데이터의 바다를 누비는 해적: AI로 레드팀 활동 강화
Mandiant
* 해당 블로그의 원문은 2024년 11월 15일 Google Cloud 블로그(영문)에 게재되었습니다.
작성자: Matthijs Gielen, Jay Christiansen
배경
새로운 솔루션들, 오래된 문제들, 그리고 AI와 거대 언어 모델(Large Language Model, 이하 LLM)은 사이버 보안의 새로운 시대를 예고하고 있습니다. 그렇다면 이러한 발전이 공격자와 방어자에게 어떤 의미가 있을까요? 그리고 방대한 데이터 속에서 보안을 개선하려는 방어자의 노력에 어떤 영향을 미칠까요?
데이터는 어디에나 존재합니다. 시대가 바뀌면서 데이터를 수집하는 것을 넘어선 도전 과제가 등장하고 있습니다. 방대한 데이터의 양, 그 안에 존재하는 필요 없거나 의미 없는 정보, 다양한 위치에 분산되어 있는 데이터, 그리고 수집한 데이터를 어떻게 이해하고 해석할 것인가? 이런 것이 앞으로 풀어가야 할 과제입니다.
레드팀 활동을 수행할 때 네트워크, 사용자, 도메인 데이터를 이해하고 해석하는 것은 공격 경로를 찾는 것 외에도 보안 데이터와 관련한 새로운 도전 과제를 풀기 위한 열쇠를 찾는 데에도 도움이 됩니다. 레드팀 활동을 하면 공격자와 방어자의 시각으로 데이터를 분석할 수 있으므로 보안에 대한 통찰력을 얻고, 위협을 최소화하고, 시스템을 강화할 수 있습니다. 가령 레드팀 작업 내용을 방어의 관점에서 보면 쉽게 접근할 수 있는 자격 증명 같은 위험 요소를 신속히 찾아내고 우선순위를 정하는 데 도움이 됩니다.
그렇다면 방어자는 나날이 늘어만 가는 보안 관련 정형, 비정형 데이터를 어떻게 해석하여 경쟁 우위를 확보할 수 있을까요? AI는 모든 것을 바꿀 가능성이 있습니다.
이번 포스팅에서는 글로벌 고객을 위해 레드팀 활동을 하면서 맨디언트가 축적한 사례 연구를 바탕으로 가상의 공격 활동 중에 수집한 데이터를 AI와 LLM 시스템을 활용해 구조화하고 분석한 내용을 소개합니다. 더불어 맨디언트가 배운 교훈과 주요 내용을 공유하며, 레드팀과 블루팀 모두에게 도움이 될 수 있는 다양한 문제 해결 방안도 제시합니다.
접근 방식
AI가 처음 등장했을 때부터 가장 잘하는 일 중 하나가 복잡한 데이터를 쉽게 이해하고 분석하는 것입니다. 우리는 여러 사례를 통해 AI가 데이터를 빠르게 처리하는 데 도움을 줄 수 있음을 확인했습니다. 본 포스팅에서는 구조화되지 않은 비정형 데이터를 LLM으로 처리한 방법을 살펴봅니다. 참고로 비정형 데이터란 파싱(parsing)을 하기 전에 형식이나 구조를 알 수 없는 데이터를 의미합니다. 대표적인 비정현 데이터가 문서입니다.
본 포스팅에서 소개하는 작업을 직접 해보고 싶다면, 온프레미스 환경에 LLM을 배포해 사용하거나 데이터를 외부 서비스로 전송할 수 있는 권한을 확보한 다음에 퍼블릭 클라우드가 제공하는 API로 LLM을 쓸 수 있는 서비스를 이용해야 합니다.
LLM을 통한 구조화된 데이터 생성
첫 번째 단계는 데이터를 활용 가능한 형식으로 변환하는 것입니다. LLM을 사용해 본 적이 있다면, 특히 채팅 기반 AI 어시스턴트의 경우 LLM이 주로 이야기나 산문 형태의 텍스트를 생성한다는 것을 잘 알 것입니다. 이러한 출력 형식은 많은 경우 문제가 없지만, 데이터를 분석하거나 구조화된 형태로 얻고 싶을 때는 적합하지 않을 수 있습니다. 따라서, 먼저 LLM이 데이터를 지정된 형식으로 출력하도록 만들어야 합니다.
가장 간단한 방법은 LLM에 JSON, XML, CSV처럼 기계가 읽을 수 있는 형식으로 데이터를 출력해 달라고 요청하는 것입니다. 하지만 LLM이 지시를 무시하고 다른 형식으로 데이터를 생성할 가능성이 있으므로, 원하는 데이터 형식에 대해 매우 구체적이고 명확하게 지시해야 합니다.
