自然言語クエリを使用した画像検索
Google Cloud Japan Team
※この投稿は米国時間 2021 年 8 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
この投稿では、自然言語クエリを使用して画像検索ユーティリティを構築する方法を紹介します。目的は、さまざまな GCP サービスを使用して実際の手順を示すことです。プロジェクトの中心となっているのは、OpenAI の CLIP モデルです。このモデルは、2 つのエンコーダ(1 つは画像用、もう 1 つはテキスト用)を利用しています。それぞれのエンコーダは表現を学習するようトレーニングされており、類似した画像やテキストのエンベディングが、可能な限り近接して投影されるようになっています。
最初に、自然言語クエリを処理し、関連画像に一致させることができる、Flask ベースの REST API 機能を作成します。次に、Flutter ベースのウェブおよびモバイルアプリを通して API を使用する手順をお見せします。図 1 は、今回の最終的なアプリケーションがどのようになるのかを示しています。
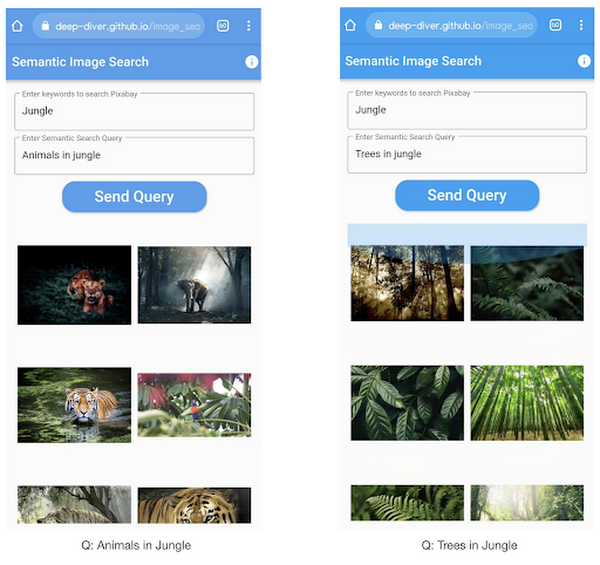
この投稿内のすべてのコードは GitHub リポジトリで公開されています。それでは詳しく見ていきましょう。
アプリケーションの概要
アプリケーションは、ユーザーから次の 2 つのクエリを受け取ります。
タグまたはキーワード クエリ。これは、Pixabay から対象の画像のセットを pull するために必要です。そのために、他の画像リポジトリを使用しても構いません。しかし、Pixabay の API では作業がより簡単なことがわかりました。これらの画像をキャッシュに保存して、ユーザー エクスペリエンスを最適化します。「花畑の中にいる馬」というクエリに類似した画像を見つけたいとします。そのためには、まず数枚の「馬」の画像を pull してから、別のユーティリティを実行して、このクエリに最も一致する画像を見つけます。
前述の手順で作成したプールから画像を取得するために使用する、長いクエリまたは意味的クエリ。これらの画像は、このクエリに意味的に類似している必要があります。
注: 2 つのクエリの代わりに長いクエリを 1 つだけ受け取り、名前付きエンティティ抽出を実行して最も重要だと思われるキーワードを判断し、それを使用して最初の検索を実行することもできます。今回の投稿では、このアプローチは使用しません。
以下の図 2 は、各コンポーネントに使用される、アプリケーションのアーキテクチャ設計と技術スタックを示しています。
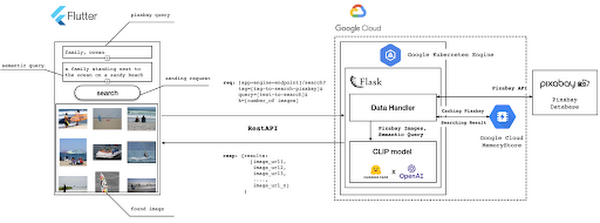
図 2: アーキテクチャ設計とフロー。
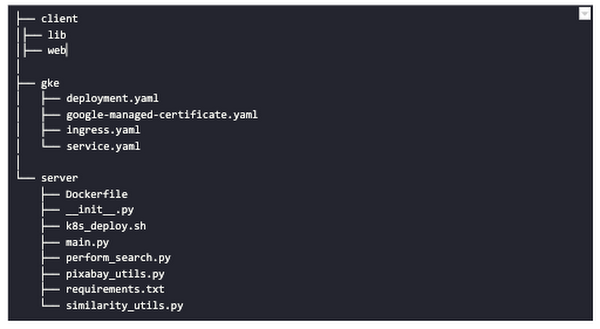
図 2 は、この投稿で断片的に開発する API の中心となるロジックも示しています。Google Kubernetes Engine(GKE)を使用して、Kubernetes クラスタ上にこの API をデプロイします。以下は、アプリケーションのコードベースの簡潔なディレクトリ構造を示しています。
次に、画像検索 API を構築するための、コードと他の関連コンポーネントについて説明します。さまざまな機械学習関連のユーティリティ向けに、PyTorch を使用します。
Flask を使用したバックエンド API の構築
まずは、自然言語画像検索を実行する前に、ユーザーが指定したタグやキーワードに関して一連の画像を取得する必要があります。pixabay_utils.py スクリプトの以下のユーティリティがこれを行ってくれます。
すべての API ユーティリティがロギング関連の情報である点に注意してください。ただし、わかりやすくするため、ロギング関連のコード行は省略しています。次に、CLIP モデルを呼び出し、指定されたクエリに意味的に最も一致する画像を選択する方法を紹介します。このためには、最先端の NLP 機能を提供する、使いやすい Python ライブラリである Hugging Face を使用します。この検索に関連するすべてのロジックを SimilarityUtil クラス内で照合します。
