第一原則に基づいたデータ アナリスト ドリブン組織の構築
Google Cloud Japan Team
※この投稿は米国時間 2021 年 10 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
このブログシリーズでは、ホワイトペーパーに関連して、さまざまなタイプのデータドリブン組織について紹介します。このシリーズの前回のブログでは、データ サイエンティスト ドリブン組織は、データへのアクセス性と検出性を高めることで、データから得られる価値を最大化するとともに、強固なガバナンスと運用の徹底を適用して、ML モデルを迅速にデプロイすることを目指していました。データ エンジニアリングドリブン組織では、一般的に 3 つのカテゴリのデータワーカーが存在します。データ エンジニアは、ビジネス ユーザーが使用するために分析チームが分析を行う際に使用するデータ管理者としての役割を果たします。これらの組織タイプの間では、多くの同じ設計上の決定や技術が作用しますが、社会的な側面や組織的な側面は異なります。
組織内のデータワーカーの構成や役割にかかわらず、おそらく多くの同じ課題に直面しているはずです。次のようないくつかの課題に直面されたことがあるかもしれません。
お客様のデータが古い、ノイズが多い、または信頼できない
ビジネス上の意思決定を迅速に行うために、信頼性の高いデータが迅速に必要なものの、新しいデータソースの統合には時間とコストがかかる
リスクの低減、収益性の向上、イノベーションの 3 つのバランスを取るのに苦労している
ビジネスのための分析情報を生み出すのではなく、規制遵守のためのレポート作成に多くの時間が費やされている
これらの課題の中には、規制の厳しい業界に属する企業にとってより深刻なものもありますが、データの更新頻度、分析情報を得るまでの時間、リスクの低減、イノベーションはどの企業にとっても重要な課題です。共通しているのは、分析情報をできるだけ早くビジネス価値に変換しなければならないという大きなプレッシャーがあるということです。お客様は、データを活用した正確かつ迅速な操作を求めています。その結果、組織が競争力を維持するためには、データ分析の能力を磨く必要があります。
一方で、テクノロジーは進化しており、データレイクや Spark などのデータ処理フレームワークなどの新しいテクノロジーの導入により、スキルギャップが生じています。これらのテクノロジーは強力ですが、Java や Scala などの言語によるプログラミング スキルが必要です。また、従来の SQL 宣言型アプローチとは根本的に異なるパラダイムを提示しています。企業内のデータワーカーのバランスは微妙で、従来のデータ アーキテクチャには非常に特殊な技術的スキルが必要とされます。このバランスを崩すような新しい技術スタックについては、技術的なスキルの再配分や、他のデータワーカーに対するエンジニアリング リソースの比率の変更が必要です。部門長にとって、新しいスキルを持った人材をチームに加えることは、中央の IT 部門に大規模な変更を加えることよりも容易であることが多く、その結果、進化や新しいスキルセットは組織図の一部でしか発生しませんでした。
では、なぜテクノロジーはあなたのニーズに適応しないのでしょうか?
