3 か月で 30 倍の需要増: COVID-19 期間中の Google Meet のスケーリングはどのように成し遂げられたか

Google Cloud Japan Team
※この投稿は米国時間 2020 年 8 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
COVID-19(新型コロナウイルス感染症)の蔓延で、私たちは物理的接触を回避した生活を強いられています。そんな中、多くの人が社会、教育、職場のつながりを保つためにオンライン ビデオ会議に目を向け始めました。次のグラフに示すように、この変化によって Google Meet のユーザー数は大幅に増加しています。
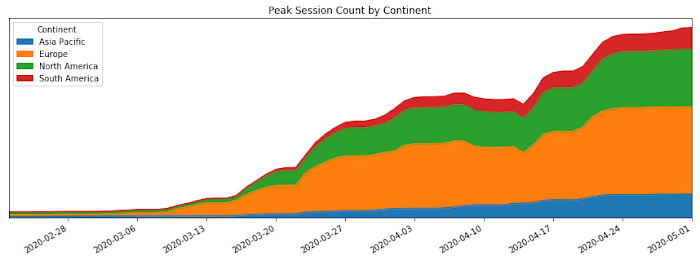
この投稿では、COVID-19 による Meet 利用者数の 30 倍の増加に先駆けて Google がどのようにして Meet のサービス キャパシティを確保し、数多くのサイト信頼性エンジニアリング(SRE)のベスト プラクティスを活用してその成長を技術的かつ運用的に持続可能にしたかについて紹介します。
初期アラート
COVID-19 が世界中に広がるにつれて、人々はこの現実に日常生活のリズムを適応させ始めました。ウイルスが人々の仕事、学習、友人や家族との交流に及ぼす影響はますます強まり、より多くの人が連絡を取り合うために Google Meet のようなサービスを求めるようになりました。2 月 17 日、Meet SRE チームに地域的なキャパシティの問題に関するページが届き始めました。
これらのページは前兆的なもので、「タスクの失敗が多すぎる」、「大量の負荷が遮断されている」というようなブラックボックス アラートでした。Google のユーザー向けサービスには冗長性が組み込まれているため、これらのアラートがユーザーに直接的な問題をもたらすことはありませんでした。しかしまもなく、アジアでの Meet の利用が急激に増加していることが明らかになりました。
SRE チームはこの急増に対処するため、キャパシティ プランニング チームと協力して追加のリソースを探し始めましたが、今後この感染症がアジアを越えて広がる事態に備えて早急にプランニングを開始しなければならないことが明白になりました。
予想どおり、その後まもなくイタリアで COVID-19 のロックダウンが実施され、イタリアでの Meet の利用が増加し始めました。
従来とは異なるインシデント
この時点で、私たちは対応策を練り始めました。いつものように、SRE チームはまずインシデントを宣言し、この世界的なキャパシティ リスクに対するインシデント対応に取り掛かりました。
ただし、ここで注目すべきことは、私たちは実証済みのインシデント管理フレームワークを使用してこの難題に着手したものの、その時点ではサービス停止の真っただ中にはなく、今にもサービスが停止しそうな状況にもなかったということです。ユーザーへの直接的な影響は見られませんでした。COVID-19 の社会的な影響の大部分はわかっておらず、予測するのも困難でした。私たちの使命は抽象的なものでした。つまり、大量の新規ユーザーが押し寄せて突然クリティカルな存在になったサービスの停止を防ぎながら、この成長の出所や成長がいつ安定するかもわからないままシステムをスケールする必要がありました。
