프롬프트 인젝션과 제일브레이크 공격, 왜 Model Armor가 필요한가?

Pallavi Vageria
Senior Strategic Cloud Engineer, Google Cloud
해당 블로그의 원문은 2025년 10월 23일 Google Cloud 블로그(영문)에 게재되었습니다.
AI가 계속해서 빠르게 발전함에 따라, IT 팀이 프롬프트 인젝션(prompt injection)과 탈옥(jailbreaking)이라는 두 가지 일반적인 위협으로 인해 발생하는 비즈니스 및 조직적 위험을 해결하는 것이 중요합니다.
올해 초 저희는 생성형 AI 프롬프트와 응답, 그리고 에이전트 상호작용을 보호하는 데 도움이 될 수 있는 모델에 구애받지 않는(model-agnostic) 고급 스크리닝 솔루션인 Model Armor를 소개했습니다. Model Armor는 개발자를 위한 직접적인 API 통합, 그리고 Apigee, Vertex AI, Agentspace 및 네트워크 서비스 확장과의 인라인 통합을 포함한 포괄적인 통합 옵션 제품군을 제공합니다.
많은 조직이 이미 Apigee를 API 게이트웨이로 사용하고 있으며, 트래픽 및 보안 관리를 위해 Spike Arrest, Quota, OAuth 2.0과 같은 기능을 활용하고 있습니다. Model Armor와 통합함으로써 Apigee는 생성형 AI 상호작용을 위한 중요한 보안 레이어가 될 수 있습니다.
이 강력한 조합은 프롬프트와 응답을 선제적으로 스크리닝할 수 있게 하여, AI 애플리케이션이 안전하고 규정을 준수하며 정의된 가드레일 내에서 작동하도록 보장합니다. 오늘 저희는 여러분의 AI 앱을 보호하기 위해 Apigee와 함께 Model Armor를 사용하는 시작 방법을 설명합니다.
AI 앱 보호를 위한 Model Armor 사용 방법
Model Armor는 5가지 주요 기능을 가지고 있습니다.
-
프롬프트 인젝션 및 탈옥 감지: LLM을 조작하여 지침과 안전 필터를 무시하도록 하는 시도를 식별하고 차단합니다.
-
민감한 데이터 보호: 사용자 프롬프트와 LLM 응답 모두에서 개인 식별 정보(PII) 및 기밀 데이터를 포함한 민감한 정보의 노출을 감지, 분류 및 방지할 수 있습니다.
-
악성 URL 감지: 입력과 출력 모두에서 악성 및 피싱 링크를 스캔하여 사용자가 유해한 웹사이트로 연결되는 것을 방지하고, LLM이 의도치 않게 위험한 링크를 생성하는 것을 막습니다.
-
유해 콘텐츠 필터링: 성적으로 노골적이거나, 위험하거나, 괴롭힘 또는 증오 발언을 포함하는 콘텐츠를 감지하는 내장 필터가 있어, 출력이 책임감 있는 AI 원칙에 부합하도록 보장합니다.
-
문서 스크리닝: PDF 및 Microsoft Office 파일을 포함한 문서 내 텍스트에서 악성 및 민감한 콘텐츠를 스크리닝할 수도 있습니다.

Model Armor와 Apigee 및 LLM의 연동
Model Armor는 모델 독립적(model-independent)이고 클라우드에 구애받지 않도록(cloud-agnostic) 설계되었습니다. 즉, Google Cloud, 다른 클라우드 제공업체 또는 다른 플랫폼 중 어디에서 실행되든 상관없이 REST API를 통해 모든 생성형 AI 모델을 보호하는 데 도움을 줄 수 있습니다. 이러한 기능을 수행하기 위해 REST 엔드포인트 또는 다른 Google AI 및 네트워킹 서비스와의 인라인 통합을 노출합니다.
