BigQuery のユーザー フレンドリーな SQL について一年を振り返る

Google Cloud Japan Team
※この投稿は米国時間 2022 年 12 月 15 日に、Google Cloud blog に投稿されたものの抄訳です。
今年初めのバレンタイン デー アップデートで、BigQuery SQL をこれまで以上にユーザー フレンドリーにする新機能を発表しました。今回の年末エディションでは、エンタープライズ クラス、データ品質、スキーマ オペレーションのカテゴリで導入した新しい SQL 機能をご紹介します。
エンタープライズ クラス
エンタープライズ データ アナリスト向けに、従来のデータベースやデータ ウェアハウスで使用したことのある馴染みのある方法でワークロードを管理できるようにする BigQuery SQL の新機能が追加されました。
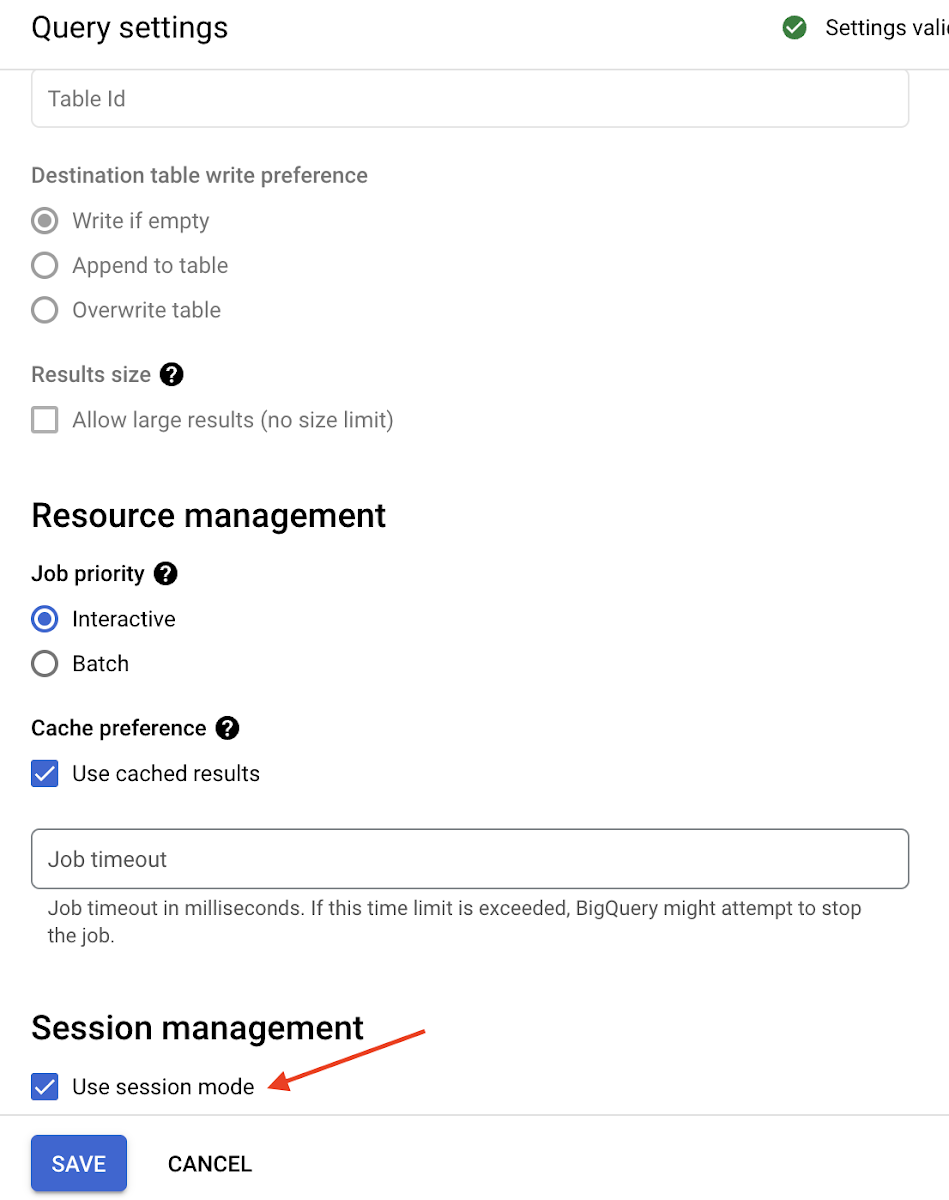
セッション(一般提供)
データベース セッション(またはセッション)は、ユーザーまたはプログラムと、クエリデータを保存するデータベースまたはデータ ウェアハウスとの間の接続を表します。データ アナリストがツールまたはプログラムを通じて実行する複数のコマンドも、このセッションで追跡されます。BigQuery は本質的にステートレスなクエリエンジンであるため、従来のデータベース接続のような永続的なネットワーク接続は維持されません。これによって BigQuery は、制限なくコンピューティングとストレージを個別にスケールできます。
セッションを通じて BigQuery アクティビティを管理することを検討している企業のデータ管理者は、オプションとして UI、API、CLI を使用して BigQuery でセッション サポートを有効にするか、JDBC または ODBC ドライバで EnableSession パラメータを設定できます。そうすることで、企業は永続的な接続によるオーバーヘッドなしに、セッションのすべてのメリットを享受できます。
データ アナリストにとって、セッションは次のメリットを提供します。
セッションの変数: セッション固有の変数を作成できます。この変数は、セッションで実行されるすべてのコマンドで保持されます。
システムの変数: タイムゾーン、データセット ID、プロジェクト、セッション ID に対して事前構築された変数。これらの変数を指定すると、データ アナリストは組織レベルまたはプロジェクト レベルのデフォルト値を、セッション固有の設定でオーバーライドできます。
セッション継続期間中の一時テーブルと一時的な関数: セッション中に結果をステージするために一時テーブルを使用したり、クエリ オペレーションを効率化するためにセッション固有の一時的な関数を使用したりすると、その一時テーブルや一時的な関数がセッション継続期間中を通じて保持され、そのセッション内のすべてのジョブでアクセスできます。
データ管理者にとってのメリットは次のとおりです。
セッション ラベル: ジョブ トラッキング用にラベルを割り当てることで、データ管理者は監査ログでそのラベルを使用して、そのセッションに関連付けられたすべてのアクティビティを見つけることができます。
セッション管理: データ管理者は、セッション ID を入力として使用して BQ.ABORT_SESSION システム プロシージャを呼び出すことで、手動でセッションを終了できます。
BigQuery セッションは、マルチステートメント クエリとマルチステートメント トランザクションもサポートします。ドキュメント
