새로운 자동 확장 처리를 통한 Spanner 인스턴스의 자동 크기 조정
Ben Good
Solutions Architect
David Cueva Tello
Cloud Solutions Architect
* 본 아티클의 원문은 2020년 12월 15일 Google Cloud 블로그(영문)에 게재되었습니다.
Cloud Spanner를 사용하면 가용성과 확장성이 우수한 관계형 데이터베이스를 손쉽게 얻을 수 있습니다. 따라서 Google Cloud 고객은 니즈에 따라 데이터베이스 백엔드를 확장할 수 있을지 걱정할 필요 없이 애플리케이션 혁신성을 추구할 수 있게 되었습니다. 또한 Spanner를 통해 사용량을 기준으로 비용을 최적화할 수 있습니다. Spanner를 사용해 더욱더 쉽게 빌드할 수 있도록 지원하는 자동 확장 처리 도구가 출시되었습니다. 자동 확장 처리는 주요 사용률 측정항목을 관측하고 이 측정항목을 기준으로 필요에 따라 노드를 추가하거나 삭제하는 Spanner용 오픈소스 도구입니다.
바로 시작하려면 이 GitHub 저장소를 클론하고 제공된 Terraform 구성 파일을 사용해 자동 확장 처리를 설정하세요.
자동 확장 처리로 어떤 작업이 가능한가요?
자동 확장 처리는 사용자 수요에 따라 노드 수를 조정하는 방식으로 운영 관련 요구사항을 쉽게 충족하고 클라우드 지출의 효율성을 극대화하도록 설계되었습니다.
자동 확장 처리는 선형, 단계식, 직접식의 3가지 확장 방법을 지원합니다. 이러한 확장 방법을 사용하면 워크로드에 맞게 자동 확장 처리를 구성할 수 있으며 세 가지 방법을 자유롭게 조합하여 하루 동안의 로드 패턴에 맞게 조정하고, 일괄 프로세스가 있는 경우에는 일정에 따라 수직 확장하고, 작업을 완료한 후 다시 축소할 수 있습니다.
대부분의 로드 패턴은 기본 확장 방법을 사용하여 관리할 수 있지만 추가적인 맞춤설정이 필요한 경우 자동 확장 처리에 새 측정항목과 확장 방법을 손쉽게 추가하여 특정 워크로드를 지원하도록 확장할 수 있습니다.
애플리케이션을 지원하는 Spanner 인스턴스가 여러 개인 경우가 많으므로 자동 확장 처리는 단일 배포에서 여러 Spanner 인스턴스를 관리할 수 있습니다. 자동 확장 처리는 간단한 JSON 객체를 통해 구성되기 때문에 Spanner 인스턴스마다 자체 구성을 포함하고 공유된 자동 확장 처리를 사용할 수 있습니다.
마지막으로 개발 및 운영팀의 작업 모델과 관계가 각기 다르므로 자동 확장 처리에서는 다양한 배포 모델을 지원합니다. 이러한 모델을 사용하면 자동 확장 처리를 Spanner 인스턴스와 함께 배포할지 아니면 중앙의 자동 확장 처리 하나로 다양한 프로젝트의 Spanner를 관리할지 선택할 수 있습니다. 다양한 배포 모델 덕분에 개발자 지원 강화와 자동 확장 처리 지원 최소화 간의 적절한 균형을 찾을 수 있습니다.
자동 확장 처리를 내 환경에 배포하려면 어떻게 해야 하나요?
가장 간단한 설계를 원한다면 프로젝트별 토폴로지로 자동 확장 처리를 배포하면 됩니다. 이 경우 하나 이상의 Spanner 인스턴스를 소유한 각 팀에서 자동 확장 처리 인프라 및 구성을 책임지게 됩니다. 이 토폴로지의 구조는 다음과 같습니다.