CLIP_MODEL は ViT ベースのモデルを使用して、指定されたクエリに関する、意味を持つエンベディングを生成するための画像をエンコードします。エンベディングを生成するための Transformers ベースのモデルを使用して、テキストベースのクエリもエンコードされます。これら 2 つのエンベディングは、推論中に互いに照合されます。CLIP モデルに使用している特定の手法の詳細については、Hugging Face のこちらのドキュメントをご覧ください。
前述のコードでは、画像と自然言語クエリを含む CLIP モデルをまず呼び出しています。これにより、各画像とクエリ間の類似性スコアを含むベクトル(logits_per_image)を取得できます。次に、ベクトルを降順で並べ替えます。モデルの読み込み時間を短縮するために、SimilarityUtilをインスタンス化しながら、CLIP モデルを初期化している点に注目してください。これはアプリケーションの重要な部分であり、すでに対処してあります。リアルタイムでこのユーティリティを操作したい場合は、こちらの Colab ノートブックをご覧ください。
次に、Pixabay から画像を取得し、単一のスクリプト(perform_search.py)内で自然言語画像検索を実行するために、ユーティリティを照合する必要があります。以下は、そのスクリプトのメインクラスです。
ここでは、最も類似している画像の URL とそのスコアを返すための、さきほど開発したユーティリティを呼び出しているだけです。ここでさらに重要なのは、取得機能です。このために、GCP の MemoryStore と、direct-redis という Python ライブラリを組み合わせています。MemoryStore の設定の詳細は後ほど説明します。
MemoryStore は、Redis インスタンスをホストするための、フルマネージドで低コストのプラットフォームを提供します。Redis データベースはインメモリで軽量なため、キャッシュに最適となっています。前述のコードでは、Pixabay から取得した画像とその URL をキャッシュに保存しているので、キャッシュ ヒットが発生しても CLIP モデルを呼び出す必要はなく、API の応答時間が大幅に向上します。
キャッシュのその他のオプション
アプリケーションの他の要素をキャッシュに保存することもできます。たとえば、自然言語クエリもキャッシュに保存できます。キャッシュ ヒットであるかどうかを判断するためにキャッシュに保存されたエントリを検索する際に、2 つのクエリを意味的類似性で比較し、それに応じた結果を返すことができます。
ユーザーが「暗い空と山」という自然言語クエリを入力したとします。検索の実行後、このクエリのエンベディングをキャッシュに保存します。次に、別のユーザーが「薄暗い雰囲気の山」という別のクエリを入力したとします。このエンベディングをコンピューティング処理して、キャッシュに保存されたエンベディングを使用して類似性検索を実行します。次に、しきい値に関連して類似度スコアを比較し、最も類似しているクエリと対応する結果を解析します。キャッシュミスの場合は、さきほど開発した画像検索ユーティリティを呼び出します。
リアルタイムのアプリケーションで作業をする際は、大抵の場合、こうしたさまざまな側面を考慮し、何がユーザー エクスペリエンスを向上させて同時にビジネス価値を最大化させるのかを決定する必要があります。
バックエンドで必要なのは、後は Flask アプリケーションである main.py だけです。
ここでは、まず検索 API のリクエスト ペイロードのクエリ パラメータを解析しています。次に、perform_search.py から適切なファンクションを呼び出してリクエストを処理しています。この Flask アプリケーションは CORS を処理することもできます。これは、flask_cors ライブラリによって行います。
これで完了です。API のデプロイの準備が整いました。
