예시로 알아보는 Google Kubernetes Engine 서비스 문제 해결
Yuri Grinshteyn
Site Reliability Engineer, CRE
* 본 아티클의 원문은 2021년 2월 27일 Google Cloud 블로그(영문)에 게재되었습니다.
애플리케이션이 실패하고 컨테이너가 비정상 종료되는 일은 흔하게 발생합니다. 이는 SRE 및 DevOps팀도 익히 알고 있는 사실입니다. 앞서 일시적인 장애를 잘 해결할 수 있도록 Google Kubernetes Engine(GKE)에서 실행되는 애플리케이션을 디버깅하는 방법을 알려드린 바 있습니다. 또한 더 쉽게 사용할 수 있는 새로운 문제 해결 흐름으로 GKE 대시보드도 업데이트했습니다. 오늘은 한 단계 더 나아가 이러한 흐름을 사용해 애플리케이션 및 인프라의 문제점을 빠르게 찾아 해결하는 방법을 알려드립니다.
이 블로그에서는 클러스터에 샘플 앱을 배포하고 컨테이너 재시작이 관측되면 알려주는 알림 정책을 구성하는 과정을 살펴보겠습니다. 그런 다음 알림을 트리거하여 새로운 GKE 대시보드에서 얼마나 쉽게 문제를 식별하고 문제의 원인일 수 있는 워크로드 또는 인프라의 상황을 정확히 파악하는지 알아봅니다.
설정
앱 배포
이 예시에서는 'hello world'에 해당하는 /의 엔드포인트와 Go의 os.Exit(1)를 사용해 프로세스를 종료하는 /crashme 엔드포인트를 노출하는 데모 앱을 사용합니다. 앱을 자체 클러스터에 배포하려면 Cloud Build를 사용해 컨테이너 이미지를 만들어 GKE에 배포하세요. 그런 다음 부하 분산기를 사용해 서비스를 노출하시기 바랍니다.
서비스가 배포되면 실행 중인 pod를 확인합니다.
각 pod에서 RESTARTS가 처음에는 0인 것에 주목하세요. 브라우저나 curl과 같은 명령줄 도구를 사용해 /crashme 엔드포인트에 액세스합니다. 이번에는 재시작이 표시됩니다.
이 엔드포인트에 대한 각 요청에서 재시작이 발생합니다. 하지만 이 작업을 30초 미만 간격으로 반복하면 컨테이너가 CrashLoopBackOff 상태가 되며 서비스를 다시 사용할 수 있기까지 시간이 걸리므로 주의해야 합니다. 이 단순한 셸 스크립트를 사용하면 필요할 때 재시작을 트리거할 수 있습니다.
여기에서 $IP_ADDRESS는 앞서 만든 부하 분산기의 IP 주소입니다.
컨테이너 재시작이 중요한 이유는 무엇일까요? 재시작은 Kubernetes의 일반적인 컨테이너 수명 주기에서 어느 정도 예상되는 문제입니다. 하지만 컨테이너 재시작이 지나치게 여러 번 발생하고 특히 특정 pod에서 많은 수의 복제본으로 확장되면 서비스 가용성에 영향을 미칠 수 있습니다. 과도한 재시작은 문제의 서비스 성능을 저하시킬 뿐만 아니라 해당 서비스를 종속 항목으로 사용하는 다른 서비스에도 영향을 미칠 위험이 있습니다.
실제로는 잘못 설계된 활성 프로브, 애플리케이션 자체의 교착 상태와 같은 문제 또는 OOMkilled 오류를 발생시키는 잘못 구성된 메모리 요청이 과도한 재시작의 원인일 수 있습니다. 따라서 컨테이너 재시작에 대한 사전 알림을 통해 다수의 서비스로 확산될 수 있는 잠재적 성능 저하를 방지해야 합니다.