それに加えて、チーム全体が(Google の他の部署と同様に)COVID-19 による無期限の在宅勤務に移行しようとしていました。Google のワークフローやツールの大部分はすでに社外からアクセス可能になってはいましたが、このように長期間続くインシデントにネットワーク上で対応した経験はなく、問題は山積していました。
全員が同じ部屋に集まることができないため、コミュニケーション チャネルを積極的に駆使して全員が目標達成に必要な情報にアクセスできるようにすることが重要となりました。メンバーの多くには、新しい環境に適応しながら友人や家族の世話をするといった仕事以外の課題もありました。これらの要因によってインシデント対応に余計な課題が生まれましたが、代替要員の割り当てや増員、先を見越したオーナーシップとコミュニケーション チャネルのやりくりなどの戦法でこの試練を乗り越えました。
それでもなお、インシデント管理アプローチは断念しませんでした。グローバルな対応を開始する際、24 時間休みなくサポートできるように、北米とヨーロッパにインシデント コマンダー、コミュニケーション リード、オペレーション リードを配置しました。
総合的なインシデント コマンダーの一人として、私の役割はステートフルな情報ルーターのようなものでした(意見、影響力、意思決定力を持ってはいましたが)。私は、なかなか解消されない戦術的問題、誰が何の仕事をしているか、インシデント対応に影響を与える状況(政府の COVID-19 への対応など)に関するステータス情報を収集し、適任と思われる人に仕事を割り振りました。不確実な領域(問題の定義: 「南米で 50% の CPU 使用率で運用するのは問題か?」と解空間: 「起動プロセスを高速化するにはどうすればよいか?」の両面で不確実な領域)を見つけ出して詳細に調べることにより、インシデント対応活動全体を調整し、必要なすべてのタスクに明確なオーナーを定めました。
インシデント対応を開始してまもなく、私たちの使命の範囲はきわめて広く、この仕事は当分続くだろうと悟りました。各貢献者の業務範囲を扱いやすくするため、インシデント対応活動をいくつかの半ば独立したワークストリームにまとめました。業務範囲が重複した場合は、ワークストリーム間のインターフェースを明確に定義しました。
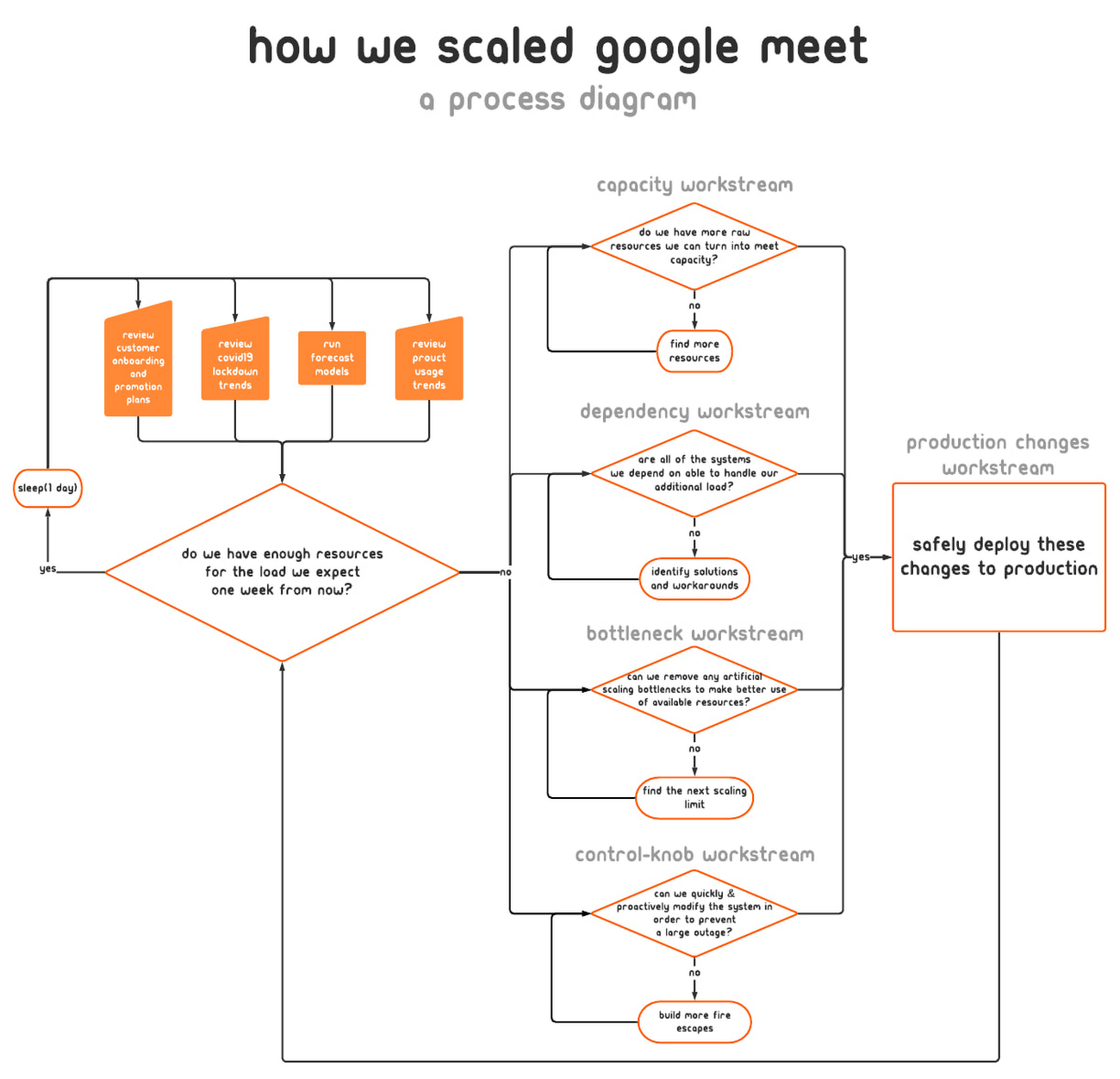
上の図に示すように、以下のワークストリームを設定しました。
- キャパシティ: リソースを探し、サービスの量をどこでどのくらい増やせるかを決定する責任を負いました。
- 依存関係: Meet のインフラストラクチャ(Google のアカウント認証および認可システムなど)を所有するチームと協力し、それらのシステムも Meet の利用増加に伴ってスケールできるように十分なリソースを確保しました。
- ボトルネック: Google システム上の関連するスケーリング制限の特定とその除去を担当しました。
- コントロール ノブ: キャパシティ限界が迫ったとき、または限界を超えたときに備えて新しい包括的な緩和措置をシステムに組み込みました。
- 本番環境変更: 見つかったすべてのキャパシティを安全に投入し、チューニングが新たに最適化されたサーバーを再配備して、すぐに使用できる追加のコントロール ノブを備えた新しいリリースを導入しました。
インシデント対応者として、私たちは現在のオペレーション構造が引き続き意味をなしているかどうかを継続的に再評価しました。目標は、効果的に運用するためにちょうど必要なだけの構造を持ち、必要以上に構造が多くならないようにすることでした。構造が少なすぎると、人は正確な情報なしで決断を下しますが、構造が多すぎると、すべての時間を計画会議に費やします。
