倫理的 AI の種をまこう: 軌道に乗るための 4 つのタスク

Google Cloud Japan Team
※この投稿は米国時間 2021 年 11 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
未来の AI は、最初から倫理と責任が組み込まれた、さらに良いものになっていくでしょう。これは同時に、モデルが公正な結果を出すように、きちんと機能した戦略とプロセスが確立されるまでは、AI 変革に待ったがかかるということを意味します。この必要性を認識していないと、利益を脅かすことになります。以下の投稿では、アルゴリズムへの信頼度を高めつつ、ビジネスを正しい方向に導くために従うべきシンプルなフレームワークを紹介します。
AI は本質的に社会技術的なものです。AI システムは、人間とテクノロジーの相互関連性を表しており、特定のコンテキスト内で人間が使用し、情報を得るように設計されています。AI が誇る速度と規模は、すなわち種々の責任の欠如も同じような速度と規模で再現されるということを意味します。責任とは例えばバイアス、安全性、プライバシー、科学的卓越性などです。倫理と責任が設計段階から組み込まれていないと、AI システムは長期的な成功のカギとなる「インプット」や社会的コンテキストを致命的に欠くことになります。
特定のグループに偏重した AI システムを原因とする訴訟が増えてきています。2020 年 8 月、気象チャンネル アプリで、データの不適切な収集を行ったとしてロサンゼルス市から提訴されていた IBM は、同市との和解を余儀なくされました。ヘルスサービスの会社である Optum は、医師や看護師がより重症の黒人よりも白人の患者に注意を向けさせるよう推奨するアルゴリズムを作成した疑いで、規制当局の捜査を受けています。また、Facebook は、政治関連団体である Cambridge Analytica に 5,000 万人以上の個人データへのアクセスを許可したとして、訴訟に巻き込まれています。 Google は、アルゴリズムが重大なミスを犯すという問題にも遭遇しています。