경고 구성
이제 재시작이 감지되면 알려주는 알림을 구성할 차례입니다. 알림 정책을 설정하는 방법은 다음과 같습니다.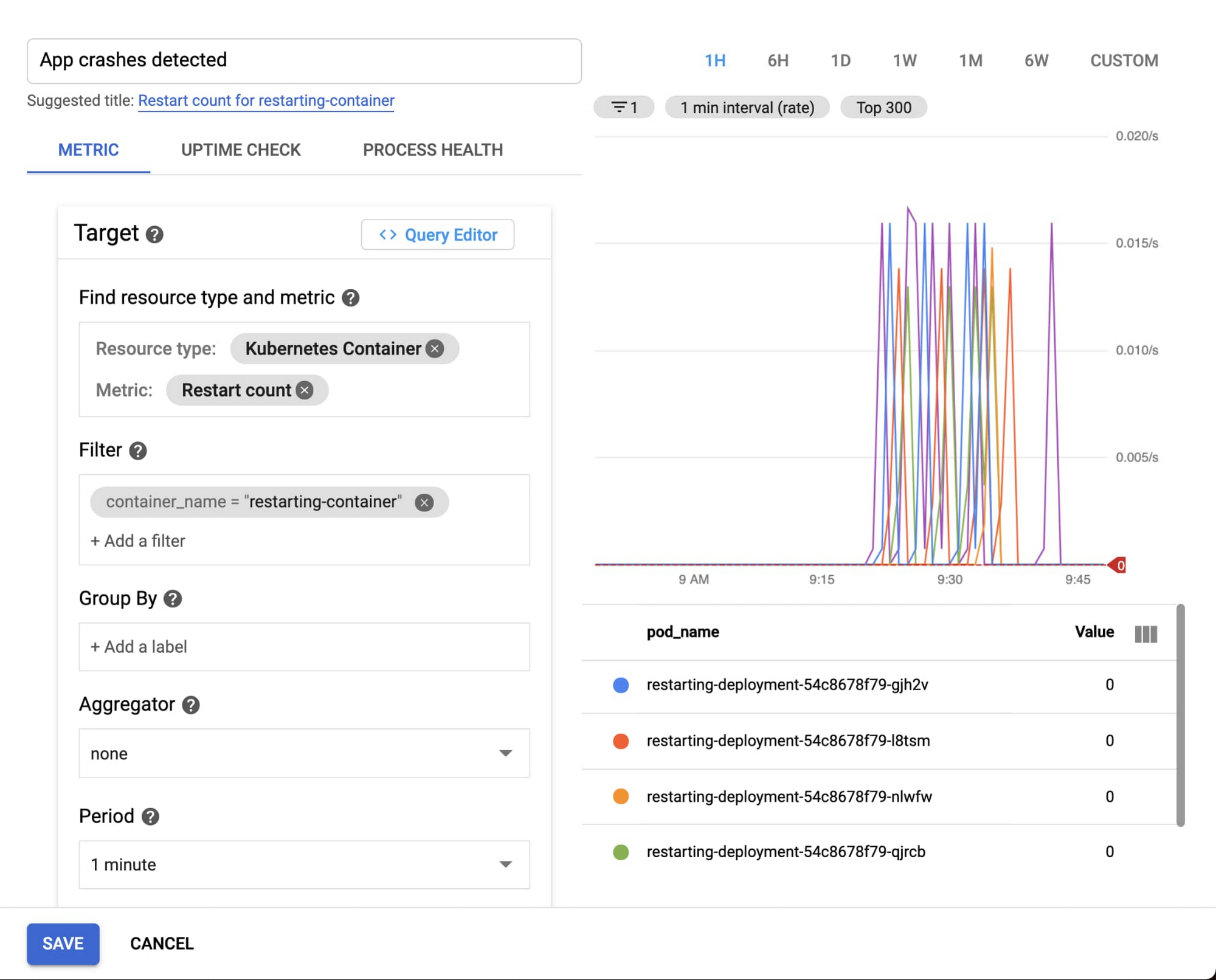
배포 YAML 파일에 지정되어 있는 특정 컨테이너 이름으로 필터링하여 kubernetes.io/container/restart_count 측정항목을 사용하면 됩니다. 시계열이 0을 초과하는 경우, 즉 컨테이너 재시작이 관측되면 알림이 트리거되도록 구성합니다.
설정을 완료하면 알림을 테스트하여 상황을 파악할 수 있습니다.
