順調なスタート: Twitter に Google Cloud BigQuery を導入するためのリソース階層
Google Cloud Japan Team
※この投稿は米国時間 2022 年 6 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: BigQuery へのオンプレミス データ ウェアハウジングの移行の一環として、Twitter と Google Cloud の両チームで Google Cloud リソース階層アーキテクチャを構築し、Hadoop 分散ファイル システム(HDFS)と BigQuery の 1 対 1 のマッピングを実現しました。スケーラビリティとセキュリティを重視して設計されたこのアーキテクチャは、HDFS / Google Cloud Storage(GCS)データ レイアウト構造とアクセス制御をミラーリングすることで BigQuery のスムーズな導入を実現するよう設定されており、スケーラブルなコンピューティングの導入が可能です。このブログ記事作成にご協力いただいた Vrushali Channapattan 氏(Twitter の元チームメイト)および Google の Vrishali Shah に著者一同よりお礼申し上げます。
Twitter 全体でデータ ウェアハウジングの利用を拡大
Twitter のリソースを階層化して BigQuery をスムーズに導入した方法を説明する前に、まずは Twitter が Google Cloud と BigQuery を選んだ理由と、移行前のデータ ウェアハウスの設定方法について説明させていただいたほうが理解しやすいと思います。2018 年に Twitter がデータ ウェアハウジングに使用していたインフラストラクチャには、プログラミングのバックグラウンドを必要とするツールが含まれており、大規模なパフォーマンスの問題を抱えていました。データはサイロ化されており、アクセス方法にも一貫性がありませんでした。
社員が自らデータを分析および可視化でき、同時に機械学習をテストする開発速度を向上させるために、Twitter は 2019 年にデータの処理と分析を民主化するミッションに着手しました。データ分析情報を改善し、生産性を向上させるために、スケーラブルかつクラウド ファーストなデータ ウェアハウスへの移行を決断したのです。一人ひとりの技術スキルに関係なく、すべての社員がデータにアクセスして分析でき、ビジネス インテリジェンスや分析情報を活用できるよう、移行先のデータ ウェアハウスはシンプルかつパワフルである必要がありました。そこで Twitter のデータ プラットフォーム チームは、使いやすさ、パフォーマンス、データ ガバナンス、システム運用性の観点から BigQuery を選択しました。2019 年にオンプレミスのデータ ウェアハウジング インフラストラクチャから BigQuery への移行を開始し、2021 年 4 月に Twitter での BigQuery 一般提供をスタートしました。
現在では、何万もの BigQuery テーブルに格納されたおよそ 1 エクサバイトのデータに対して、Twitter 社員により 1 か月あたり数百万件のクエリが実行されています。さらに、Twitter の内部データ処理ジョブにより、エクサバイト級の非圧縮データが処理されています。
スムーズに移行し、完了後にこうしたスケーリングを有効にするために、Twitter のデータ プラットフォーム チームと Google Cloud チームはいくつかの要件を提示しました。そのなかで最も重要な要件が、オンプレミスのリソース階層を BigQuery に 1 対 1 でマッピングすることでした。その他にも、BigQuery の設定が Twitter の Identity and Access Management(IAM)ストラクチャをミラーリングして、Twitter 社員が分析する顧客データを保護するという要件もありました。こうした要件を念頭に置いて、両チームは作業を開始しました。
1 対 1 のマッピングに向けたストレージ プロジェクト階層の構築
Twitter の BigQuery 構造には、ストレージとコンピューティングという 2 つの異なるタイプのプロジェクトがあります。ストレージ プロジェクトは、データのみを保存するように設計されています。一方、ストレージ プロジェクトに保存されているデータを操作するデータ処理ジョブは、コンピューティング プロジェクト内で実行する必要があります。このセクションでは、ストレージ プロジェクト向けのリソース階層について説明します。