訴訟などの問題ももちろんですが、倫理的 AI が収益に直結する基本的な理由は、信頼です。信頼がなければ、お客様の関心は徐々に薄れ、より信頼のおけるブランドを選ぶことになるでしょう。世界規模のブランド エクイティの調査(50 市場にわたる 400 万人の消費者、18,000 ブランド)を実施している Kantar が行った調査によると、ブランド エクイティの約 9% は企業の評判に大きく左右され、中でも責任感は重要な属性であることが明らかになりました。過去 10 年間で、ブランド選択における企業の消費者に対する責任の重要性は 3 倍に増えました。
同調査によると、世界で最も信頼され、責任感があると評価されているブランドには、共通した 3 つの重要な要素があることがわかりました。これらの要素は、新しい市場においても、消費者の信頼と確信を築くために特に重要であるとされています。その要素は以下の 3 つです。
誠実さとオープン性
尊重とインクルージョン
お客様とのつながりと思いやり
こういった要素を強く持つブランドは、ブランド価値を守り、成長させるうえで、競合他社よりも優位に立つ傾向があります。
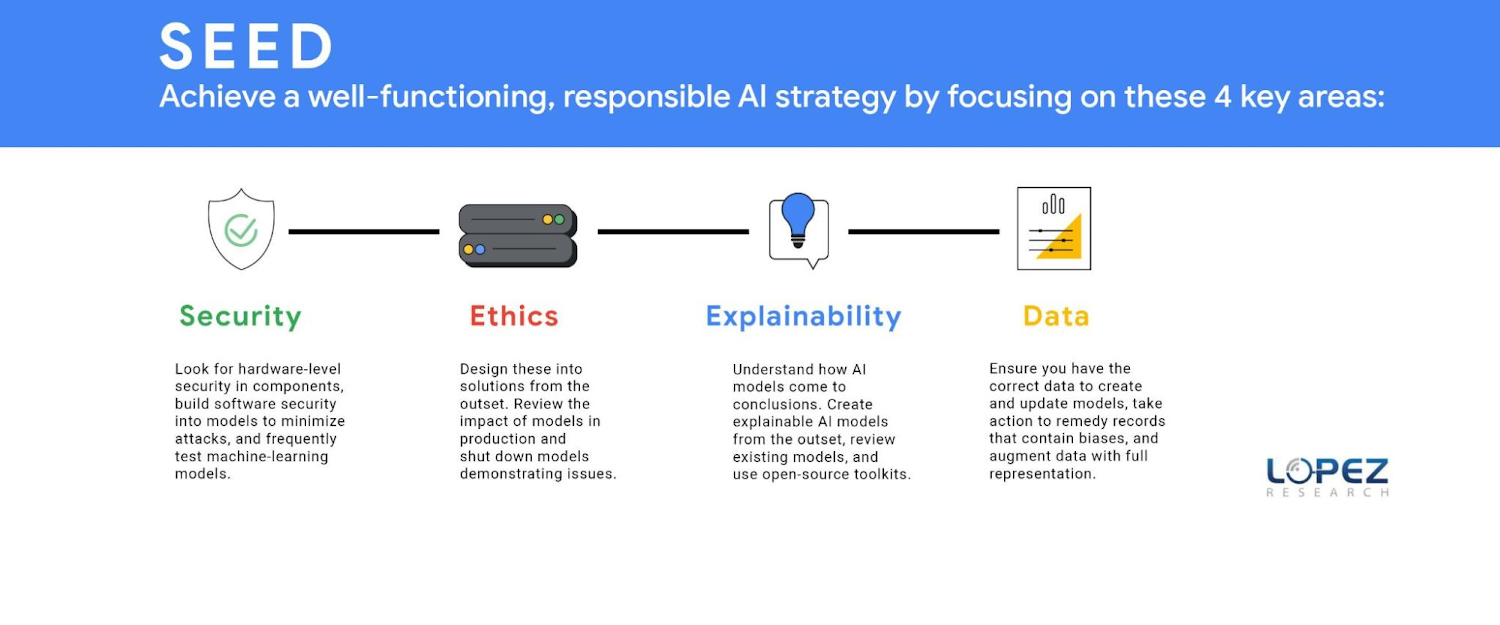
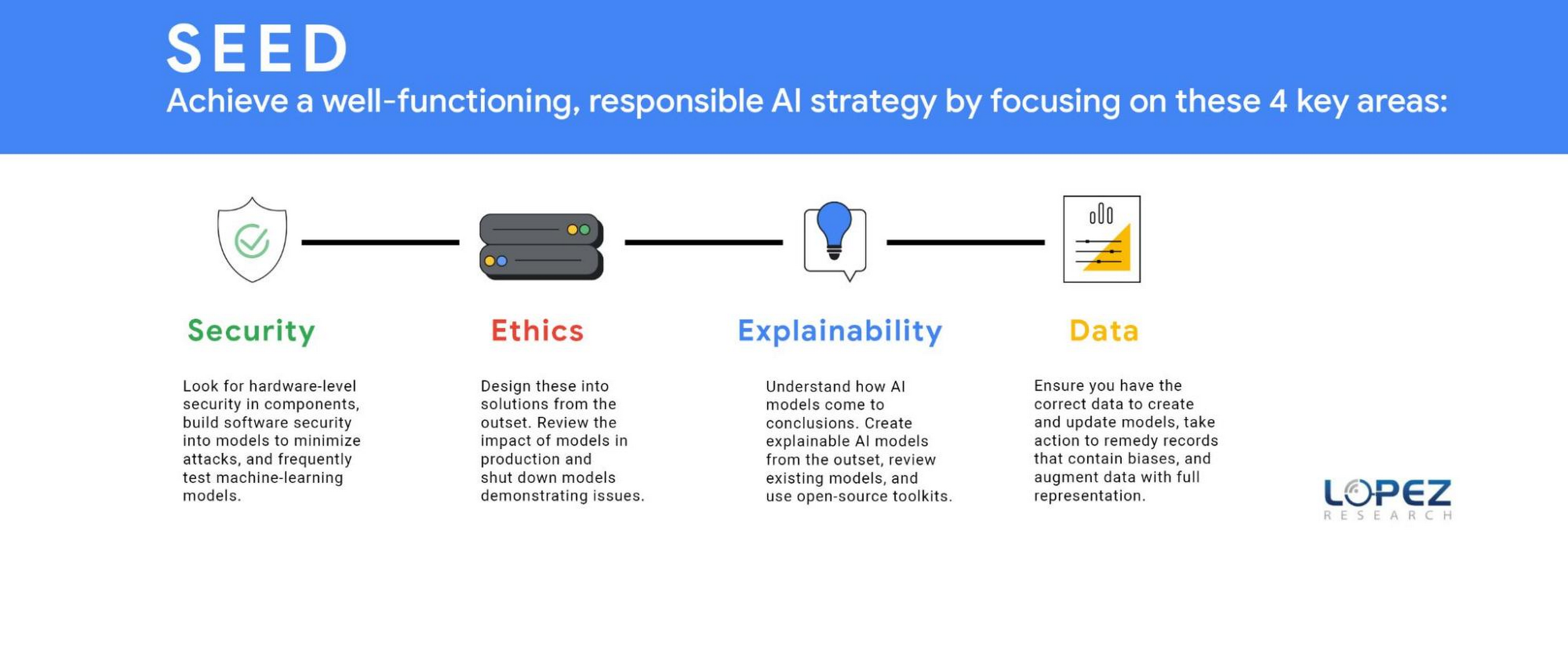
テクノロジーとビジネスのリーダーは、倫理的 AI の戦略をうまく機能させるために、次の 4 つの分野に力を入れる必要があります。Lopez Research は、これらのタスクグループの頭文字をとって SEED と名付けました。Security(セキュリティ)、Ethics(倫理)、Explainability(説明可能性)、そして Data(データ)です。これらのテーマはそれぞれが 1 つの記事になるほどのものですが、この投稿ではいくつかの重要な要素を定義します。
セキュリティ(SECURITY)
一見してわからないかもしれませんが、堅牢な AI 戦略には埋め込み型のセキュリティ戦略が必要です。企業は、GPU や CPU などのコンポーネントにも、ハードウェア レベルのセキュリティを求めるべきです。IT リーダーは、モデルにソフトウェア セキュリティを構築し、ポイズニング、回避、ディープフェイク、バックドア、モデル抽出といった攻撃を最小限に抑える必要があります。敵対的なデータ ポイズニングは、モデルの正確性を損なうよう設計された不正確なデータを悪意を持って導入し、機械学習モデルを攻撃します。もう一つのセキュリティ脅威はモデル抽出で、モデル クローニングとも呼ばれます。