다행히 이러한 문제는 Guardrails라는 프로젝트를 통해 해결할 수 있습니다. Guardrails는 Python 라이브러리로, 모델이 특정 요구 사항을 준수하도록 합니다. 예를 들어 Pydantic을 사용해 데이터를 검증할 수 있습니다.
간단한 Python 클래스 예제를 통해 Guardrails의 사용법을 알아보겠습니다.
먼저 Guardrails의 등장 배경을 알아보겠습니다. 이 프로젝트는 AI 어시스턴의 답변을 데이터를 분석하거나 구조화된 형태로 받기 위한 방안을 찾던 이들이 모여 시작하였습니다. 맨디언트가 발견한 프로젝트 중 하나인 guardrails-ai는 Python 라이브러리로 Pydantic을 기반으로 모델에 특정 요구 사항을 설정할 수 있도록 도와줍니다.
LLM의 출력을 활용해 Pet 클래스 데이터를 검증하는 간단한 Python 클래스의 예제를 통해 사용법을 알아보겠습니다.
from pydantic import BaseModel, Field
class Pet(BaseModel):
pet_type: str = Field(description="Species of pet")
name: str = Field(description="a unique pet name")이제 Guardrails 문서에 나와 있는 코드를 사용해 LLM의 출력을 구조화된 객체로 처리할 수 있습니다.
from guardrails import Guard
import openai
prompt = """
What kind of pet should I get and what should I name it?
${gr.complete_json_suffix_v2}
"""
guard = Guard.from_pydantic(output_class=Pet, prompt=prompt)
raw_output, validated_output, *rest = guard(
llm_api=openai.completions.create,
engine="gpt-3.5-turbo-instruct"
)
print(validated_output)라이브러리가 프롬프트를 처리하면서 생성한 구조화된 객체를 살펴보면 LLM이 데이터를 특정 형식으로 출력하도록 유도하는 지침이 포함된 것을 알 수 있습니다. 이를 통해 LLM에서 구조화된 데이터를 얻는 과정을 훨씬 더 간편하게 만들 수 있습니다.

그림 1: Pydantic 모델에서 생성된 프롬프트
다음에 소개할 레드팀 사례 연구 내용을 통해 구조화된 데이터를 처리하기 위해 우리가 생성한 Pydantic 모델을 소개하겠습니다.
레드팀 사례 연구
이제 LLM을 사용하여 데이터를 처리한 활용 사례를 알아보겠니다. 사례는 공격 수명 주기의 세 가지 주요 단계로 나뉩니다:
-
초기 정찰
-
권한 상승
-
내부 정찰
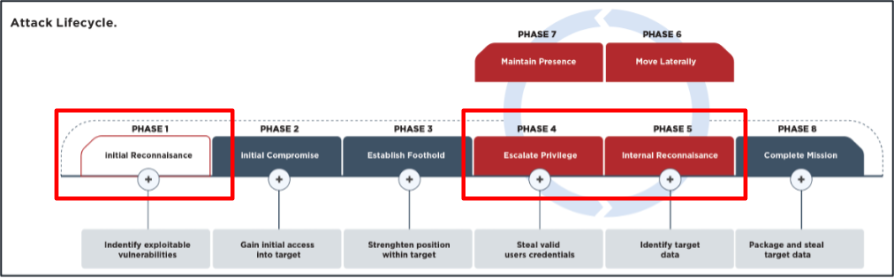
그림 2. 공격 수명 주기
초기 정찰
공개적으로 접근 가능한 정보인 오픈 소스 인텔리전스(OSINT)는 레드팀 활동에서 매우 중요한 역할을 합니다. 공격자 역할을 담당한 레드팀의 팀원은 뉴스 기사, 소셜 미디어, 기업 보고서 등 다양한 공개 채널에서 목표로 삼은 조직에 대한 정보를 수집합니다.
이렇게 수집한 정보는 피싱과 같은 다른 레드팀 작업 단계에서 활용할 수 있습니다. 방어 측면에서는 오픈 소스 인텔리전스를 참조해 조직의 어떤 부분이 인터넷에 노출되어 있는지 파악하고, 이를 바탕으로 향후 공격 가능성을 예측할 수 있습니다. 다음에 소개하는 사례에서 소셜 미디어 정보를 분석해 초기 침투 대상으로 삼은 조직에 속한 이들의 직무와 역할을 파악하고, 그 과정에서 유용한 정보를 추출하는 방법을 알아보겠습니다.
사례 1: 소셜 미디어 정보 활용
레드팀 활동에서 중요한 단계 중 하나는 오픈 소스 인텔리전스를 참조해 타깃 조직 직원들이 회사 내에서 어떤 역할을 맡고 있는지 파악하는 것입니다. 이 정보는 특히 피싱 공격 시 유용합니다. 이를 통해 IT 전문가나 보안팀과 같이 초기 침투 시도를 알아챌 수 있는 타깃을 피할 수 있기 때문입니다.