시작하는 방법
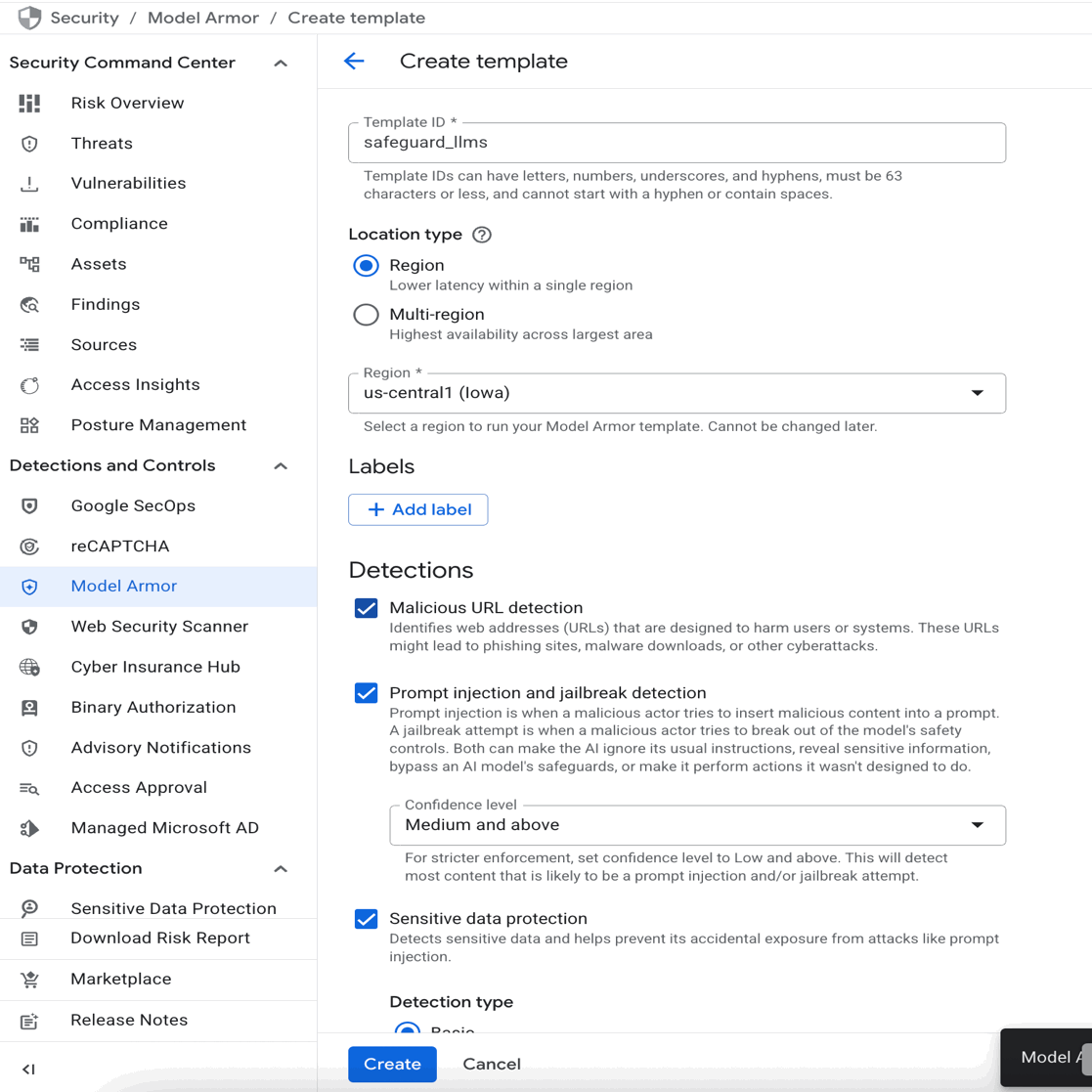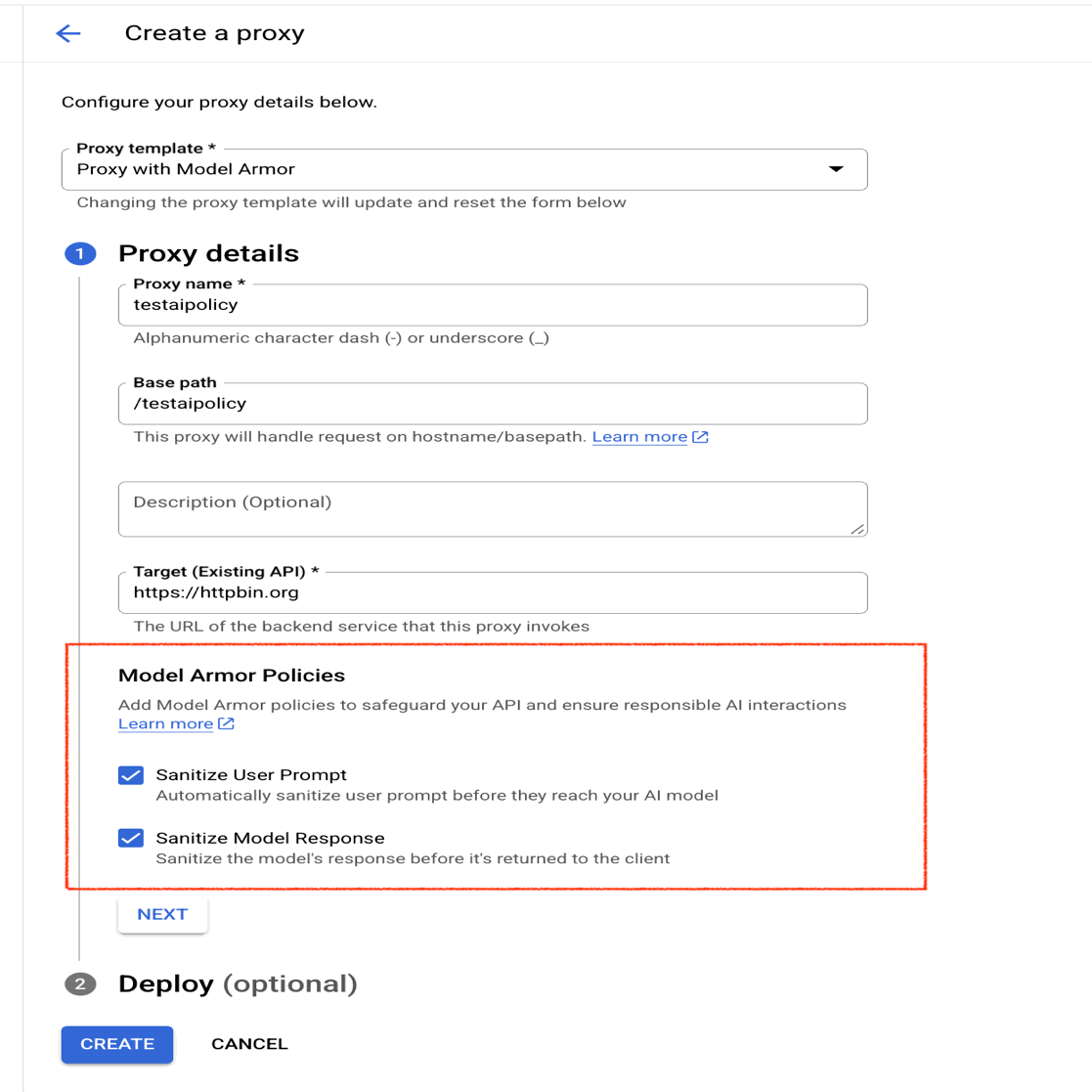