제어 흐름의 복잡성을 크게 증가시킵니다.
- 종료 및 디스패치
ret명령어는 디스패처 함수의 끝을 동시에 알리고 프로그램의 제어 흐름을 이전에 계산된 대상 주소로 리디렉션하는 데 전략적으로 사용됩니다.
난독화 도구가 원래 바이너리에 변환을 적용할 때 그림 9와 유사한 템플릿을 활용한다고 추론하는 것이 합리적입니다.

그림 9: 명령어 디스패처 템플릿
불투명 조건자
ScatterBrain은 분석가에게는 간단해 보이지만 특히 집합적으로 사용될 때 현대적인 바이너리 분석 프레임워크에 상당한 어려움을 주는 일련의 겉보기에 사소한 불투명 조건자(OP)를 사용합니다. 이러한 불투명 조건자는 해당 논리에 대응하도록 특별히 설계되지 않은 정적 CFG 복구 기술을 효과적으로 방해합니다. 또한 경로 폭발을 유도하고 경로 우선 순위 지정을 방해하여 심볼릭 실행 접근 방식을 복잡하게 만듭니다. 다음 섹션에서는 ScatterBrain에서 생성된 몇 가지 예를 보여드리겠습니다.
test OP
이 불투명 조건자는 즉각적인 0 값과 쌍을 이루는 test 명령어의 동작을 중심으로 구성됩니다. test 명령어가 비트 단위 AND 연산을 효과적으로 수행한다는 점을 감안할 때, 난독화 도구는 0과 비트 단위 AND 연산된 모든 값은 항상 예외 없이 0이 된다는 사실을 이용합니다.
다음은 보호된 바이너리에서 찾을 수 있는 몇 가지 추상화된 예입니다. 여기서 추상화되었다는 의미는 모든 명령어가 서로 직접적으로 이어지는 것이 보장되지 않는다는 것입니다. 다른 형태의 변형과 명령어 디스패처가 그 사이에 있을 수 있습니다.
test bl, 0
jnp loc_56C96 ; we never satisfy these conditions
------------------------------
test r8, 0
jo near ptr loc_3CBC8
------------------------------
test r13, 0
jnp near ptr loc_1A834
------------------------------
test eax, 0
jnz near ptr loc_46806그림 10: Test 불투명 조건자 예시
이 불투명 조건자의 구현 로직을 이해하려면 test 명령어의 의미론과 프로세서의 플래그 레지스터에 미치는 영향을 알아야 합니다. 이 명령어는 다음과 같은 방식으로 6개의 서로 다른 플래그에 영향을 줄 수 있습니다.
- 오버플로 플래그(OF): 항상 지워짐
- 캐리 플래그(CF): 항상 지워짐
- 부호 플래그(SF): 결과의 최상위 비트(MSB)가 설정된 경우 설정되고, 그렇지 않으면 지워짐
- 제로 플래그(ZF): 결과가 0이면 설정되고, 그렇지 않으면 지워짐
- 패리티 플래그(PF): 결과의 최하위 바이트(LSB)에서 설정된 비트 수가 짝수이면 설정되고, 그렇지 않으면 지워짐
- 보조 캐리 플래그(AF): 정의되지 않음
이러한 이해를 ScatterBrain에서 생성된 시퀀스에 적용하면 생성된 조건이 논리적으로 충족될 수 없다는 것이 분명합니다.
표 1: Test 불투명 조건자 이해
jcc OP
이 불투명 조건자는 조건부 분기 (jcc) 명령어에 대한 원래 즉각적인 분기 대상을 정적으로 모호하게 하도록 설계되었습니다. 다음 예시를 고려해보세요.
test eax, eax
ja loc_3BF9C
ja loc_2D154
test r13, r13
jns loc_3EA84
jns loc_53AD9
test eax, eax
jnz loc_99C5
jnz loc_121EC
cmp eax, FFFFFFFF
jz loc_273EE
jz loc_4C227그림 11: jcc 불투명 조건자 예시
구현은 간단합니다. 각 원래의 jcc 명령어는 가짜 분기 대상으로 복제됩니다. 두 jcc 명령어는 각각의 분기 목적지를 제외하고 기능적으로 동일하므로, 각 쌍의 첫 번째 jcc가 원래 명령어임을 확실하게 판단할 수 있습니다. 이 원래 jcc는 해당 조건이 충족될 때 따라야 할 올바른 분기 대상을 결정하고, 복제된 jcc는 오도된 분기 경로를 도입하여 분석 도구를 혼란스럽게 하는 역할을 합니다.
Stack-Based OP
스택 기반 불투명 조건자는 현재 스택 포인터(rsp)가 미리 정해진 즉각적인 임계값 아래에 있는지 확인하도록 설계되었습니다. 이는 절대 참이 될 수 없는 조건입니다. 이는 cmp rsp 명령어와 그 직후에 jb(아래인 경우 점프) 조건을 쌍으로 구성하여 일관되게 구현됩니다.
cmp rsp, 0x8d6e
jb near ptr unk_180009FDA그림 12: 스택 기반 불투명 조건자 예시
이 기술은 항상 거짓인 조건을 삽입하여 CFG 알고리즘이 두 분기를 모두 따르도록 하여 제어 흐름을 정확하게 재구성하는 능력을 방해합니다.
Import 보호
난독화 도구는 정교한 import 보호 계층을 구현합니다. 이 메커니즘은 문제의 import를 동적으로 확인하고 호출하는 방법을 알고 있는 고유한 스텁 디스패처 루틴을 통해 import로 향하는 각 원래 call 또는 jmp 명령어를 변환하여 바이너리의 종속성을 숨깁니다.

그림 13: import 보호에 관련된 모든 구성 요소의 그림
이것은 다음 구성 요소로 구성됩니다.
- Import별 암호화된 데이터: 각 보호된 import는 고유한 디스패처 스텁과 암호화된 동적 연결 라이브러리(DLL) 및 애플리케이션 프로그래밍 인터페이스(API) 이름 모두에 대한 RVA를 저장하는 분산된 데이터 구조로 표시됩니다. 이 구조를
obf_imp_t라고 합니다. 각 디스패처 스텁은 해당obf_imp_t에 대한 참조로 하드 코딩됩니다. -
디스패처 스텁: 이는 의도된 import를 동적으로 확인하고 호출하는 난독화된 스텁입니다. 모든 스텁이 동일한 템플릿을 공유하지만, 각 스텁에는 해당
obf_imp_t를 식별하고 찾는 고유한 하드 코딩된 RVA가 포함되어 있습니다. -
Resolver 루틴: 디스패처 스텁에서 호출되는 이 난독화된 루틴은 import를 확인하고 디스패처로 반환하여 의도된 import에 대한 최종 호출을 용이하게 합니다.
obf_imp_t의 정보를 기반으로 암호화된 DLL 및 API 이름을 찾는 것으로 시작합니다. 이러한 이름을 해독한 후 루틴은 이를 사용하여 API의 메모리 주소를 확인합니다. -
Import 해독 루틴: Resolver 루틴에서 호출되는 이 난독화된 루틴은 사용자 지정 스트림 암호 구현을 통해 DLL 및 API 이름 blob을 해독하는 역할을 합니다. 보호된 샘플당 고유한 하드 코딩된 32비트 솔트를 사용합니다.
-
수정 테이블: 헤더 없음 모드에만 존재하는 이 테이블은 헤더 없음 모드의 로더가 다음 import 보호 구성 요소에 대한 모든 메모리 변위를 수정하는 데 사용하는 재배치 수정 테이블입니다.
-
암호화된 DLL 이름
-
암호화된 API 이름
-
Import 디스패처 참조
-
Dispatcher Stub
import 보호 메커니즘의 핵심은 디스패처 스텁입니다. 각 스텁은 개별 import에 맞게 조정되며 일관되게 lea 명령어를 사용하여 해당 obf_imp_t에 액세스하고, 이를 resolver 루틴에 대한 유일한 입력으로 전달합니다.
push rcx ; save RCX
lea rcx, [rip+obf_imp_t] ; fetch import-specific obf_imp_t
push rdx ; save all other registers the stub uses
push r8
push r9
sub rsp, 28h
call ObfImportResolver ; resolve the import and return it in RAX
add rsp, 28h
pop r9 ; restore all saved registers
pop r8
pop rdx
pop rcx
jmp rax ; invoke resolved import그림 14: 디오브퍼스케이트된 import 디스패처 스텁
각 스텁은 앞에서 설명한 변형 메커니즘을 통해 난독화됩니다. 이는 resolver 및 import 해독 루틴에도 적용됩니다. 다음은 스텁의 실행 흐름이 어떻게 보일 수 있는지 보여줍니다. 순차적으로 표시되지만 명령어 디스패처로 인해 실제로는 코드 세그먼트 전체에서 점프하는 분산된 주소를 확인하십시오.
0x01123a call InstructionDispatcher_TargetTo_11552
0x011552 push rcx
0x011553 call InstructionDispatcher_TargetTo_5618
0x005618 lea rcx, [rip+0x33b5b] ; fetch obf_imp_t
0x00561f call InstructionDispatcher_TargetTo_f00c
0x00f00c call InstructionDispatcher_TargetTo_191b5
0x0191b5 call InstructionDispatcher_TargetTo_1705a
0x01705a push rdx
0x01705b call InstructionDispatcher_TargetTo_05b4
0x0105b4 push r8
0x0105b6 call InstructionDispatcher_TargetTo_f027
0x00f027 push r9
0x00f029 call InstructionDispatcher_TargetTo_18294
0x018294 test eax, 0
0x01829a jo 0xf33c
0x00f77b call InstructionDispatcher_TargetTo_e817
0x00e817 sub rsp, 0x28
0x00e81b call InstructionDispatcher_TargetTo_a556
0x00a556 call 0x6afa (ObfImportResolver)
0x00a55b call InstructionDispatcher_TargetTo_19592
0x019592 test ah, 0
0x019595 call InstructionDispatcher_TargetTo_a739
0x00a739 js 0x1935
0x00a73b call InstructionDispatcher_TargetTo_6eaa
0x006eaa add rsp, 0x28
0x006eae call InstructionDispatcher_TargetTo_6257
0x006257 pop r9
0x006259 call InstructionDispatcher_TargetTo_66d6
0x0066d6 pop r8
0x0066d8 call InstructionDispatcher_TargetTo_1a3cb
0x01a3cb pop rdx
0x01a3cc call InstructionDispatcher_TargetTo_67ab
0x0067ab pop rcx
0x0067ac call InstructionDispatcher_TargetTo_6911
0x006911 jmp rax그림 15: 난독화된 import 디스패처 스텁
Resolver 로직
obf_imp_t 는 각 import를 확인하는 데 관련된 정보를 포함하는 중앙 데이터 구조입니다. 그 형태는 다음과 같습니다:
struct obf_imp_t { // sizeof=0x18
uint32_t CryptDllNameRVA; // NOTE: will be 64-bits, due to padding
uint32_t CryptAPINameRVA; // NOTE: will be 64-bits, due to padding
uint64_t ResolvedImportAPI; // Where the resolved address is stored
};그림 16: 원래 C 구조체 소스 형식의 obf_imp_t
resolver 루틴에 의해 처리되며, 이 루틴은 포함된 RVA를 사용하여 암호화된 DLL 및 API 이름을 찾고 각 이름을 차례로 해독합니다. 각 이름 blob을 해독한 후에는 LoadLibraryA를 사용하여 DLL 종속성이 메모리에 로드되었는지 확인하고 GetProcAddress를 활용하여 import의 주소를 검색합니다.
완전히 디컴파일된 ObfImportResolver:

그림 17: 완전히 디컴파일된 import resolver 루틴
Import 암호화 로직
Import 해독 로직은 LCG 알고리즘을 사용하여 의사 난수 키 스트림을 생성하고, 생성된 키 스트림을 XOR 기반 스트림 암호에 사용하여 암호화된 Import 이름(DLL, API)을 해독합니다.
Xn + 1 = (a • Xn + c) mod 232
a는 항상17로 하드코딩되어 있으며, 승수 역할을 합니다.-
c는 암호화 컨텍스트에 따라 결정되는 고유한 32비트 상수이며, 보호된 샘플마다 고유합니다. 이를imp_decrypt_const라고 부릅니다. -
mod232는 시퀀스 값을 32비트 범위로 제한합니다.
해독 로직은 암호화된 데이터의 값으로 초기화되고, LCG 공식을 사용하여 반복적으로 새로운 값을 생성합니다. 생성된 값에서 파생된 바이트는 해당 암호화된 바이트와 XOR 연산됩니다. 이 과정은 특정 조건이 충족될 때까지 반복됩니다.
여기서 강조하는 것은 해독 로직에 대한 완전히 복구된 Python 구현이 그림 18에 제공됩니다.
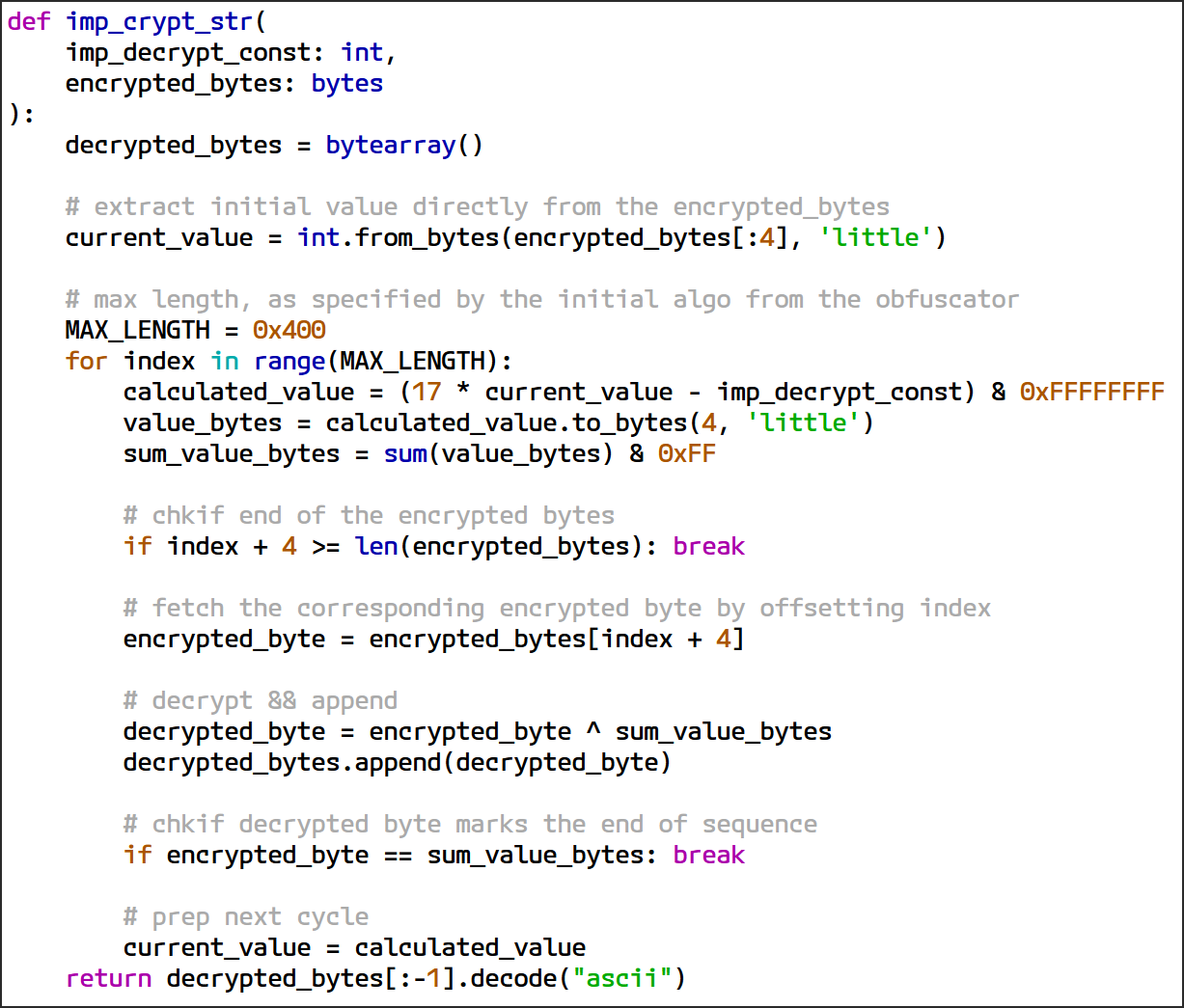
그림 18: Import 문자열 해독 루틴의 완전한 Python 구현
Import 수정 테이블
Import 재배치 수정 테이블은 두 개의 32비트 RVA 항목으로 구성된 고정 크기 배열입니다. 첫 번째 RVA는 데이터가 참조되는 위치의 메모리 변위를 나타냅니다. 두 번째 RVA는 문제의 실제 데이터를 가리킵니다. 수정 테이블의 항목은 세 가지 고유한 유형으로 분류할 수 있으며, 각 유형은 특정 import 구성 요소에 해당합니다.
- 암호화된 DLL 이름
- 암호화된 API 이름
- Import 디스패처 참조

그림 19: Import 수정 테이블의 그림
수정 테이블의 위치는 로더의 메타데이터에 의해 결정되며, 메타데이터는 .data섹션의 시작 부분에서 테이블의 시작 부분까지의 오프셋을 지정합니다. 초기화 중에 로더는 테이블의 각 항목에 대한 재배치 수정을 적용합니다.