Compute Engine と GKE を使用したデプロイ
Kubernetes での API のデプロイが望ましい理由は、Kubernetes はデプロイの管理が柔軟であるからです。大規模な運用の場合、自動的なスケーラビリティと負荷分散は非常に重要です。セキュリティの要件を考慮すると、ユーティリティがデータベースなど内部サービスとやり取りすることは望ましくありません。Kubernetes では、これらすべてを簡単かつ効率的に実現できます。
GKE は Kubernetes クラスタを運用化するための、セキュアでフルマネージドの機能を提供します。GKE で API をデプロイする手順の概要は次のとおりです。
まず API 用に Docker イメージを構築して、それをGoogle Container Registry(GCR)に push します。
次に、GKE 上に Kubernetes クラスタを作成してデプロイを開始します。
次に、スケーラビリティのオプションを追加します。
API を一般公開する必要がある場合は、この問題にも対処します。
これらすべてをシェル スクリプトの k8s_deploy.sh に取り込めます。
これらの手順はこちらのチュートリアルで詳しく説明されているため、詳細を知りたい場合はご覧ください。ローカルマシンですべての依存関係を構成し、上記のシェル スクリプトを実行できます。また、GCP Console 上のターミナルは、必要なシステムレベルの依存関係を使用して事前構成されているため、GCP Console を使用して実行することもできます。実際には、Kubernetes クラスタは 1 度のみ作成し、さまざまなデプロイメント バージョンをその下に作成する必要があります。
上記のシェル スクリプトを正常に実行したら、kubectl get サービスを実行して、デプロイしたばかりのサービスの外部 IP アドレスを確認します。
次に、ベース URI http://203.0.113.0/ を使用してこの API を使用します。http ベースの API リクエストのみを処理する場合は、これで完了です。しかし、アプリケーションを確実に実行するには、セキュアな通信が必要となることがよくあります。次のセクションでは、Kubernetes クラスタが https リクエストを許可できるようにするための、追加アイテムの構成方法について説明します。
GKE を使用して https リクエストを処理するための構成
現代のクライアントとサーバーのアプリケーションでは、セキュアな接続がほぼ必須となっています。フロントエンドの Flutter アプリケーションは、このプロジェクトの GitHub ページでホストされ、http ベースの接続も必要となります。https 接続の構成は、特に GKE ベースのクラスタの場合は面倒そうに思え、その設定は最初は難しく見えるかもしれません。
GKE 環境で https 接続を構成するには 6 つの手順があります。
ドメイン名を用意する必要があります。低価格で購入できる選択肢が多数あります。たとえば、このプロジェクト用の mlgde.com ドメインは、韓国のサービス プロバイダである Gabia を通して取得しています。
予約済みの(静的)外部 IP アドレスは、gcloud コマンドまたは GCP Console を通して取得する必要があります。
ドメイン名を取得した外部 IP アドレスとバインドする必要があります。これは、ドメイン名の提供元の、プラットフォーム固有の構成です。
GKE 環境に固有の、特別な ManagedCertificate リソースがあります。ManagedCertificate リソースは、SSL 証明書の作成対象となるドメインを指定するために必要です。
Ingress リソースは、静的外部 IP アドレス、ManagedCertificate リソース、受信トラフィックのルーティング先のサービス名およびポートをリストして作成する必要があります。Service リソースは、LoadBalancer が ClusterIP に変更されたことを除き、前のセクションと同じとなります。
