Vertex AI Prediction の最適化された TensorFlow ランタイムでモデルの推論を迅速化
Google Cloud Japan Team
※この投稿は米国時間 2022 年 6 月 15 日に、Google Cloud blog に投稿されたものの抄訳です。
サービスのレコメンデーションから不正行為の検出やルートの最適化まで、低レイテンシでの予測を実現することは、膨大な数の機械学習タスクを実行するために必要不可欠です。このたび Google は、Vertex AI Prediction サービス上の TensorFlow モデル サービングを最適化する新しいランタイムの公開プレビューを開始します。この最適化された TensorFlow ランタイムは、Google 社内で使用されているテクノロジーとモデル最適化手法を活用しており、トレーニングやモデル セービング コードを一切変更することなく、サービング ワークフローに組み込むことができます。そのため、オープンソース ベースのビルド済み TensorFlow サービング コンテナと比較して、低コストでより迅速な予測が可能となります。
この投稿では、最適化された TensorFlow ランタイムの概要について紹介し、いくつかの機能や使用方法について説明したうえで、パフォーマンスを実証するベンチマーク データを提示します。ランタイムの使用方法に関する詳細は、Vertex AI ユーザーガイドの最適化された TensorFlow ランタイムをご覧ください。
最適化された TensorFlow ランタイムの概要
最適化された TensorFlow ランタイムは、モデルの最適化と Google 独自のテクノロジーを使用して、オープンソースの TensorFlow よりも低コストでトレーニング済みモデルを迅速にサービングします。このランタイムは、TensorFlow ランタイム(TFRT)と Google の内部スタックの両方を活用しています。
モデルのデプロイ時に特定のコンテナを選択し、必要に応じてフラグをいくつか設定するだけでこのランタイムを使用できます。これにより、次のメリットが得られます。
GPU での表形式モデルのパフォーマンスの改善: このランタイムにより、モデルの演算でコストのかかる部分は GPU で実行されるため、表形式モデルが低コストで迅速にサービングされます。残りの部分は、ホストとアクセラレータ間の通信を最小限に抑えることにより、CPU で処理されます。GPU で実行すべきオペレーションと CPU で実行すべきオペレーションは、ランタイムにより自動で判別されます。この最適化は、モデルコードの変更やフラグの設定を行う必要はなくデフォルトで使用できます。
モデルのプリコンパイル: すべて(または一部)の TensorFlow グラフをプリコンパイルし、すべてのオペレーションを個別に実行することで発生するオーバーヘッドを軽減します。なお、プリコンパイルはオプションであり、モデルのデプロイ時に有効にできます。