これは、ハッカーがブラック ボックスの機械学習モデルを再構築したり、トレーニング データを抽出する方法を見つけたりする攻撃です。セキュリティ攻撃に対する第一の防御ラインは、セキュリティを最初の段階から設計することですが、次善の策は、モデルが計画通りに動作しているかどうかを頻繁にテストすることです。ビジネス リーダー、データ サイエンス エキスパート、そして IT リーダーは、協力して定期的に AI モデルの状況をレビューしていく必要があります。
倫理(ETHICS)
組織は、ソリューションの初期段階で倫理を設計して組み込む必要があることを理解しなければなりません。倫理のプロセスは、ビジネスが作り上げるポジティブおよびネガティブな潜在的効果を定義するところから始まります。チームが害を及ぼしうる影響を評価したら、つまりテクノロジーと相互接続するシステム、信念、階層、ダイナミクスを見つけたら、こうした影響を排除または最小化する必要があります。また、本番環境のモデルの影響を確認し、問題のあるモデルをシャットダウンすることも非常に重要です。例として、Microsoft がデプロイした Tay Chatbot の公開ベータ版が、ネガティブなバイアスを伝播したため、すぐに廃止されたことなどが挙げられます。
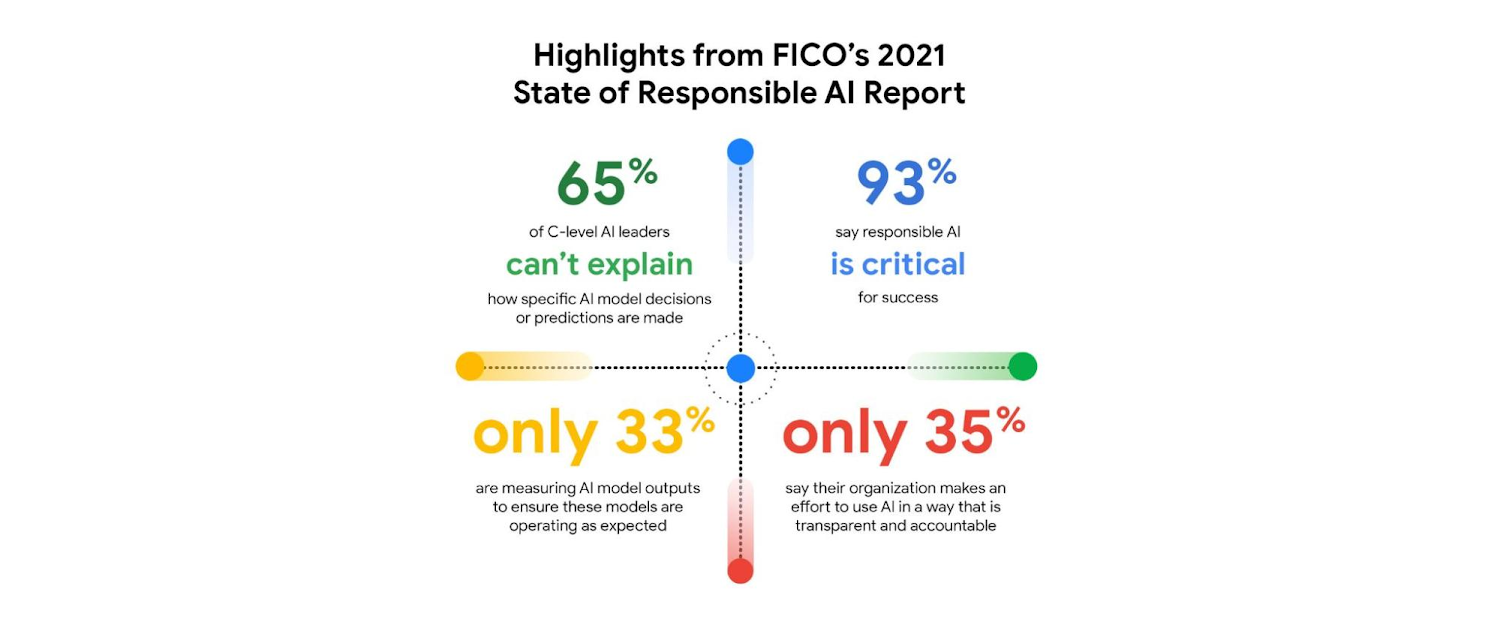
多くの組織は、まだこうした行動を起こしていません。FICO の調査によると、93% の企業が、責任を持つ AI は成功に欠かせないと答えたのに対し、こうしたモデルが期待通りに運用されているかを確認するために AI モデルの効果を測定している企業は、そのうちのわずか 33% でした(モデルドリフトの測定)。Pew Research による別の調査では、68% が、2030 年までに、公共の利益のための倫理原則がほとんどの AI システムに採用されることはないと考えていることが明らかになりました。
組織が倫理的 AI のフレームワークを採用するか否かにかかわらず、規制がこの流れを変える可能性があります。欧州委員会が提案した AI の法的枠組みなど、AI におけるデータの倫理的利用を規定する法律は、早ければ 2022 年には確定する見込みです。当初から AI の倫理的な使用を念頭に置いている組織は、顧客のプライバシーに関する懸念や規制の遵守に対処するうえで有利になります。
説明可能性(EXPLAINABILITY)