最後に、既存の Flask アプリケーションと Deployment リソースを修正し、Deployment の健全性ステータスの確認に使用される liveness および readiness プローブをサポートするようにします。Flask アプリケーション側は、flask-healthz Python パッケージを使用して簡単に修正できます。Deployment リソースで livenessProbe および readinessProbe セクションを追加するだけです。以下のコード例では、livenessProbe および readinessProbe が、それぞれ /alive および /ready エンドポイントを介してチェックされています。
ここで注意すべきは、プローブのinitialDelaySeconds 属性です。この属性を大きな数値で構成することは一般的ではありませんが、使用するモデルのサイズに応じて 90~120 秒以上にすることも可能です。このプロジェクトについては、CLIP モデルがメモリに読み込まれるまで待機するために、90 秒に構成されています(YAML スクリプト全文はこちら)。
繰り返しになりますが、これらの手順は最初は難しく思われるかもしれません。しかし、1 度行えばはっきりと理解できるようになります。Google が管理する SSL 証明書の使用の公式ドキュメントをご覧ください。このプロジェクトで使用されている GKE 関連のすべてのリソースは、こちらで公開されています。
すべての手順が完了したら、GKE 環境でサーバー アプリケーションが走行していることを確認できるはずです。Deployment、Service、Ingress、ManagedCertificate などの Kubernetes リソースを作成する際は、必ずkubectl apply コマンドを実行するようにしてください。また、ManagedCertificate のプロビジョニングが完了するまで 10 分以上待機することが重要です。
構成した静的外部 IP アドレスを確認するには、gcloud compute addresses リストコマンドを実行できます。
その後、IP アドレスがドメインにマッピングされる必要があります。図 3 は、mlgde.com ドメインを取得したダッシュボードのスクリーンショットです。GCP で構成した静的外部 IP アドレスに、mlgde.com がマッピングされているのがはっきりとわかります。

App Engine にこのアプリケーションをデプロイしない理由は、CLIP モデルの実行に必要なコンピューティングによるものです。App Engine インスタンスはこの体制に適していません。VPC Connector を介して、コンピューティング負荷の高い機能を取り組むこともできます。これは、ご自身とチームで検討すべき設計上の選択です。Google によるテストでは、今回のニーズについて GKE のデプロイがより簡単で適していることがわかりました。
CLIP モデルのインフラストラクチャ
前述のとおり、アプリケーションの中心となっているのは CLIP モデルです。演算コスト的には通常のディープ ラーニング モデルよりも若干高コストになります。そのため、モデルを実行するためにハードウェア インフラストラクチャを適切に設定することが大切です。GPU ベースの環境の利点を調べるために、小規模なベンチマークを実行しました。
Tesla P100 ベースのマシンと、標準的な CPU のみのマシンで CLIP を 1,000 回実行しました。以下のコード スニペットは、実行した内容です。
ある程度予想されたとおり、GPU ではコードの実行完了に 13 分かかりました。対して、GPU なしでは約 157 分かかりました。
モデル予測に GPU を利用するは費用上の制限から一般的ではありませんが、CLIP のような大規模なモデルのデプロイに GPU を利用する場合もあります。GKE に GPU ベースのクラスタを構成し、ありとなしの場合のパフォーマンスの違いを比較しました。GPU と MemoryStore キャッシュを使用してリクエストを処理するのには約 1 秒かかりましたが、MemoryStore のみ(GPU なし)の場合は 4 秒以上かかりました。