適合率に影響する最適化: このフラグを設定すると、レイテンシとスループットを大幅に改善するオプションの最適化が有効になります。ただし、モデルの適合率や精度がわずかに低下する場合があります(通常 1% 未満)。そのため、この最適化を有効にしたモデルをデプロイする場合は、事前にホールドアウト検証セットで最適化モデルの適合率や精度をテストすることをおすすめしています。
以上が公開プレビュー版の時点で使用できる最適化です。今後のリリースでは、さらなる改良を加え最適化機能を追加していく予定です。
最適化された TensorFlow ランタイムのプライベート エンドポイントを使用すると、レイテンシをさらに低減できます。詳細については、Vertex AI Prediction ユーザーガイドのオンライン予測にプライベート エンドポイントを使用するをご覧ください。
上記の最適化による効果は、モデル内で使用されている演算子やモデル アーキテクチャによって異なります。また、レイテンシとスループット(コストなど)の改善度はモデルによって異なります。この後のセクションで紹介するベンチマークで、希望する効果についての大まかな見込みを示します。
最適化された TensorFlow ランタイムの使用方法
最適化された TensorFlow ランタイムの使用方法は、オープンソース ベースのビルド済み TensorFlow サービング コンテナの使用方法とほとんど変わりません。オープンソースの TensorFlow ビルドがベースのビルド済みコンテナを使用する代わりに、最適化された TensorFlow ランタイムのコンテナを選択するだけです。
使用できるコンテナには、ナイトリー版と安定版の 2 種類があります。ナイトリー版のコンテナは最新の状態にアップデートおよび最適化されており、テストに最適です。一方、安定版のコンテナは TensorFlow の安定版リリースに基づくもので、本番環境へのデプロイに最適です。最適化された TensorFlow ランタイムのコンテナの一覧については、使用可能なコンテナ イメージをご覧ください。
この記事ですでに説明した「モデルのプリコンパイル」と「適合率に影響する最適化」の 2 つの最適化オプションは、デプロイを構成するタイミングで有効にできます。この 2 つの最適化オプションを有効にする詳しい方法については、Vertex AI Prediction ユーザーガイドのモデル最適化フラグをご覧ください。
次のコードサンプルが示しているのは、ビルド済みの最適化された TensorFlow ランタイム コンテナを使用してモデルを作成する方法です。主な違いは、us-docker.pkg.dev/vertex-ai-restricted/prediction/tf_opt-cpu.nightly:latest コンテナを “container_spec” で使用する点です。詳細については、Vertex AI Prediction ユーザーガイドの最適化された TensorFlow ランタイムを使用してモデルをデプロイするをご覧ください。
パフォーマンスの比較
