Dataproc 永続履歴サーバーのベスト プラクティス

Google Cloud Japan Team
※この投稿は米国時間 2022 年 12 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
Apache Hadoop と Spark を運用するときは、構成の調整、クラスタの計画、コンピューティングの適正化が重要となります。また、最適な利用率と性能を確保するために、徹底したベンチマークが必要です。Dataproc では、準長時間実行クラスタまたはエフェメラル Cloud Dataproc on Google Compute Engine(DPGCE)クラスタで、もしくは Dataproc Serverless Spark を使用して、Spark ジョブを実行できます。Dataproc Serverless for Spark は、エフェメラル クラスタでワークロードを実行します。エフェメラル クラスタでは、クラスタのライフサイクルがジョブと関連付けられています。クラスタが起動されたら、ジョブの実行に使用され、ジョブ完了後に破棄されます。エフェメラル クラスタは、単一のワークロードを実行するか、複数のワークロードを順番に実行するため、構成がより簡単です。Dataproc ワークフロー テンプレートを利用して、これをオーケストレートできます。エフェメラル クラスタは、ジョブの要件に合わせてサイズを変更できます。このジョブ限定クラスタモデルは、バッチ処理に適しています。エフェメラル クラスタを作成し、これを特定の Hive ワークロード、Apache Pig スクリプト、Presto クエリなどを実行して、ジョブが完了したらクラスタを削除するよう構成できます。
エフェメラル クラスタには、以下の魅力的な利点があります。
アイドル状態のクラスタとワーカーマシンにより発生する不要なストレージとサービス費用を削減できる。
各ジョブセットが、ジョブ限定のクラスタ仕様、イメージ バージョン、オペレーティング システムを使用して、ジョブ限定のエフェメラル クラスタ上で動作する。
各ジョブが専用のクラスタを使用するため、あるジョブのパフォーマンスが他のジョブに影響を与えることがない。
永続履歴サーバー(PHS)
エフェメラル クラスタや Dataproc Serverless for Spark の課題は、ジョブ終了後にクラスタマシンが削除されたときにアプリケーション ログが失われてしまうことです。永続履歴サーバー(PHS)は、複数のエフェメラル クラスタまたはサーバーレス Spark で実行されたジョブについて、完了した Hadoop と Spark アプリケーションの詳細にアクセスできます。実行中のアプリケーションと完了したアプリケーションを一覧表示できます。PHS は、完了した全アプリケーションの履歴(イベントログ)とそのランタイム情報を GCS バケットに保持するため、これを使用して後で指標を確認したりアプリケーションをモニタリングしたりできます。PHS はスタンドアロン クラスタにすぎません。GCS から Spark イベントを読み込んでから、アプリケーションの詳細、スケジューラのステージ、タスクレベルの詳細、環境と実行者の情報を解析して Spark UI に表示します。これらの指標は、アプリケーションのパフォーマンス向上に役立ちます。アプリケーションのイベントログとエフェメラル クラスタの YARN コンテナログの両方が、GCS バケットに収集されます。これらのログファイルは、Google Cloud テクニカル サポートにトラブルシューティングや調査を依頼するうえで重要です。PHS が設定されていない場合、ワークロードを再実行する必要がありますが、これによりサポートのサイクルタイムが増加します。PHS を設定したら、ログを直接テクニカル サポートに提供できます。