次の図は、オンプレミスの HDFS データセットを BigQuery テーブルまたはビューに 1 対 1 でマッピングするための BigQuery リソース階層を示したものです。このような階層があるおかげで、HDFS と GCS のデータを BigQuery にスムーズに移行でき、Twitter 社員は使い慣れた方法でデータにアクセスできます。
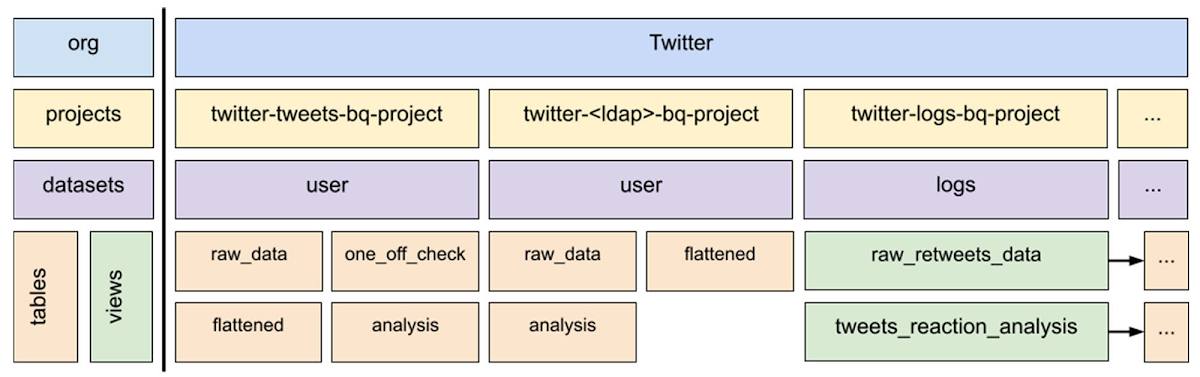
このアーキテクチャにより、ユーザーはデータセットの場所を簡単に特定してアクセスでき、オンプレミスの場合と同様に適切な権限を持つことができます。階層内のコンポーネントを詳しく見てから、それぞれがどのように連携しているのか説明していきます。
マッピングを理解するためのストレージ プロジェクト階層のドリルダウン
Twitter の BigQuery 内のプロジェクト命名法は、2 つのデータセット タイプを明確に識別することで、それぞれのデータセットを 1 対 1 でマッピングできるようになっています。この 2 つのタイプには、「ユーザー」と「ログ」があります。
ユーザータイプには、ユーザーが作成したデータセットが含まれており、ユーザーはさらに人間と人間以外(サービス アカウント)に分けられています。
ログ データセットとは、クライアント アプリケーション、トラフィック フロントエンド、その他の Twitter アプリケーションによって生成されるさまざまな種類のイベントログです。
上の図では、1 つ目のユーザー プロジェクト twitter-tweets-bq-project は人間以外のユーザーのデータセットであり、「tweets」が識別子です。2 つ目のプロジェクト twitter-<ldap>-bq-project により、データを生成する Twitter の社員が特定されます。3 つ目のプロジェクト twitter-logs-bq-project には、ログ ストレージ プロジェクトに保管されているログ データセットを指すビューが含まれています(この図には示されていません)。ビューをまとめたこの一覧表により、イベントログを簡単に見つけることができます。
マッピングは実際のデータセットでどのように機能するのでしょうか?たとえば次のようになります。tweets.raw_data と仮に名付けたオンプレミスのデータセットを twitter-tweets-bq-project ストレージ プロジェクトにマッピングします。ここでは、「tweets」が人間以外のユーザー(LDAP サービス アカウント)とします。データセットは常にユーザーであり、自動的に生成されます。Twitter のオンプレミス HDFS データセットが BigQuery データセットの同じ名前のテーブルに読み込まれます。こうして、twitter-tweets-bq-project.user.raw_data が BigQuery で利用できるようになります。これは、データセットの所有者が人間であろうと人間以外であろうと同様です。ログの場合、関連するログ データセットは名前に基づいて同じストレージ プロジェクトに配置されます。その後、twitter-logs-bq-project に自動的にビューが生成され、該当のログ データセットを簡単に見つけてアクセスできるようになります。
このマッピング フローは一度実行したら終わりというものではありません。プロジェクトとそれに対応するデータセットのライフサイクル(作成、変更、更新、削除)を継続的に管理する必要があります。そのため Twitter は、自動プロビジョニング用オープンソース システムである Terraform を含む一連のサービスを活用しています。
コンピューティング プロジェクトの自動プロビジョニングは、これらのプロジェクトを作成するプロセスとは異なります。
コンピューティング プロジェクト作成と ID 管理は裏方にお任せ
Twitter は、BigQuery のコンピューティング プロジェクトにセルフサービス型のアプローチを採用しています。内部システムを使用することで、ユーザーは UI から直接プロジェクトを作成できます。社員たちは最小限の労力でジョブを実行し、データにアクセスして分析し、ML モデルを作成できます。これが分析情報の迅速な取得と生産性の向上につながっていきます。ユーザーが内部 UI からプロジェクト名とプロジェクトの特徴を選択して送信をクリックすると、バックエンドでアクションがトリガーされます。