Vertex AI Prediction の最適化された TensorFlow ランタイムを使用するメリットを示すために、Vertex AI Prediction にデプロイされた表形式の Criteo と BERT ベースの分類モデルを並べて比較しました。なお、比較には既存の TensorFlow 2.7 と最適化された TensorFlow ランタイム コンテナを使用しました。
パフォーマンスを評価するため、「サーバー」シナリオで MLPerf loadgen for Vertex AI を使用しました。MLPerf loadgen は、MLPerf Inference の公式ベンチマークと同じ配分を使用して Vertex Prediction エンドポイントにリクエストを送信します。モデルが飽和状態になるまで秒間クエリ数(QPS)を増加させながらこの loadgen を実行し、リクエストごとのレイテンシを観測して記録しました。
モデルとベンチマーク コードは完全に再現可能であり、GitHub の vertex-ai-samples リポジトリで入手できます。次のノートブックを使用して、ベンチマーク テストを検証および実行できます。
Criteo モデルのパフォーマンス テスト
Criteo の表形式モデルを、NVIDIA T4 GPU インスタンス、最適化された TensorFlow ランタイム、TF2.7 CPU、TF2.7 GPU コンテナで n1-standard-16 を使用して Vertex AI Prediction にデプロイしました。最適化された TensorFlow ランタイムと gRPC プロトコルの併用は公式にサポートされているわけではありませんが、連携して動作します。さまざまな Criteo モデルのデプロイのパフォーマンスを比較するために、バッチサイズ 512 のリクエストで gRPC プロトコルを使用して、Vertex AI Prediction のプライベート エンドポイントで MLPerf loadgen ベンチマークを実行します。
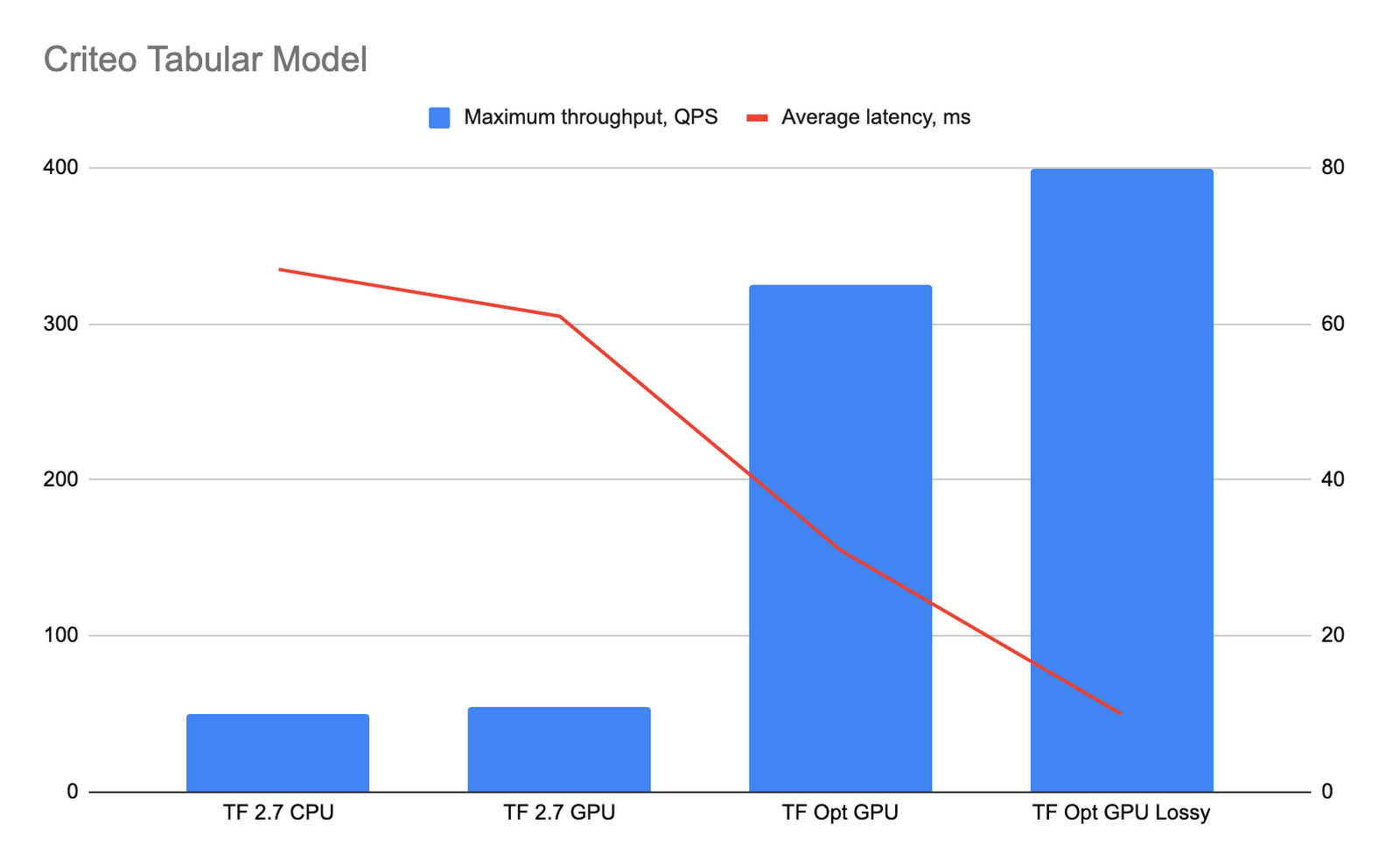
下のグラフはパフォーマンスの結果を示したものです。「TF Opt GPU」の棒は、プリコンパイルが有効な最適化された TensorFlow ランタイムのパフォーマンスを表し、「TF Opt GPU lossy」の棒は、プリコンパイルと適合率に影響する最適化の両方が有効な場合のパフォーマンスを表しています。
最適化された TensorFlow ランタイムにより、大幅なレイテンシの低減とスループットの向上が得られました。最適化された TensorFlow ランタイムにより演算の大部分が GPU に移行されることにより、CPU 性能の低いマシンを使用できるようになります。このようなベンチマーク テストにより、適合率に影響する最適化オプション(TF Opt GPU lossy の棒)を有効にすることでモデルのパフォーマンスが大幅に向上することがわかりました。また、適合率に影響する最適化が有効になっている最適化された TensorFlow ランタイム上で実行されているモデルと、TF2.7 コンテナ上で実行されているモデルについて、51,200 リクエストに対する予測結果を比較しました。その結果、適合率に関する平均値の差は 0.0016% 未満、最も差がある場合でも 0.05% 未満でした。