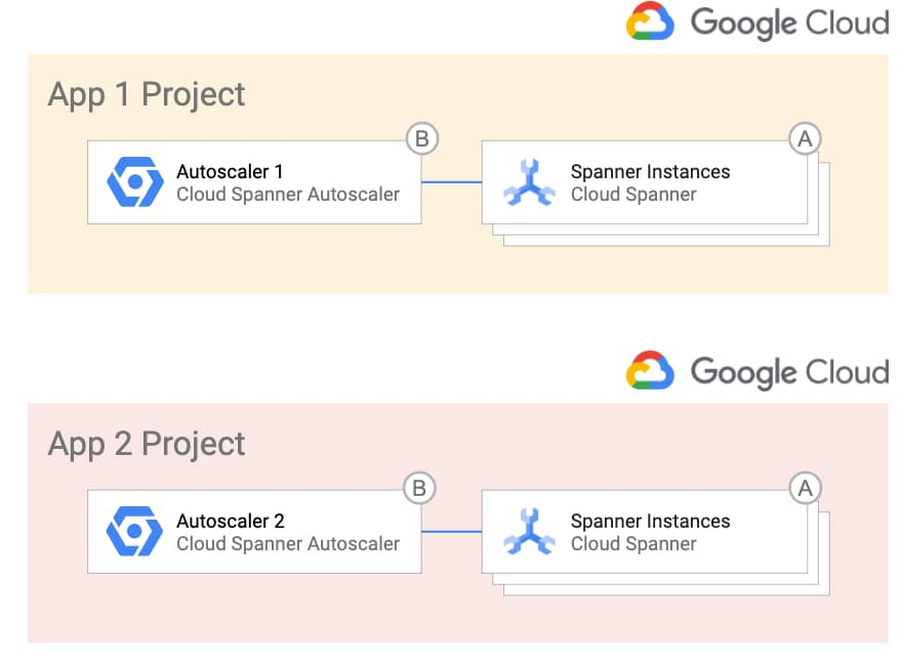
또는 자동 확장 처리 인프라 및 구성을 더 세부적으로 제어하려면 중앙화하도록 선택하여 단일 운영팀에 책임을 부여하면 됩니다. 이 토폴로지는 규제가 심한 산업에 적합할 수 있습니다. 이 토폴로지의 구조는 다음과 같습니다.
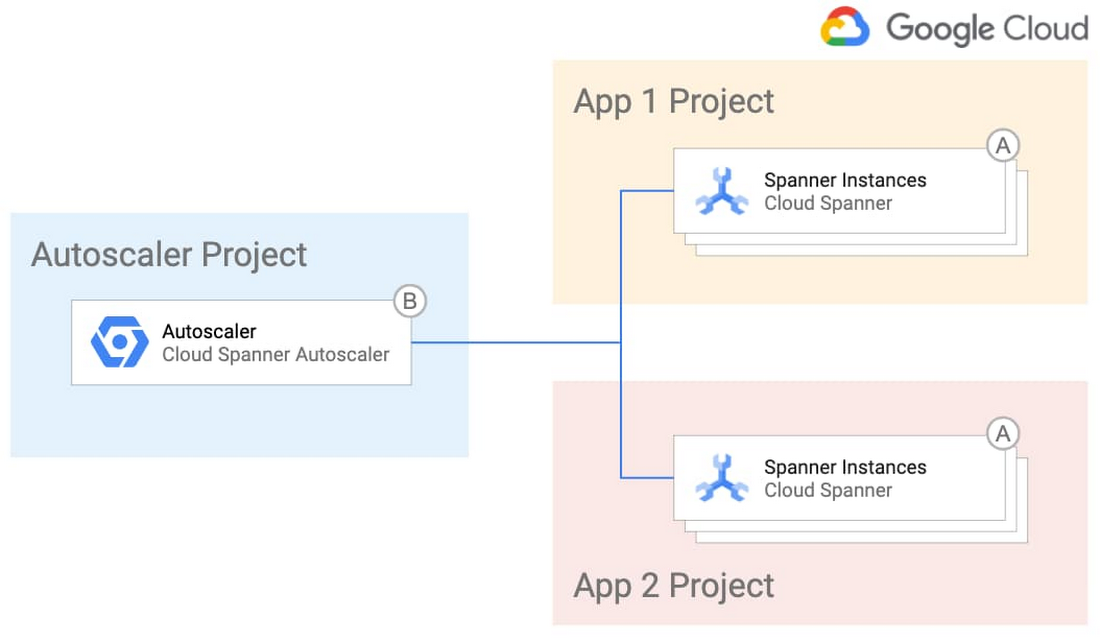
간단한 설계와 세부적인 제어를 모두 원한다면 자동 확장 처리 인프라를 중앙화하여 단일 팀에서 관리하도록 하고 애플리케이션팀에는 개별 Spanner 배포의 자동 확장 처리 구성을 관리할 수 있는 재량을 부여하면 됩니다. 다음 다이어그램에서 이 배포 옵션을 보여줍니다.