알림 테스트
준비가 되면 45초마다 /crashme 엔드포인트에 도달하는 반복 스크립트를 시작합니다. restart_count 측정항목은 60초 간격으로 샘플링되어 있으므로 알림이 대시보드에 표시되는 데 오랜 시간이 걸리지 않습니다.
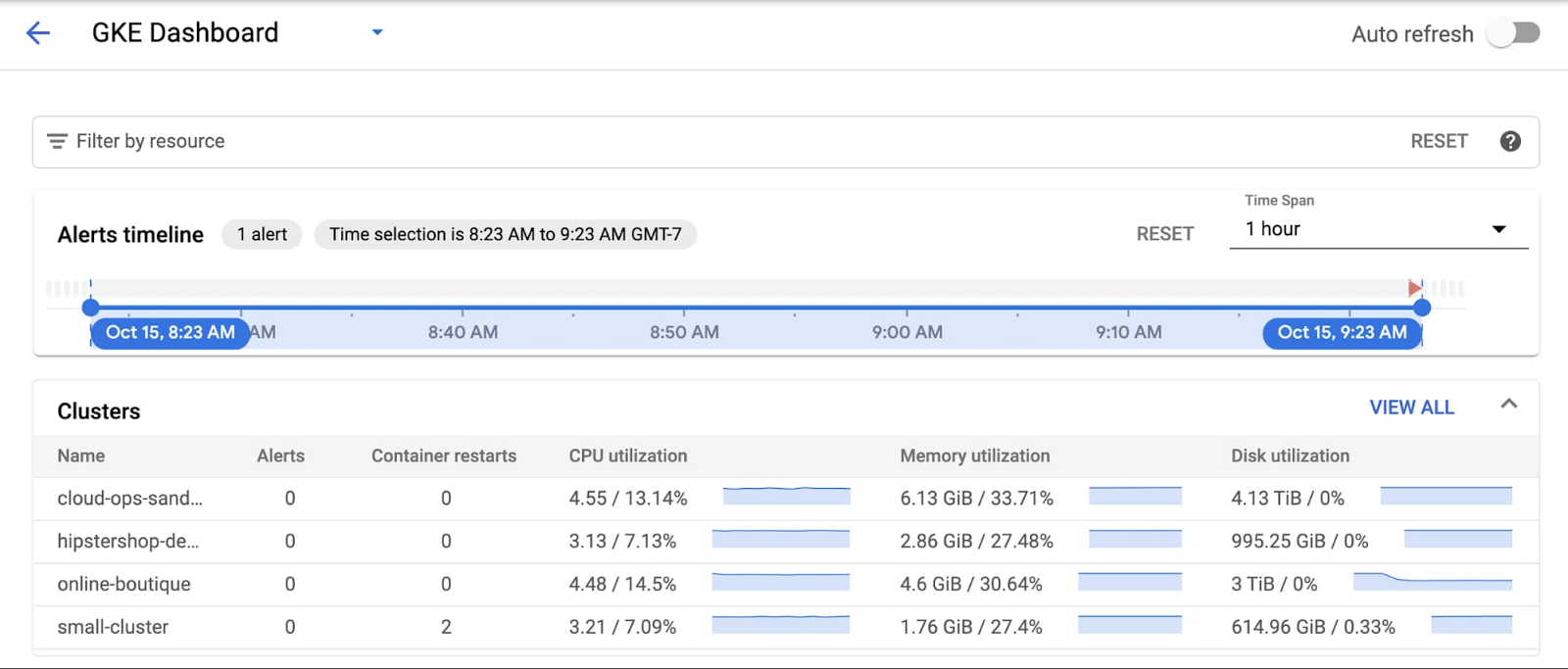
이슈 위로 마우스를 가져가면 자세한 정보를 확인할 수 있습니다.