今回の投稿の目的では、Kubernetes で CPU ベースのクラスタを使用しました。しかし、GKE クラスタで GPU を使用するよう構成するのは簡単です。こちらのドキュメントでは、その方法を紹介しています。簡潔に説明すると、2 つの手順があります。まず、GKE クラスタの作成時に GPU ありでノードを構成する必要があります。次に、GKE ノードで GPU ドライバをインストールする必要があります。各ノードについて、自分でアクセスして手動で GPU ドライバをインストールする必要はありません。こちら.に記載のとおり、シンプルに DaemonSet リソースを GKE に適用できます。
MemoryStore の設定
このプロジェクトでは、まず画像の一般的なコンセプトを Pixabay にクエリし、次に CLIP を使用して意味的クエリで画像をフィルタします。これは、次の固有の意味的クエリのために、Pixabay から最初に取得した画像をキャッシュに保存できることを意味します。たとえば、まず「ネクタイを着けた男性」で検索し、「メガネを着けた男性」で検索をやり直すとします。この場合、ベースとなる画像はすべて同じままとなるため、Redis のようなキャッシュ サーバーにそれらを保存できます。
MemoryStore は、インメモリのデータストアである Redis をラップする GCP サービスであるため、アクセスに標準の Redis Python パッケージを単に使用できます。MemoryStore Redis インスタンスのプロビジョニング時に唯一注意すべきなのは、それが GKE クラスタまたは Compute Engine と同じリージョンにあることを確認することです。
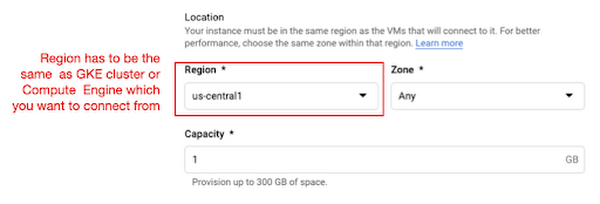
図 4: MemoryStore の設定。
以下のコード スニペットは、Python 内の Redis インスタンスに接続する方法を示しています。GCP に固有のことはありませんが、標準の redis-py パッケージの使用には注意する必要があります。
接続を作成すると、データを保存し MemoryStore からデータを取得できるようになります。Redis の高度なユースケースは多くありますが、デモ用として exists、get、set メソッドのみを使用しました。マップや辞書などの類似したデータ構造についての知識があれば、これらのメソッドには慣れていることでしょう。Redis 関連のユーティリティを使用するコードの部分については、前のセクションで説明した Searcher Python クラスを参照してください。
以下の URL では、MemoryStore の使用を左右で比較しています。
MemoryStore なしの場合: https://youtu.be/7B88Eyrd-4s
MemoryStore ありの場合(1 回目): https://youtu.be/LE6xeEIRuMM
MemoryStore ありの場合(2 回目): https://youtu.be/rRfK17sdk84
まとめ
最後に、これまでのセクションで開発したさまざまなコンポーネントを照合し、フロントエンドとともにアプリケーションをデプロイします。フロントエンド関連のコードはこちらにあります。
フロントエンド アプリケーションはFlutter 開発キットで記述されています。メイン画面には、それぞれ Pixabay と CLIP モデルへのクエリ用に 2 つのテキスト フィールドがあります。[Send Query] ボタンをクリックすると、RestAPI リクエストがサーバーに送信されます。サーバーから結果を受信すると、意味的クエリから取得した画像が画面の下部に表示されます。
Flutter アプリケーションは、パソコン、ウェブ、iOS、Android などのさまざまな環境向けにデプロイできます。できるだけシンプルにするために、ここではアプリケーションを GitHub ページにデプロイすることにしました。クライアント側のソース ディレクトリに変更が加えられた場合は、GitHub Action がトリガーされ、ウェブページが構築され最新バージョンが GitHub ページにデプロイされます。