소셜 미디어 플랫폼에서는 사용자들이 자신의 직책을 자유롭게 입력할 수 있습니다. 이들 정보는 다양한 언어와 형식으로 표현되는 비정형 데이터로 구성됩니다.
단순한 패턴 매칭만으로는 이러한 정보를 효과적으로 추출하기 어려울 수 있습니다. LLM을 활용하면 더 정확하고 효율적으로 데이터를 분석하고 필요한 정보를 추출할 수 있습니다.
데이터 모델
다음으로 소셜 미디어 데이터를 처리해 역할을 추출하는 데 사용되는 Pydantic 모델의 활용 방법을 살펴보겠습니다. 먼저, Guardrails를 위한 Pydantic 모델을 생성합니다.
class RoleOutput(BaseModel):
role: str = Field(description="Role being analyzed")
it: bool = Field(description="The role is related to IT")
cybersecurity: bool = Field(description="The role is related to
CyberSecurity")
experience_level: str = Field(
description="Experience level of the role.",
)이 모델은 역할이 IT 또는 사이버 보안과 관련이 있는지를 나타내는 IT와 관련이 있는지, 또는 사이버 보안과 관련이 있는지를 나타내는 불리언(Boolean) 옵션을 포함하고 있습니다. 또한, 해당 직무를 수행하는 사람이 가진 전문성이나 숙련도를 파악할 수 있도록 설계되었습니다.
프롬프트
다음으로 LLM이 필요한 정보를 추출하도록 지시하는 프롬프트를 생성해 보겠습니다. 이 프롬프트는 매우 간단한데, LLM이 요청된 데이터를 채울 수 있도록 안내하는 방식으로 작성하였습니다.
Given the following role, answer the following questions.
If the answer doesn't exist in the role, enter ``.
${role}
${gr.complete_xml_suffix_v2}결과
모델을 테스트하기 위해 소셜 미디어에서 직원들이 사용하는 직함을 스크래핑하여 데이터 세트를 구성했습니다. 이 데이터 세트에는 총 235개의 직함이 포함되어 있습니다. 테스트는 gemini-1.0-pro 모델을 사용해 진행했습니다.
테스트 결과 Gemini는 총 232개의 직함을 성공적으로 파싱 했습니다. 자세한 결과는 아래 표에서 확인할 수 있습니다.
결과를 놓고 보면 Gemini는 사람과 거의 유사한 수준으로 역할을 처리했음을 알 수 있습니다. 대부분의 오탐은 해당 역할이 실제로 IT와 관련이 있는지 명확하지 않은 경우에서 발생했습니다. 한편, 경험 수준에 대한 결과는 대부분의 항목이 “알 수 없음” 또는 “없음”으로 판단되어 기대에 미치지 못했습니다. 이를 개선하기 위해 경험 수준을 1에서 10까지의 숫자 체계로 변경했습니다. 수정된 모델로 분석을 다시 실행한 결과 경험 수준에 대한 결과가 크게 향상되었습니다. 가장 낮은 경험 수준(1~4)에는 “인턴”, “전문가”, “보조”와 같은 직책이 포함되었으며, 이는 일반적으로 해당 역할에서 근무한 기간이 짧다는 것을 나타냅니다. 업데이트된 데이터 모델은 다음과 같습니다.
class RoleOutput(BaseModel):
role: str = Field(description="Role being analyzed")
it: bool = Field(description="The role is related to IT")
cybersecurity: bool = Field(description="The role is related to
CyberSecurity")
experience_level: int = Field(
description="Estimate of the experience level of the role on
a scale of 1-10. Where 1 is low experience and 10 is high.",
)이 접근 방식을 통해 IT나 사이버 보안 역할을 맡고 있지 않은 직원들을 식별하고, 이들의 직무 역량을 가늠해 볼 수 있는 경험 수준별로 분류하여 대규모 조직에서 타깃을 더 빠르고 효율적으로 선택할 수 있습니다. 또한, 프롬프트나 선택 기준을 조정하면 공격자의 행동을 더욱 사실적으로 모방할 수 있습니다. 방어적인 관점에서는 데이터 분석이 더 까다로워질 수 있습니다. 모든 직원에게 직책에 “사이버 보안”을 포함하도록 지시할 수는 있지만, 이는 비효율적일 뿐 아니라 근본적인 피싱 문제를 해결하지 못합니다. 피싱 공격을 효과적으로 방어하기 위해 가장 좋은 방법은 강력한 다중 인증(MFA)과 애플리케이션 허용 목록을 도입하는 것입니다. 이러한 솔루션을 적절히 적용하면 피싱을 초기 침투 경로로 이용하는 공격을 효과적으로 차단할 수 있습니다.