Hadoop などのテクノロジーの盛衰により、見て見ぬふりをしてきた問題が明らかになりました。テクノロジーは自社の文化に適合し自社の能力を高める必要があります。これにより、生産性を高め、ビジネスニーズを反映させ、エキスパティーズを維持できます。新しいテクノロジーを活用するために、エンジニアリング ドリブン組織になる必要はありません。
ここでは、クラウド型構造化データレイクのコンセプトの先駆者である BigQuery のようなプラットフォームが、新しい多様なデータソースに対応できるスケーラブルな処理エンジンとストレージ層を、使い慣れた SQL ベースのユーザー インターフェースを介してどのように提供できるかを探っていきます。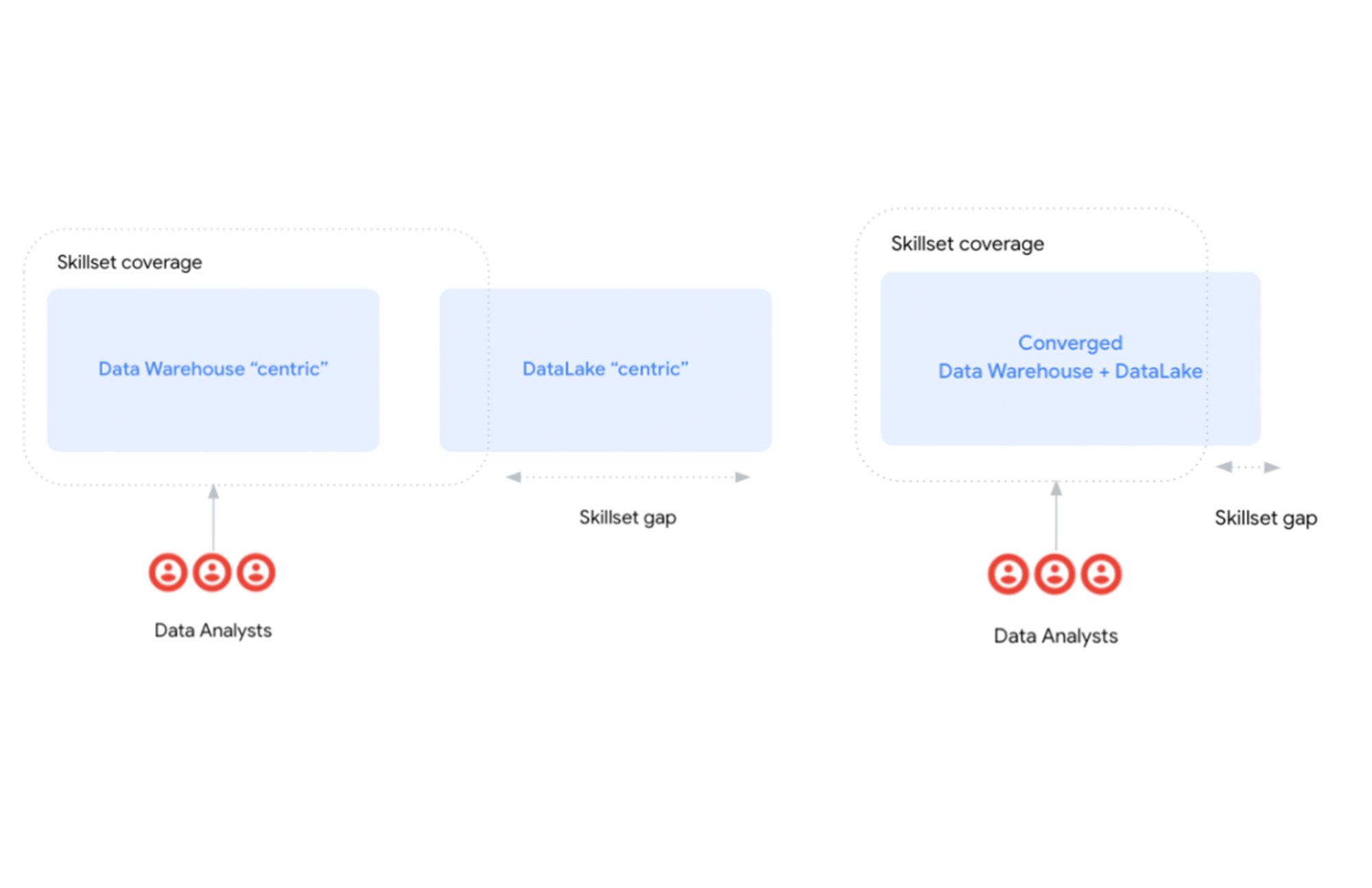
データ アナリスト ドリブン組織で「データドリブン」なアジェンダを構築するには?