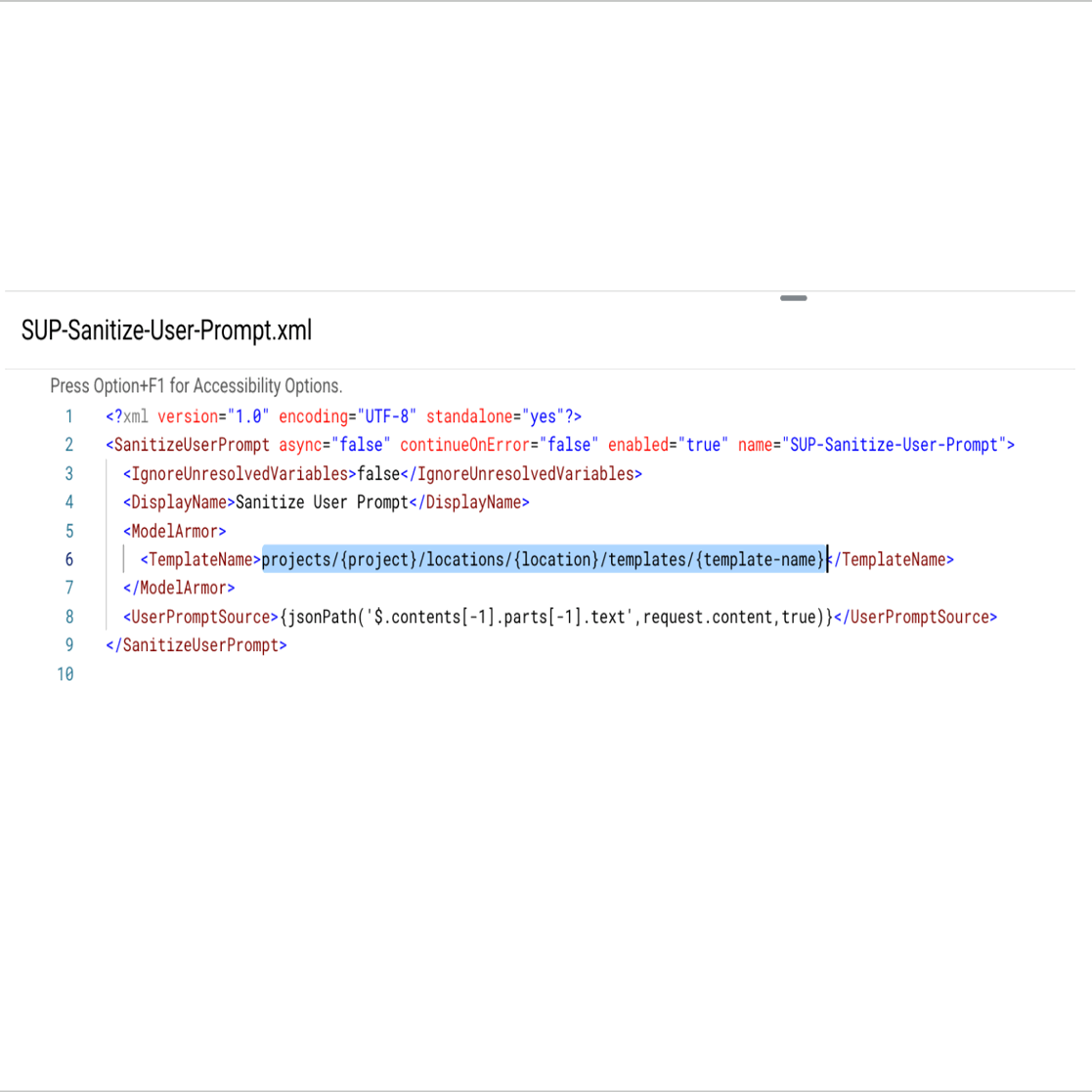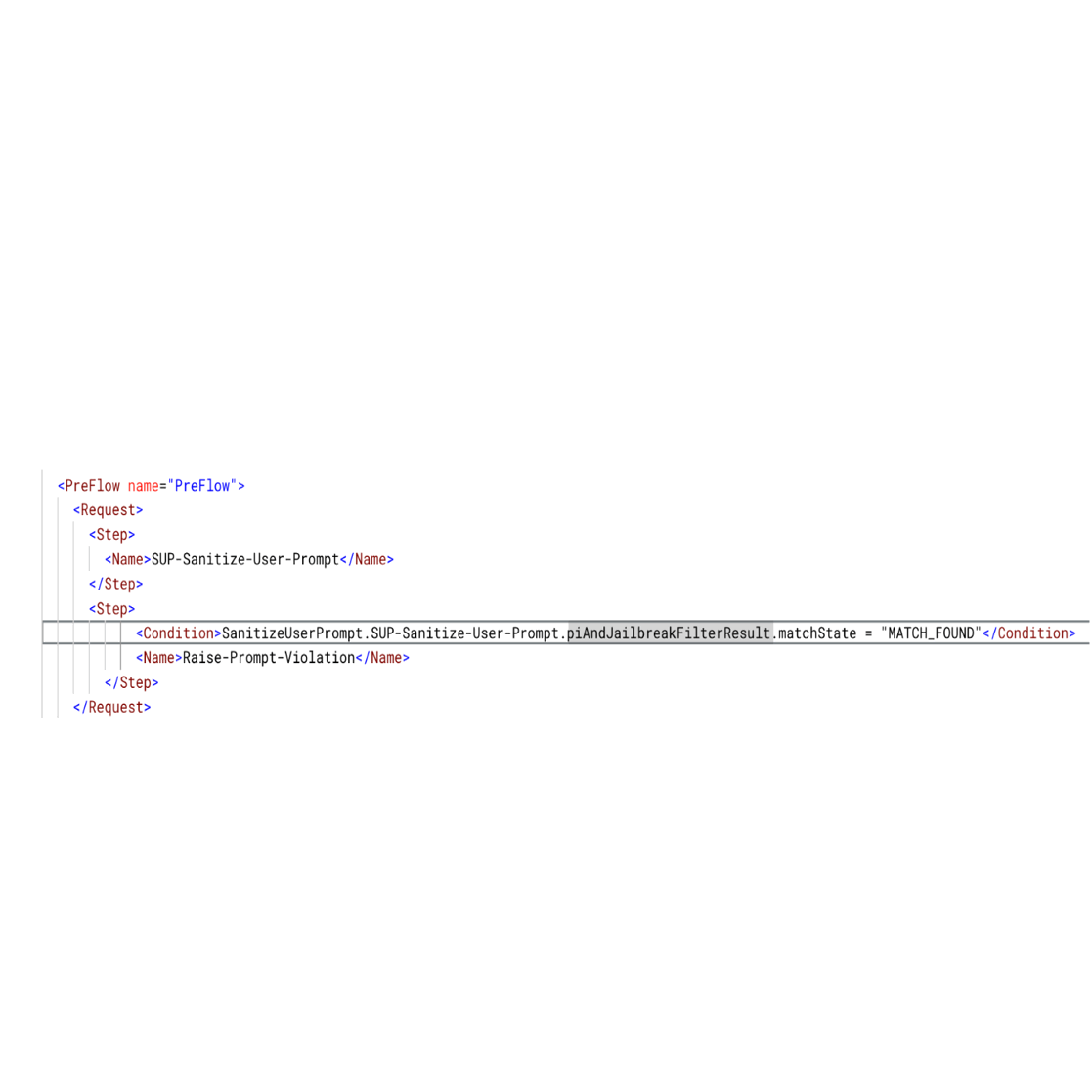
- Google Cloud 콘솔에서 Model Armor API를 활성화하고 "템플릿 만들기"를 클릭합니다.