그림 20: Import 수정 테이블 항목과 이를 찾는 데 사용되는 메타데이터를 보여주는 로더 메타데이터
복구
난독화된 바이너리로부터 효과적으로 복구하려면 사용된 보호 메커니즘을 철저히 이해해야 합니다. 디오브퍼스케이션은 원시 디스어셈블리보다는 중간 표현(IR)을 사용하는 것이 더 유리한 경우가 많지만(IR은 변환을 취소하는 데 더 세분화된 제어를 제공함), 이 난독화 도구는 원래 컴파일된 코드를 보존하고 추가 보호 계층으로만 둘러쌉니다. 이러한 상황을 고려하여 우리의 디오브퍼스케이션 전략은 디스어셈블리에서 난독화 도구의 변환을 제거하여 원래 명령어와 데이터를 드러내는 데 중점을 둡니다. 이는 일련의 계층적 단계를 통해 달성되며, 각 후속 단계는 이전 단계를 기반으로 포괄적인 디오브퍼스케이션을 보장합니다.
우리는 이 접근 방식을 결국 통합하는 세 가지 고유한 범주로 분류합니다.
-
CFG 복구
-
명령어 및 기본 블록 수준에서 난독화 인공물을 제거하여 자연스러운 제어 흐름을 복원합니다. 여기에는 다음 두 단계가 포함됩니다.
- 명령어 디스패처 고려: 실행 흐름을 모호하게 하는 제어 흐름 보호의 핵심을 해결합니다.
- 함수 식별 및 복구: 분산된 명령어를 목록화하고 원래 함수 대응 항목으로 재조립합니다.
-
Import 복구
-
-
원래 Import 테이블: 목표는 원래 import 테이블을 재구성하여 필요한 모든 라이브러리 및 함수 참조가 정확하게 복원되도록 하는 것입니다.
-
-
바이너리 재작성
-
디오브퍼스케이트된 실행 파일 생성: 이 프로세스에는 ScatterBrain의 수정 사항을 제거하면서 원래 기능을 유지하는 새로운 디오브퍼스케이트된 실행 파일을 만드는 작업이 포함됩니다.
-
각 범주의 복잡성을 고려하여 디오브퍼스케이터의 소스 코드에 대한 안내 연습을 제공하고 이러한 변환을 되돌리는 데 필요한 필수 로직을 강조 표시하여 난독화 도구를 해독하는 데 필요한 핵심 측면에 집중합니다. 이 단계별 검사는 각 난독화 기술이 체계적으로 취소되어 궁극적으로 바이너리의 원래 구조를 복원하는 방법을 보여줍니다.
우리의 디렉토리 구조는 이러한 체계적인 접근 방식을 반영합니다.
+---helpers
| | emu64.py
| | pefile_utils.py
| |--- x86disasm.py
|
\---recover
| recover_cfg.py
| recover_core.py
| recover_dispatchers.py
| recover_functions.py
| recover_imports.py
|--- recover_output64.py그림 21: 디오브퍼스케이터 라이브러리의 디렉토리 구조
이 포괄적인 복구 프로세스는 바이너리를 원래 상태로 복원할 뿐만 아니라 분석가에게 유사한 난독화 기술에 맞서 싸우는 데 필요한 도구와 지식을 제공합니다.
CFG 복구
자연스러운 제어 흐름 그래프를 방해하는 주요 장애물은 명령어 디스패처의 사용입니다. CFG를 얻는 데 있어 이러한 디스패처를 제거하는 것이 우리의 최우선 과제입니다. 그 후, 우리는 분산된 명령어를 원래 함수 표현으로 다시 구성해야 합니다. 이는 함수 식별이라고 알려진 문제이며, 일반화하기가 매우 어렵습니다. 따라서 우리는 난독화 도구에 대한 특정 지식을 사용하여 접근합니다.
분산된 CFG 선형화
원래 CFG를 복구하는 첫 번째 단계는 명령어 디스패처로 인해 발생하는 분산 효과를 제거하는 것입니다. 모든 디스패처 호출 명령어를 해결된 대상으로 직접 분기로 변환합니다. 이 변환은 실행 흐름을 선형화하여 CFG 복구의 두 번째 단계를 정적으로 추구하는 것을 간단하게 만듭니다. 이는 무차별 대입 스캔, 정적 파싱, 에뮬레이션 및 명령어 패치를 통해 구현됩니다.
함수 식별 및 복구
알려진 코드 진입점에 적용된 깊이 우선 탐색(DFS) 전략을 사용하는 재귀 내림차순 알고리즘을 활용하여 한 번에 하나의 명령어씩 "싱글 스텝"하여 모든 코드 경로를 소진하려고 시도합니다. 각 명령어를 처리하는 데 "변형 규칙" 형태의 추가 로직을 추가합니다. 이러한 규칙은 각 개별 명령어를 처리하는 방법을 규정합니다. 이러한 규칙은 원래 코드에서 난독화 도구의 코드를 제거하는 데 도움이 됩니다.
명령어 디스패처 제거
명령어 디스패처를 제거하려면 각 디스패처 위치와 해당 디스패치 대상을 식별해야 합니다. 대상은 디스패처 호출의 반환 주소에 있는 고유하게 인코딩된 32비트 변위입니다. 명령어 디스패처를 제거하려면 먼저 이를 정확하게 식별하는 방법을 이해하는 것이 필수적입니다. 먼저 개별 명령어 디스패처의 정의 속성을 분류하는 것으로 시작합니다.
- 근거리 호출의 대상
- 디스패처는 항상
E8opcode와 32비트 변위로 표시되는 근거리call명령어의 대상입니다.
- 디스패처는 항상
- 반환 주소에서 인코딩된 32비트 변위 참조
- 디스패처는 스택 포인터에서 32비트 읽기를 수행하여 스택의 반환 주소에 있는 인코딩된 32비트 변위를 참조합니다. 이 변위는 다음 실행 대상을 결정하는 데 필수적입니다.
- 디코딩을 보호하기 위한
pushfq및popfq명령어 쌍
- 디스패처는 디코딩 프로세스 중에
RFLAGS레지스터의 상태를 보존하기 위해pushfq및popfq명령어 쌍을 사용합니다. 이는 디스패처가 원래 실행 컨텍스트를 변경하지 않도록 하여 레지스터 내용의 무결성을 유지합니다.
- 디스패처는 디코딩 프로세스 중에
ret명령어로 끝남- 각 디스패처는
ret명령어로 끝나며, 이는 디스패처 함수를 종료할 뿐만 아니라 제어를 다음 명령어 세트로 리디렉션하여 실행 흐름을 효과적으로 계속합니다.
- 각 디스패처는
앞서 언급한 분류를 활용하여 명령어 디스패처를 식별하고 제거하기 위해 다음 접근 방식을 구현합니다.
-
근거리 호출 위치에 대한 무차별 대입 스캐너
-
보호된 바이너리의 코드 섹션 내에서 모든 근거리
call명령어를 검색하는 스캐너를 개발합니다. 이 스캐너는 디스패처 역할을 할 수 있는 잠재적인 호출 위치의 거대한 배열을 생성합니다
-
-
지문 루틴 구현
- 무차별 대입 스캔은 많은 거짓 긍정을 생성하므로 이를 필터링하는 효율적인 방법이 필요합니다. 에뮬레이션은 거짓 긍정을 필터링할 수 있지만 무차별 대입 결과에 대해 수행하는 것은 계산 비용이 많이 듭니다.
- 각 후보의 디스어셈블리를 순회하여
pushfq및popfq시퀀스와 같은 주요 디스패처 특성의 존재를 식별하는 얕은 지문 루틴을 도입합니다. 이는 에뮬레이션을 통해 구체적으로 확인하기 전에 대부분의 거짓 긍정을 제거하여 성능을 크게 향상시킵니다
-
대상의 에뮬레이션을 통한 대상 복구
-
각 확인된 호출 위치에서 시작하여 실행을 에뮬레이션하여 실제 디스패치 대상을 정확하게 복구합니다. 호출 위치에서 에뮬레이션하면 에뮬레이터가 반환 주소에서 인코딩된 오프셋 데이터를 처리하여 각 디스패처에서 사용하는 특정 디코딩 로직을 추상화합니다.
-
성공적인 에뮬레이션은 디스패처를 식별했음을 확인하는 최종 확인 단계 역할도 합니다.
-
-
ret 명령어를 통한 디스패치 대상 식별
-
종료
ret명령어를 활용하여 바이너리 내에서 디스패치 대상을 정확하게 식별합니다. -
ret명령어는 디스패처 함수의 끝과 제어가 리디렉션되는 지점을 나타내는 명확한 표시기이므로 대상 식별을 위한 신뢰할 수 있는 지표가 됩니다
-
무차별 대입 스캐너
다음 Python 코드는 보호된 바이너리의 코드 세그먼트 내에서 포괄적인 바이트 서명 스캔을 수행하는 무차별 대입 스캐너를 구현합니다. 스캐너는 근거리 call 명령어와 연결된 0xE8 opcode를 스캔하여 모든 잠재적인 call 명령어 위치를 체계적으로 식별합니다. 식별된 주소는 후속 분석 및 검증을 위해 저장됩니다.

그림 22: 무차별 공격 스캐너에 대한 Python 구현
지문 채취 디스패쳐
지문 채취 루틴은 보호된 바이너리 내에서 잠재적인 디스패처 위치를 정적으로 식별하기 위해 Instruction Dispatchers 섹션에 자세히 설명된 대로 명령어 디스패처의 고유한 특성을 활용합니다. 이 식별 프로세스는 이전의 무차별 대입 스캔의 결과를 활용합니다. 이 배열의 각 주소에 대해 루틴은 코드를 디스어셈블하고 결과 디스어셈블리 목록을 검사하여 알려진 디스패처 서명과 일치하는지 확인합니다. 이 방법은 100% 정확성을 보장하기 위한 것이 아니라 명령어 디스패처일 가능성이 높은 호출 위치를 식별하는 비용 효율적인 접근 방식으로 사용됩니다. 이러한 식별을 확인하기 위해 후속 에뮬레이션이 사용됩니다.
-
call명령어의 성공적인 디코딩 -
식별된 위치는
call명령어로 성공적으로 디코딩되어야 합니다. 디스패처는 항상call명령어를 통해 호출됩니다. 또한 디스패처는 호출 사이트의 반환 주소를 사용하여 인코딩된 32비트 변위를 찾습니다. -
후속
call명령어의 부재 -
디스패처는 디스어셈블리 목록 내에
call명령어를 포함해서는 안 됩니다. 추정되는 디스패처 범위 내에call명령어가 있으면 즉시 호출 위치가 디스패처 후보에서 제외됩니다. -
권한 있는 명령어 및 간접 제어 전송의 부재
-
call명령어와 마찬가지로 디스패처는 권한 있는 명령어 또는 간접적인 무조건jmps를 포함할 수 없습니다. 이러한 명령어가 있으면 호출 위치가 유효하지 않습니다. -
pushfq및popfq가드 시퀀스 감지 -
디스패처는 디코딩 중에 RFLAGS 레지스터를 보호하기 위해
pushfq및popfq명령어를 포함해야 합니다. 이러한 시퀀스는 디스패처에 고유하며 디코딩이 수행되는 방식 간에 발생하는 차이점에 대해 걱정할 필요 없이 일반적인 식별에 충분합니다.
그림 23은 잠재적인 호출 위치가 주어졌을 때 앞서 언급한 모든 특성 및 유효성 검사를 통합하는 지문 확인 루틴입니다.

그림 23: 디스패치 지문 루틴
디스패처를 에뮬레이트하여 대상 목표를 확인하기
지문 채취 루틴을 사용하여 잠재적인 디스패처를 필터링한 후, 다음 단계는 대상 목표를 복구하기 위해 디스패처를 에뮬레이트하는 것입니다.

그림 24: 디스패처 대상 목표 복구에 사용되는 에뮬레이션 시퀀스
Figure 24의 Python 코드는 이 로직을 수행하며 다음과 같이 작동합니다.
- 에뮬레이터 초기화
- 실행 시뮬레이션을 위한 핵심 엔진(
EmulateIntel64)을 생성하고, 보호된 바이너리 이미지(imgbuffer)를 에뮬레이터의 메모리 공간에 매핑하고, 실제와 같은 Windows 실행 환경을 시뮬레이션하기 위해 TEB(Thread Environment Block)도 매핑하고, 매번 전체 에뮬레이터를 다시 초기화할 필요 없이 각 에뮬레이션 실행 전에 빠른 재설정을 용이하게 하기 위해 초기 스냅샷을 생성합니다 MAX_DISPATCHER_RANGE는 각 디스패처에 대해 에뮬레이트할 최대 명령어 수를 지정합니다. 값 45는 디스패처의 제한된 명령어 수를 고려하여 임의로 선택되며, 추가된 변형이 있더라도 충분합니다.try/except블록은 에뮬레이션 중 발생하는 예외를 처리하는 데 사용됩니다. 예외는 이전에 식별된 잠재적인 디스패처 간의 거짓 양성 결과로 발생하며 안전하게 무시할 수 있다고 가정합니다.
- 실행 시뮬레이션을 위한 핵심 엔진(
- 각 잠재적 디스패처 에뮬레이트
- 각 잠재적 디스패처 주소(
call_dispatch_ea)에 대해 에뮬레이터의 컨텍스트가 초기 스냅샷으로 복원됩니다. 프로그램 카운터(emu.pc)는 각 디스패처의 주소로 설정됩니다.emu.stepi()는 현재 프로그램 카운터에서 하나의 명령어를 실행하고, 그 후 명령어를 분석하여 완료되었는지 확인합니다. 명령어가ret인 경우 에뮬레이션이 디스패치 지점에 도달한 것입니다.
- 명령어가
ret인 경우 에뮬레이션이 디스패치 지점에 도달한 것입니다. - 디스패치 대상 주소는
emu.parse_u64(emu.rsp)를 사용하여 스택에서 읽습니다.
- 명령어가
- 결과는 디스패처 주소를 디스패치 대상으로 매핑하는
d.dispatchers_to_target에 의해 캡처됩니다. 디스패처 주소는 추가적으로d.dispatcher_locs조회 캐시에 저장됩니다.break문은 내부 루프를 종료하고 다음 디스패처로 진행합니다.
- 각 잠재적 디스패처 주소(
패칭 및 선형화
캡처된 모든 명령어 디스패처를 수집하고 확인한 후, 마지막 단계는 각 호출 위치를 해당 대상 목표에 대한 직접 분기로 바꾸는 것입니다. 근거리 호출 및 jmp 명령어는 모두 크기가 5바이트를 차지하므로, 이 교체는 jmp 명령어를 호출 위에 패치하는 것만으로 원활하게 수행할 수 있습니다.
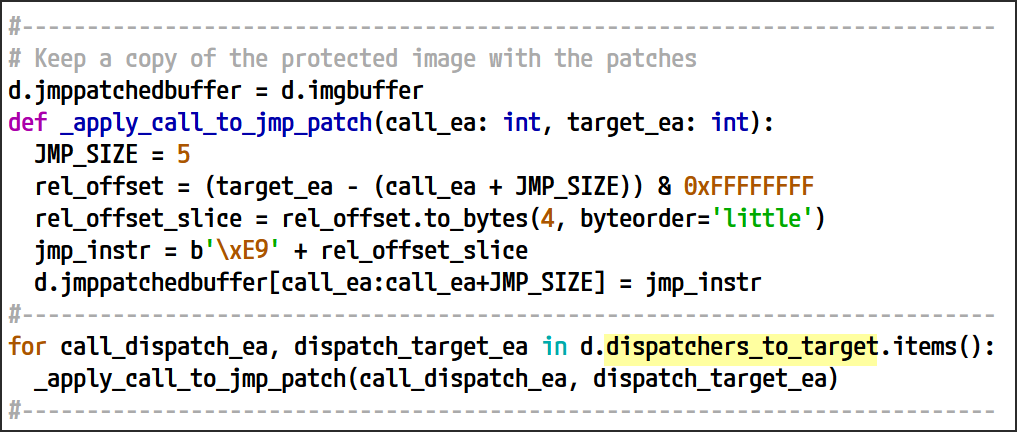
그림 25: 명령어 디스패처 호출을 대상 목표에 대한 무조건 jmp로 변환하는 패치 시퀀스
이전 섹션에서 설정된 dispatchers_to_target 맵을 활용합니다. 이 맵은 각 디스패처 호출 위치를 해당 대상 목표와 연결합니다. 이 맵을 반복하여 각 디스패처 호출 위치를 식별하고 원래 호출 명령어를 jmp로 바꿉니다. 이 대체는 실행 흐름을 의도된 대상 주소로 직접 리디렉션합니다.
이 제거는 명령어 디스패처가 제공하도록 설계된 의도된 동적 디스패치 요소를 제거하므로 난독화 해제 전략에 매우 중요합니다. 코드는 여전히 코드 세그먼트 전체에 흩어져 있지만, 실행 흐름은 이제 정적으로 결정적이 되어 어떤 명령어가 다음 명령어로 이어지는지 즉시 알 수 있습니다.
이러한 결과를 Instruction Dispatcher 섹션의 초기 스크린샷과 비교하면 블록은 여전히 흩어져 있는 것처럼 보입니다. 그러나 실행 흐름은 선형화되었습니다. 이 진행 상황을 통해 CFG 복구의 두 번째 단계로 나아갈 수 있습니다.