これは短距離走ではなく、マラソンでした。期間中ずっと、追加のヘルプが必要な人、休憩を取らなければならない人がいないか定期的にチェックしました。これは、このような長期のインシデントで燃え尽きを防ぐために不可欠でした。
疲労困憊しないため、インシデント対応の役割を担った各人員は別の人を代替要員として指名しました。代替要員はその役割の主担当者と同じ会議に出席し、関連するすべてのドキュメント、メーリング リスト、チャットルームにアクセスできました。また、十分な情報が与えられないまま主担当者を引き継がなければならなかった場合は、現在答えを探している問題について質問しました。この方法は、担当者が病気になったときや休憩が必要なときに役立ちました。代替要員がすでに必要な情報を持っており、すぐに戦力になったためです。
キャパシティ ランウェイの構築
インシデント対応チームは、このインシデントを解決するために必要な情報と作業のフローをどのように連携させるのがベストであるかわかっていましたが、関係者のほとんどは、実際には本番環境でのリスクに対処していました。
第一の技術的要件は単純で、ユーザーの需要を先読みして、各地域で使用可能な Meet サービス キャパシティの量を維持することでした。Google は世界中で 20 を超えるデータセンターを運営しており、その堅牢なインフラストラクチャを活用して、すでに使用可能な生のリソースをすぐさま利用しました。これには、提供可能な Meet のサービス キャパシティをおよそ 2 倍に高めるほどの量がありました。
これまでは、過去の傾向を頼りにして、プロビジョニングするキャパシティをどの程度増強するかを決定していました。しかし、もはや過去のデータからの推定は当てにできないため、予測に基づくキャパシティのプロビジョニングを開始しました。これらのモデルを、本番環境変更チームが本番環境に適用する数値に変えるため、利用モデルから CPU と RAM の必要な追加量を導き出す必要があり、キャパシティ ワークストリームがこれを担当しました。この変換モデルを構築したおかげで、その後ツールや自動化にこのモデルを理解するよう学習させることにより、本番環境で空いているキャパシティを取得するプロセスを高速化できました。
まもなく、単にフットプリント サイズを 2 倍にするだけでは十分でないことが明らかになり、以前は考えられなかった 50 倍の成長予測に立ち向かい始めました。
リソースのニーズを減らす
キャパシティのスケールアップに加えて、サービス スタックにおける非効率性の特定とその除去にも取り組みました。この作業の多くは、バイナリフラグとリソースの割り振りの調整、コードの書き換えによる実行費用の低減といったいくつかのカテゴリに分類できました。
サーバー インスタンスのリソース効率の向上には多次元的なアプローチが必要でした。その目標は、「ユーザー エクスペリエンスまたはシステムの信頼性を損なうことなく、できるだけ安いリソース費用でできるだけ多くのリクエストを処理する」とされました。
調査的な側面から、次のような質問を自らに問いかけました。
- サーバーの数を減らし、個々のサーバーのリソース予約を増やすことで、計算オーバーヘッドを削減できないか?
- 必要以上に多くの RAM または CPU を予約していないか?これらのリソースを他の用途にうまく利用できないか?