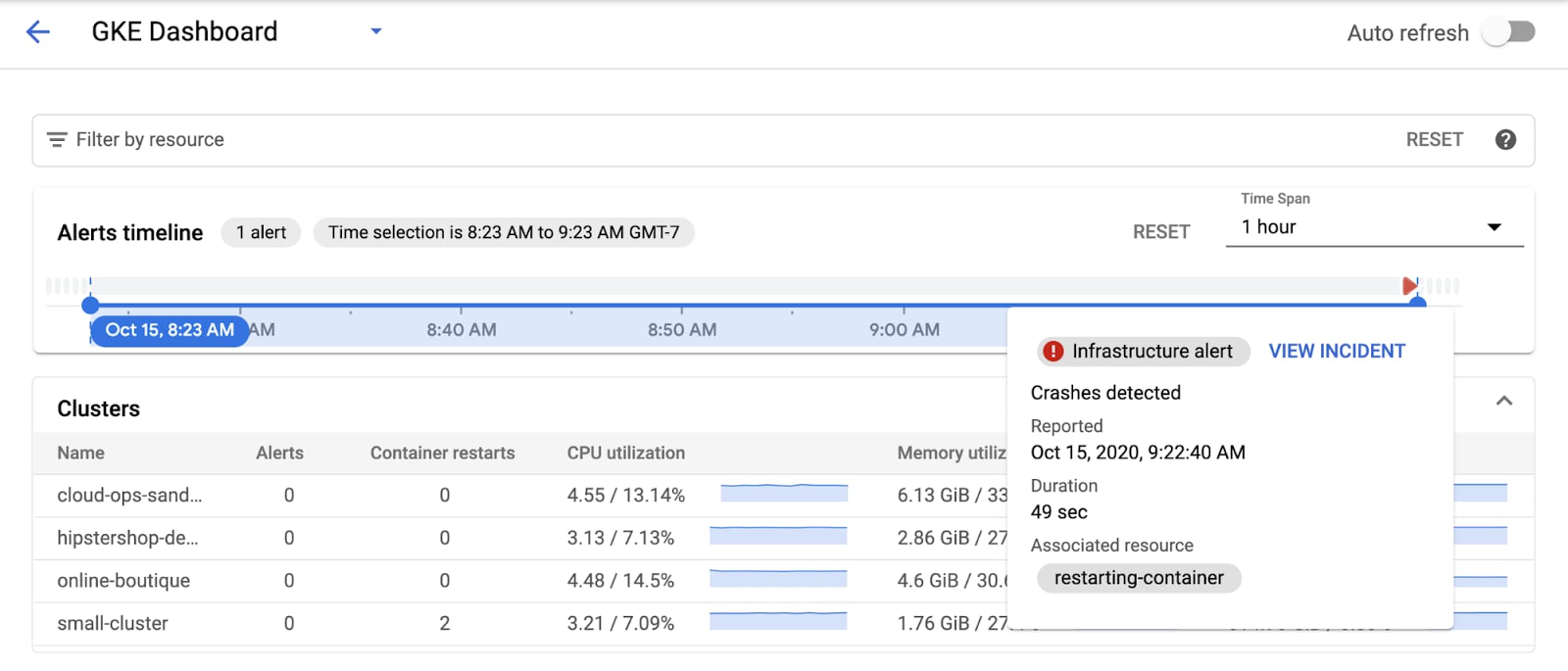
그런 다음 '이슈 보기'를 클릭합니다. 그러면 이슈 세부정보 화면으로 이동하여 이슈를 트리거한 특정 리소스를 확인할 수 있습니다. 이 경우에는 컨테이너에서 이슈가 생성되었습니다.