変換にあたって押すべき主なスイッチについて説明する前に、データ アナリスト ドリブン組織とは何を意味するのかを定義しましょう。組織がアナリスト ドリブンであるかどうかは二元的な概念ではなく、さまざまな特徴が重なり合っていることに留意する必要があります。
成熟した業界。マクロレベルでは、これらの組織は以前のシステムを有する近代の老舗です。一般的に、これらの企業が事業を行っている業界は成熟しており、安定していると考えられます。
デジタル ネイティブの新興勢力との競争。 競争上の観点からは、他の類似した組織に加えて、急成長しているデジタル分野や最も高い可能性を秘めた顧客層を獲得することを目的とした新興のデジタル組織(フィンテックなど)も存在します。
EDW + バッチ ETL。技術的に言えば、中心となる情報は、高度な技術的負債や以前の技術を用いて長年にわたって構築されたエンタープライズ データ ウェアハウス(EDW)の形で提供されます。データ ウェアハウス内のデータの変換は、毎晩のバッチのようにスケジュールされた ETL(抽出 / 加工 / 読み込み)プロセスによって行われます。このバッチ処理は、データを提供する際のレイテンシを増加させます。
ビジネス インテリジェンス。組織内のデータワーカーの多くは、一元化されたデータ ウェアハウスに対して SQL クエリを起動したり、BI ツールを使ってレポートやダッシュボードを作成したりして、ビジネス上の疑問に答えることに慣れています。さらに、同様のデータにアクセスするためにスプレッドシートが使用されているため、社内の人材プールは、SQL、BI ツール、スプレッドシートに最も慣れています。
データ部門に焦点を絞ると、この種の組織における主なペルソナとプロセスは以下のように一般化できます。
データ アナリスト: 企業からのリクエストを受け取り、理解し、サービスを提供し、関連するデータの意味を理解することに注力します。
ビジネス アナリスト: 情報をコンテキストに落とし込み、分析した分析情報に基づいて行動します。
データ エンジニア: 下流のデータ パイプラインとデータ変換の最初のフェーズ(新しいソースの読み込みと統合など)に焦点を当てます。さらに、データ ガバナンスとデータ品質プロセスの管理を行います。