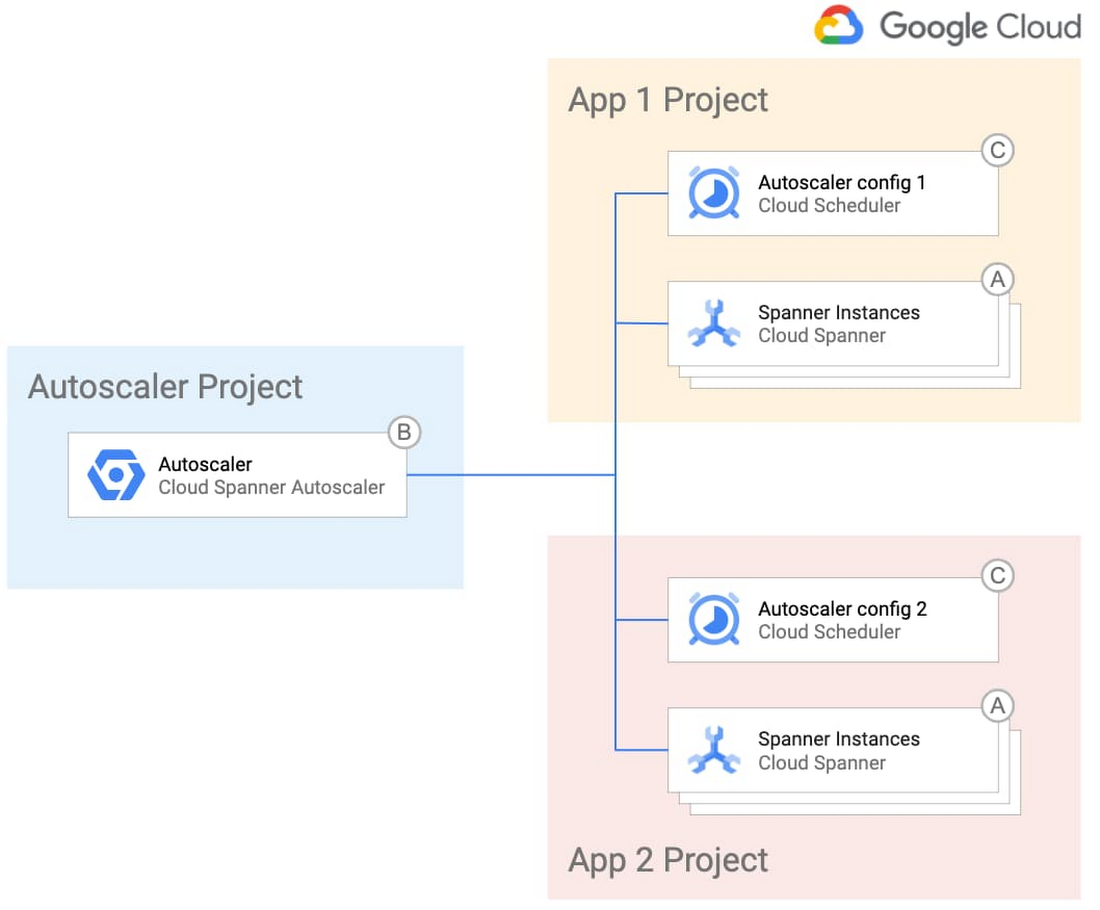
빠른 준비와 실행을 위해 GitHub 저장소에는 Terraform 구성 파일과 각 환경에 따른 단계별 안내가 포함되어 있습니다.
자동 확장 처리는 어떻게 작동되나요?
간단히 말해 자동 확장 처리는 Cloud Monitoring API에서 측정항목을 가져와 권장되는 기준과 비교한 후 Spanner에 노드를 추가 또는 삭제하도록 요청합니다. 다음 다이어그램은 분산형 배포의 내부 구성요소를 보여줍니다.