그림 26: 선형화된 명령어 디스패처 제어 흐름
함수 식별 및 복구
명령어 디스패처의 영향을 제거함으로써 실행 흐름을 선형화했습니다. 다음 단계는 분산된 코드를 통합하고 선형화된 제어 흐름을 활용하여 보호되지 않은 바이너리를 구성했던 원래 함수를 재구성하는 것입니다. 이 복구 단계에는 원시 명령어 복구, 정규화 및 최종 CFG 구성과 같은 여러 단계가 포함됩니다.
함수 식별 및 복구는 다음 두 가지 추상화에 요약되어 있습니다.
- 복구된 명령어 (
RecoveredInstr): 난독화된 바이너리에서 복구된 개별 명령어를 나타내기 위한 기본 단위입니다. 각 인스턴스는 원시 명령어 데이터뿐만 아니라 CFG 복구 프로세스 내에서 재배치, 정규화 및 분석에 필수적인 메타데이터도 캡슐화합니다. -
복구된 함수 (
RecoveredFunc): 난독화된 바이너리에서 개별 함수를 성공적으로 복구한 최종 결과입니다. 보호되지 않은 함수를 구성하는 명령어 시퀀스를 나타내는 여러 RecoveredInstr 인스턴스를 집계합니다. 전체 CFG 복구 프로세스는 RecoveredFunc 인스턴스의 배열을 생성하며, 각 인스턴스는 바이너리 내의 고유한 함수에 해당합니다. 이러한 결과는 완전히 난독화 해제된 바이너리를 생성하기 위해 최종 Building Relocations in Deobfuscated Binaries 섹션에서 활용할 것입니다
다음과 같은 이유로 복구 접근 방식에 기본 블록 추상화를 사용하지 않습니다. 기본 블록을 적절하게 추상화하려면 완전한 CFG 복구가 선행되어야 하며, 이는 우리의 목적에 불필요한 복잡성과 오버헤드를 초래합니다. 대신, 이 특정 난독화 해제 컨텍스트에서는 함수를 기본 블록의 모음이 아닌 개별 명령어의 집합으로 개념화하는 것이 더 간단하고 효율적입니다.
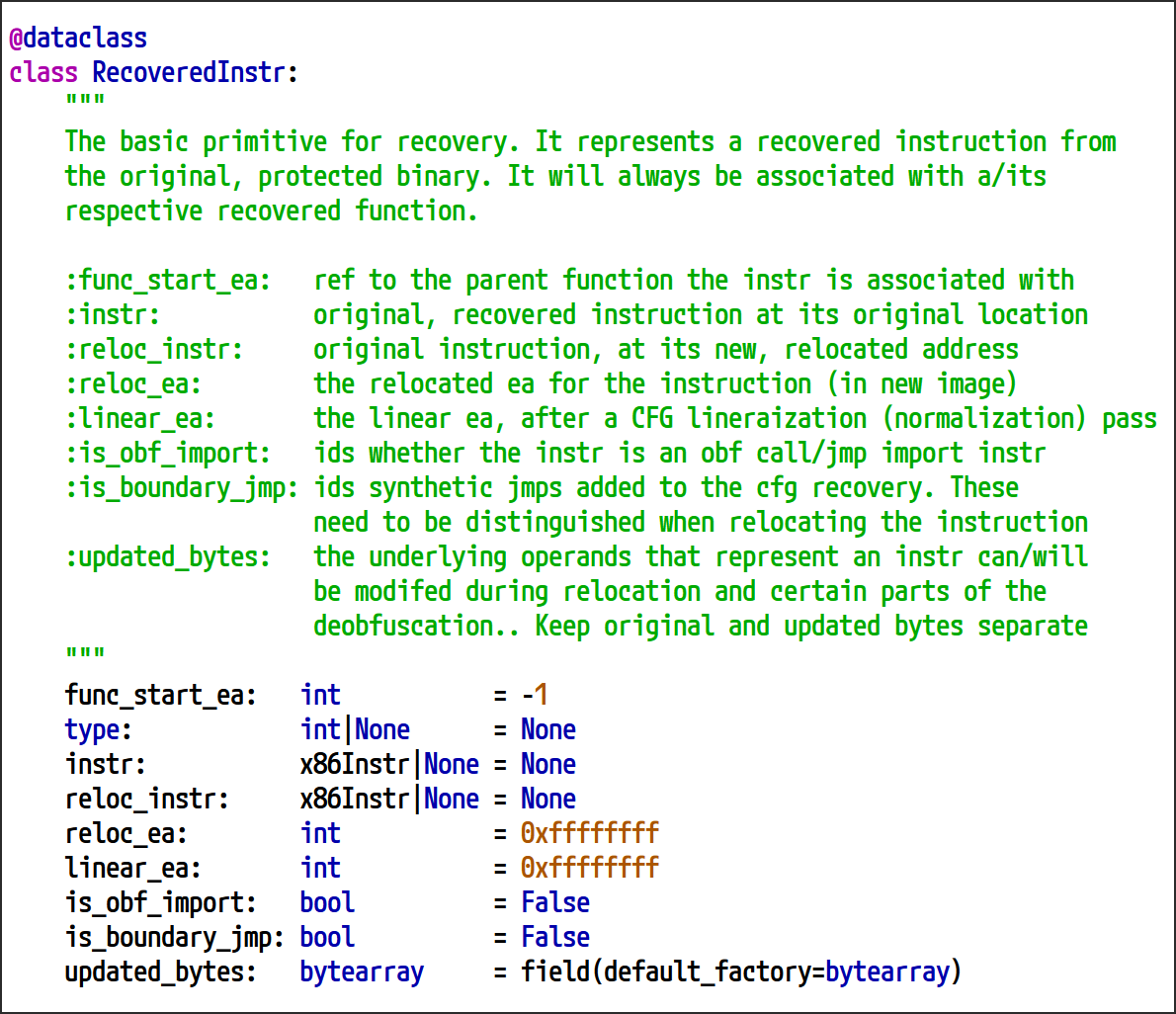
그림 27: RecoveredInstr 유형 정의

그림 28: RecoveredFunc 유형 정의
DFS 규칙 기반 단계 실행 소개
다음과 같은 이유로 재귀적 깊이 우선 탐색(DFS) 알고리즘을 선택했습니다.
- 코드 순회에 자연스러운 적합성: DFS를 사용하면 실행 흐름만으로 함수 경계를 추론할 수 있습니다. 함수가 다른 함수를 호출하는 방식을 반영하므로 함수 경계를 재구성할 때 구현하고 추론하기가 직관적입니다. 또한 루프와 조건부 분기의 흐름을 따르는 것을 단순화합니다.
- 보장된 실행 경로: 우리는 확실히 실행되는 코드에 집중합니다. 난독화된 코드에 대한 최소한 하나의 알려진 진입점이 주어지면, 코드의 다른 부분에 도달하려면 실행이 해당 코드를 통과해야 한다는 것을 알고 있습니다. 코드의 다른 부분이 더 간접적으로 호출될 수 있지만, 이 진입점은 기초적인 시작점 역할을 합니다. 이 알려진 진입점에서 재귀적으로 탐색하면 탐색 중에 거의 모든 코드 경로와 함수를 확실히 만나고 식별할 것입니다.
- 명령어 변형에 적응: 각 개별 명령어를 처리하는 방법을 규정하는 콜백 또는 "규칙"으로 탐색 로직을 맞춤화합니다. 이는 알려진 명령어 변형을 설명하는 데 도움이 되며 난독화 도구의 코드를 제거하는 데 도움이 됩니다.
이 프로세스에 관련된 핵심 데이터 구조는 다음과 같습니다: CFGResult, CFGStepState, 및 RuleHandler
CFGResult: CFG 복구 프로세스의 결과에 대한 컨테이너입니다. 바이너리 내에서 함수의 CFG를 나타내는 데 필요한 모든 관련 정보를 집계하며, 주로CFGStepState에서 사용합니다.CFGStepState: CFG 복구 프로세스 전반에 걸쳐, 특히 제어된 단계 탐색 중에 상태를 유지 관리합니다. 탐색 상태를 관리하고, 진행 상황을 추적하며, 중간 결과를 저장하는 데 필요한 모든 정보를 캡슐화합니다.- 복구된 캐시: 추가 정리 또는 검증 없이 보호된 함수에 대해 복구된 명령어를 저장합니다. 이 초기 수집은 난독화 바이너리 내에 존재하는 명령어의 원시 상태를 이후에 적용되는 정규화 또는 유효성 검사 프로세스 전에 보존하는 데 필수적입니다. 항상 복구의 첫 번째 단계입니다.
- 정규화된 캐시: CFG 복구 프로세스의 마지막 단계입니다. 난독화 도구에서 도입한 모든 명령어를 제거하고 유효하고 일관된 함수 생성을 보장하여 복구된 캐시에 저장된 원시 명령어를 완전히 정규화된 CFG로 변환합니다.
- 탐색 스택: 보호된 함수에 대한 DFS 탐색 중에 탐색 대기 중인 명령어 주소 집합을 관리합니다. 명령어가 처리되는 순서를 결정하고, 각 명령어가 한 번만 처리되도록
visited집합을 활용합니다. - 난독화 도구 백본: 난독화 도구에서 도입한 필수 제어 흐름 링크를 보존하기 위한 매핑
RuleHandler: 변형 규칙은 특정 함수 시그니처를 준수하고 CFG 복구 프로세스의 각 명령어 단계에서 호출되는 단순한 콜백입니다. 입력으로 현재 보호된 바이너리,CFGStepState및 현재 단계별 명령어을 사용합니다. 각 규칙은 난독화 도구에서 도입한 특정 유형의 명령어 특성을 감지하도록 설계된 특정 로직을 포함합니다. 이러한 특성의 감지를 기반으로 규칙은 탐색을 진행하는 방법, 특정 명령어를 건너뛰는 방법 또는 변형의 특성에 따라 프로세스를 중지하는 방법을 결정합니다.

그림 29: CFGResult 유형 정의

그림 30: CFGStepState 유형 정의

그림 31: RuleHandler 유형 정의
다음 그림은 이전 섹션에서 도입한 패치된 명령어 디스패처를 감지하고 이를 표준 jmp 명령어와 구별하는 데 사용되는 규칙의 예입니다.

그림 32: 패치된 명령어 디스패처를 식별하고 이를 표준 jmp 명령어와 구별하는 RuleHandler 예시
DFS 규칙 기반 단계 실행 구현
나머지 구성 요소는 보호된 바이너리 내의 주어진 함수 주소에 대한 CFG 복구 프로세스를 조정하는 루틴입니다. CFGStepState를 활용하여 DFS 탐색을 관리하고 변형 규칙을 적용하여 명령어를 체계적으로 디코딩하고 복구합니다. 결과는 원시 복구의 첫 번째 단계를 구성하는 RecoveredInstr 인스턴스의 집합이 됩니다.

그림 33: DFS 규칙 기반 단계 알고리즘의 순서도
다음 Python 코드는 그림 33에 설명된 알고리즘을 직접 구현합니다. CFG 스테핑 상태를 초기화하고 함수의 진입 주소에서 시작하는 DFS 탐색을 시작합니다. 탐색의 각 단계에서 현재 명령어 주소는 to_explore 탐색 스택에서 검색되고 중복 처리를 방지하기 위해 visited 집합에 대해 확인됩니다. 그런 다음 현재 주소의 명령어가 디코딩되고 난독화 도구로 인한 명령어 수정 사항을 처리하기 위해 일련의 변형 규칙이 적용됩니다. 이러한 규칙의 결과에 따라 탐색은 계속되거나 특정 명령어를 건너뛰거나 완전히 중지될 수 있습니다.
복구된 명령어는 recovered 캐시에 추가되고 해당 매핑은 CFGStepState 내에서 업데이트됩니다. 그런 다음 to_explore 스택은 체계적인 탐색을 보장하기 위해 다음 순차 명령어의 주소로 업데이트됩니다. 이 반복 프로세스는 모든 관련 명령어가 탐색될 때까지 계속되며, 결국 완전히 복구된 CFG를 캡슐화하는 CFGResult로 끝납니다.

그림 34: DFS 규칙 기반 단계 알고리즘 Python 구현
흐름 정규화
원시 명령어가 성공적으로 복구되면 다음 단계는 제어 흐름을 정규화하는 것입니다. 원시 복구 프로세스는 모든 원본 명령어가 캡처되도록 보장하지만 이러한 명령어만으로는 응집력 있고 정돈된 함수를 구성하지 않습니다. 간소화된 제어 흐름을 달성하려면 복구된 명령어를 필터링하고 다듬어야 합니다. 이 프로세스를 정규화라고 합니다. 이 단계에는 몇 가지 주요 작업이 포함됩니다.
-
분기 대상 업데이트: 난독화 도구에서 도입한 모든 코드(명령어 디스패처 및 변형)가 완전히 제거되면 모든 분기 명령어를 올바른 대상으로 리디렉션해야 합니다. 난독화로 인해 발생하는 분산 효과로 인해 분기가 관련 없는 코드 세그먼트를 가리키는 경우가 많습니다.
-
겹치는 기본 블록 병합: 엄격하게 단일 진입, 단일 출구 구조인 기본 블록이라는 개념과 달리 컴파일러는 한 기본 블록이 다른 기본 블록 내에서 시작되는 코드를 생성할 수 있습니다. 기본 블록의 이러한 겹침은 루프 구조에서 흔히 나타납니다. 결과적으로 일관된 CFG를 보장하려면 이러한 겹침을 해결해야 합니다.
-
적절한 함수 경계 명령어: 각 함수는 바이너리의 메모리 공간 내에서 명확하게 정의된 경계에서 시작하고 끝나야 합니다. 이러한 경계를 올바르게 식별하고 적용하는 것은 정확한 CFG 표현 및 후속 분석에 필수적입니다.
합성 경계 점프를 사용한 단순화
불필요한 오버헤드를 초래할 수 있는 기존의 기본 블록 추상화에 의존하는 대신, 합성 경계 점프를 사용하여 CFG 정규화를 단순화합니다. 이러한 인위적인 jmp 명령어는 그렇지 않으면 분리된 명령어를 연결하여 겹치는 블록을 분할하지 않고 각 함수가 적절한 경계 명령어에서 끝나도록 합니다. 이 접근 방식은 복구된 함수를 최종 난독화 해제된 출력 바이너리로 재구성할 때 바이너리 재작성 프로세스를 간소화합니다.
겹치는 기본 블록을 병합하고 함수에 적절한 경계 명령어가 있는지 확인하는 것은 동일한 문제(분산된 명령어를 함께 연결해야 하는지 결정)와 같습니다. 이를 설명하기 위해 합성 점프가 함수가 올바른 경계 명령어로 끝나도록 보장함으로써 이 문제를 효과적으로 해결하는 방법을 살펴보겠습니다. 기본 블록을 함께 병합하는 데에도 동일한 접근 방식이 적용됩니다.
함수 경계를 보장하는 합성 경계 점프
DFS 기반 규칙 안내 방식을 사용하여 함수를 성공적으로 복구한 예를 생각해 보겠습니다. CFGState에서 복구된 명령어를 검사하면 mov 명령어가 마지막 작업으로 나타납니다. 이 함수를 있는 그대로 메모리에 재구성하면 후속 폴스루(fallthrough) 명령어가 없으면 함수의 논리가 손상됩니다.

그림 35: 자연스러운 함수 경계 명령어로 끝나지 않는 원시 복구의 예
이 문제를 해결하기 위해, 마지막으로 복구된 명령어가 자연스러운 함수 경계(예: ret, jmp, int3)가 아닌 경우 합성 점프를 도입합니다.

그림 36: 함수 경계 명령어를 식별하는 간단한 Python 루틴
폴스루 주소를 확인하고, 해당 주소가 난독화 도구에서 도입한 명령어를 가리키는 경우, 첫 번째 일반 명령어에 도달할 때까지 계속 진행합니다. 이 탐색을 "난독화 도구의 백본 걷기"라고 부릅니다.

그림 37: 난독화 도구의 백본 로직을 구현하는 Python 루틴
그런 다음 이러한 지점을 합성 점프로 연결합니다. 합성 점프는 원래 주소를 메타데이터로 상속하여 어떤 명령어에 논리적으로 연결되어 있는지를 효과적으로 나타냅니다.
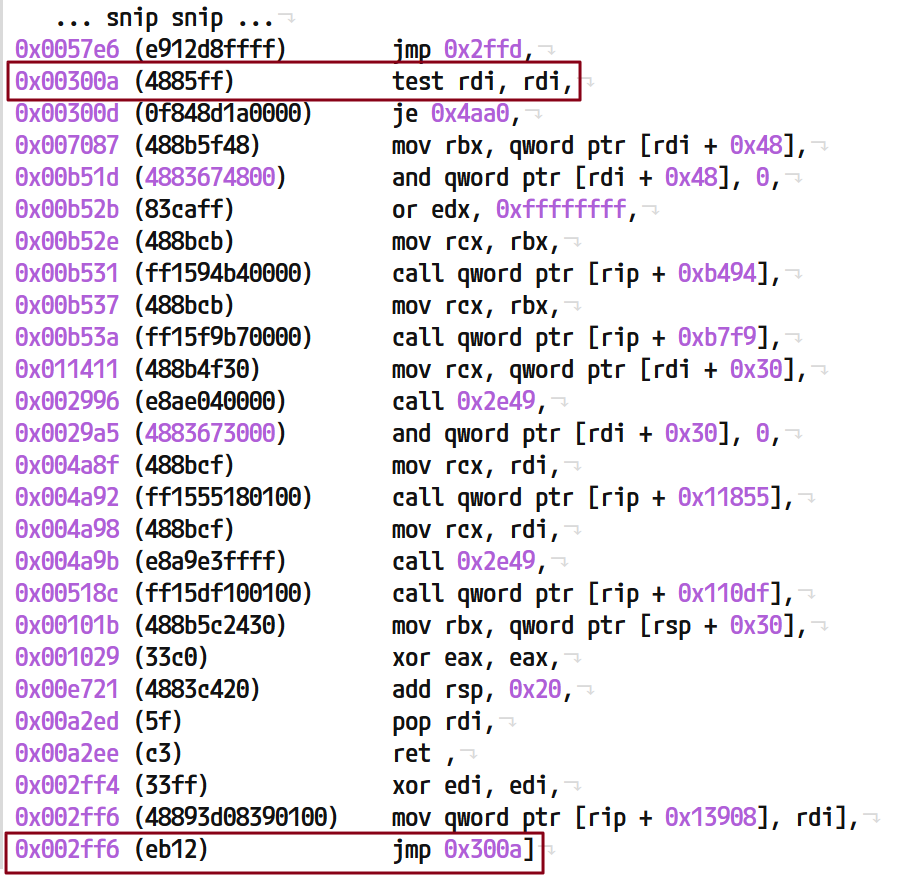
그림 38: 자연스러운 함수 경계를 만들기 위해 합성 경계 jmp를 추가하는 예
분기 대상 업데이트
제어 흐름을 정규화한 후에는 분기 대상을 조정하는 과정이 간단해집니다. 복구된 코드의 각 분기 명령어는 의도한 대상 대신 난독화 도구에서 도입한 명령어를 가리키고 있을 수 있습니다. normalized_flow 캐시(다음 섹션에서 생성됨)를 반복하여 분기 명령어를 식별하고 walk_backbone 루틴을 사용하여 대상을 확인합니다.
이렇게 하면 모든 분기 대상이 난독화 도구의 아티팩트에서 벗어나 의도한 실행 경로에 올바르게 정렬됩니다. 디스패처가 아닌 모든 call 명령어는 항상 합법적이며 난독화 도구 보호의 일부가 아니기 때문에 call 명령어는 무시할 수 있습니다. 그러나 이러한 명령어는 Building Relocations in Deobfuscated Binaries 섹션에 설명된 최종 재배치 단계에서 업데이트해야 합니다.
일단 다시 계산되면, 정확성과 일관성을 모두 유지하면서 업데이트된 변위를 사용하여 명령어를 다시 어셈블하고 디코딩합니다.