最後に、その関連性から、データ アナリストとは何かを掘り下げて考えてみたいと思います。データ アナリストとしての目標は、組織の情報ニーズを満たすことです。データ アナリストはデータ自体の論理的な設計とメンテナンスを担当します。その中には、ビジネス プロセスに合わせたテーブルのレイアウトやデザインの作成、ソースの再編成や変換なども含まれます。さらに、企業から求められるトレンド、パターン、または予測を効果的に伝えるレポートや分析情報の作成も担当します。
データ アナリスト ドリブン組織のミッションをどのように構築するかという最初の質問に戻ると、その答えは、 データ アナリストのコミュニティの経験とスキルセットを利用し、拡大することです。
一方で、私たちはデータ アナリストが企業サイドに進出する傾向を促進しています。先に述べたように、データ アナリストは、ビジネス ドメインに関する深い知識と、データの量や大きさにかかわらずデータを分析するための十分な技術的スキルに基づいた貴重な知識を提供します。
クラウドベースのデータ ウェアハウスや BigQuery などのサーバーレス技術は、右側の責任の拡大に貢献しています(図 3 でハイライト表示しています)。これにより、データ アナリストは、管理や技術的な作業に時間と労力を費やすことなく、付加価値の提供に集中できます。さらに、ストレージ システムがサポートするデータの量や種類に制限されることなく、ビジネスをより深く掘り下げるために余った時間を投資することができるようになりました。
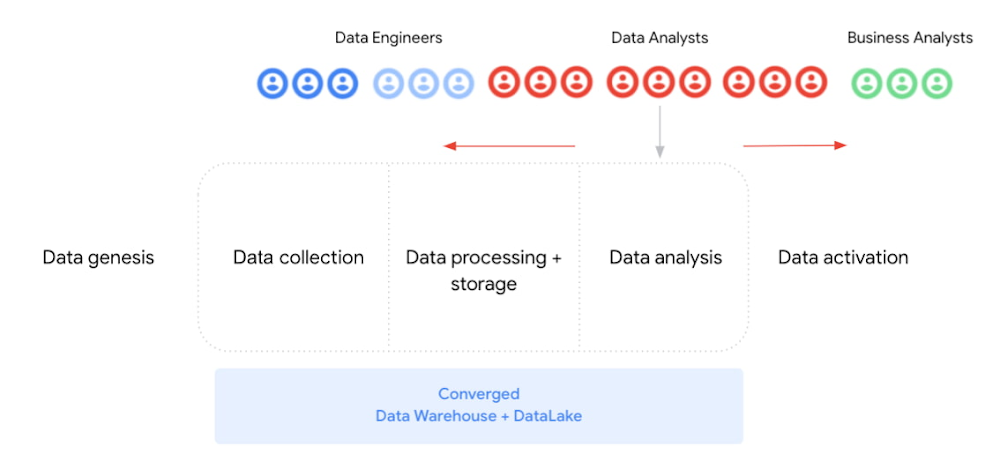
一方で、新しいデータ処理のパラダイムにより、データ アナリストの責任範囲で逆方向への動きを可能にします。データ分析の基本的なクエリツールとして SQL を使用できますが、これからはデータの処理 / 変換にも使用できるようになります。その過程で、データ アナリストはデータ エンジニアリングの仕事の一部である、データのインテグレーションとエンリッチメントを担当できます。
データ アナリストを中心とした組織では、従来の ETL(抽出 / 加工 / 読み込み)ではなく、ELT(抽出 / 読み込み / 加工)のコンセプトを取り入れています。主な違いは、データ ウェアハウスにデータが読み込まれた後、一般的なデータ処理タスクが行われることです。ELT は SQL ロジックを多用し、データの強化、クレンジング、ノーマライズ、絞り込み、インテグレーションを行い、分析の準備を整えます。このようなアプローチには、行動に移すまでの時間が短縮される、データがすぐに読み込まれる、複数のユーザーが同時に利用できる、などのメリットがあります。