モデルが洗練されていくにつれて、そのモデルがどのようにしてその判断を下したのかを説明するのも難しくなります。FICO の責任ある AI レポートによると、回答者のうち 65% が、AI モデルの判断や予測がどのように行われているかを説明できず、自身の組織が透明性と説明責任のある方法で AI を使用できるよう努力していると回答したのは、わずか 35% でした。 しかし、例えばローン審査の拒絶、特定の戦略の実装、採用時における候補者の選考基準のように、AI モデルが下した判断の理由を知ることは非常に重要です。最初から説明可能な AI モデルを作成できれば一番いいのですが、現在のモデルの多くはこの機能を備えていません。すべての組織は、既存のモデルを見直し、機械学習モデルの解釈可能性と説明可能性をサポートする Github.com に掲載されているオープンソース ツールキットを使用する必要があります。
説明可能性は、万能ではないということを心に留めておいてください。ステークホルダーによって必要とされる情報の種類は異なります。これまでの説明可能性の多くは、「ブラック ボックスを開ける」ことに焦点が当てられており、データ サイエンティストにしか役に立たない情報と思われていました。もちろんそれも重要なのですが、AI がワークフローに組み込まれているビジネスラインのユーザーや、AI の判断の理由を知りたいエンドユーザー、データ サイエンスのバックグラウンドを持たない意思決定者などの助けにはなりません。
データ(DATA)
倫理において同じように重要なのはデータです。倫理は、モデルを作成、更新するための正しいデータを持つことから始まります。主な問題として、代表的なデータ、既存のデータにある固有バイアス、不正確なデータの 3 つが挙げられます。多くの企業がモデルを作成する際に見落としがちな重要な問題として、現在のデータセットが市場の状況を忠実に表しているとは限らないということです。最近の Capgemini Research Institute のレポートによると、経営幹部の 65% が、こういったシステムで「差別的なバイアスの問題を認識していた」と答えました。