그림 39: 모든 분기 대상을 업데이트하는 Python 루틴
모두 합치기
지금까지 설명한 내용을 종합하여, 이전에 복구된 명령어를 기반으로 구축되는 다음 알고리즘을 개발했습니다. 이 알고리즘은 각 명령어, 분기, 블록이 적절하게 연결되도록 보장하여, 전체 보호된 바이너리에 대해 완전히 복구되고 난독화가 제거된 CFG를 생성합니다. 복구된 캐시를 활용하여 새로운 정규화된 캐시를 구성합니다. 알고리즘은 다음 단계를 따릅니다.
-
모든 복구된 명령어 반복
-
DFS 기반의 단계별 접근 방식을 통해 생성된 모든 복구된 명령어를 순회합니다.
-
정규화된 캐시에 명령어 추가
-
각 명령어를 정규화 단계의 결과를 저장하는 정규화된 캐시에 추가합니다.
-
경계 명령어 식별
-
현재 명령어가 경계 명령어인지 확인합니다.
-
경계 명령어인 경우, 해당 명령어에 대한 추가 처리를 건너뛰고 다음 명령어로 진행합니다 (1단계로 돌아갑니다).
-
예상 폴스루 명령어 계산
-
메모리에서 현재 명령어를 따르는 순차 명령어를 식별하여 예상 폴스루 명령어를 결정합니다.
-
폴스루 명령어 확인
-
계산된 폴스루 명령어를 복구된 캐시의 다음 명령어와 비교합니다.
-
폴스루 명령어가 메모리의 다음 순차 명령어가 아닌 경우, 이미 정규화한 복구된 명령어인지 확인합니다.
-
그렇다면, 합성 점프를 추가하여 정규화된 캐시에서 두 명령어를 함께 연결합니다.
-
그렇지 않다면, 복구 캐시에서 연결 폴스루 명령어를 가져와 정규화된 캐시에 추가합니다.
-
폴스루 명령어가 복구된 캐시의 다음 명령어와 일치하는 경우:
-
복구된 명령어가 이미 폴스루를 올바르게 가리키므로 아무 작업도 수행하지 않습니다. 6단계로 진행합니다.
-
최종 명령어 처리
-
현재 명령어가 복구된 캐시의 최종 명령어인지 확인합니다.
-
최종 명령어인 경우:
-
최종 합성 경계 점프를 추가합니다. 이 단계에 도달하면 3단계에서 확인에 실패했기 때문입니다.
-
반복을 계속하면 루프가 종료됩니다.
-
최종 명령어가 아닌 경우:
-
평소대로 반복을 계속합니다 (1단계로 돌아갑니다).

그림 40: 정규화 알고리즘 순서도
Figure 41의 Python 코드는 이러한 정규화 단계를 직접 구현합니다. 복구된 명령어를 반복하고 정규화된 캐시(normalized_flow)에 추가하고, 선형 매핑을 생성하고, 합성 점프가 필요한 위치를 식별합니다. 분기 대상이 난독화 도구가 삽입한 코드를 가리키면 백본을 따라 이동(walk_backbone)하여 다음 합법적인 명령어를 찾습니다. 함수의 끝에 자연스러운 경계 없이 도달하면 적절한 연속성을 유지하기 위해 합성 점프가 생성됩니다. 반복이 완료된 후에는 이전 섹션에서 설명한 대로 모든 분기 대상이 업데이트(update_branch_targets)되어 각 명령어가 올바르게 연결되도록 하여 완전히 정규화된 CFG를 생성합니다.

그림 41: 정규화 알고리즘의 Python 구현
결과 관찰
두 가지 주요 단계를 적용한 후, 우리는 거의 모든 보호 메커니즘을 제거했습니다. 임포트 보호는 여전히 해결해야 할 문제로 남아 있지만, 우리의 접근 방식은 이해할 수 없는 혼란을 완벽하게 복구된 CFG로 효과적으로 변환합니다.
예를 들어, 그림 42와 그림 43은 백도어 페이로드 내의 중요한 함수의 전후를 보여주며, 이는 플러그인 관리자 시스템의 구성 요소입니다. 출력에 대한 추가 분석을 통해 난독화 해제 프로세스 없이는 구분할 수 없었던, 더 나아가 그렇게 자세하게는 식별할 수 없었던 기능들을 식별할 수 있습니다.

그림 42: 원래 난독화된 shadow::PluginProtocolCreateAndConfigure 루틴

그림 43: 완전히 난독화 해제되고 작동하는 shadow::PluginProtocolCreateAndConfigure 루틴
Import 복구
원래 import 테이블을 복구하고 복원하는 것은 어떤 import 위치가 어떤 import 디스패처 스텁과 연결되어 있는지 식별하는 것을 중심으로 이루어집니다. 스텁 디스패처에서 해당 obf_imp_t 참조를 파싱하여 해당 디스패처가 나타내는 보호된 import를 결정할 수 있습니다.
다음 로직을 따릅니다.
- Import와 연결된 각 유효한 call/jmp 위치를 식별합니다.
- 이들의 메모리 변위는 해당 디스패처 스텁을 가리킵니다.
- HEADERLESS 모드의 경우, 변위가 유효한 디스패처 스텁을 가리키도록 먼저 fixup 테이블을 확인해야 합니다.
- 각 유효한 위치에 대해 디스패처 스텁을 탐색하여 obf_imp_t를 추출합니다.
obf_imp_t에는 암호화된 DLL 및 API 이름에 대한 RVA가 포함되어 있습니다.
- 문자열 복호화 로직 구현
- DLL 및 API 이름을 원래의 평문으로 복구하기 위해서는 복호화 과정이 필요합니다.
- 이전에 Import Protection 섹션에서 이미 복호화 로직을 구현했습니다.
다음 RecoveredImport 데이터 구조를 사용하여 import 복구를 캡슐화합니다.

그림 44: RecoveredImport 유형 정의
RecoveredImport는 복구하는 각 import에 대해 생성되는 결과 역할을 합니다. 여기에는 난독화 해제된 이미지를 생성할 때 원래 import 테이블을 재구성하는 데 사용할 모든 관련 데이터가 포함됩니다.
보호된 Import CALL 및 JMP 사이트 찾기
각 보호된 import 위치는 간접 근거리 호출(FF/2) 또는 간접 근거리 점프(FF/4)로 반영됩니다.

그림 45: import 호출 및 점프 표현의 디스어셈블리
간접 근거리 호출 및 점프는 ModR/M 바이트 내의 Reg 필드가 그룹의 특정 작업을 식별하는 FF 그룹 연산 코드에 속합니다.
-
/2:CALL r/m64에 해당 -
/4:JMP r/m64에 해당
간접 근거리 호출을 예로 들어 분석하면 다음과 같습니다.
-
FF: 그룹 연산 코드 -
15: RIP 상대 주소 지정을 사용하는CALL r/m64를 지정하는 ModR/M 바이트-
Mod (bits 6-7):
00 -
직접 RIP 상대 변위 또는 변위가 없는 메모리 주소 지정을 나타냅니다.
-
Reg (bits 3-5):
010 -
그룹에 대한 호출 작업을 식별합니다.
-
R/M (bits 0-2):
101 -
Mod
00및 R/M101을 사용하는 64비트 모드에서 이는 RIP 상대 주소 지정을 나타냅니다.
-
-
15는 이진수로00010101로 인코딩됩니다. -
<32-bit 변위>: 절대 주소를 계산하기 위해RIP에 추가됩니다.
각 보호된 import 위치와 연결된 디스패처 스텁을 찾기 위해 처음 두 연산 코드를 통해 잠재적인 모든 간접 근거리 call/jmps를 찾는 간단한 무차별 대입 스캐너를 구현합니다.

그림 46: 가능한 모든 import 위치를 찾기 위한 무차별 대입 스캐너
제공된 코드는 보호된 바이너리의 코드 섹션을 스캔하여 간접 호출 및 점프 명령어와 관련된 연산 코드 패턴을 가진 모든 위치를 식별하고 기록합니다. 이는 유효한 import 사이트임을 보장하기 위해 추가 검증을 적용하는 첫 번째 단계입니다.
Import Fixup 테이블 확인
HEADERLESS 보호에 대한 import를 복구할 때, 어떤 import 위치가 어떤 디스패처와 연결되어 있는지 식별하기 위해 fixup 테이블을 확인해야 합니다. 보호된 import 사이트의 메모리 변위는 테이블 내부의 확인된 위치와 쌍을 이룹니다. 이 변위를 테이블에서 조회하여 확인된 위치를 찾는 데 사용합니다.
특정 import에 대한 jmp 명령어를 예로 들어 보겠습니다.

그림 47: import fixup 테이블의 항목 및 관련 디스패처 스텁을 포함하는 jmp import 명령어의 예
jmp 명령어의 변위는 가비지 데이터를 가리키는 메모리 위치 0x63A88을 참조합니다. 메모리 변위를 사용하여 fixup 테이블에서 이 import에 대한 항목을 검사하면 이 import와 연결된 디스패처 스텁의 위치를 0x295E1에서 식별할 수 있습니다. 로더는 jmp 명령어가 호출될 때 실행이 적절하게 디스패처 스텁으로 리디렉션되도록 0x63A88에서 참조된 데이터를 0x295E1로 업데이트합니다.
그림 48은 fixup 테이블을 확인하는 로더의 난독화 해제된 코드입니다. 어떤 import 위치가 어떤 디스패처를 대상으로 하는지 연결하려면 이 동작을 모방해야 합니다.
$_Loop_Resolve_ImpFixupTbl:
mov ecx, [rdx+4] ; fixup , either DLL, API, or ImpStub
mov eax, [rdx] ; target ref loc that needs to be "fixed up"
inc ebp ; update the counter
add rcx, r13 ; calculate fixup fully (r13 is imgbase)
add rdx, 8 ; next pair entry
mov [r13+rax+0], rcx ; update the target ref loc w/ full fixup
movsxd rax, dword ptr [rsi+18h] ; fetch imptbl total size, in bytes
shr rax, 3 ; account for size as a pair-entry
cmp ebp, eax ; check if done processing all entries
jl $_Loop_Resolve_ImpTbl그림 48: import fixup 테이블을 확인하는 데 사용되는 알고리즘의 난독화 해제된 디스어셈블리
import fixup 테이블을 확인하려면 먼저 보호된 바이너리 내의 데이터 섹션과 import 테이블을 식별하는 메타데이터(IMPTBL_OFFSET, IMPTBL_SIZE)를 식별해야 합니다. fixup 테이블의 오프셋은 데이터 섹션의 시작 부분부터 계산됩니다.

그림 49: import fixup 테이블을 확인하는 데 사용되는 알고리즘의 Python 재구현
fixup 테이블의 시작 주소를 얻었으므로, 단순히 한 번에 하나의 항목을 반복하고 어떤 import 변위(location)가 어떤 디스패처 스텁(fixup)과 연결되어 있는지 식별합니다.
Import 복구
무차별 대입 스캔에서 잠재적인 모든 import 위치를 얻고 HEADERLESS 모드에서 재배치를 고려했으므로, 각 보호된 import를 복구하기 위한 최종 확인을 진행할 수 있습니다. 복구 프로세스는 다음과 같이 수행됩니다.
- 해당 위치를 유효한 call 또는 jmp 명령어로 디코딩합니다.
- 디코딩 실패는 해당 위치에 유효한 명령어가 없음을 나타내므로 안전하게 무시할 수 있습니다.
- 메모리 변위를 사용하여 import에 대한 스텁을 찾습니다.
- HEADERLESS 모드에서 각 변위는 해당 디스패처에 대한 fixup 테이블의 조회 키 역할을 합니다.
- 디스패처 내에서
obf_imp_t구조체를 추출합니다.- 이는 디스패처의 디스어셈블리 목록을 정적으로 탐색하여 수행됩니다.
- 처음 발견되는
lea명령어는obf_imp_t에 대한 참조를 포함합니다.
obf_imp_t를 처리하여 DLL 및 API 이름을 모두 해독합니다.- 구조체에 포함된 두 개의 RVA를 활용하여 DLL 및 API 이름에 대한 암호화된 블롭을 찾습니다.
- 제시된 가져오기 복호화 루틴을 사용하여 블롭을 복호화합니다.

그림 50: 각 보호된 임포트를 복구하는 루프
Python 코드는 모든 잠재적인 임포트 위치(potential_stubs)를 반복하며, 각 추정된 호출(call) 또는 점프(jmp) 명령어를 임포트로 디코딩하려고 시도합니다. try/except 블록은 명령어 디코딩 오류 또는 발생할 수 있는 기타 예외와 같은 모든 실패를 처리하는 데 사용됩니다. 모든 오류는 복구 프로세스에 대한 이해를 무효화하고 안전하게 무시될 수 있다고 가정합니다. 전체 코드에서 이러한 오류는 기록되고 발생 시 추가 분석을 위해 추적됩니다.
다음으로, 코드는 임포트와 연결된 디스패처에 대한 RVA를 가져오는 GET_STUB_DISPLACEMENT 헬퍼 함수를 호출합니다. 보호 모드에 따라 다음 루틴 중 하나가 사용됩니다.

그림 51: 보호 모드를 기반으로 스텁 RVA를 검색하는 루틴들
recover_import_stub 함수는 임포트 스텁의 제어 흐름 그래프(CFG)를 재구성하는 데 사용되며, _extract_lea_ref는 CFG의 명령어를 검사하여 obf_imp_t에 대한 lea 참조를 찾습니다. GET_DLL_API_NAMES 함수는 보호 모드에 따른 약간의 차이를 고려하여 GET_STUB_DISPLACEMENT와 유사하게 작동합니다.

그림 52: 보호 모드를 기반으로 DLL 및 API 블롭을 복호화하는 루틴들
복호화된 DLL 및 API 이름을 얻은 후, 코드는 보호 기법이 숨기는 임포트를 드러내기 위한 모든 필요한 정보를 갖게 됩니다. 각 임포트 항목의 최종 개별 출력은 RecoveredImport 객체와 두 개의 딕셔너리에 저장됩니다.
d.imports- 이 딕셔너리는 각 보호된 임포트의 주소를 복구된 상태에 매핑합니다. 이를 통해 바이너리에서 임포트가 발생하는 특정 위치와 전체 복구 세부 정보를 연결할 수 있습니다.
d.imp_dict_builder- 이 딕셔너리는 각 DLL 이름을 해당 API 이름의 집합에 매핑합니다. 이는 임포트 테이블을 재구성하여 바이너리에서 사용되는 고유한 DLL 집합과 API를 보장하는 데 사용됩니다.
이러한 체계적인 수집 및 구성은 난독화 해제된 출력에서 원래 기능을 복원하는 데 필요한 데이터를 준비합니다. 그림 53과 그림 54에서 성공적인 복구 후 이러한 두 컨테이너의 구조를 보여주는 것을 관찰할 수 있습니다.

그림 53: 성공적인 복구 후 d.imports 딕셔너리의 출력 결과

그림 54: 성공적인 복구 후 d.imp_dict_builder 딕셔너리의 출력 결과
최종 결과 관찰
이 마지막 단계, 즉 이 데이터를 사용하여 임포트 테이블을 재구성하는 작업은 pefile_utils.py 소스 파일의 build_import_table 함수에 의해 수행됩니다. 이 부분은 피할 수 없는 길이와 수많은 번거로운 단계로 인해 블로그 게시물에서 생략되었습니다. 그러나 코드는 임포트 테이블 재구성에 필요한 모든 측면을 철저히 다루고 보여주기 위해 주석이 잘 달려 있고 구조화되어 있습니다.
그럼에도 불구하고 다음 그림은 헤더가 없는 보호된 입력으로부터 완전히 작동하는 바이너리를 생성하는 방법을 보여줍니다. 헤더가 없는 보호된 입력은 셸코드 블롭과 거의 유사한 원시 헤더 없는 PE 바이너리라는 것을 기억하십시오. 이 블롭에서 임포트 보호가 완전히 복원된 완전히 새로운 작동하는 바이너리를 생성합니다. 그리고 모든 보호 모드에 대해 동일하게 수행할 수 있습니다.

그림 55: HEADERLESS 모드로 보호된 바이너리의 완전히 복원된 임포트 테이블 표시
난독화 해제된 바이너리에서 재배치 빌드
이제 보호된 바이너리의 CFG를 완전히 복구하고 원래 임포트 테이블을 완전히 복원할 수 있으므로, 난독화 해제기의 마지막 단계는 이러한 요소를 병합하여 작동하는 난독화 해제된 바이너리를 생성하는 것입니다. 이 프로세스를 담당하는 코드는 recover_output64.py 및 pefile_utils.py Python 파일에 캡슐화되어 있습니다.
재빌드 프로세스는 두 가지 주요 단계로 구성됩니다.
-
출력 이미지 템플릿 빌드
-
재배치 빌드
1. 출력 이미지 템플릿 빌드
난독화 해제된 바이너리를 생성하려면 출력 이미지 템플릿을 만드는 것이 필수적입니다. 여기에는 두 가지 주요 작업이 포함됩니다.
-
템플릿 PE 이미지: 모든 난독화된 구성 요소의 복원을 통합하는 출력 바이너리의 컨테이너 역할을 하는 PE(Portable Executable) 템플릿입니다. 또한 메모리 내 PE 실행 파일과 파일 내 PE 실행 파일 간의 모든 다양한 특성을 인식해야 합니다.
-
다양한 보호 모드 처리: 다양한 보호 모드 및 입력은 다양한 요구 사항을 규정합니다.
-
헤더가 없는 변형은 파일 헤더가 제거됩니다. 작동하는 바이너리를 정확하게 재구성하려면 이러한 변형을 고려해야 합니다.
-
선택적 보호는 기능을 유지하기 위해 원래 임포트를 보존하고 선택한 함수 내에서 활용되는 모든 임포트에 대한 특정 임포트 보호를 포함합니다.
2. 재배치 빌드
재배치 빌드는 난독화 해제 프로세스의 중요하고 복잡한 부분입니다. 이 단계는 난독화 해제된 바이너리 내의 모든 주소 참조가 기능을 유지하도록 올바르게 조정되었는지 확인합니다. 일반적으로 다음 두 단계를 중심으로 진행됩니다.
-
재배치 가능한 변위 계산: 재배치가 필요한 바이너리 내의 모든 메모리 참조를 식별합니다. 여기에는 이러한 참조가 가리키는 새 주소를 계산하는 작업이 포함됩니다. 사용할 기술은 원래 메모리 참조를 새 재배치 가능한 주소에 매핑하는 조회 테이블을 생성하는 것입니다.
-
수정 적용: 새 재배치 가능한 주소를 반영하도록 바이너리의 코드를 수정합니다. 이는 위에서 언급한 조회 테이블을 활용하여 메모리를 참조하는 모든 명령어 변위에 필요한 수정을 적용합니다. 이렇게 하면 바이너리 내의 모든 메모리 참조가 의도한 위치를 올바르게 가리키도록 보장됩니다.
출력 바이너리 이미지의 재빌드를 보여주는 세부 정보는 의도적으로 생략합니다. 이는 난독화 해제 프로세스에 필수적이지만 충분히 간단하고 자세히 살펴볼 가치가 없을 정도로 지나치게 번거롭기 때문입니다. 대신 재배치에만 집중합니다. 재배치는 더 미묘하고 명백하지 않지만 바이너리를 다시 작성할 때 이해해야 하는 중요한 특성을 드러내기 때문입니다.
재배치 프로세스 개요
재배치 재빌드는 난독화 해제된 바이너리를 실행 가능한 상태로 복원하는 중요한 단계입니다. 이 프로세스에는 코드가 이동되거나 수정된 후 모든 참조가 올바른 위치를 가리키도록 코드 내의 메모리 참조를 조정하는 작업이 포함됩니다. x86-64 아키텍처에서 이는 주로 RIP 상대 주소 지정(메모리 참조가 명령어 포인터에 상대적인 모드)을 사용하는 명령어와 관련됩니다.
재배치는 난독화 해제 중에 코드가 삽입, 제거 또는 이동되는 등 바이너리의 레이아웃이 변경될 때 필요합니다. 난독화 해제 접근 방식이 난독화 해제기에서 원래 명령어를 추출하므로 각 복구된 명령어를 새 코드 세그먼트에 적절하게 재배치해야 합니다. 이렇게 하면 난독화 해제된 상태가 모든 메모리 참조의 유효성을 유지하고 원래 제어 및 데이터 흐름의 정확성이 유지됩니다.
명령어 재배치 이해
명령어 재배치는 다음을 중심으로 진행됩니다.
- 명령어의 메모리 주소: 명령어가 상주하는 메모리 위치입니다.
- 명령어의 메모리 참조: 명령어의 피연산자가 사용하는 메모리 위치에 대한 참조입니다.
다음 두 명령어를 예시로 고려하십시오.