データ アナリスト ドリブン組織のための、強固で変革的な実用的アーキテクチャ
これまで、データ変換を可能にする技術革新について簡単に説明してきましたが、このセクションでは、これらのビルディング ブロックのより詳細な説明に焦点を当てていきます。
ハイレベルなアーキテクチャを定義するためには、まずコンポーネントと相互関係を導き出すための第一原則を定義することから始めます。言うまでもなく、実際の組織では、これらの原則と、アーキテクチャの決定を現実と既存の投資に適合させる必要があります。
原則 1: SQL はアナリティクスの「共通語」である
テクノロジーは、現在の組織文化に適応すべきであり、データ処理パイプラインのどこにあっても、SQL インターフェースを提供するコンポーネントを優先します。
原則 2: 構造化データレイクの登場
情報システム基盤とそのデータが融合することで、多様なデータソースに対する分析処理の可能性が広がります。これは、従来のデータ ウェアハウスをデータレイクに統合し、サイロを解消することを意味します。
原則 3: データ / スキーマの流動性を想定し、計画する
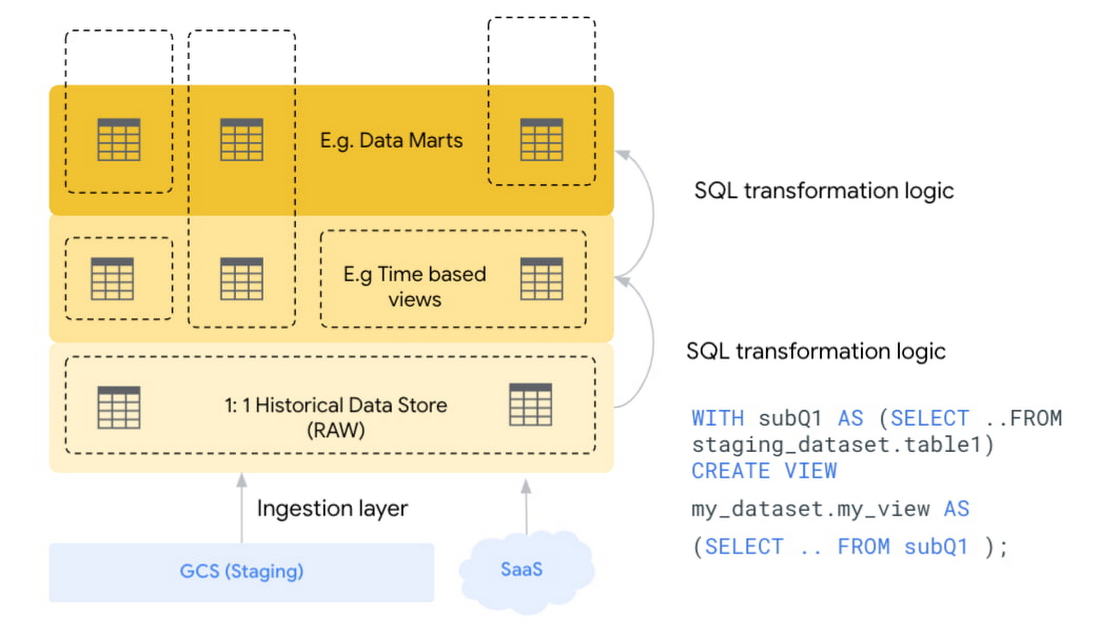
ストレージは安価なので、データが届く前にデータ構造に関する厳格なルールを課す必要はありません。スキーマオンライト モデルからスキーマオンリード モデルに移行することで、データへのリアルタイムなアクセスが可能になります。 データは未処理の状態で保管しておき、有用なスキーマに変換できます。さらに、データ プラットフォームは、これらのコピーを同期させるプロセスを管理できます(例えば、マテリアライズド ビューや CDC などを使用します)。そのため、同じデータ資産のコピーを複数持つことを恐れる必要はありません。
これらの原則を組み合わせることで、次の図のようなハイレベルなアーキテクチャを定義できます。
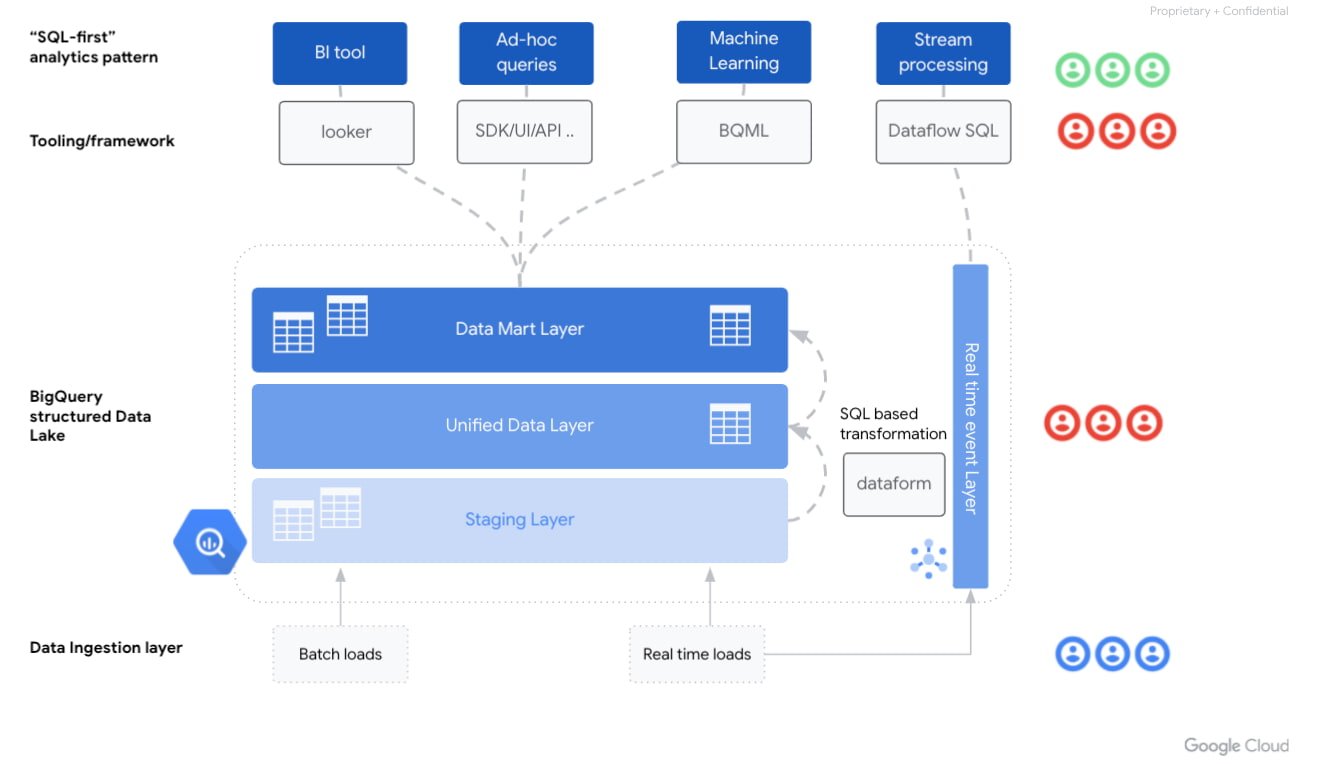
このような組織の情報アーキテクチャには、どのような要素がありますか?