気づきは最初のステップですが、組織はこの問題を解決するためにアクションを起こさなければなりません。過去のデータは、モデル作成における現在のニーズにはそぐわないかもしれません。さらに、過去の記録は、特定のグループへのバイアスを含んでいるおそれもあります。例えば、過去の犯罪データの記録では、人種や民族ごとの収監状況に不均衡が見られ、モデルにバイアスがかかっていると考えられます。また、法律や社会的規範も変化していきます。過去には特定のグループが性的嗜好で起訴されたこともありましたが、この情報は現在、不正確なモデルを作成してしまいかねません。
また、マーケティングで一般的に行われているユーザー層データの使用も、モデルバイアスにつながる可能性があることに企業は気づき始めています。例えば、主に現金を使用して取引を行う人や、ある郵便番号の地域に住んでいる人は、銀行の信用度を判定するモデルでは不利な立場にありました。こうした問題を最小限に抑えるため、企業は民族、性別、年齢、行動、経済的プロファイルなどの分野において完全な表現でデータを補強する必要があります。
継続的なフィードバック ループで AI モデルを設計
さらに顕著で厄介なのが、データの正確性という問題です。よく言うように、「ゴミを入れたら、ゴミが出てくる」のです。AI モデルのライフサイクルの中で、最も評価されていないものの、間違いなく一番重要な要素は、モデルが常に正確なデータを持っていることです。データ ハイジーンが悪かったり、セキュリティ上の理由でデータが改ざんされたりすることによる不正確なデータは、モデルの失敗の原因となります。正しいデータを確保するために、組織は時間とリソースを投資する必要があります。データ プライバシーも取り組むべき重要な要素ですが、データ プライバシー、主権、セキュリティのコンセプトについては、非常に重要なので改めて別の記事で紹介します。
全体的に見て、データは豊富にあるものの、将来的にモデル化したいものを表していない可能性が高いことは明らかです。成功する AI 戦略とは、倫理的な AI 戦略と言えます。組織はモデルの作成において、正確なデータを幅広く表現することに配慮し、モデルが安全で期待通りに動作することをテストする必要があります。
組織は、継続的なフィードバック ループで AI モデルのライフサイクルを定義することにより、より優れたインテリジェンスの恩恵を受けることができます。そのためには、お客様とより強固で長期的な信頼関係を築き、新しい法律や規制に適切に対応することが肝要です。
- Lopez Research 設立者/アナリスト/著者 Maribel Lopez 氏

{kind=link}
{kind=link}