권한 상승
공격자가 조직 내부에 침투하면 가장 먼저 시도하는 것 중 하나가 권한 상승을 통해 더 높은 접근 권한이나 통제력을 확보하는 일입니다. 이를 위해 다양한 방법을 동원하는데, 크게 시스템 내부에서 실행되는 로컬 방식과 조직 전체를 대상으로 하는 도메인 방식으로 나눌 수 있습니다. 일부 방법은 취약점 악용이나 잘못된 시스템 설정을 이용하고, 또 다른 방법은 파일 검색을 통해 민감한 정보를 찾아내는 것에 초점을 둡니다.
이 포스팅에서는 특히 방대한 데이터 속에서 원하는 정보를 찾아내는 문제와 유사한 파일 검색 기반 권한 상승에 중점을 두고자 합니다.
사례 2: 파일 내 자격 증명 찾기
공격자가 타깃 네트워크에 초기 접근 권한을 획득한 후 가장 흔히 사용하는 정보 수집 방법 중 하나는 공유 파일을 열람하여 중요한 정보를 포함한 파일을 찾는 것입니다. 이 작업은 Snaffler 같은 도구를 통해 수행할 수 있습니다. 공격자는 자격 증명과 같은 민감한 정보를 포함한 파일을 발견한 다음에 수작업 방식으로 검토하여 유용한 내용을 추출할 수 있습니다. 하지만 대규모 조직에서는 수백에서 수천 개의 파일을 검토해야 할 수도 있습니다. 이러한 상황에서는 TruffleHog이나 Nosey Parker와 같은 도구가 유용하며, detect-secrets 같은 Python 라이브러리도 이 작업에 도움을 줄 수 있습니다.
이러한 도구들은 주로 알려진 패턴이나 파일 형식을 기반으로 탐지를 수행합니다. 그러나 알려지지 않은 파일 형식이나 이메일처럼 특이한 형식에 포함된 자격 증명을 찾기 위해서는 LLM을 활용해 파일을 분석하는 것이 더 효과적일 수 있습니다. 기술적으로 이러한 도구들을 조합하여 실행한 다음에 선형 회귀 모델을 사용해 결과를 결합할 수도 있습니다. 아래는 테스트 과정에서 발견된 암호가 포함된 파일의 익명화 예시입니다.
@Echo Off
Net Use /Del * /Yes
Set /p Path=<"path.txt"
Net Use %Path% Welcome01@ /User:CHAOS.LOCAL\WorkstationAdmin
If Not Exist "C:\Data" MKDIR "C:\Data"
Copy %Path%\. C:\Data
Timeout 02데이터 모델
Gemini에게 도메인이 포함된 자격 증명을 검색하도록 지시하기 위해 아래와 같은 Python 클래스를 사용했습니다. 하나의 파일에 여러 자격 증명이 포함될 수 있기 때문에 Gemini가 파일에서 여러 자격 증명을 찾아낼 수 있도록 자격 증명 목록을 제공합니다.
class Credential(BaseModel):
password: str = Field(description="Potential password of an account")
username: str = Field(description="Potential username of an account")
domain: Optional[str] = Field(
description="Optional domain of an account", default=""
)
class ListOfCredentials(BaseModel):
credentials: list[Credential] = []프롬프트
프롬프트에서 우리가 찾고자 하는 시스템의 종류를 몇 가지 예로 제시하고, 그 결과를 JSON 형식으로 출력하도록 요청합니다.
Given the following file, check if there are credentials in the file.
Only include results if there is at least one username and password.
If the domain doesn't exist in the file, enter `` as a default value.
${file}
${gr.complete_xml_suffix_v2}결과
600개의 파일 중 304개는 자격 증명이 포함되어 있었고, 296개는 포함되지 않았습니다. Gemini-1.5 모델을 사용해 테스트를 진행했으며, 각 파일의 처리 시간은 약 5초가 소요되었습니다.
결과를 다른 도구와 비교하기 위해 Nosey Parker와 TruffleHog도 함께 테스트했습니다. 두 도구는 파일뿐만 아니라 리포지토리에서도 구조화된 방식으로 자격 증명을 탐지하도록 설계되었으며, 주로 알려진 파일 형식과 비정형 파일 구조를 대상으로 합니다.
테스트 결과는 표 2에 요약되어 있습니다.
표 2에 나와 있는 용어인 참음성(True Negative), 오탐(False Positive), 누락(False Negative), 참양성(True Positive)의 정의는 다음과 같습니다.