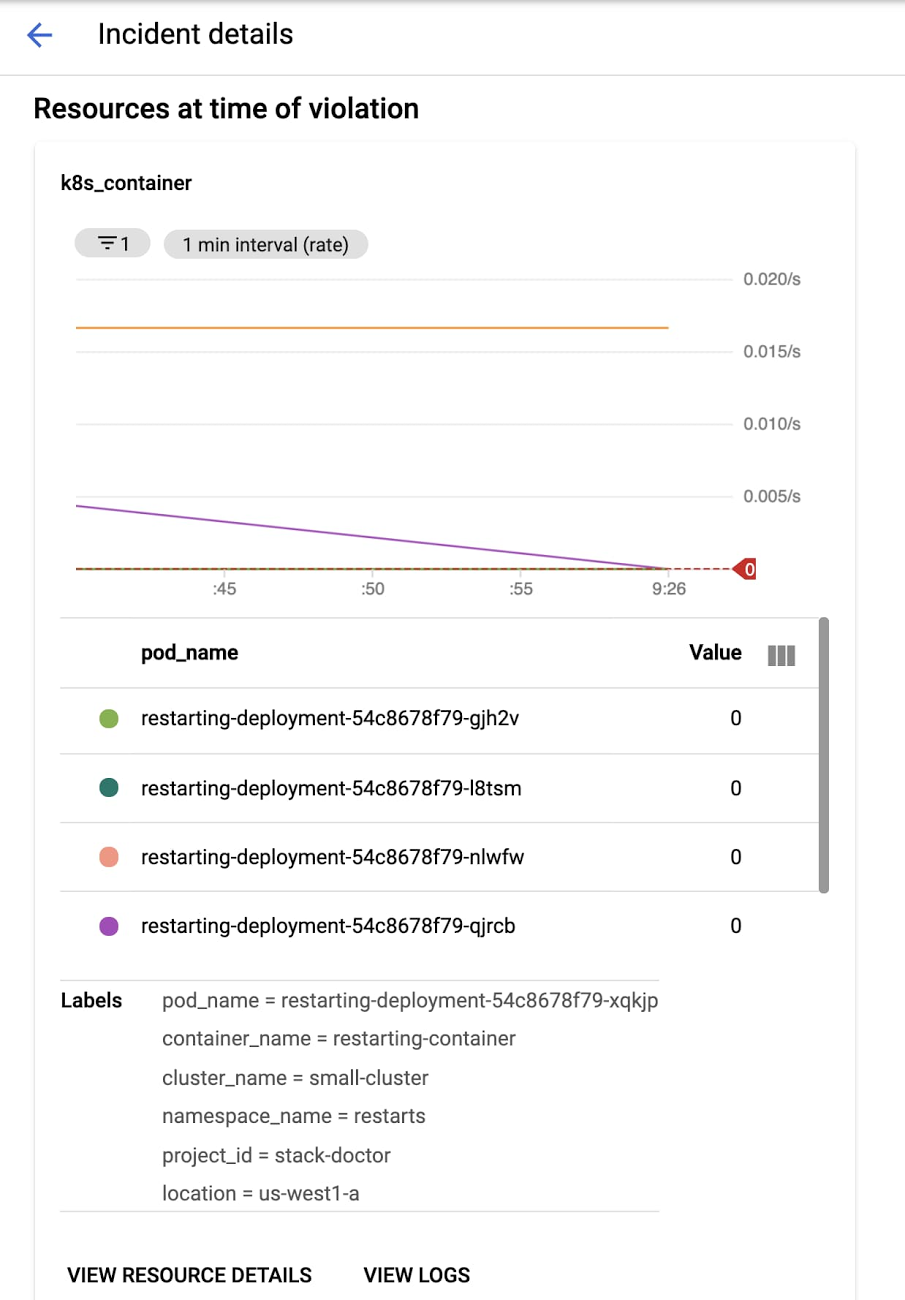
다음으로 '로그 보기'를 클릭하여 새 로그 뷰어에서 로그를 확인합니다. 재시작된 컨테이너에서 알림이 트리거된 것을 바로 확인할 수 있습니다.