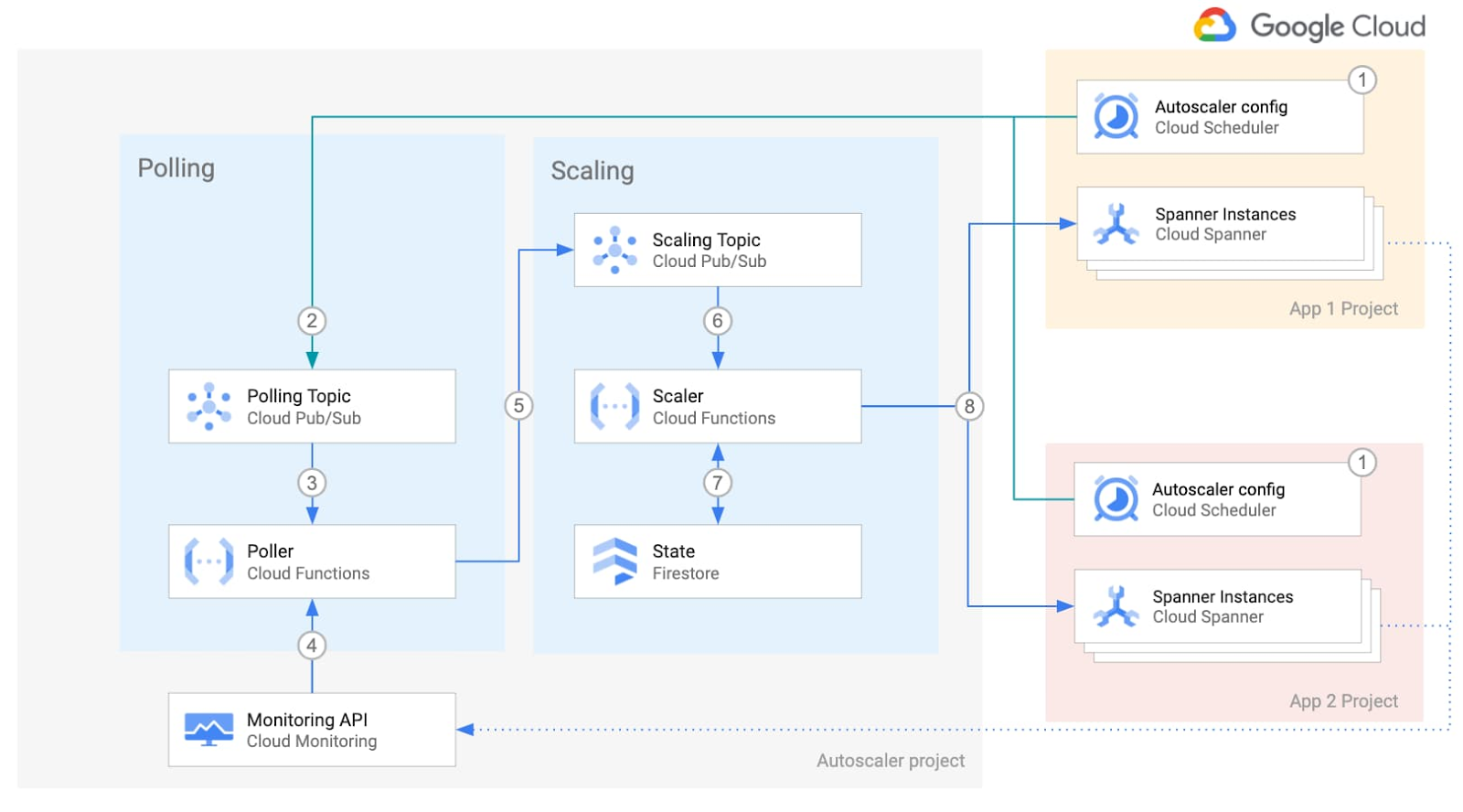
(1) Cloud Scheduler 작업을 하나 이상 구성하여 자동 확장 처리에서 측정항목을 가져오는 빈도를 정의합니다. (2) 이 작업이 트리거되면 Cloud Scheduler에서 Pub/Sub 큐에 정의한 인스턴스별 구성 매개변수를 사용해 메시지를 게시합니다. (3) Cloud 함수('Poller')에서 이 메시지를 읽고 (4) Cloud Monitoring API를 호출하여 Cloud Spanner 인스턴스 측정항목을 가져온 후 (5) 다른 Pub/Sub 큐에 이를 게시합니다.
(6) 별도의 Cloud 함수('Scaler')에서 새 메시지를 읽고 (7) 마지막 확장 이벤트 후 안전한 기간이 지났는지 확인하고 (8) 권장 노드 수를 계산하여 특정 인스턴스에 노드를 추가하거나 삭제하도록 Cloud Spanner에 요청합니다.
이 과정이 진행되는 동안 자동 확장 처리에서 추적 및 감사를 위해 Cloud Logging에 권장사항 및 작업의 단계별 요약을 작성합니다.