-
참음성(True Negative): 파일에 자격 증명이 포함되어 있지 않으며, 도구가 이를 올바르게 자격 증명이 없다고 판단한 경우
-
오탐(False Positive): 파일에 자격 증명이 포함되어 있지 않지만, 도구가 잘못된 판단으로 자격 증명이 있다고 표시한 경우
-
누락(False Negative): 파일에 자격 증명이 포함되어 있지만, 도구가 잘못된 판단으로 자격 증명이 없다고 표시한 경우
-
참양성(True Positive): 파일에 자격 증명이 포함되어 있으며, 도구가 이를 올바르게 자격 증명이 있다고 판단한 경우
결론적으로 Gemini는 더 높은 거짓양성률을 감수하면서도 가장 많은 자격 증명 파일을 탐지합니다. 반면에 TruffleHog은 가장 낮은 거짓양성률을 보이지만 탐지한 참양성의 수가 가장 적습니다. 이는 더 높은 참양성률을 달성하려면 일반적으로 더 높은 오탐률을 감수해야 하기 때문입니다. 현재 데이터 세트에서는 자격 증명을 포함한 파일과 포함하지 않은 파일의 수가 거의 동일합니다. 하지만 실제 상황에서는 이러한 비율이 크게 다를 수 있으므로, 백분율이 비슷하더라도 오탐률이 여전히 중요한 요소가 됩니다.
이 접근 방식을 최적화하려면 세 가지 도구를 모두 활용하고, 각 도구의 결과를 하나로 통합한 후, 결합된 결과를 기준으로 잠재적인 파일을 정렬하는 방식이 효과적일 수 있습니다.
보안 관리자는 앞서 설명한 기법을 사용해 내부 파일 공유를 검토하고, 자격 증명이 포함된 파일에 대한 접근 권한을 제거하거나 제한할 수 있습니다. 각 서버와 워크스테이션에서 네트워크에 노출된 파일 공유를 점검해야 합니다. 이는 경우에 따라 파일 공유가 실수로 노출되거나 잊힐 가능성이 있기 때문입니다.
내부 정찰
네트워크에 침투한 공격자는 다음 단계로 목표에 도달하기 위한 경로를 설계하기 위해 침투한 도메인의 구조와 작동 방식을 파악해야 합니다. 이들의 목표는 위협 행위자의 임무에 따라 전체 도메인의 장악, 특정 시스템의 제어, 혹은 특정 사용자 계정 접근과 같은 다양한 형태로 나타날 수 있습니다. 시나리오에 따라 가상의 공격을 수행하는 레드팀은 이러한 과정을 모방하며, 방어팀은 공격자가 이를 악용하기 전에 가능한 경로를 사전에 파악해야 합니다.
레드팀이 액티브 디렉토리를 분석하는 데 주로 사용하는 도구는 BloodHound입니다. BloodHound는 그래프 데이터베이스를 활용해 액티브 디렉터리 내의 잠재적 경로를 시각적으로 분석합니다. 이 도구는 데이터 수집과 경로 분석 두 단계로 작동합니다: 먼저 데이터 수집기(ingester)를 사용해 목표 액티브 디렉터리에서 데이터를 가져옵니다. 다음으로 수집한 데이터를 BloodHound에 입력하여 공격 가능 경로를 분석합니다.
BloodHound와 함께 사용할 수 있는 주요 데이터 수집 도구는 다음과 같습니다.
-
Sharphound
-
Bloodhound.py
-
Rusthound
-
Adexplorer
-
Bofhound
-
Soaphound
이 도구들은 액티브 디렉토리 및 관련 시스템에서 데이터를 수집하고, BloodHound가 이해할 수 있는 형식으로 변환하여 출력합니다. 이론적으로 네트워크에 대한 모든 정보가 그래프에 포함되어 있다면, 간단한 쿼리로 목표에 도달하는 경로를 파악할 수 있습니다.
BloodHound 데이터를 더욱 유용하게 만들기 위해 추가적인 사용 사례도 고려되었습니다. 사례 3은 공격 가치가 높은 시스템을 식별하는 데 중점을 두고 있으며, 사용 사례 4와 5는 BloodHound 내에서 숨겨진 연결(edge)을 더 많이 발견하고 분석하는 데 초점을 맞추고 있습니다.