まず、最新のデータ プラットフォームは 増え続けるデータ分析のパターンに対応する必要があります:
Looker などのツールを用いた「古典的な」ビジネス インテリジェンス ワークロード
SQL ベースのアドホック分析インターフェースで、ELT を介したデータ パイプラインの管理が可能
機械学習技術でデータ サイエンスのユースケースを実現
リアルタイム イベント処理
最初の 2 つのパターンは、伝統的な SQL データ ウェアハウスの世界に極めて近いですが、最後の 2 つのパターンは、より高度な分析パターンに対する SQL の抽象化という形でイノベーションを提示しています。例えば、機械学習の分野では、BigQuery MLがあります。これを使えば標準的な SQL クエリを使ってBigQuery で機械学習モデルを実行できます。Dataflow SQL ストリーミング拡張機能により、Dataflow の基礎となるソース、たとえば Pub/Sub や Kafka などでデータ ストリームを集約できます。新しいプロファイルや役割に投資することなく、テクノロジーが可能にする可能性の世界を考えてみましょう。
データ アナリスト ドリブン組織では データの準備と変換という課題は、ELT と ETL のどちらを選択するかという明確で大きなメッセージとなります。可能な限り ELT を使用します。この新しいパラダイムとの大きな違いは、データがどこで変換されるかという点ですが、これは構造化データレイクの中で、SQL を使って変換されます。
大規模なデータ インテグレーション スイートが提供する機能を犠牲にすることなく、SQL でデータを変換できます。しかし、スケジュール管理、依存関係の管理、データ品質、運用監視などはどうすればよいでしょうか?dbt や BigQuery Dataform のようなプロダクトは、データ モデリングやデータ ワークフローの構築にソフトウェア エンジニアリングのアプローチをもたらします。同時に、プログラマーではない人でも、しっかりとしたデータ変換を行うことができます。
Data Vault 2.0 のようなモデリング技術は、クラウド ドリブンの新しいデータ ウェアハウスにおける ELT の力によって復活しています。そのため、データの論理的な分布は、Immon や Kimball のリファレンス アーキテクチャのような古典的なパターンに沿って変更されないことに注意する必要があります。[1] [2]
データ アナリスト ドリブン組織では、データ エンジニアリング チームがソースシステムからのデータ抽出を管理するのが一般的です。SQL ベースのツールを使用することで、データ アナリストがその作業の一部を行うことができますが、強力なデータ エンジニアリング チームの必要性は変わりません。ETL に適したデータ パイプラインの作成が必要なバッチジョブもあります。例えば、メインフレームからデータ ウェアハウスにデータを持ってくる場合、データタイプのマッピングや COBOL ブックの変換など、追加の処理ステップが必要になります。また、リアルタイム分析などのユースケースでは、データ エンジニアリング チームが Pub/Sub や Kafka トピックなどのストリーミング データソースの構成を行います。汎用的なタスクを扱う方法はこれまでと同じで、汎用的な ETL パイプラインとして記述し、アナリストが再構成できます。たとえば、さまざまなソース データセットからターゲット環境にデータ品質の検証チェックを適用します。 まとめると、クラウド データ ウェアハウスの力で、従来の ETL 作業の代わりに ELT を使うことができるようになったということです。しかし、前述したように、データ品質アプリケーションなど、ETL を必要とするユースケースもあります。
まとめ
この記事では、データ アナリスト ドリブン組織を特定し、その組織が直面する課題を検討しました。最も貴重なアセットの一つであるデータ アナリストを中心に変革プランを構築することが可能であることを見てきました。また、このような組織を効率的に利用するために必要な、現代的でスケーラブルな情報アーキテクチャに登場する主なコンポーネントについても確認しました。データ アナリストの責務は、自動学習やリアルタイム イベント処理などの高度なデータ エンジニアリング業務に拡大しています。これらはすべて、慣れ親しんだ、愛すべきお気に入りのインターフェースは SQL によって実現可能です。Google Cloud の無料枠を利用する場合は、お気軽にお問い合わせいただくか無料トライアルを開始してください。
- Google Cloud カスタマー エンジニア Luis Velasco
- データ アナリティクス プラクティス リード Firat Tekiner 博士