大文字と小文字を区別しないデータセットとテーブルの名前(プレビュー)
BigQuery テーブルの名前とデータセットの名前は、デフォルトで大文字と小文字が区別されます。これは、その起源であるビッグデータ分析では、常にデータセット ファイルの名前で大文字と小文字が区別されているためです。データ アナリストが従来のデータ ウェアハウスから持ち寄ったツールやプログラムに対して、よりユーザー フレンドリーなサービスとなるように、BigQuery は大文字と小文字を区別しないテーブル名とスキーマ(データセット)名をサポートするようになりました。この場合たとえば、dataset.Table、DaTaSeT.TABLE、Dataset.table、DATASET.tAbLe はどれも同じ名前として認識されます。これは、データセットまたはテーブルの定義(DDL)で is_case_insensitive オプションを使用して構成できます。ドキュメント
データ品質
BigQuery などのデータ分析プラットフォームは、意思決定を支援するためにさまざまなソースからデータを収集するため、データ エンジニアは重要なデータ要素の質を維持する必要があります。データソースは不完全だったり、その情報が不十分だったりする場合があります。そのため、列データが不足している場合、データ エンジニアはインテリジェントなデフォルト ロジックを構成して、適切なデータが入力されるようにする必要があります。同様に、データ パイプラインは、数値データのバイアスを減らし、正確な結果を確実に得られるように、柔軟なロジックを提供する必要があります。データ分析では、大文字と小文字の区別なくテキスト情報を照合して、正確なレポートを作成する必要があります。
デフォルトの列の値(プレビュー)
テーブルに新しい行が挿入されると、データが含まれない列が存在する場合があります。デフォルト値の式では、関連付けられた列データがない場合にデフォルト値を算出するリテラル値または関数を使用して、デフォルトの値を指定できます。デフォルト値の指定は、新しいテーブルの作成時に、または既存テーブルの列のプロパティを変更することで、設定できます。また、INSERT、CREATE TABLE AS SELECT、MERGE などの DML ステートメントによって、実際の挿入値の代わりにデフォルトのロジックを指定できます。このロジックは挿入先の列のデフォルト指定を使用します。ドキュメント
大文字と小文字を区別しない文字列の照合順序(プレビュー)
照合順序の指定は、列のオペレーション(結合、比較など)または ORDER BY、GROUP BY といった句と関連付けられた場合、文字列の値を比較するまたは並べ替えるために使用するロジックを決定します。たとえば、BigQuery 固有のデフォルトの照合順序は「バイナリ」で、コードポイントの順序を使用して Unicode でオーダリング シーケンスを指定します。このシーケンスでは、すべての大文字 [A-Z] が小文字 [a-z] に先行します。このたび、「und:ci」を使用して指定する、大文字と小文字を区別しない照合順序を利用できるようになりました。この順序では、文字列の値のオペレーションにおいて、[A,a] は同等の文字として扱われ、[B,b] に先行するようになります。これにより、データ アナリストはマッチする文字列の値を、大文字と小文字を区別せずに(たとえば Maclean と MacLean を同等に扱って)見つけることができます。ドキュメント
偶数丸め(一般提供)