사례 3: 액티브 티렉토리에서 중요 타깃 탐지
BloodHound는 기본적으로 일부 그룹과 컴퓨터를 공격 가치가 높은 타깃으로 간주합니다. 내부 정찰 과정에서 가장 중요한 작업 중 하나는 클라이언트 네트워크 내에서 어떤 시스템이 공격 가치가 높은 타깃인지 파악하는 것입니다. 주목할 만한 공격 가치가 높은 시스템으로는 다음이 포함됩니다:
-
백업 시스템
-
SCCM
-
인증서 서비스
-
Exchange
-
WSUS 시스템
이러한 시스템은 IT 관리자가 도메인에서 어떻게 구성했는지에 따라 다양한 방식으로 나타날 수 있습니다. 시스템의 용도를 보여주는 정보는 여러 형태로 존재할 수 있으며, 이는 비구조화된 데이터의 주요 예로 LLM을 사용해 분석할 수 있습니다.
특히 액티브 디렉토리의 다음 필드에는 관련 정보가 포함될 가능성이 있습니다:
-
Name
-
Samaccountname
-
Description
-
Distinguishedname
-
SPNs
이 필드들은 공격 가치가 높은 시스템의 기능과 속성을 식별하는 데 중요한 단서를 제공하며, 정찰 및 분석 과정에서 유용하게 활용될 수 있습니다.
데이터 모델
궁극적으로 LLM이 고가치로 판단한 시스템의 이름 목록을 얻는 것이 목표입니다. 개발 과정에서 결과를 개선하기 위해 이유를 구체적으로 명시하는 것이 LLM의 성능을 크게 향상시킨다는 점을 확인했습니다. 이를 위해 다음과 같은 Pydantic 모델을 활용합니다.
class HighValueSystem(BaseModel):
name: str = Field(description="Name of this system")
reason: str = Field(description="Reason why this system is
high value", default="")
class HighValueResults(BaseModel):
systems: list[HighValueSystem] = Field(description="high value
systems", default=[])프롬프트
아래는 우리가 찾고자 하는 시스템의 예시를 제공하는 프롬프트입니다.
Given the data, identify which systems are high value targets,
look for: sccm servers, jump systems, certificate systems, backup
systems and other valuable systems. Use the first (name) field to
identify the systems.결과
400개의 시스템에 대해 이 프롬프트를 테스트했으며, 각 시스템의 정보를 한 번에 Gemini-1.5 모델에 입력했습니다. Gemini는 다음과 같은 이유로 고가치 시스템을 식별했습니다.
-
도메인 컨트롤러: “OU=Domain Controllers”라는 distinguishedname 필드를 기반으로 판단
-
점프박스: “OU=Jumpboxes,OU=Bastion Servers”라는 distinguishedname 필드를 기반으로 판단
-
Lansweeper: 컴퓨터의 설명 필드를 기반으로 판단
-
백업 서버: “OU=Backup Servers”라는 distinguishedname 필드를 기반으로 판단
도메인 컨트롤러 같은 공격 가치가 높은 타깃은 이미 알려진 시스템으로 유효성이 명확합니다. 반면, 점프박스나 백업 서버와 같은 다른 타깃은 유용한 새로운 발견에 해당합니다. 이 접근법은 시스템 이름이 다른 언어로 작성되었거나 시스템에 대한 설명이 더 상세한 경우에도 공격 가치가 높은 시스템을 식별할 수 있습니다. 또한, 특정 클라이언트 환경에 맞춘 세부적인 쿼리를 허용하여, 예를 들어 SWIFT 서버와 같은 특정 시스템을 탐지하는 데 활용할 수 있습니다.
Given the data, identify which systems are related to
SWIFT. Use the first (name) field to identify the systems.이 경우 LLM은 액티브 디렉토리 정보가 부족하더라도 내부 문서와 결합하여 의미 있는 결과를 도출할 수 있습니다. 방어자의 관점에서 이러한 상황을 방지하기 위한 방법은 다음과 같습니다. 이러한 방어 조치는 네트워크 보안을 강화하고, 잠재적인 정보 유출 가능성을 줄이는 데 도움이 될 것입니다.
-
액티브 디렉토리에 저장된 정보의 양을 제한하고, 시스템 설명은 액티브 디렉토리 외부의 별도 문서에 기록합니다.
-
일반 사용자가 액티브 디렉토리에서 검색할 수 있는 정보의 양을 줄입니다.
-
LDAP 쿼리를 모니터링하여 대량의 데이터가 검색되는지 감시합니다.
사례 4: 사용자 클러스터링
공격자가 네트워크에서 초기 강력한 위치를 확보하고 시스템 구조를 파악한 후 다음 단계로 도메인 내에서 추가 권한을 얻기 위해 적절한 사용자를 찾아야 합니다. 방어자의 입장에서, 레거시 사용자 계정이나 과도한 권한을 가진 관리자는 일반적으로 보안상의 취약점으로 간주됩니다.