그림 56: 재배치가 필요한 두 명령어의 예시
-
무조건 점프
jmp명령어 이 명령어는 메모리 주소0x1000에 위치합니다. 주소0x4E22의 분기 대상을 참조합니다. 명령어 내에 인코딩된 변위는0x3E1D이며, 이는 명령어의 위치를 기준으로 분기 대상을 계산하는 데 사용됩니다. RIP 상대 주소 지정을 사용하므로 대상은 변위를 명령어 길이와 메모리 주소에 더하여 계산됩니다. -
lea명령어 이 명령어는0x4E22에 위치한jmp명령어의 분기 대상입니다. 또한 데이터 세그먼트에 대한 메모리 참조를 포함하며 인코딩된 변위는0x157입니다.
이러한 명령어를 재배치할 때 다음 두 가지 측면을 모두 처리해야 합니다.
- 명령어 주소 변경: 재배치 프로세스 중에 명령어를 새 메모리 위치로 이동하면 본질적으로 메모리 주소가 변경됩니다. 예를 들어 이 명령어를
0x1000에서0x2000으로 재배치하면 명령어 주소는0x2000이 됩니다. -
메모리 변위 조정: 명령어 내의 변위(
jmp의 경우0x3E1D,lea의 경우0x157)는 명령어의 원래 위치와 참조 위치를 기준으로 계산됩니다. 명령어가 이동하면 변위가 더 이상 올바른 대상 주소를 가리키지 않습니다. 따라서 명령어의 새 위치를 반영하도록 변위를 다시 계산해야 합니다.

그림 57: 재배치가 어떻게 보이는지를 보여주는 업데이트된 그림
난독화 해제 과정에서 명령어를 재배치할 때 정확한 제어 흐름과 데이터 접근을 보장해야 합니다. 이를 위해서는 명령어의 메모리 주소와 다른 메모리 위치를 참조하는 모든 변위를 조정해야 합니다. 이러한 값을 업데이트하지 못하면 복구된 CFG가 무효화됩니다.
RIP 상대 주소 지정이란 무엇입니까?
RIP 상대 주소 지정은 실행될 다음 명령어를 가리키는 RIP(명령어 포인터) 레지스터를 기준으로 오프셋에서 메모리를 참조하는 모드입니다. 절대 주소를 사용하는 대신 명령어는 현재 명령어 포인터에서 부호 있는 32비트 변위를 통해 참조된 주소를 캡슐화합니다.
명령어 포인터를 기준으로 주소를 지정하는 것은 x86에도 존재하지만 상대 변위를 지원하는 제어 전송 명령어(예: JCC 조건부 명령어, 근거리 CALL, 근거리 JMP)에만 해당합니다. x64 ISA는 거의 모든 메모리 참조가 RIP 상대 주소 지정이 되도록 이를 확장했습니다. 예를 들어 x64 Windows 바이너리의 대부분의 데이터 참조는 RIP 상대 주소 지정입니다.
디코딩된 Intel x64 명령어의 복잡성을 시각화하는 훌륭한 도구는 ZydisInfo입니다. 여기서는 이를 사용하여 LEA 명령어(488D151B510600으로 인코딩됨)가 0x6511b에서 RIP 상대 메모리를 참조하는 방법을 보여줍니다.

그림 58: lea 명령어에 대한 ZydisInfo 출력
대부분의 명령어에서 변위(displacement)는 명령어의 마지막 4바이트에 인코딩됩니다. 즉시 값(immediate value)이 메모리 위치에 저장될 때 즉시 값은 변위 뒤에 옵니다. 즉시 값은 최대 32비트로 제한되며, 이는 64비트 즉시 값을 변위 뒤에 사용할 수 없음을 의미합니다. 그러나 이 인코딩 체계 내에서 8비트 및 16비트 즉시 값은 지원됩니다.

그림 59: 즉시 피연산자를 저장하는 mov 명령어에 대한 ZydisInfo 출력
제어 전송 명령어의 변위는 즉시 피연산자로 인코딩되며, RIP 레지스터가 암묵적으로 베이스 역할을 합니다. 이는 jnz 명령어를 디코딩할 때 명확하게 드러나는데, 변위가 명령어 내에 직접 포함되고 현재 RIP를 기준으로 계산되기 때문입니다.

그림 60: 변위로 즉시 피연산자를 사용하는 jnz 명령어에 대한 ZydisInfo 출력
재배치 프로세스의 단계
재배치를 재구성하기 위해 다음 접근 방식을 취합니다.
-
코드 섹션 재구성 및 재배치 맵 생성 복구된 CFG 및 임포트를 사용하여 완전히 난독화 해제된 코드를 포함하는 새 코드 섹션에 변경 사항을 커밋합니다. 다음과 같이 수행합니다.
-
함수별 처리: 각 함수를 한 번에 하나씩 재구성합니다. 이렇게 하면 각 함수 내에서 각 명령어의 재배치를 관리할 수 있습니다.
-
명령어 위치 추적: 각 함수를 재구성하면서 각 명령어의 새 메모리 위치를 추적합니다. 여기에는 원래 명령어 주소를 난독화 해제된 바이너리의 새 주소에 매핑하는 전역 재배치 딕셔너리를 유지하는 작업이 포함됩니다. 이 딕셔너리는 수정 단계에서 참조를 정확하게 업데이트하는 데 중요합니다.
-
수정 적용 코드 섹션을 재구성하고 재배치 맵을 설정한 후에는 난독화 해제된 바이너리의 올바른 위치를 가리키도록 명령어를 수정합니다. 이렇게 하면 바이너리의 전체 기능이 복원되고 명령어가 가질 수 있는 코드 또는 데이터에 대한 메모리 참조를 조정하여 수행됩니다.
코드 섹션 재구성 및 재배치 맵 생성
새 난독화 해제된 코드 세그먼트를 구성하기 위해 복구된 각 함수를 반복하고 고정된 오프셋(예: 0x1000)부터 시작하여 모든 명령어를 순차적으로 복사합니다. 이 과정에서 각 명령어를 재배치된 주소에 매핑하는 전역 재배치 딕셔너리(global_relocs)를 빌드합니다. 이 매핑은 수정 단계에서 메모리 참조를 조정하는 데 필수적입니다.
global_relocs 딕셔너리는 튜플을 조회 키로 사용하며 각 키는 해당 명령어가 나타내는 재배치된 주소와 연결됩니다. 튜플은 다음 세 가지 구성 요소로 구성됩니다.
-
함수의 원래 시작 주소: 보호된 바이너리에서 함수가 시작되는 주소입니다. 명령어에 속하는 함수를 식별합니다.
-
함수 내의 원래 명령어 주소: 보호된 바이너리에서 명령어의 주소입니다. 함수의 첫 번째 명령어의 경우 함수의 시작 주소가 됩니다.
-
합성 경계 JMP 플래그: 정규화 중에 도입된 합성 경계 점프 명령어인지 여부를 나타내는 부울 값입니다. 이러한 합성 명령어는 원래 난독화된 바이너리에 없었으며 원래 주소가 없기 때문에 재배치 중에 특별히 고려해야 합니다.

그림 61: 새 코드 세그먼트와 재배치 맵이 생성되는 방식에 대한 그림
다음 Python 코드는 그림 61에 설명된 논리를 구현합니다. 간결함을 위해 오류 처리 및 로깅 코드는 제거되었습니다.

그림 62: 코드 세그먼트 빌드 및 재배치 맵 생성을 구현하는 Python 논리
- 현재 오프셋 초기화
코드 섹션이 배치될 새 이미지 버퍼의 시작점을 설정합니다. 변수curr_off는 일반적으로 0x1000인starting_off로 초기화됩니다. 이는 PE 파일의.text섹션의 일반적인 시작 주소를 나타냅니다. SELECTIVE 모드의 경우 보호된 함수의 시작 오프셋이 됩니다. - 복구된 함수 반복
난독화 해제된 제어 흐름 그래프(d.cfg)에서 복구된 각 함수를 반복합니다.func_ea는 원래 함수 진입 주소이고rfn은 복구된 함수의 명령어 및 메타데이터를 캡슐화하는RecoveredFunc객체입니다.- 함수 시작 주소를 먼저 처리
-
함수의 재배치된 시작 주소 설정: 새 이미지 버퍼에서 이 함수가 시작될 위치를 표시하는 현재 오프셋을
rfn.reloc_ea에 할당합니다. - 전역 재배치 맵 업데이트: 원래 함수 주소를 새 위치에 매핑하기 위해 전역 재배치 맵
d.global_relocs에 항목을 추가합니다.
-
- 각 복구된 명령어 반복
함수 내의normalized_flow을 반복합니다. 정규화된 흐름을 사용하면 새 이미지에 적용할 때 각 명령어를 선형으로 반복할 수 있습니다.- 명령어의 재배치된 주소 설정: 새 이미지 버퍼에서 이 명령어가 상주할 위치를 나타내는 현재 오프셋을
r.reloc_ea에 할당합니다. - 전역 재배치 맵 업데이트: 명령어의 원래 주소를 재배치된 주소에 매핑하는 명령어에 대한
d.global_relocs에 항목을 추가합니다. - 출력 이미지 업데이트: 현재 오프셋에서 새 이미지 버퍼
d.newimgbuffer에 명령어 바이트를 씁니다. 명령어가 난독화 해제 중에 수정된 경우(r.updated_bytes) 해당 바이트를 사용하고, 그렇지 않으면 원래 바이트(r.instr.bytes)를 사용합니다. - 오프셋 진행: 버퍼의 다음 빈 위치를 가리키도록 명령어 크기만큼
curr_off를 증가시키고 나머지 명령어가 소진될 때까지 다음 명령어로 이동합니다.
- 명령어의 재배치된 주소 설정: 새 이미지 버퍼에서 이 명령어가 상주할 위치를 나타내는 현재 오프셋을
- 함수 시작 주소를 먼저 처리
- 현재 오프셋을 16바이트 경계로 정렬 함수의 모든 명령어를 처리한 후
curr_off를 다음 16바이트 경계로 정렬합니다. 마지막 명령어에서 패딩할 마지막 명령어에서 임의의 포인터 크기 값으로 8바이트를 사용하여 다음 함수가 이전 함수의 마지막 명령어와 충돌하지 않도록 합니다. 이렇게 하면 x86-64 아키텍처의 성능 및 정확성에 필수적인 다음 함수의 적절한 메모리 정렬이 추가로 보장됩니다. 그런 다음 모든 함수가 소진될 때까지 2단계부터 프로세스를 반복합니다.
이 단계별 프로세스는 난독화 해제된 바이너리의 실행 가능한 코드 섹션을 정확하게 재구성합니다. 각 명령어를 재배치함으로써 코드는 참조가 올바른 위치를 가리키도록 조정되는 후속 수정 단계를 위한 출력 템플릿을 준비합니다.
수정 적용
난독화 해제된 코드 섹션을 빌드하고 복구된 각 함수를 완전히 재배치한 후 복구된 코드 내의 주소를 수정하기 위해 수정을 적용합니다. 이 프로세스는 새 출력 이미지의 명령어 바이트를 조정하여 모든 참조가 올바른 위치를 가리키도록 합니다. 이는 작동하는 난독화 해제된 바이너리를 재구성하는 마지막 단계입니다.
수정은 주로 제어 흐름 또는 데이터 흐름 명령어에 적용되는지 여부에 따라 세 가지 고유한 범주로 분류합니다. 또한 두 가지 유형의 제어 흐름 명령어를 구별합니다. 표준 분기 명령어와 임포트 보호를 통해 난독화 해제기가 도입한 명령어입니다. 각 유형에는 특정 미묘한 차이가 있으므로 각 범주에 정확한 논리를 적용할 수 있도록 맞춤형 처리가 필요합니다.
-
임포트 재배치: 복구된 임포트에 대한 호출 및 점프와 관련됩니다.
-
제어 흐름 재배치: 모든 표준 제어 흐름 분기 명령어입니다.
-
데이터 흐름 재배치: 정적 메모리 위치를 참조하는 명령어입니다.
이러한 세 가지 범주화를 사용하여 핵심 논리는 다음 두 단계로 요약됩니다.
- 변위 수정 해결
- 즉시 피연산자(분기 명령어)로 인코딩된 변위와 메모리 피연산자(데이터 접근 및 임포트 호출)로 인코딩된 변위를 구별합니다.
- 이전에 생성된
d.global_relocs맵을 사용하여 이러한 변위에 대한 올바른 수정 값을 계산합니다.
- 출력 이미지 버퍼 업데이트
- 변위가 해결되면 변경 사항을 영구적으로 반영하기 위해 업데이트된 명령어 바이트를 새 코드 세그먼트에 씁니다.
이를 위해 여러 도우미 함수와 람다 표현식을 활용합니다. 다음은 수정을 계산하고 명령어 바이트를 업데이트하는 코드를 단계별로 설명한 것입니다.
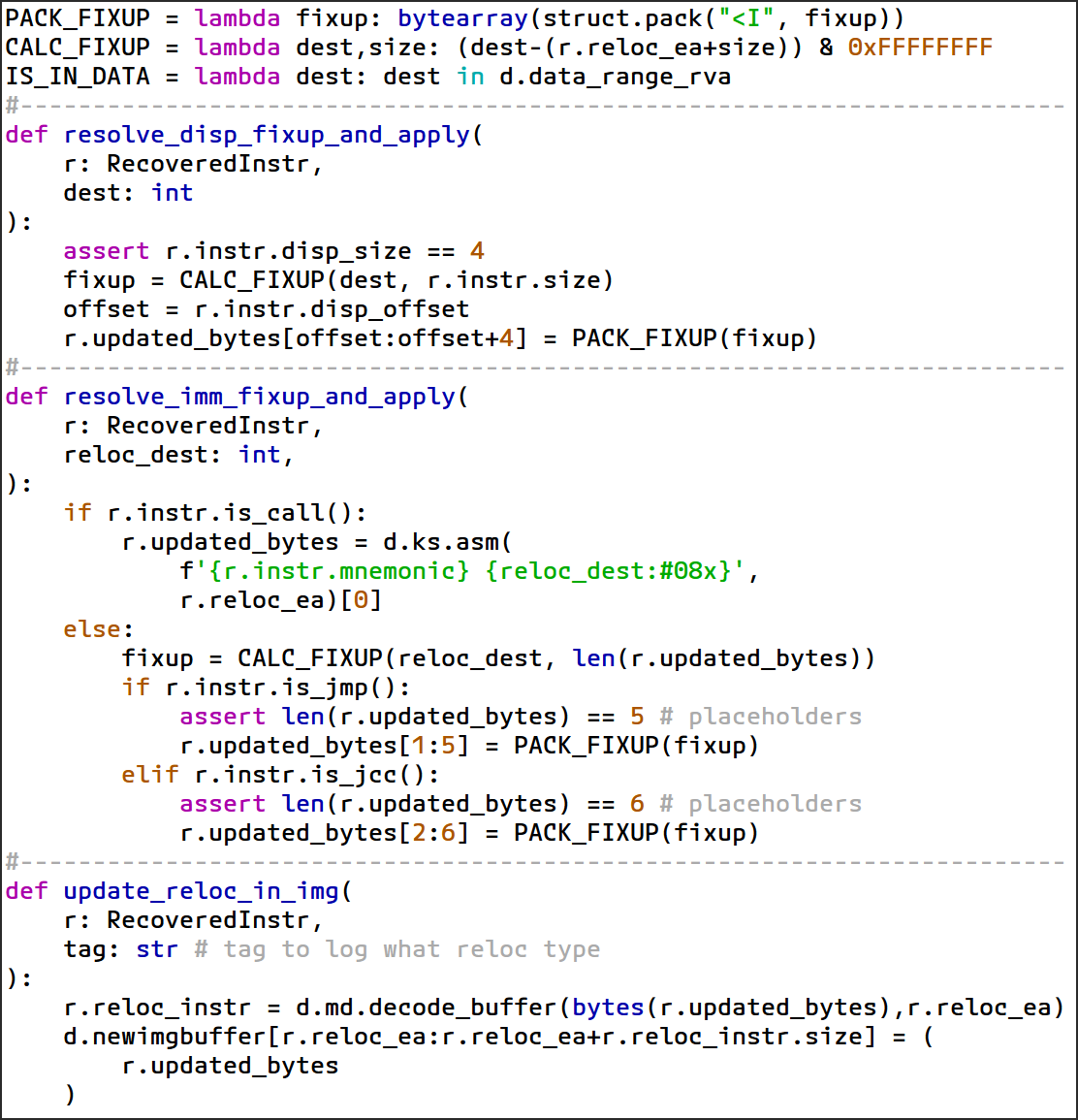
그림 63: 수정 적용을 돕는 도우미 루틴들
- 람다 도우미 표현식 정의
PACK_FIXUP: 32비트 수정 값을 리틀 엔디안 바이트 배열로 압축합니다.CALC_FIXUP: 대상 주소(dest)와 현재 명령어의 끝(r.reloc_ea + size) 사이의 차이를 계산하여 32비트 내에 맞는지 확인하여 수정 값을 계산합니다.IS_IN_DATA: 주어진 주소가 바이너리의 데이터 섹션 내에 있는지 확인합니다. 데이터 섹션은 원래 위치에 보존하므로 이러한 주소의 재배치는 제외합니다.
- 각 명령어에 대한 수정 해결
- 임포트 및 데이터 흐름 재배치
- 메모리 피연산자 내에 변위를 인코딩하므로
resolve_disp_fixup_and_apply도우미 함수를 활용합니다.
- 메모리 피연산자 내에 변위를 인코딩하므로
- 제어 흐름 재배치
- 변위가 즉시 피연산자에 인코딩되므로
resolve_imm_fixup_and_apply도우미 함수를 사용합니다. - CFG 복구 중에 1바이트 짧은 분기의 단점을 피하기 위해 각
jmp및jcc명령어를 근거리 점프 동등 명령어(2바이트에서 6바이트로)로 변환했습니다
- 모든 수정에 충분한 범위를 보장하기 위해 각 분기에 대해 32비트 변위를 강제합니다.
- 변위가 즉시 피연산자에 인코딩되므로
- 임포트 및 데이터 흐름 재배치
- 출력 이미지 버퍼 업데이트
- 업데이트된 명령어 바이트를 디코딩하여 해당 명령어를 나타내는
RecoveredInstr내에 반영되도록 합니다. - 업데이트된 바이트를 새 이미지 버퍼에 씁니다.
updated_bytes는 완전히 재배치된 명령어의 최종 opcode를 반영합니다.
- 업데이트된 명령어 바이트를 디코딩하여 해당 명령어를 나타내는
도우미 함수가 준비되면 다음 Python 코드는 각 재배치 유형에 대한 최종 처리를 구현합니다.