最初に、そのプロジェクトに対応するオンプレミスの LDAP グループと Google グループがシステムによって自動的に 1 つずつ作成され、相互更新でリンクされます。このリンクされたグループが自動的にプロジェクトの所有グループとなり、このプロジェクトにアクセスしたい人は誰でもそのグループからリクエストできます。Google Cloud 管理サービス システムにより、すべてがバインディングされ、プロジェクトがプロビジョニングされます。また、Google Cloud への API 呼び出しも行われ、Twitter のセキュリティ管理および基準に基づいてクラウド リソースが構成されます。
BigQuery コンピューティング プロジェクトの Identity and Access Management(IAM)は、認証(Authentication)、承認(Authorizaton)、監査(Auditing)の AAA 原則に従っています。Twitter 社員が BigQuery のデータにアクセスする場合、自身のユーザー アカウントを使用してログインできます。システムによりすべてのサービス アカウントに対するキーが自動的に定期発行され、対応するユーザーの認証に使用できます。
BigQuery と並行した Google Cloud データベースの活用
BigQuery を使用しているお客様の多くは、Cloud Bigtable などの Google Cloud データベースも活用して自社のデータセットを管理しており、Twitter もそうした企業のうちの 1 社です。私たちが Cloud Bigtable を選んだ決め手は、何十億ものイベントをリアルタイムで処理できる機能にありました。Bigtable を実装したことで、コストを削減でき、集計精度が向上し、低レイテンシで安定性の高いリアルタイム パイプラインを実現しています。さらに、Bigtable を実装してからというもの、複数のデータセンターで異なるリアルタイムのイベントを集約し続ける必要がなくなりました。将来的に、Bigtable データセットがリージョン エラーに対する復元力を持つようにすることを計画しています。Twitter による Bigtable 活用法の詳細はこちらをご覧ください。
移行プロセスで得た教訓を生かした今後の展望
Twitter の BigQuery への移行作業は、やりがいのある大掛かりな取り組みであり、Twitter と Google Cloud 両チームの知識を豊かにし能力を高めるものでした。Google Cloud と協力して問題なく移行を終え、Twitter はエンジニアリング チームの生産性を向上させることができました。今回の連携と Google Cloud のテクノロジーを基に、Twitter はデータからさらに多くを学び、より迅速に行動することで、日常的にサービスを利用する人々に関連性の高いコンテンツを提供できるようになります。Twitter は規模の拡大を続けるなかで、今後も Google Cloud と連携し、データと機械学習の分野で業界をリードするテクノロジー イノベーションを促進していきます。
今回の取り組みで、Google Cloud チーム側はプロジェクトのパラメータ、データベース サイズ、サポートに関するアイデアを異なる視点から検討できるようになりました。たとえば、同チームは VPC Service Control 境界内の GCP プロジェクトの上限を大幅に引き上げました。また、UI のユーザビリティとパフォーマンスも改善し、1 つのプロジェクト内で 1,000 個以上のデータセットにアクセスできるようにしました。BigQuery に対するこうした変更や、その他の Google Cloud プロジェクトやエンジニアリング チームとのコラボレーションにより、プロジェクト間でサービス アカウントをサポートできるようになったことで、Twitter は新プロジェクトに取り組む際に引き続き恩恵を受けられるでしょう。
Google Cloud との素晴らしいパートナーシップにより、何千人もの内部の月間アクティブ ユーザー(MAU)に BigQuery を使用できるようにすることで、Twitter はビッグデータ分析を民主化できました。さらに、Google Cloud 上でビッグデータ処理を高速化し、機械学習をテストすることで開発速度を向上させました。
- Twitter、スタッフ ソフトウェア エンジニア Gary Steelman 氏
- Twitter、シニア サイト信頼性エンジニア Saurabh Deochake 氏