こうした結果に基づき、表形式 Criteo モデルでは、最適化された TensorFlow ランタイムは TensorFlow 2.7 CPU と比較してスループットが約 6.5 倍、レイテンシが約 2.1 倍改善し、適合率に影響する最適化が有効な場合にはスループットが約 8 倍、レイテンシが約 6.7 倍改善することがわかりました。
BERT ベース モデルのパフォーマンス テスト
BERT ベース モデルのベンチマーク実行については、TensorFlow Hub の bert_en_uncased_L-12_H-768_A-12 分類モデルを IMDB データセットを使用した感情分析用に微調整しました。バッチサイズ 32 のリクエストで、パブリック エンドポイントで MLPerf loadgen を使用してベンチマークを実行しました。
下のグラフはパフォーマンスの結果を示したものです。「TF Opt GPU」の棒は、プリコンパイルが有効な最適化された TensorFlow ランタイムのパフォーマンスを表し、「TF Opt GPU lossy」の棒は、プリコンパイルと適合率に影響する最適化の両方が有効な場合のパフォーマンスを表しています。
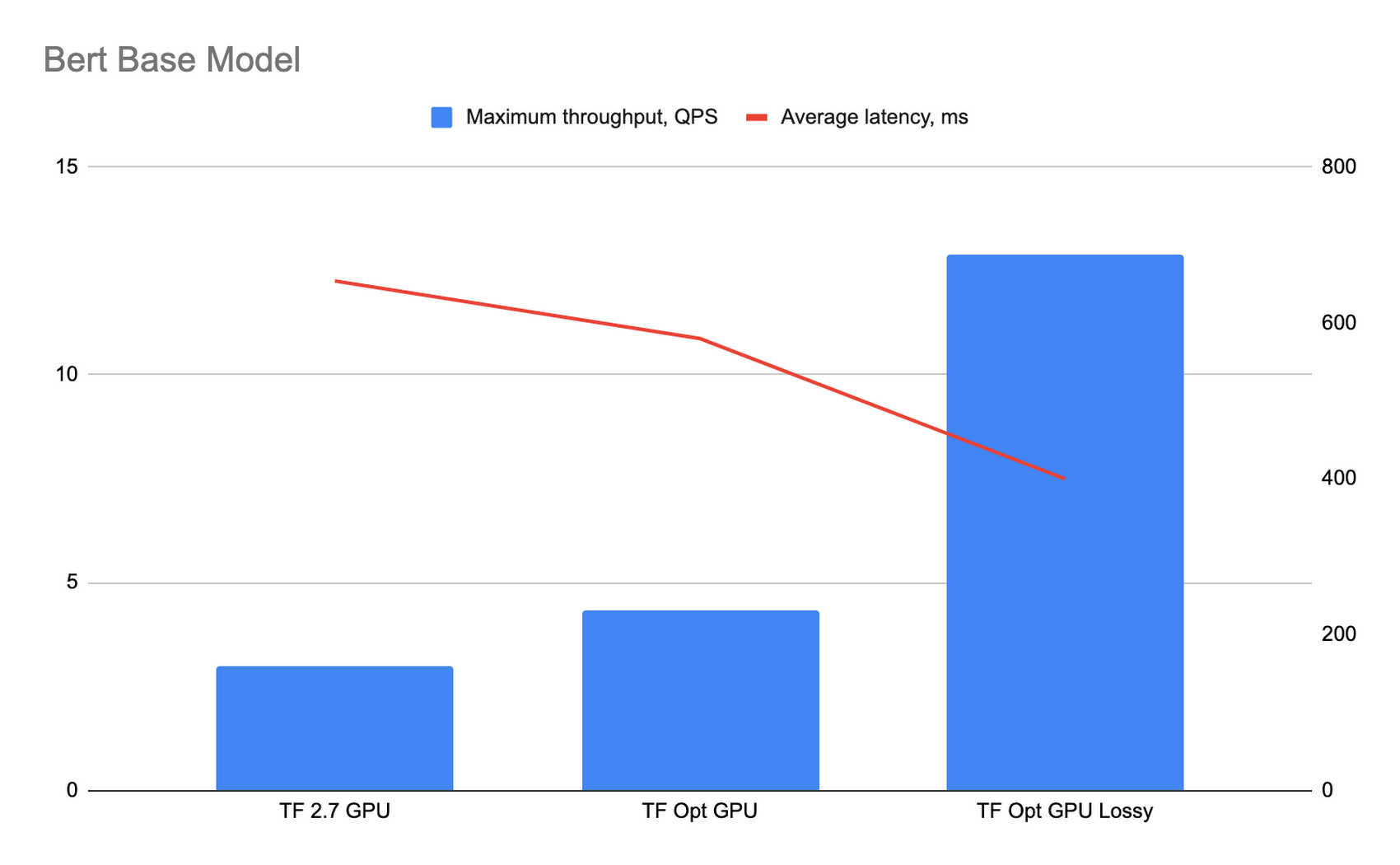
適合率に影響する最適化により、モデルの適合率にどの程度影響があるかを見極めるため、適合率に影響する最適化が有効になっている最適化された TensorFlow ランタイム上で実行されているモデルと、TF2.7 コンテナ上で実行されているモデルについて、32,000 リクエストに対する予測結果を比較しました。その結果、適合率に関する平均値の差は 0.01% 未満、最も差がある場合で 1% 未満でした。
BERT ベース モデルでは、最適化された TensorFlow ランタイムは TensorFlow 2.7 と比較してスループットが約 1.45 倍、レイテンシが約 1.13 倍改善し、適合率に影響する最適化が有効な場合にはスループットが約 4.3 倍、レイテンシが約 1.64 倍改善することがわかりました。
次のステップ
この記事では、新しい最適化された TensorFlow ランタイムの概要と使用方法について紹介しました。ベンチマークの結果を再現したいお客様は、Criteo や Bert のサンプルをお試しください。または、使用可能なイメージのリストを確認し、ご自身でレイテンシ低減テストを実行してみてください。
謝辞
今回のプロジェクトでベンチマーク結果の取得に大きく貢献した Cezary Myczka 氏に感謝いたします。
- デベロッパー アドボケイト Nikita Namjoshi
- ソフトウェア エンジニア Aleksey Vlasenko
- テクニカル ライター Mark Iverson