下の図は、エフェメラル クラスタから PHS サーバーに記録されるイベントの流れを表しています。
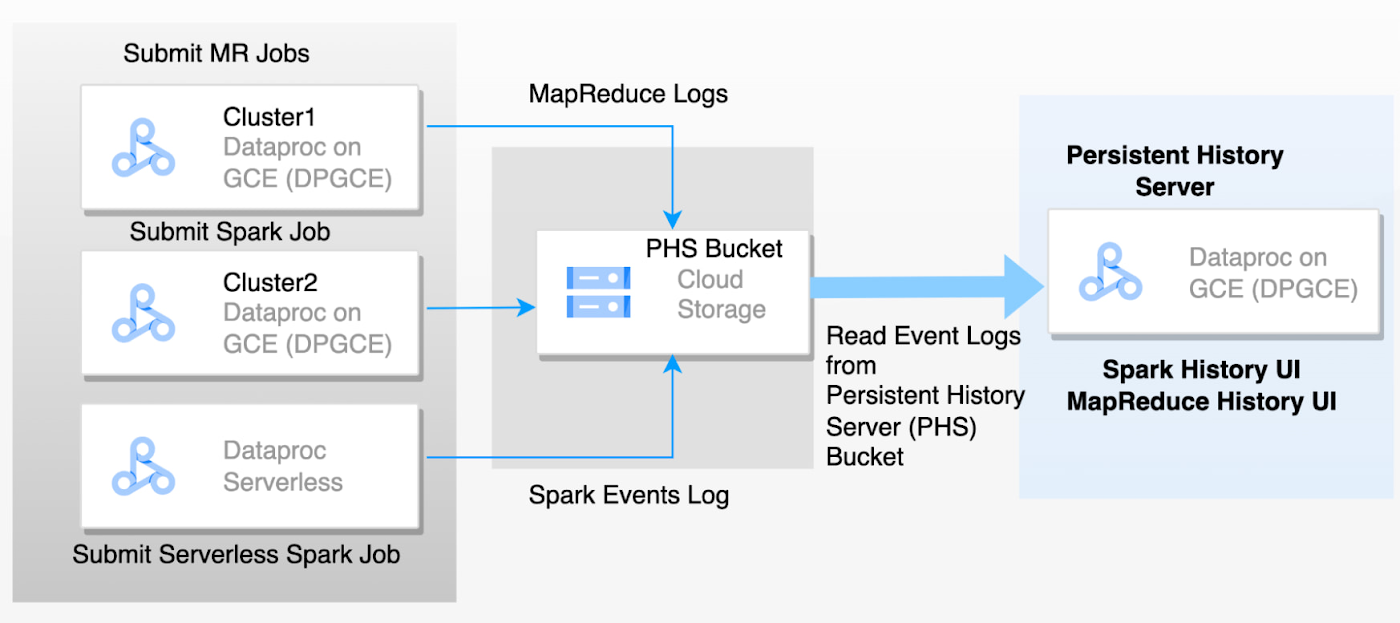
このブログでは、Dataproc PHS のベスト プラクティスに焦点を当てます。MapReduce と Spark のジョブ履歴ファイルのウェブ インターフェースにアクセスできるよう PHS を設定するには、Dataproc のドキュメントをご覧ください。
PHS のベスト プラクティス
クラスタの計画とメンテナンス
特定の GCP プロジェクトに対し 1 つの PHS を使用するのが一般的です。必要に応じて、プロジェクト内の複数の GCS バケットを指す複数の PHS を作成できます。これにより、複数のエフェメラル ジョブを実行し、専用の PHS を必要とする特定のビジネス アプリケーションを分離してモニタリングできます。
ゾーンやリージョンで障害が発生した場合、障害復旧のため、別のリージョンで新しい PHS を迅速にスピンアップできます。
高可用性(HA)が求められる場合、ゾーンまたはリージョンにまたがって複数の PHS インスタンスをスピンアップできます。すべてのインスタンスは、デュアルリージョンまたはマルチリージョンの GCS バケットによってバックアップできます。
PHS は、大規模な並列処理ジョブを実行するわけではないため、単一ノードの Dataproc クラスタで PHS を実行できます。PHS マシンタイプについては、以下の扱いとします。
N2 は、最も費用対効果が高く、高性能な Dataproc 用マシンです。500~1,000 GB の標準 PD ディスクもおすすめします。
アプリが 1,000 個未満で、50K~100K のタスクを伴うアプリがある場合は、n2-highmem-8 をおすすめします。
アプリが 1,000 個未満で、50K~100K のタスクを伴うアプリがある場合は、n2-highmem-8 をおすすめします。
アプリが 10,000 個を超える場合は、n2-highmem16 をおすすめします。
PHS を本番環境で構成する前に、テスト環境で Spark アプリケーションを使用してベンチマークを行うことをおすすめします。本番環境では、GCE でバックアップした PHS インスタンスのメモリと CPU の使用率をモニタリングし、必要に応じてマシンシェイプを調整することをおすすめします。
多数のアプリケーションや大規模なジョブが大規模なイベントログを生成することにより、Spark UI 内のパフォーマンスが著しく低下した場合、より大容量のメモリを搭載してマシンサイズを増やすことで、PHS を再作成できます。
Dataproc は、隔週以上の頻度で新しいサブマイナー バージョンをリリースしているため、PHS インスタンスを再作成して、最新の Dataproc バイナリおよび OS セキュリティ パッチにアクセスできるようにすることをおすすめします。
PHS のサービス(Spark UI や MapReduce History Server など)には後方互換性があるため、すべてのインスタンスで Dataproc 2.0+ ベースの PHS クラスタを作成することが推奨されています。
ログの保存