그림 64: 각 재배치 범주를 처리하는 세 가지 핵심 루프
- 임포트 재배치: 첫 번째
for루프는 임포트 복구 단계에서 생성된 데이터를 활용하여 임포트 재배치에 대한 수정을 처리합니다.rfn.relocs_imports캐시 내의 모든 복구된 명령어r을 반복하고 다음을 수행합니다.- 업데이트된 명령어 바이트 준비: 수정 준비를 위해 원래 명령어 바이트의 변경 가능한 복사본으로
r.updated_bytes를 초기화합니다. - 임포트 항목 및 변위 검색:
d.imports딕셔너리에서 임포트 항목을 가져오고 임포트의 API 이름을 사용하여d.import_to_rva_map에서 새 RVA를 검색합니다. - 수정 적용:
resolve_disp_fixup_and_apply도우미 함수를 사용하여 새 RVA에 대한 수정을 계산하고 적용합니다. 이렇게 하면 임포트된 함수를 올바르게 참조하도록 명령어의 변위가 조정됩니다. - 이미지 버퍼 업데이트:
update_reloc_in_img를 사용하여r.updated_bytes를 새 이미지에 다시 씁니다. 이렇게 하면 출력 이미지의 명령어에 대한 수정이 완료됩니다.
- 업데이트된 명령어 바이트 준비: 수정 준비를 위해 원래 명령어 바이트의 변경 가능한 복사본으로
- 제어 흐름 재배치: 두 번째
for루프는 제어 흐름 분기 재배치(call, jmp, jcc)에 대한 수정을 처리합니다.rfn.relocs_ctrlflow의 각 항목을 반복하면서 다음을 수행합니다.- 대상 검색: 즉시 피연산자에서 원래 분기 대상 대상을 추출합니다.
- 재배치된 주소 가져오기: 재배치 딕셔너리
d.global_relocs를 참조하여 분기 대상의 재배치된 주소를 가져옵니다. 호출 대상인 경우 호출된 함수의 시작에 대한 재배치된 주소를 구체적으로 조회합니다. - 수정 적용:
resolve_imm_fixup_and_apply를 사용하여 분기 대상을 재배치된 주소로 조정합니다. - 버퍼 업데이트:
update_reloc_in_img를 사용하여r.updated_bytes를 새 이미지에 다시 써서 수정을 완료합니다.
- 데이터 흐름 재배치: 마지막 루프는
rfn.relocs_dataflow에 저장된 모든 정적 메모리 참조의 해결을 처리합니다. 먼저 데이터 참조 재배치가 필요한 KNOWN 명령어 목록을 설정합니다. 이러한 명령어의 광범위한 다양성을 고려할 때 이 분류는 접근 방식을 단순화하고 보호된 바이너리에 존재하는 모든 가능한 명령어를 포괄적으로 이해할 수 있도록 합니다. 다음으로 논리는 임포트 및 제어 흐름 재배치와 유사하게 관련 명령어를 체계적으로 처리하여 메모리 참조를 정확하게 조정합니다.
코드 섹션을 재구성하고 재배치 맵을 설정한 후 난독화 해제된 바이너리 내에서 재배치하도록 분류된 각 명령어를 조정했습니다. 이렇게 하면 각 명령어가 의도한 코드 또는 데이터 세그먼트를 정확하게 참조하도록 보장되므로 출력 바이너리의 전체 기능을 복원하는 마지막 단계가 됩니다.
결과 관찰
ScatterBrain에 대한 난독화 해제 라이브러리를 시연하기 위해 기능을 보여주는 테스트 연구를 수행합니다. 이 테스트 연구를 위해 POISONPLUG.SHADOW 헤더 없는 백도어와 두 개의 임베디드 플러그인이라는 세 가지 샘플을 선택합니다.
라이브러리를 소비하고 앞에서 설명한 모든 복구 기술을 구현하는 Python 스크립트 example_deobfuscator.py를 개발합니다. 그림 65와 그림 66은 예제 난독화 해제기 내의 코드를 보여줍니다.