最終的なアプリケーションはこちらにデプロイされており、次のようになっています。
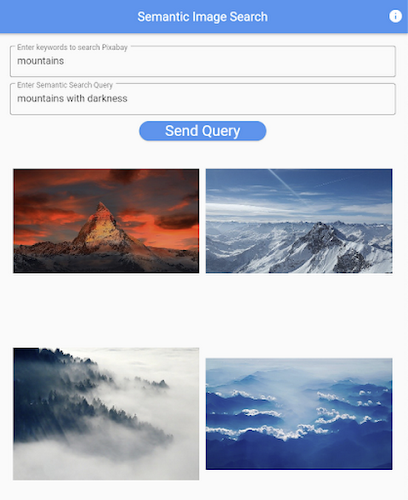
制限により、上記の URL は 1~2 か月間のみ公開される点にご注意ください。
GitHub Action を使用して、バックエンド アプリケーションを再デプロイすることもできます。
最初の手順は、以下のように Dockerfile ファイルを作成することです。Python はスクリプト言語であり、アプリケーションは数多くの負荷の高いパッケージに依存しているため、手順をキャッシュに保存することが重要です。たとえば、依存関係のインストールは他のコマンドと分離すべきです。
Dockerfile を定義したら、自動デプロイのためにこちらのような GitHub Action を使用できます。
エッジケース
CLIP モデルは、画像とテキストの組み合わせの巨大なコーパスで事前トレーニングされているため、スローするすべての自然言語クエリをうまく一般化できない場合があります。また、CLIP モデルが使用できる画像の数を制限しているため、モデルの表現性がある程度制限されます。
後者の状況については、プリフェッチされる画像の数を増やし、それらを Datastore のような低費用で高パフォーマンスなデータベースにインデックス登録することで、パフォーマンスを改善できる場合があります。
費用
このセクションでは、アプリケーション全体で使用されるさまざまなサービスの消費にかかる費用の内訳を紹介します。
フロントエンドのホスティング
フロントエンド アプリケーションは GitHub ページでホストされるため、費用はかかりません。
Compute Engine
GPU なしの e2-standard-2 インスタンスでは、費用はおよそ月額 $48.92 です。GPU(NVIDIA K80)を追加する場合は、費用は月額 $229.95 となります。
MemoryStore
MemoryStore の費用はサイズによります。1GB のスペースでは費用はおよそ月額 $35.77 となり、さらに GB を追加すると、費用は倍になります。
Google Kubernetes Engine
n2-standard-2(vCPUs: 2、RAM: 8GB、GPU なし)の 3 ノードの GKE クラスタの月額費用はおよそ $170.19 です。クラスタに GPU(NVIDIA K80)を 1 個追加すると、費用は $835.48 となります。
高額だと思われるかもしれませんが、Google では新しい GCP アカウントの作成時に $300 分の無料クレジットを差し上げています。GPU の利用には不十分ですが、GKE と MemoryStore の使用を試して学ぶには十分です。
結論
この投稿では、自然言語クエリ向けの基本的な画像検索ユーティリティを構築するために必要なコンポーネントについて説明しました。これらのさまざまなコンポーネントが互いに接続される仕組みについて説明しました。画像検索 API はキャッシュ機能を使用することができ、GKE を使用して Kubernetes クラスタにデプロイされました。これらの要素は、より大規模なワークロードに対応するための類似のサービスを構築する際に不可欠です。それに向けてこの投稿が良い開始地点となることを祈っています。以下に、類似した作業分野の参考ドキュメントを紹介します。
謝辞: GCP クレジットについてサポートを提供する Google Developers Experts プログラムに感謝します。この投稿の草案を推敲してくれた、Google の Karl Weinmeister と Soonson Kwon に感謝します。
- ML Google Developer Expert Chansung Park
- ML Google Developer Expert Sayak Paul