- すべての地域で動画ストリームを提供するために、ネットワークのエッジで十分な下り(外向き)帯域幅はあったか?
- 使用中のバックエンド サーバーの数をサブセット化することで、特定のサーバー インスタンスに必要なメモリと CPU の量を減らせないか?
私たちは常に新しいサーバーの形や構成の適格性を確認し続けてきましたが、この時点でそれらを再評価するのには十分価値がありました。Meet の利用が増加するにつれて、会議の時間、参加者の人数、参加者による音声時間の共有方法といった利用特性も変化しました。
Meet サービスが要求する生のリソース量がますます増加する中、CPU サイクルのかなりのパーセンテージがリクエストの処理ではなくプロセス オーバーヘッド(モニタリング システムやロードバランサへの接続のキープアライブなど)に費やされていることに気づきました。
スループット、つまり「1 秒間に 1 つの CPU で処理されるリクエストの数」を向上させるため、CPU と RAM の予約に関してプロセスのリソース指定を増やしました。これは「ファットタスク(太らせたタスク)の実行」と呼ばれることがあります。

上記の例のデータを見ると、2 つのことに気がつきます。1 つは、計算オーバーヘッド(赤)はどのインスタンス仕様でも同じであること、もう 1 つは、インスタンスの全体的な CPU 予約が多いほどリクエストのスループット(黄色)が高くなることです。割り当てられた CPU の総量が同じ場合は、4 倍の CPU 予約を持つインスタンスが 1 つある方が、ベースラインのインスタンスが 4 つあるよりも 1.8 倍多くのリクエストを処理できます。このようになる理由は、計算オーバーヘッド(デバッグ ログエントリの永続化、ネットワーク接続チャネルのキープアライブのチェック、クラスの初期化など)は、タスクが処理する受信リクエストの数に対して線形に拡大しないためです。
そのため、スケーリングの限界に達するまで、サービス処理タスクの予約を 2 倍に増やすとともに、フリート全体のタスクの数を半分に減らし続けました。
もちろん、こうした変更のそれぞれをテストして適格性を評価する必要はありました。カナリア環境を使用して、これらの変更が期待どおりに動作し、これまで隠れていた制限が顕在化されない、またはそのような制限にぶつからないことを確認しました。サーバーの新しいビルドの適格性評価を行う場合と同様に、機能または性能の退行がないこと、変更の望ましい効果が本番環境で実際に達成されていることについても確かめました。
また、コードベースの機能改善も行いました。たとえば、メモリ内分散キャッシュのコードを書き換え、タスク インスタンス間のエントリのシャーディングがより柔軟になるように改良しました。その結果、クラスタ内のサーバー インスタンスの数を増やしたときに、単一リージョンにより多くのエントリを保存できました。
非常階段の作成
利用増加予測の信頼性は向上していましたが、まだ 100% 信頼できるものではありませんでした。ある地域のサービス キャパシティが枯渇したらどうなるでしょうか。あるいは、特定のネットワーク リンクが飽和してしまったら?コントロール ノブ ワークストリームの目標は、この種の問題に対して、理想的とは言わないまでも、満足の行く答えを提供することでした。コンソールに突如として現れるブラックスワンに対して許容可能な計画を立てておく必要がありました。