관리자는 일반적으로 여러 개의 사용자 계정을 사용합니다. 하나는 이메일 읽기나 워크스테이션 작업과 같은 일상적인 업무를 위한 계정이고, 다른 하나는 관리자 권한을 가진 계정입니다. 이러한 계정 분리는 공격자가 관리자 계정을 해킹하는 것을 어렵게 하기 위해 설계되었습니다.
하지만 구현상의 일부 결함으로 인해 이 계정 분리가 우회될 가능성도 존재합니다. 공격자는 종종 사용자를 클러스터링 하여 동일한 직원에게 속하는 계정을 찾아내는 방법을 사용합니다. 이는 주로 액티브 디렉토리 객체를 분석하여 표시 이름, 설명, 기타 필드에서 특정 패턴을 검색함으로써 이루어집니다. 이러한 과정을 자동화하기 위해 Gemini를 사용하여 패턴을 식별하고자 했습니다.
데이터 모델
이 사례에서는 Gemini가 동일한 사용자에게 속하는 계정을 클러스터링 할 수 있도록 데이터 모델을 설계했습니다. 초기 테스트에서는 결과가 다소 무작위적으로 나타났으나, “이유(reason)” 필드를 추가하자 결과가 크게 개선되었습니다. 최종 Pydantic 모델은 아래와 같습니다.
class User(BaseModel):
accounts: list[Account] = Field(
description="accounts that probably belongs
to this user", default=[]
)
reason: str = Field(
description="Reason why these accounts belong
to this user", default=""
)
class UserAccountResults(BaseModel):
users: list[User] = Field(description="users with multiple
accounts", default=[])프롬프트
다음은 계정을 클러스터링 하기 위해 사용한 프롬프트입니다.
Given the data, cluster the accounts that belong to a single person
by checking for similarities in the name, displayname and sam.
Only include results that are likely to be the same user. Only include
results when there is a user with multiple accounts. It is possible
that a user has more than two accounts. Please specify a reason
why those accounts belong to the same user. Use the first (name)
field to identify the accounts.결과
테스트 데이터 세트에는 약 900명의 사용자가 포함되어 있었습니다. 수동 검토 결과, 일부 사용자는 다양한 권한을 가진 2~4개의 계정을 보유하고 있었습니다. 이 계정들 중 일부는 “user@test.local”과 “adm-user@test.local”과 같이 명확한 패턴을 따르고 있었습니다. 반면, 다른 계정은 관리자 계정이 기본 계정의 앞 두 글자를 기반으로 생성된 패턴을 따랐습니다. 예를 들어 기본 계정이 matthijs.gielen@test.local인 경우 관리자 계정은 adm-magi@test.local과 같은 형식이었습니다. 또한, 관리자 계정의 설명에는 “Matthijs Gielen의 관리자 계정”과 같은 텍스트가 포함되어 있었습니다.
이 프롬프트를 사용해 Gemini는 데이터 세트에서 50개의 계정 그룹을 클러스터링 했습니다. 이후 수작업으로 확인한 결과, 일부 그룹은 하나의 계정만 포함하고 있어 제외되었고, 이를 통해 최종적으로 43개의 올바른 계정 클러스터를 도출할 수 있었습니다. 수동으로도 동일한 상관관계를 찾을 수 있었지만, Gemini는 이를 몇 분 만에 완료한 반면, 수작업 방식으로 분석하고 모든 계정을 상관시키는 데는 훨씬 더 많은 시간이 소요되었습니다. 이 정보는, 이후 사용 사례에서 보여주는 것처럼, 추가 공격 준비에 활용되었습니다.
사례 5: 사용자와 컴퓨터 간 상관관계
어떤 사용자를 공격하거나 보호할 대상을 아는 것만으로는 충분하지 않습니다. 네트워크 내에서 그 사용자를 실제로 찾아야 합니다. 도메인 관리자는 실제 사람이기 때문에, 명령을 입력하거나 관리 작업을 수행할 워크스테이션이 필요합니다. 따라서, 특정 도메인 관리자가 어떤 워크스테이션에서 작업하는지를 파악해야 합니다. 이 정보를 세션 정보라고 하며, BloodHound는 이를 “HasSession”을 통해 시각화하고 활용합니다.
과거에는 일반 사용자 권한만으로도 네트워크 내 모든 세션 정보를 얻을 수 있었습니다.
사용 사례 4의 기술을 활용하면 한 직원이 사용하는 여러 계정을 상관관계 지을 수 있습니다. 다음 단계는 해당 직원이 어떤 워크스테이션을 사용하는지를 파악하는 것입니다. 이 정보를 바탕으로 해당 워크스테이션을 목표로 설정하고, 관리자 계정의 암호를 복구하는 공격을 수행할 수 있습니다.