그림 65: example_deobfuscator.py의 Python 코드 전반부

그림 66: example_deobfuscator.py의 Python 코드 후반부
example_deobfuscator.p를 실행하면 다음을 볼 수 있습니다. 헤더 없는 백도어에서 발견된 16,000개 이상의 명령어 디스패처를 에뮬레이션해야 하므로 약간의 시간이 걸립니다
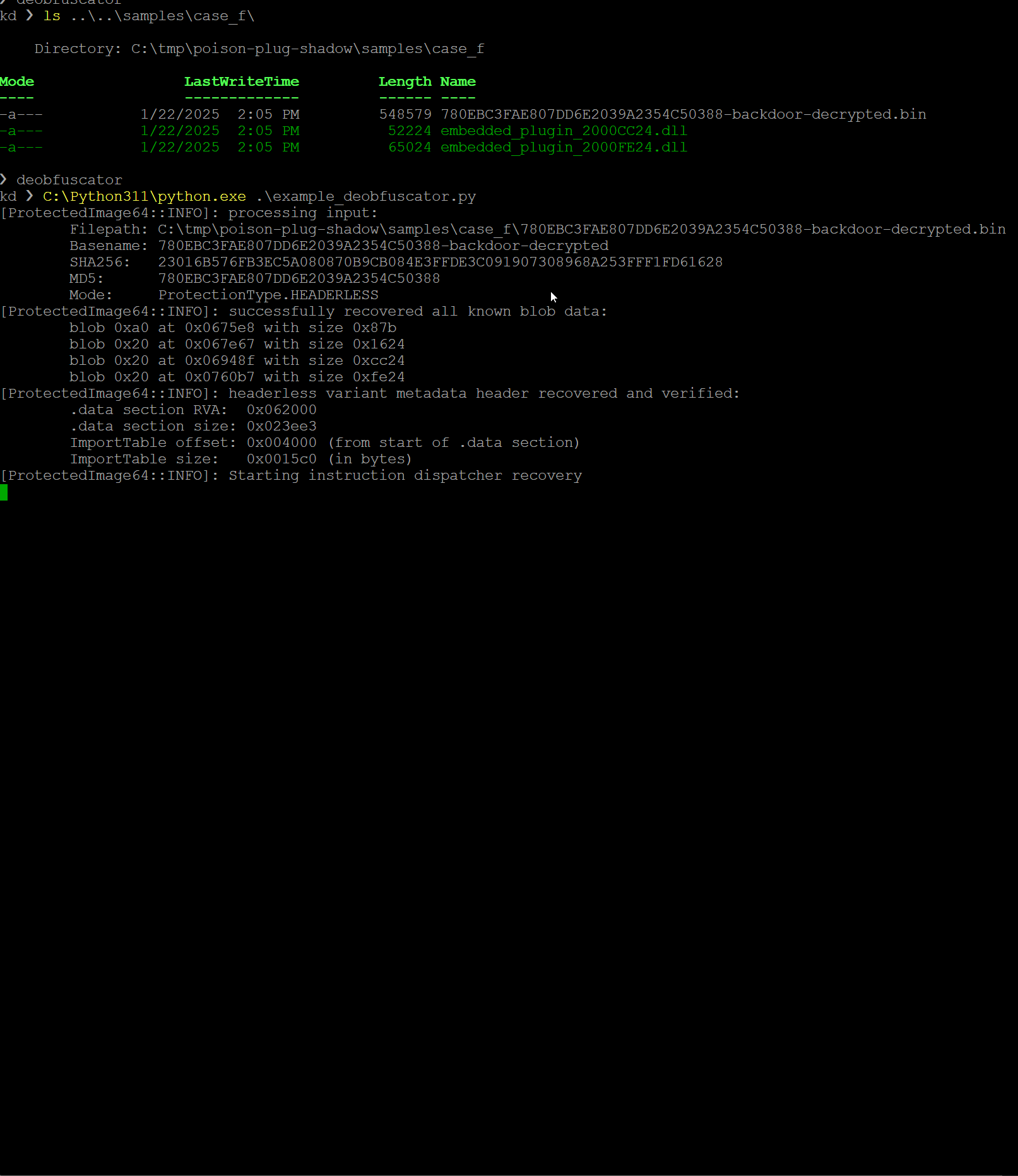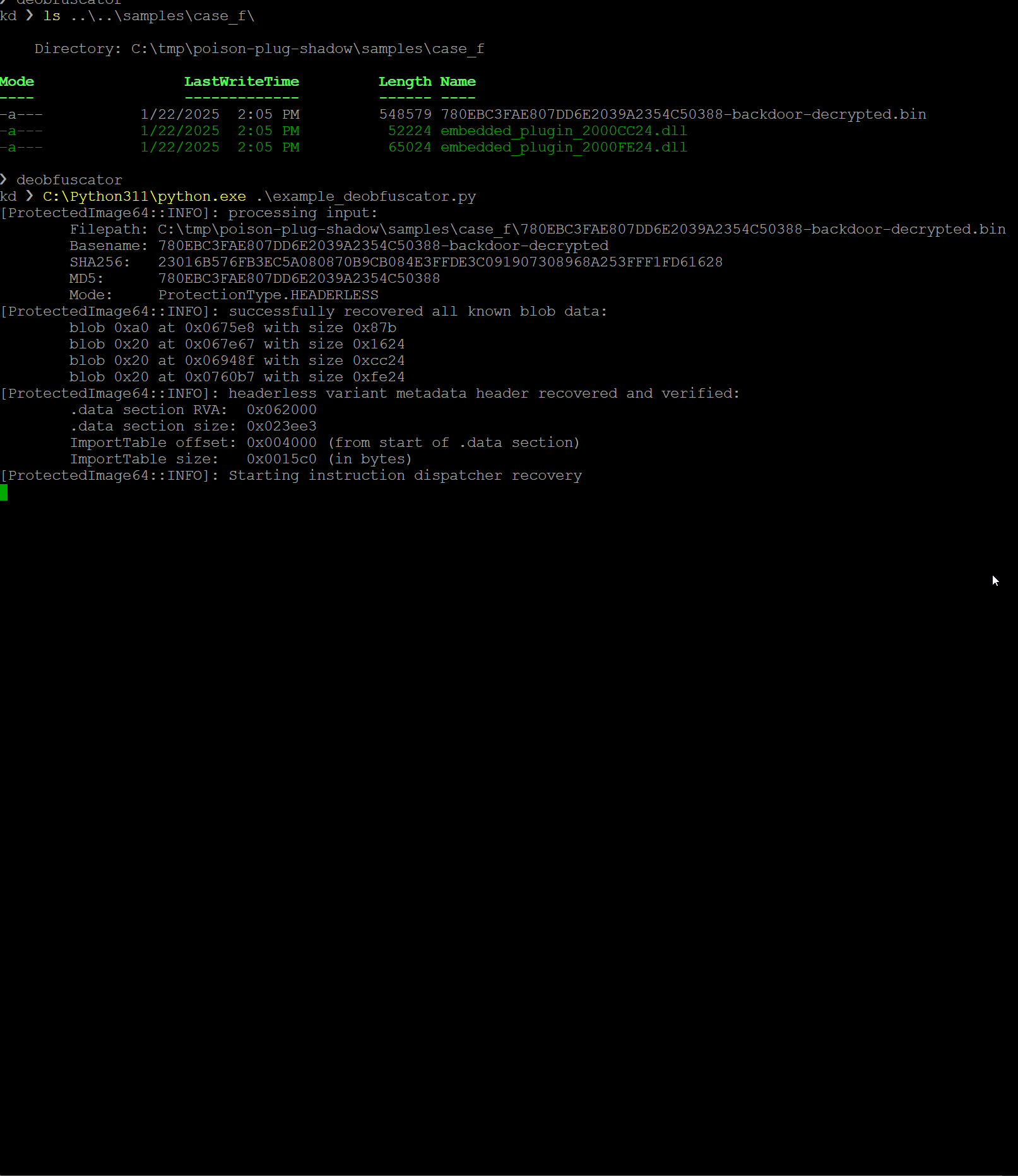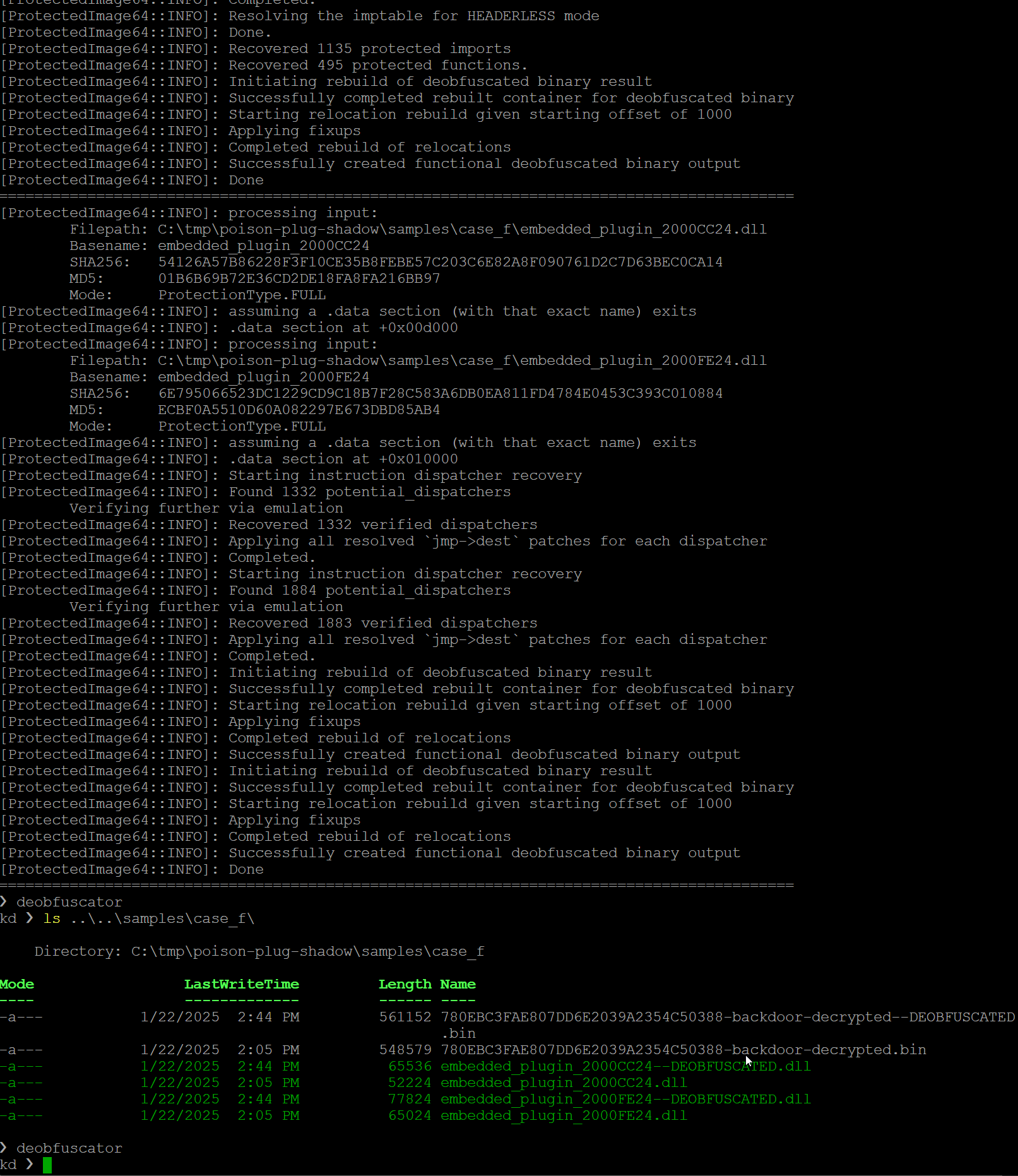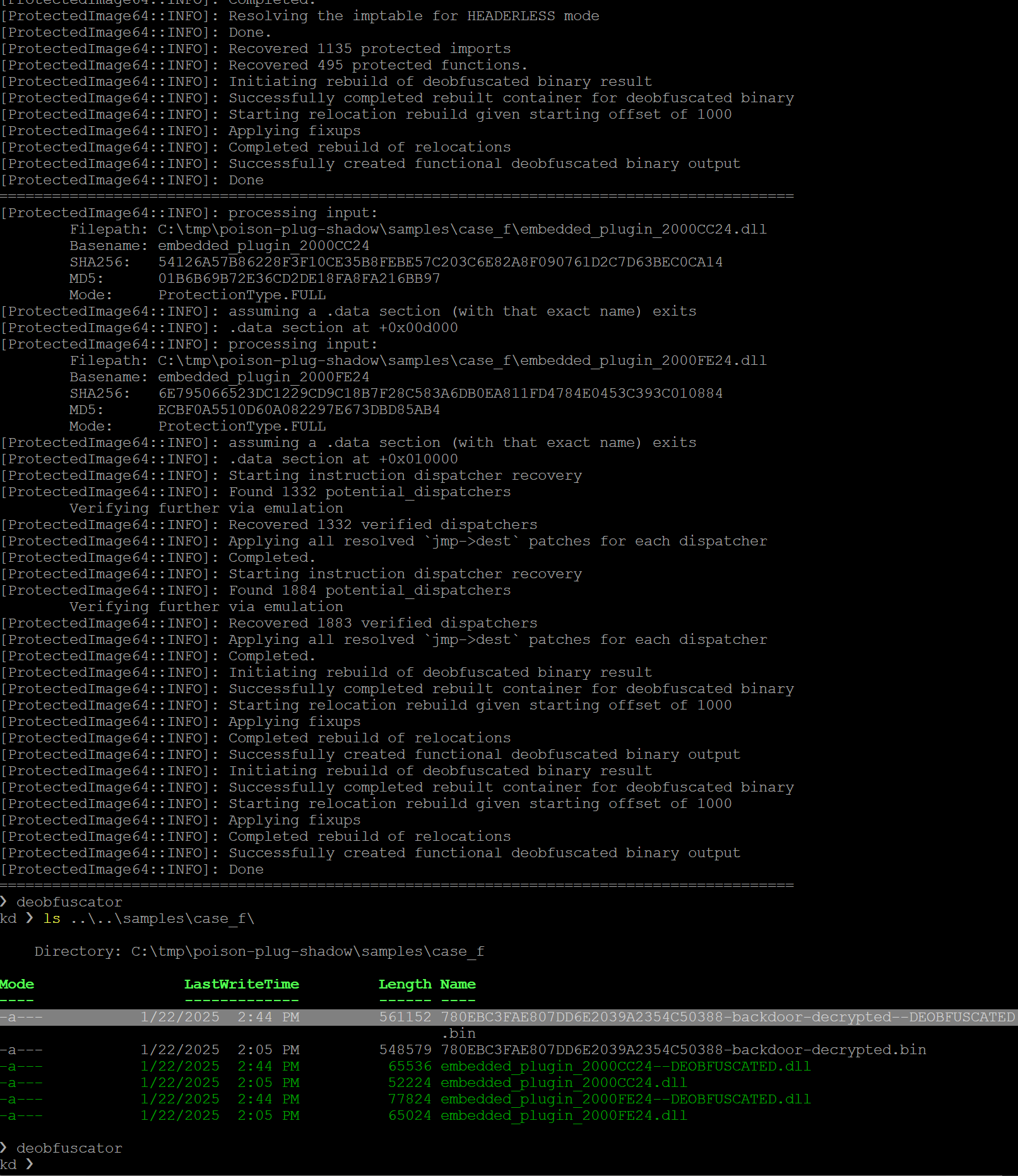
그림 67: 각 재배치 범주를 처리하는 세 가지 핵심 루프
간결함을 위해, 그리고 난독화 해제에 가장 많은 작업이 필요한 헤더 없는 백도어에 초점을 맞춰, 난독화 해제기의 출력 결과를 검사하기 전에 먼저 IDA Pro 디스어셈블러 내부에서 초기 상태를 관찰합니다. 우리는 그것이 사실상 분석이 불가능하다는 것을 알 수 있습니다.
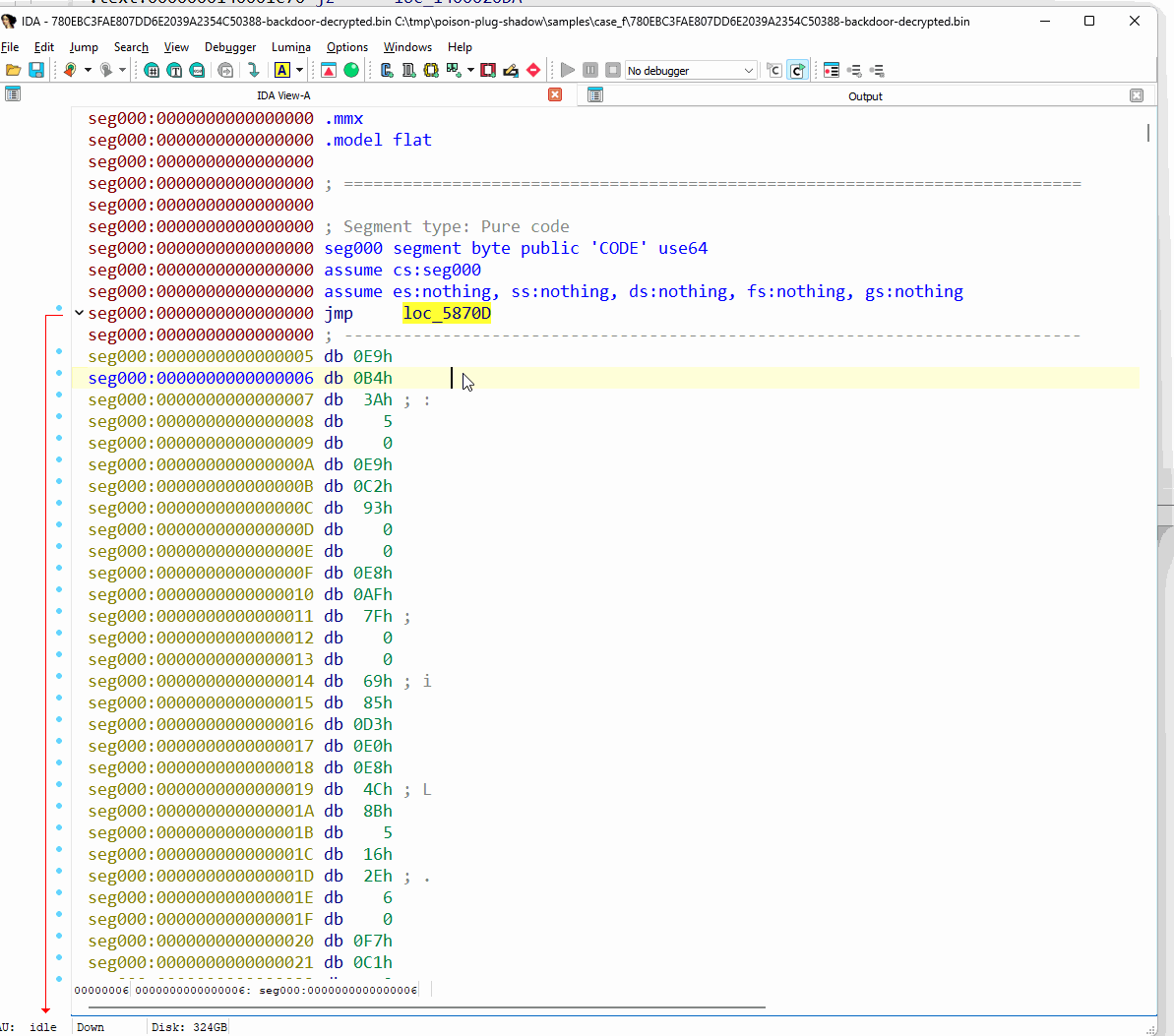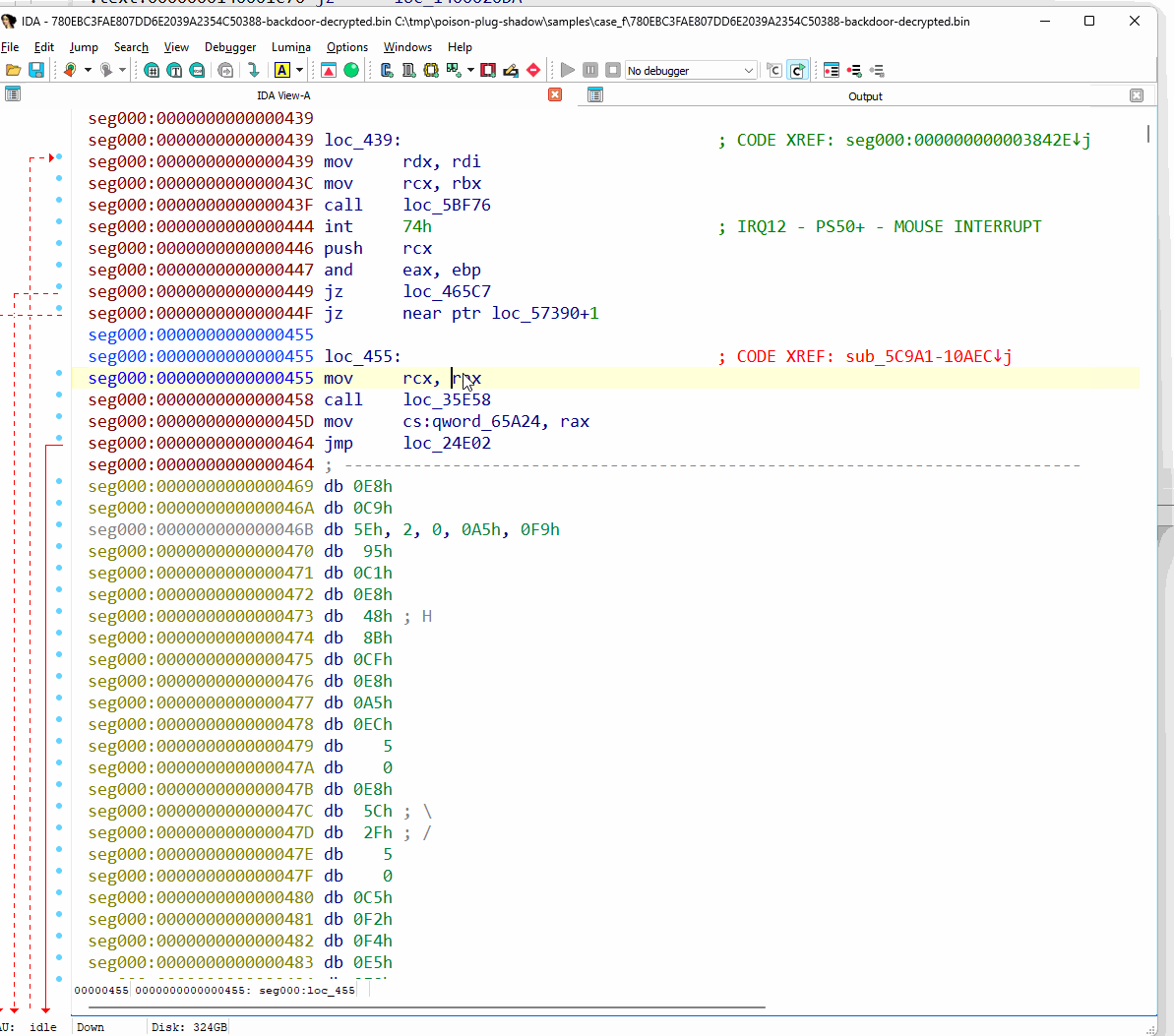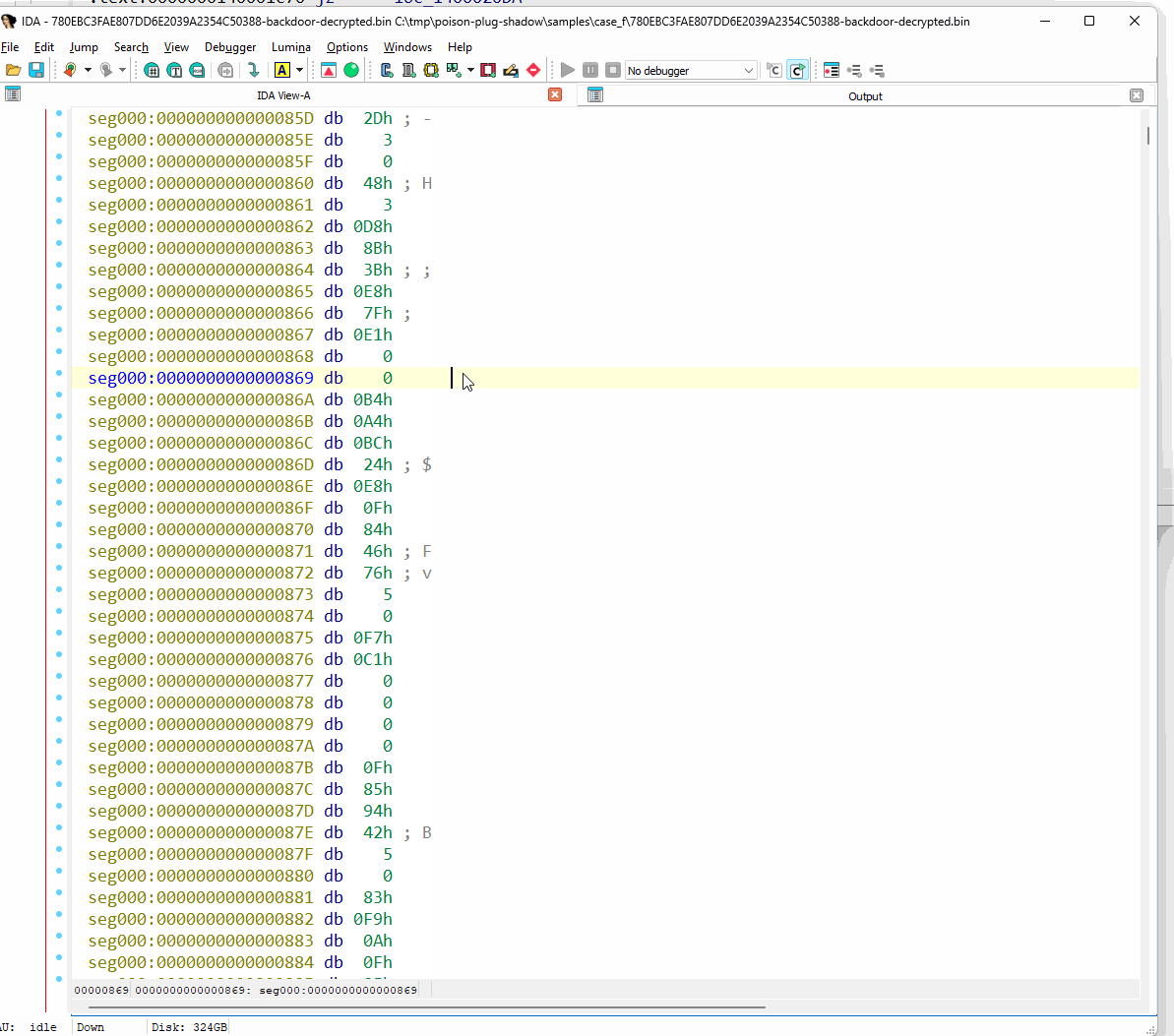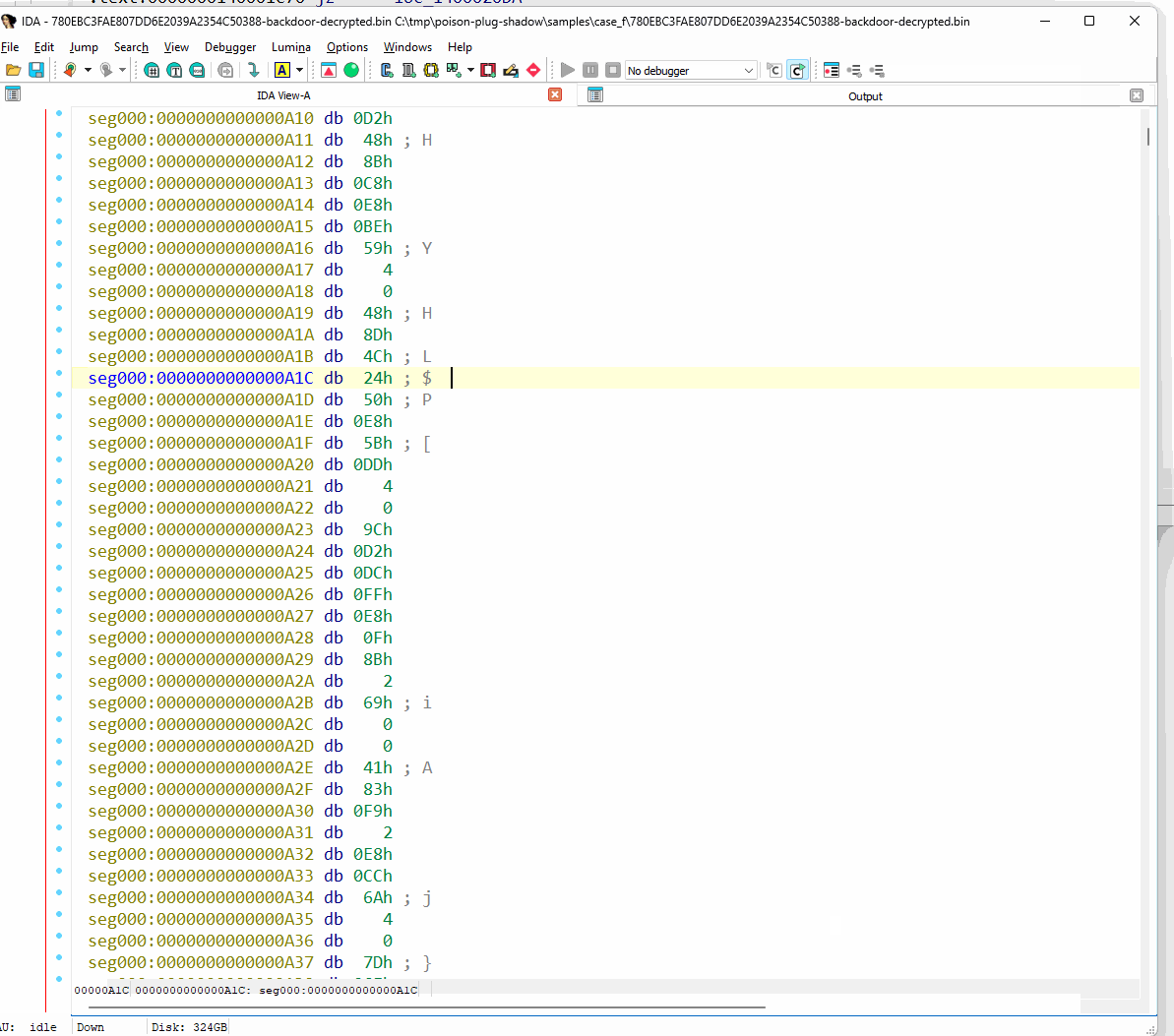
그림 68: IDA Pro에서 난독화된 헤더 없는 백도어 관찰
예제 난독화 해제기를 실행하고 완전히 새로운 난독화 해제된 바이너리를 생성한 후 출력에서 극적인 차이를 확인할 수 있습니다. 모든 원래 제어 흐름이 복구되었고, 모든 보호된 임포트가 복원되었으며, 필요한 모든 재배치가 적용되었습니다. 또한 ScatterBrain이 제거하는 헤더 없는 백도어의 의도적으로 제거된 PE 헤더도 처리합니다.
그림 69: IDA Pro에서 난독화 해제된 헤더 없는 백도어 관찰
출력의 일부로 작동하는 바이너리를 생성하므로, 결과 난독화 해제된 바이너리는 직접 실행하거나 원하는 디버거에서 디버깅할 수 있습니다.