あるグループが、できるだけ多くの本番環境コントロールと非常階段を特定し、それを構築する作業に取り掛かりました。私たちは皆、これらを使わずに済むことを願いました。たとえば、誰かが Meet 会議に参加したときにデフォルトの動画解像度を高画質から標準画質に速やかにダウングレードするという緊急措置がありました。この切り替えにより、サービスを大幅に低下させずに、他のワークストリーム(プロビジョニングと効率改善)を使用して軌道修正する時間を稼ぐことができます。しかしそれでも、ユーザー自身が必要に応じて画質を高画質にアップグレードすることは可能でした。
このような構築、テスト済みですぐに使えるインストルメントされた対策を幅広く用意しておくことで、最悪事態の予測が正確でなかった場合の補助的なランウェイが確保され、いくらかの安心感も得られました。
オペレーションの持続可能性
この組織化された対応には、多数の Google 社員がさまざまな役割で関与しました。つまり、インシデント全体を通して進歩し続けるには、本格的な連携と意図的なコミュニケーションも必要でした。
チューリッヒ、ストックホルム、ワシントン州カークランド、カリフォルニア州サニーベールで働く Google 社員を考慮して、毎日の引き継ぎミーティングは 2 つのタイムゾーンの間で行われました。コミュニケーション リードがプロダクト チーム、エグゼクティブ、インフラストラクチャ チーム、カスタマー サポート部門の多くの関係者に定期的に最新情報を伝えたため、各チームは最新のステータス情報に従って自ら判断を下すことができました。ワークストリーム リードは、Google ドキュメントを使用して、リスク、連絡先、現在行われている緩和努力、会議メモの最新情報が記載されたステータス ドキュメントを共有しました。
この方法は最初のうちはうまくいきましたが、すぐに負担になりました。調整に費やす時間を大幅に削減するために計画サイクルを数日から数週間に延ばし、実際の危機緩和に費やす時間を増やす必要がありました。
ここでの最初の戦術は、より信頼性の高い優れた予測モデルを構築することでした。予測性が向上すると、目標とするサービス キャパシティの増加量を明日 1 日だけでなく 1 週間安定させることができます。
また、追加のサービス キャパシティを投入するために必要なトイルの削減にも取り組みました。私たちが日々運用しているシステムと同じように、プロセスも自動化する必要がありました。
この時点で最も労働集約的であった業務は、Meet のサービス スタックのスケーリングでした。これは、最新の予測とリソースの数を把握する必要のある人員の数と、特定のオペレーションに関与するツール(時には信頼性に欠けるツール)の数によります。

上記のライフサイクルの図に示すように、これらのタスクを自動化するコツは、漸進的に改善することでした。まずタスクを文書化してから、それらの要素の自動化に取り掛かりました。最終的に、一切手動で介入せずにソフトウェアだけでタスクを最初から最後まで完了することを理想としました。
これを達成するために、Meet 組織の内外から自動化のエキスパートを多数集め、この問題に専念させました。その作業項目の一部を以下に示します。
- Google の本番環境サービスのできるだけ多くを、チェックインされた信頼できる構成ファイルの変更に対応できるようにする
- 一般的なツールを強化して、Meet のより独自性の強いシステム要件(高帯域幅かつ低レイテンシのネットワーキング要件など)をサポートする
- システムのスケールアップに伴って信頼性が低下した退行チェックを調整する