직원들은 일반적으로 회사에서 지급한 노트북을 사용하며, 회사는 어떤 노트북이 어떤 직원에게 할당되었는지 추적합니다. 이 정보는 종종 액티브 디렉토리의 컴퓨터 객체 필드 중 하나에 저장되지만, 구현 방식은 다양합니다. 이러한 데이터를 분석하는 방법 중 하나는 LLM을 활용하여 비정형 데이터를 파싱 하는 것입니다.
데이터 모델
이 모델은 매우 간단합니다. 우리는 단순히 기계와 사용자를 연결하고 Gemini가 그 이유를 설명하도록 합니다. 모든 사용자와 모든 컴퓨터를 한 번에 보낼 것이므로 결과 목록이 필요합니다.
class UserComputerCorrelation(BaseModel):
user: str = Field(description="name of the user")
computer: str = Field(description="name of the computer")
reason: str = Field(
description="Reason why these accounts belong to this user",
default=""
)
class CorrelationResults(BaseModel):
results: list[UserComputerCorrelation] = Field(
description="users and computers that correlate", default=[]
)프롬프트
다음은 사용자를 컴퓨터와 연결하기 위해 사용된 프롬프트입니다.
Given the two data sets, find the computer that correlates
to a user by checking for similarities in the name, displayname
and sam. Only include results that are likely to correspond.
Please specify a reason why that user and computer correlates.
Use the first (name) field to identify the users and computers.결과
데이터 세트에는 약 900명의 사용자와 400대의 컴퓨터가 포함되어 있습니다. 관리자는 컴퓨터 할당 과정에서 컴퓨터의 설명 필드에 사용자의 이름과 비슷한 정보를 기록하여 사용자와 컴퓨터를 연결했습니다. Gemini는 이러한 연결을 정확히 분석해 약 120명의 사용자와 그들이 사용하는 노트북을 올바르게 매칭했습니다.

그림 3: Gemini가 상관관계를 분석한 사용자와 노트북 간의 연결
Gemini는 적절한 워크스테이션을 식별하는 데 도움을 주었으며, 이를 활용해 워크스테이션으로 접근한 후 관리자 계정의 암호를 획득하는 등 추가 공격을 수행할 수 있었습니다.
이러한 위협에 대응하기 위해 네트워크에서 BloodHound와 같은 도구를 활용하는 것이 중요합니다. BloodHound는 네트워크 내의 모든 “숨겨진” 연결을 자동으로 탐지할 수는 없지만, 관리자가 직접 이러한 연결을 그래프에 추가할 수 있습니다. 이를 통해 네트워크 내의 액티브 디렉토리 기반 공격 경로를 식별하고, 공격자가 이를 악용하기 전에 적절한 완화 조치를 취할 수 있습니다.
결론
이 블로그 포스트에서는 적대적 에뮬레이션과 방어 강화를 위해 LLM을 활용해 레드팀 데이터를 처리하는 방법을 살펴보았습니다. 이러한 사용 사례는 조직원들이 생성한 비정형 데이터를 처리하고 구조화하는 데 초점을 맞추고 있습니다.
테이블 3: Gemini로 실행한 데이터 프로세싱 실험 결과
표 3은 실험 결과를 요약한 것으로 Gemini와 같은 LLM을 활용하면 비정형 데이터를 구조화된 형태로 변환하여 공격자와 방어자 모두에게 유용할 수 있음을 보여줍니다. 그러나 LLM은 만능 해결책이 아니며, 몇 가지 한계를 가지고 있다는 점도 기억해야 합니다. 예를 들어 때때로 오탐을 생성하거나 대규모 데이터를 처리하는 데 시간이 오래 걸릴 수 있습니다.
이 블로그에서 다루지 않은 다른 사용 사례도 다양하게 존재합니다. 예를 들어 다음과 같은 작업에 이 접근 방식을 적용할 수 있습니다.
-
워크스테이션 및 서버에 대한 관리자 권한과 사용자 그룹 간의 관계 분석
-
내부 웹사이트 컨텐츠 문서를 요약해 타깃 시스템 검색
-
문서 분석을 통해 암호 해독을 위한 잠재적 암호 후보 생성
미래 전망
맨디언트 레드팀의 Advanced Capabilities 팀은 LLM을 활용한 적대적 에뮬레이션과 방어 강화의 초기 단계를 탐구하고 있습니다. 앞으로는 프롬프트를 변형해 새로운 접근법을 테스트하고, 다양한 데이터 소스를 분석해 Gemini의 능력을 더욱 향상시킬 계획입니다. 또한, 선형 회귀 모델, 클러스터링, 경로 탐색 알고리즘을 활용해 사이버 보안 전문가가 네트워크 내의 잠재적 공격 경로를 신속하게 평가하고 대응할 수 있는 도구를 개발하는 방향으로 나아갈 것입니다.