BigQuery はネイティブで、最大有効桁数を超えるすべての値を、最も一般的な丸めロジックである四捨五入を使用して丸めてきました。しかし、四捨五入だけを使用すると、合計や平均などの集計オペレーションが実際の値から外れ、丸めバイアスが生じる可能性があります。Gaussian ラウンディング(一般的に「偶数丸め」と呼ばれる)などの他の丸め手法は、代替の丸めスキームを提供します。これらの手法では、ほとんどの合理的な値分布での集計において、四捨五入ほど大きなマイナスまたはプラスのバイアスは生じません。これに関して、BigQuery は、テーブル定義と明示的な ROUND 関数において、列に対する複数の丸めモードをサポートできるようになりました。つまり、既存の丸めモード「round_half_away_from_zero」と新しい丸めモードである偶数丸め(「round_half_even」とも呼ばれる)です。「round_half_even」モードは、最も近い「隣りの数字」の方に値を丸めます。ただし、両隣りの数字が等距離の場合は偶数の方に丸めます。たとえば、3.1 と 3.2 は 3 に丸められ、3.5 と 4.5 は 4 に丸められます。ドキュメント
スキーマ オペレーション
BigQuery は、スキーマ オペレーションの SQL 構文を継続的に拡張する取り組みの一環として、2 つの新しい SQL 機能を導入しました。テーブルにデータを読み込む LOAD DATA と、既存のテーブル列の名前を変更できる RENAME columns です。
LOAD DATA(プレビュー)
このステートメントはデータ エンジニアとアナリストに、1 つまたは複数のファイルをテーブルに読み込むための SQL インターフェースを提供します。この機能によって、BigQuery がサポートするすべてのファイルタイプ(CSV、AVRO、Parquet、JSON など)からの読み込みの一環として、名前が付けられたテーブルに読み込む、新しいテーブルを作成する、または既存のテーブル内のデータをすべて削除することができます。テーブルのメタデータや有効期限などのテーブル オプションの指定に加えて、LOAD DATA コマンドは、ユーザーがテーブル指定の一部として、または外部ファイルの Hive パーティショニング指定から、パーティション スキームとクラスタリング スキームを指定できるようにします。
LOAD DATA は、BigQuery の読み込み API と同じリソースプールを使用してデータを読み込みます。お客様が定額スロットで PIPELINE 予約を構成した場合、LOAD DATA は PIPELINE 予約の割り当てから専用のコンピューティング スロットを使用します。ドキュメント
RENAME column(プレビュー)
RENAME COLUMN を使用すると、既存のテーブルに含まれる列の名前を変更できます。これはメタデータのみの変更です。以前は、列の名前を変更するには、列のデータを書き換える必要がありました。現在は、名前が古くなった、または間違った名前を付けてしまったなどの理由で列の名前を変更する必要がある場合、データオーナーは、費用のかからないメタデータのみのコマンドである RENAME column を実行して、列の名前を修正できます。ドキュメント
本年を締めくくるにあたって、新年に、BigQuery SQL をこれまで以上にユーザー フレンドリーなサービスにする新しい機能を、BigQuery データに強いご関心をお持ちの皆様にお届けできることを嬉しく思っております。