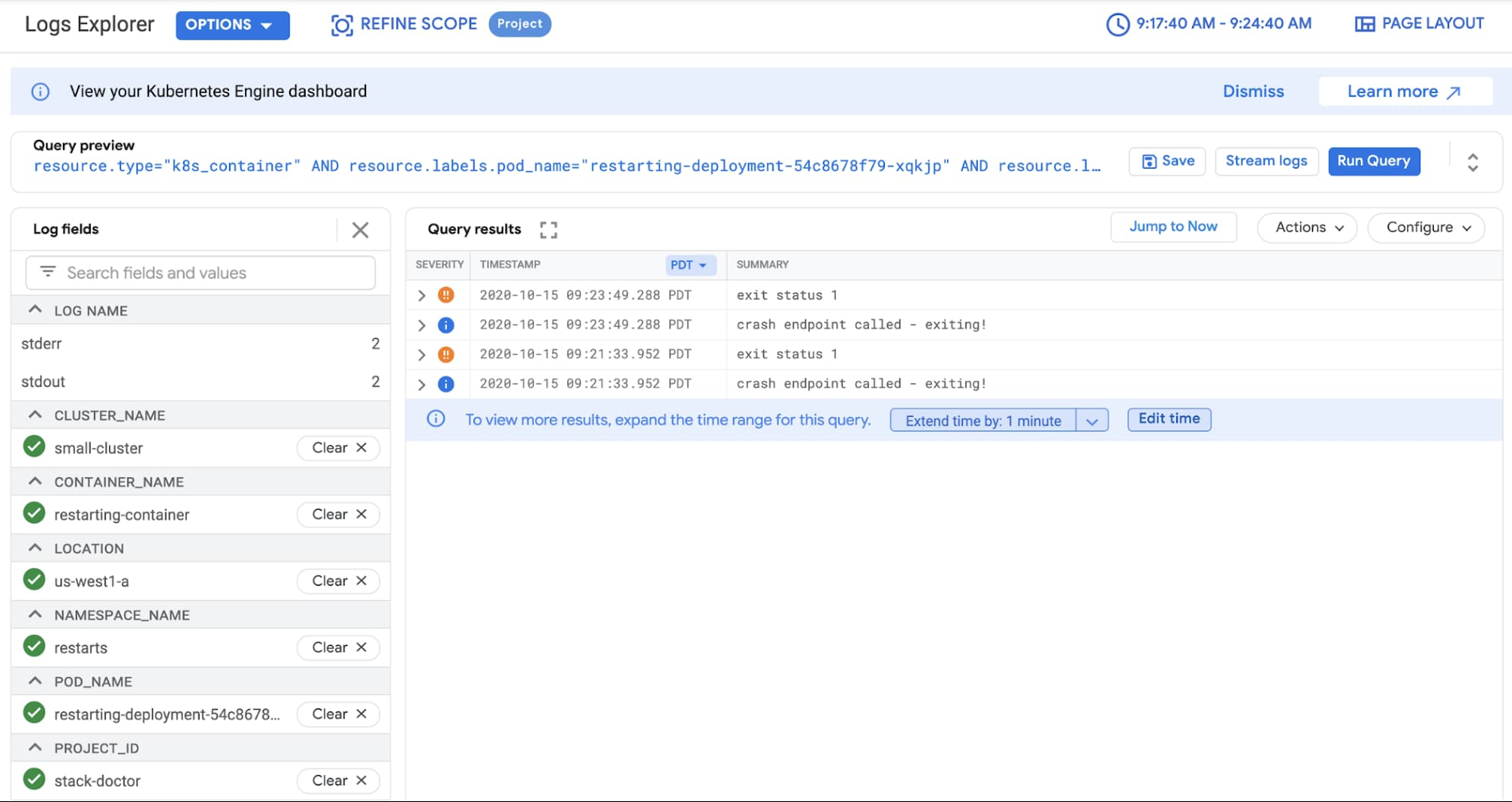
이 모든 기능이 효과적으로 연결되어 이슈가 발생했을 때 문제를 훨씬 쉽게 해결할 수 있습니다.
요약
최신 GKE 대시보드는 이전 버전보다 많은 부분이 개선되었습니다. 새로운 알림 타임라인은 직관적이며 이슈가 분명하게 표시되어 상호작용을 통해 정확한 상황에 대한 자세한 정보를 얻을 수 있고, 실질적인 문제를 알려주는 컨테이너 로그도 확인할 수 있습니다.
GKE 대시보드가 GKE에서 실행되는 서비스의 긴급 대기 SRE 또는 DevOps 엔지니어의 역할을 해주기 때문에 이슈에 쉽게 대처할 수 있습니다. 이제 이슈 확인부터 로그 디버깅까지 쉽고 빠르게 처리하여 이슈를 선별하고 완화하는 시간을 단축할 수 있습니다. GKE에서 서비스 문제를 해결하는 방법에 대한 간략한 개요를 이 동영상에서 확인하세요.

이 블로그 게시물에 도움을 주신 고객 엔지니어 전문가, 앤서니 부숑에게 감사의 말을 전합니다.