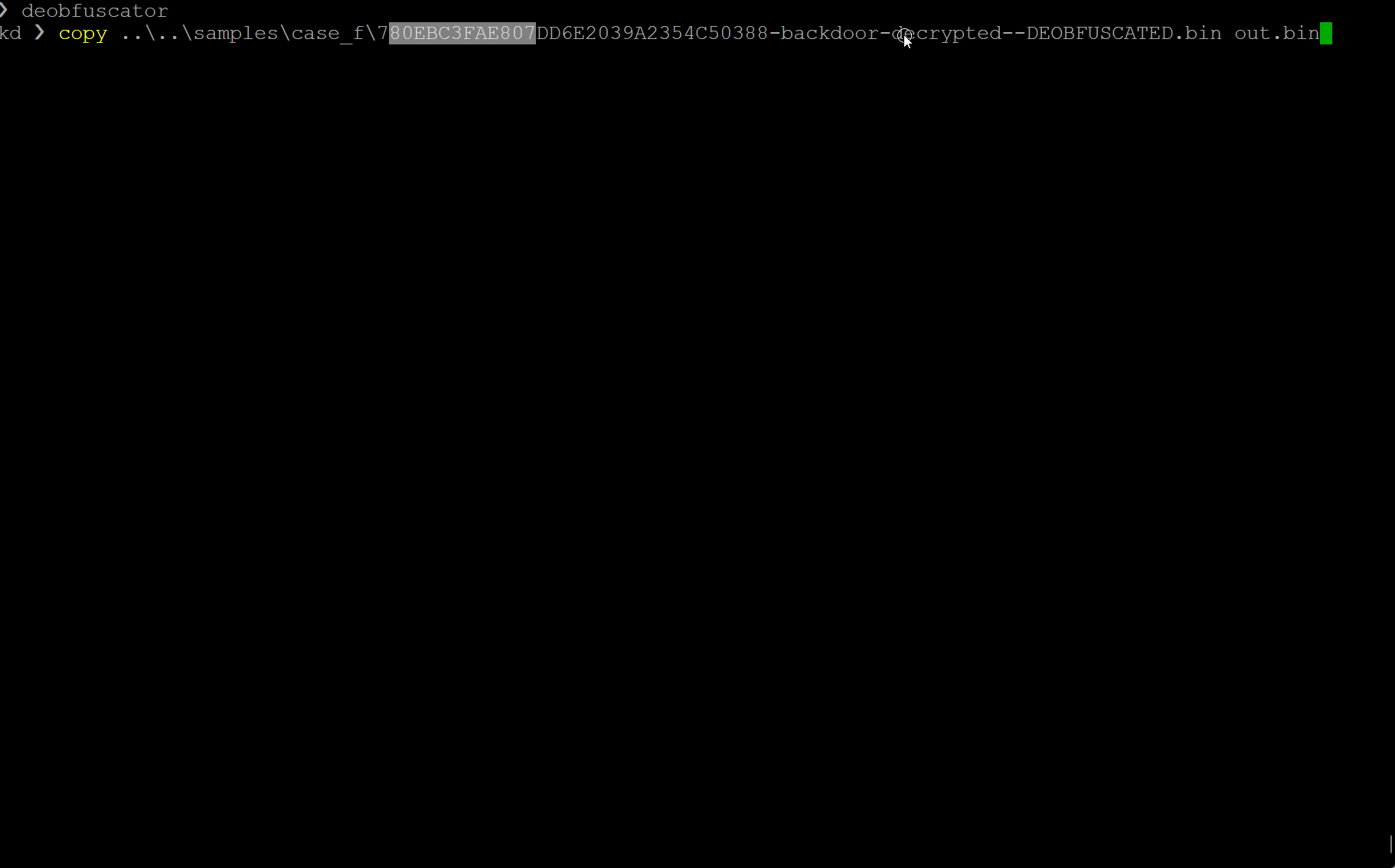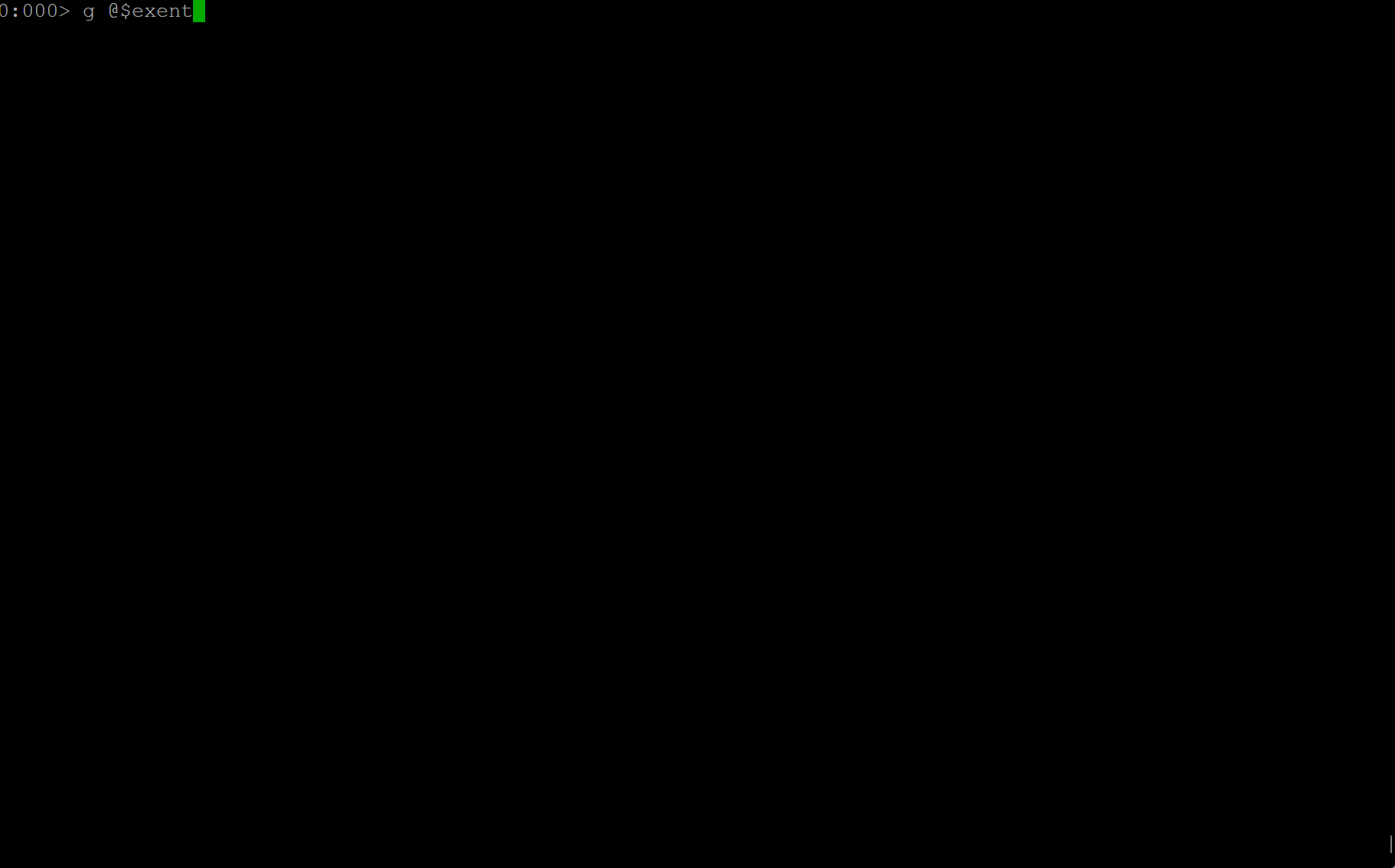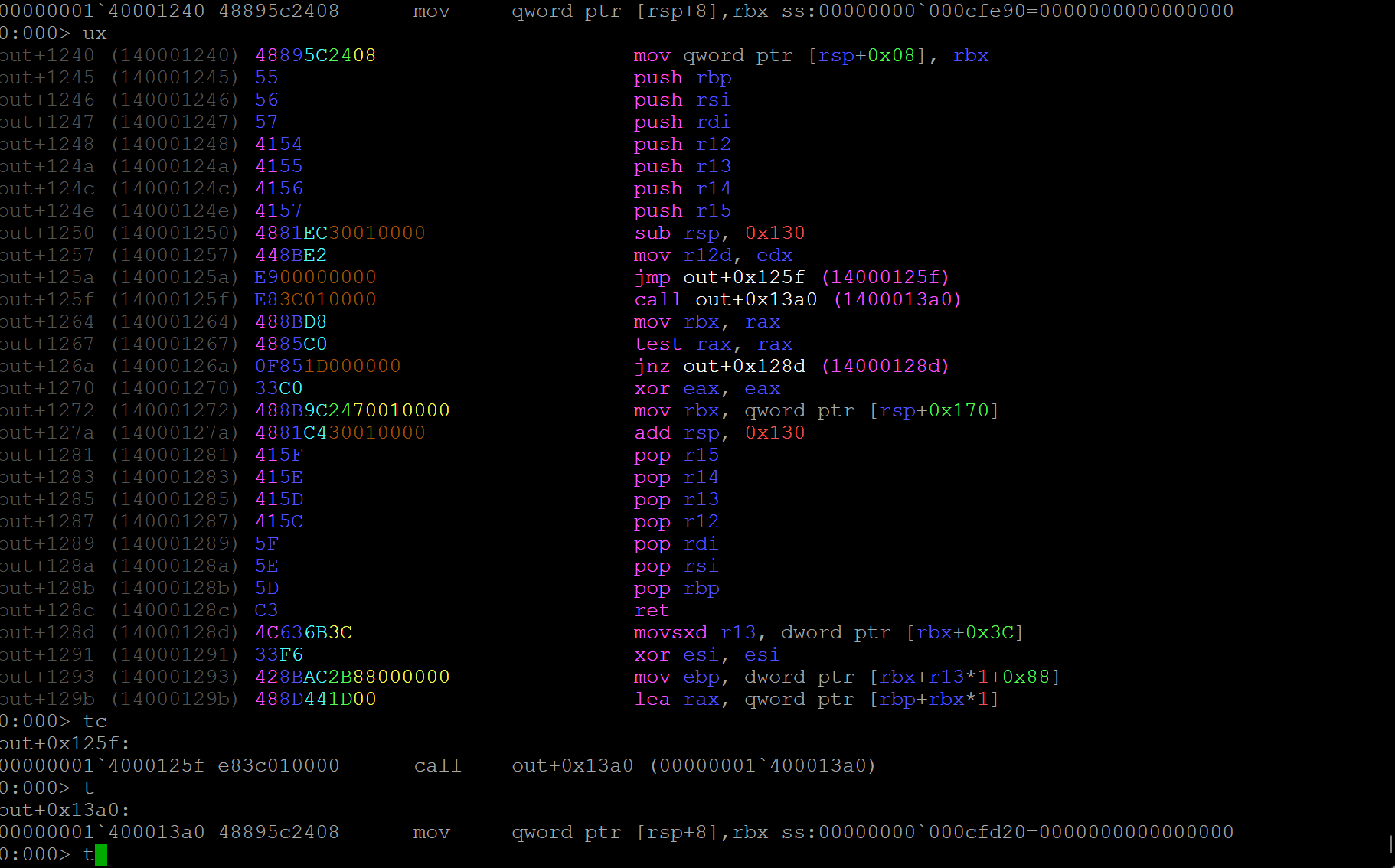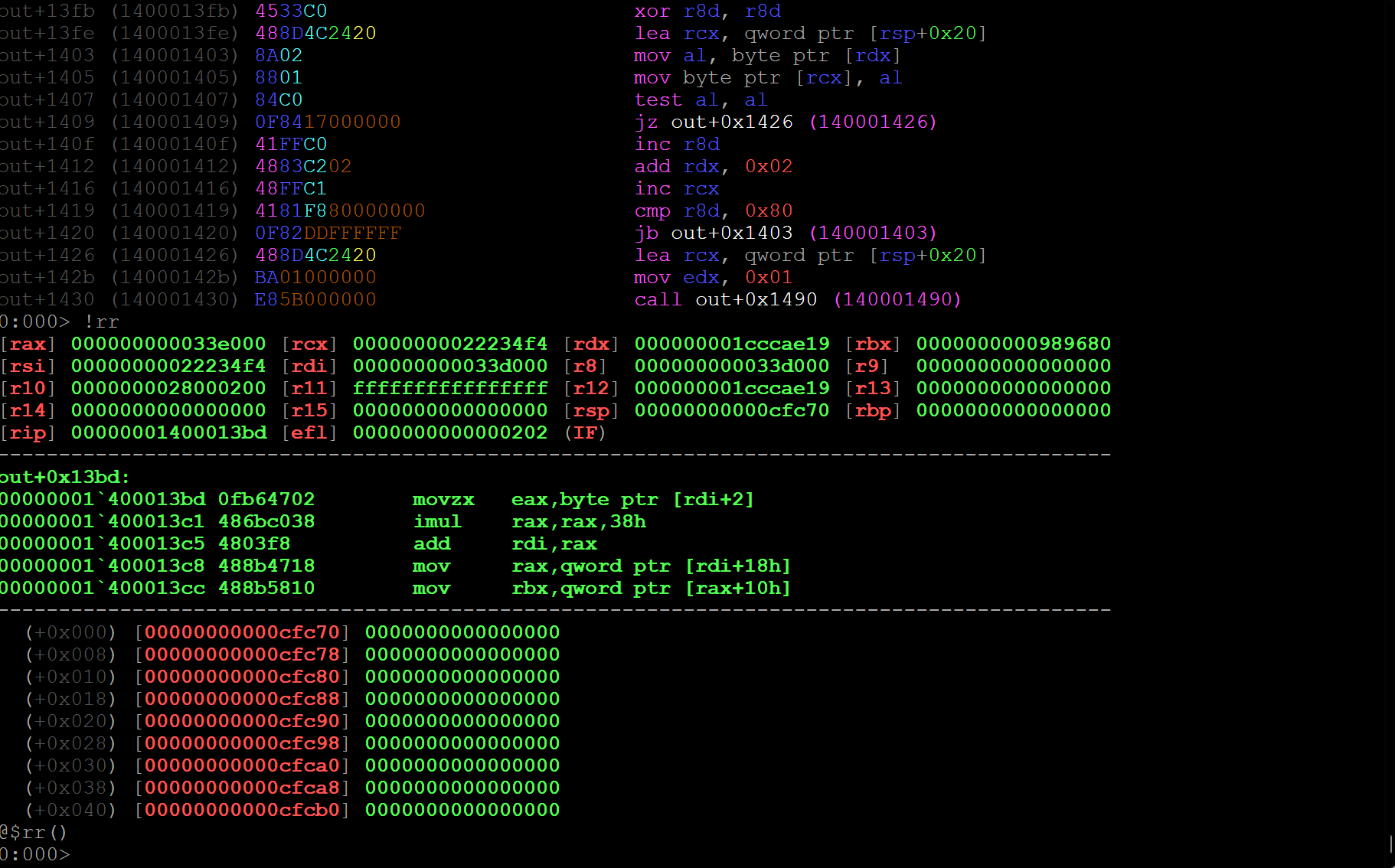
그림 70: 모두가 가장 좋아하는 디버거에서 난독화 해제된 헤더 없는 백도어 디버깅
결론
이 블로그 게시물에서는 2022년부터 GTIG가 추적해 온 특정 중국 관련 위협 행위자들이 활용하는 고급 모듈형 백도어인 POISONPLUG.SHADOW에서 사용되는 정교한 ScatterBrain 난독화 도구를 심층적으로 살펴보았습니다. ScatterBrain에 대한 탐색을 통해 방어자들에게 제기되는 복잡한 과제를 강조했습니다. 각 보호 메커니즘을 체계적으로 설명하고 해결함으로써 효과적인 난독화 해제 솔루션을 만드는 데 필요한 상당한 노력을 보여주었습니다.
궁극적으로 우리는 우리의 연구가 분석가와 사이버 보안 전문가에게 유용한 통찰력과 실용적인 도구를 제공하기를 바랍니다. 방법론을 발전시키고 협력적인 혁신을 촉진하려는 우리의 노력은 POISONPLUG.SHADOW와 같은 정교한 위협에 맞서 싸우는 최전선에 서도록 보장합니다. 이 철저한 검토와 난독화 해제 도구의 소개를 통해 우리는 고도로 난독화된 악성웨어로 인한 위험을 완화하기 위한 지속적인 노력에 기여하고 진화하는 적대적 전술에 대한 사이버 보안 방어의 복원력을 강화합니다.
침해 지표 (IOC)
이 게시물에서 설명된 활동과 관련된 침해 지표(IOC)를 포함하는 Google 위협 인텔리전스 컬렉션을 사용할 수 있습니다.
호스트 기반 IOC
감사의 말
POISONPLUG 위협을 이해하고 퇴치하기 위한 Mandiant와 Google의 노력에 기여한 Google 위협 인텔리전스 그룹의 Conor Quigley와 Luke Jenkins에게 특별한 감사를 드립니다. 또한 정교한 적대자에 대한 사이버 보안 방어를 강화하는 데 중요한 역할을 한 Google 팀의 지속적인 지원과 헌신에 감사드립니다.