spark:spark.history.fs.logDirectory を構成することで、エフェメラル クラスタまたはサーバーレス Spark により記述されるイベントログ履歴をどこに保存するかを指定できます。GCS バケットを事前に作成する必要があります。
イベントログは、PHS サーバーにとって重要です。イベントログは GCS バケットに保存されるため、高可用性確保のためマルチリージョン GCS バケットを使用することをおすすめします。マルチリージョン バケット内のオブジェクトは、160 km 以上離れた複数の場所に重複して保存されます。
構成
PHS はステートレスで、GCS バケットからアプリケーションのイベントログを読み込んで、アプリケーションの Spark UI を構築します。SPARK_DAEMON_MEMORY は、履歴サーバーに割り当てるメモリで、デフォルトは 3840m です。Spark UI にアクセスしてジョブアプリケーションの詳細にアクセスしようとするユーザーが多すぎる場合、または長時間稼働する Spark ジョブ(50K または 100K のタスクで複数のステージで反復される)がある場合、ヒープサイズが小さすぎる可能性があります。ヒープに保存されるタスクの数を制限する方法がないため、シナリオに適した数がわかるまで、ヒープサイズを 8G または 16G に増やしてみてください。
ヒープサイズを増やしてもパフォーマンスの問題が発生する場合は、spark.history.retainApplications を構成して、PHS に保持するアプリケーションの数を少なくできます。
mapred:mapreduce.jobhistory.read-only.dir-pattern を構成して、エフェメラル クラスタによって書き込まれた MapReduce ジョブ履歴ログにアクセスします。
デフォルトでは、spark:spark.history.fs.gs.outputstream.type は BASIC に設定されています。ジョブクラスタは、ジョブ完了後、GCS にデータを送信します。これを FLUSHABLE_COMPOSITE に設定すると、ジョブ実行中に一定間隔で GCS にデータをコピーできます。
spark:spark.history.fs.gs.outputstream.sync.min.interval.ms を構成することで、ジョブクラスタが GCS にデータを転送する頻度を制御できます。
PHS で実行者ログを有効化するには、外部ログサービスをサポートするためのカスタム Spark 実行者ログ URL を指定します。以下のプロパティを構成します。
ログのライフサイクル管理
GCS オブジェクトのライフサイクル管理を使用して、30 日のライフサイクル ポリシーを構成し、GCS バケットから MapReduce ジョブ履歴ログと Spark イベントログを定期的にクリーンアップします。これにより、PHS UI のパフォーマンスが大幅に改善されます。
注: クリーンアップを行う前に、長期保存のためにログを別の GCS バケットにバックアップできます。 |
PHS 設定サンプルコード
次のコードブロックで、上で提案したベスト プラクティスを用いて永続履歴サーバーを作成できます。
永続履歴サーバーを使用すると、完了したすべてのアプリケーションをモニタリングおよび分析できます。また、ログと指標を使用して、パフォーマンスを最適化し、タスクの抑制、スケジューラの遅延、メモリ不足エラーに関する問題を解決できます。
参考情報
- エンタープライズ アーキテクト Blake DuBois