- 프롬프트 인젝션 및 탈옥 탐지를 활성화합니다. 위에 표시된 대로 다른 안전 필터도 활성화하고 "만들기"를 클릭할 수 있습니다.
- 서비스 계정을 생성하거나 (Apigee 프록시를 배포하는 데 사용된 기존 서비스 계정을 업데이트하고,) 서비스 계정에서 Model Armor User(roles/modelarmor.user) 및 Model Armor Viewer(roles/modelarmor.viewer) 권한을 활성화합니다.
- Apigee 콘솔에서 새 프록시를 만들고 Model Armor 정책을 활성화합니다.
- LLM 호출을 위한 프록시가 이미 있는 경우, 플로우에 SanitizeUserPromptt와 SanitizeModelResponse라는 두 개의 Apigee 정책을 추가합니다.
- 정책 세부정보에서 이전에 생성한 Model Armor 템플릿에 대한 참조를 업데이트합니다. 예: projects/some-test-project/locations/us-central-1/templates/safeguard_llms. 유사하게, <SanitizeModelResponse> 정책도 구성합니다.
- 요청 페이로드에 사용자 프롬프트의 소스를 제공합니다 (예: JSON 경로).
- LLM 엔드포인트를 Apigee 프록시의 대상 백엔드로 구성하고 위에서 구성한 서비스 계정을 사용하여 프록시를 배포합니다. 이제 프록시가 작동하며 Model Armor 및 LLM 엔드포인트와 상호작용해야 합니다.
- 프록시 실행 중 Apigee가 Model Armor를 호출하면 "필터 실행 상태(filter execution state)"와 "일치 상태(match state)"를 포함하는 응답을 반환합니다. Apigee는
SanitizeUserPrompt.POLICY_NAME.piAndJailbreakFilterResult.executionState및SanitizeUserPrompt.POLICY_NAME.piAndJailbreakFilterResult.matchState같은 Model Armor 응답의 정보로 여러 플로우 변수를 채웁니다. - <Condition>을 사용하여 이 플로우 변수가 MATCH_FOUND와 같은지 확인하고 프록시 플로우 내에 <RaiseFault> 정책을 구성할 수 있습니다.
AI 애플리케이션을 보호하기 위해 Model Armor를 구성하고 Apigee와 통합하는 단계
결과 검토
Security Command Center의 AI Protection 대시보드에서 Model Armor 결과를 볼 수 있습니다. 그래프는 Model Armor가 분석한 프롬프트 및 응답의 양과 식별된 문제 수를 함께 보여줍니다.
또한 프롬프트 주입, 탈옥 감지, 민감한 데이터 식별을 포함한 다양한 감지된 문제 유형을 요약합니다.

AI Protection 대시보드에서 제공하는 프롬프트 및 응답 콘텐츠 분석.

Model Armor floor 설정은 필터링을 위한 신뢰도 수준을 정의
Model Armor 로깅은 템플릿 생성 또는 업데이트와 같은 관리 활동 및 프롬프트와 응답에 대한 삭제 작업을 캡처하며, 이는 Cloud Logging에서 볼 수 있습니다. Model Armor 템플릿 내에서 로깅을 구성하여 프롬프트, 응답, 평가 결과와 같은 세부 정보를 포함할 수 있습니다.
직접 사용해서 자세히 알아보기
여기에서 Apigee와 Model Armor를 통합하는 튜토리얼을 살펴보고, Model Armor 구성에 대한 가이드 랩을 사용해 보세요.