これらのタスクを自動化およびコード化することで、新規クラスタでの Meet の起動や、パフォーマンスが改善された新しいバイナリ バージョンの導入に必要な手作業が大幅に減少しました。このスケーリング インシデントが終了するまでに、ゾーンごと、サービスごとのジョブ キャパシティ フットプリントの完全な自動化が完了し、手作業で構築された数百ものコマンドライン ツールの呼び出しが不要になりました。これにより、かなりの数のエンジニアの時間とエネルギーが解放され、より難しい(しかし、等しく重要な)問題に取り組むことができました。
オペレーション スケーリングのこの時点で、拠点をまたいだハンドオフはメールによるオフライン方式に移行され、出席する会議の数がさらに減少しました。これで戦略が固定され、ランウェイも長くなったので、より純粋に戦術的な実施モードに入りました。
その後まもなく、インシデント構造は徐々に解除され、長期プロジェクトを終えたときのように残務に比重が移り始めました。
結果
インシデント対応期間の終了時までに、Meet での会議の参加者は 1 日あたり 1 億人を超えました。大きな混乱はなかったものの、そこに至る道筋は決して平坦なものではありませんでした。COVID-19 の前の障害およびインシデント対応テストの際に Meet チームが検討したシナリオには、これほどまでの長さまたは規模のキャパシティ要件の増加は含まれていませんでした。結果的に、対応の多くはその場で考案されました。
平常時の標準的なオペレーションとは異なる方法でリスクのバランスをとる必要があったため、その途中には軽微な問題が数多くありました。たとえば、新しいサーバーコードを本番環境にデプロイする際、カナリア ベーキング時間は通常より短縮されました。これは、地域のキャパシティが枯渇する期限を先延ばしにするパフォーマンスの修正が含まれていたためです。
この 2 か月に及ぶ奮闘の日々の中で私たちが磨き上げた最も重要なスキルのひとつは、リスクと効果を柔軟に分類整理して定量化し、適格性を評価する能力でした。毎日手元には、COVID-19 のロックダウン、新しいお客様の Meet の使用開始計画、提供可能な本番環境のキャパシティに関する新しい情報が届きました。ときには、この新しい情報のせいで、前日に開始した作業がすぐに陳腐化することもありました。
時間が何よりも大切だったので、それぞれの作業項目を同じ優先度または緊急性で扱う余裕はなく、独自の予測モデルをヘッジしない余裕もありませんでした。どの時点でも完璧な情報を待つという選択肢はなかったため、私たちができる最善のことは、ランウェイをできる限り構築し、手持ちのデータから計算された判断を迅速に下すことでした。
この取り組みは、多くのチームから経験豊富で協力的かつ多才な人々が結集し、SRE、デベロッパー、プロダクト マネージャー、プログラム マネージャー、ネットワーク エンジニア、カスタマー サポートなどのさまざまな職種が協力して事に当たらなければ、成し遂げられませんでした。
この困難な時期を乗り切ったことは、結果的に、Google アカウントを持つすべての人に Meet を無料で利用可能にするという次の一手につながりました。通常であれば、このプロダクトを消費者に開放することは自ずと劇的なスケーリング イベントとなるはずでしたが、集中的なインシデント対応を終えた今、スケーリングはすでに完了しており、Google は次の課題に向けて歩き出しています。
-スタッフサイト信頼性エンジニア Samantha Schaevitz


