Google Kubernetes Engine での Triton Inference Server のワンクリック デプロイ

Google Cloud Japan Team
※この投稿は米国時間 2021 年 8 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
まとめ: NVIDIA GPU 対応の機械学習(ML)推論プロジェクトの開始をサポートする、Google Kubernetes Engine(GKE)の Marketplaceソリューション(ソリューション、README)である One-Click Triton Inference Server をご紹介します。
過去 10 年間のディープ ラーニング(DL)の研究から、さまざまなユースケースのエキサイティングで有用なモデルが数多く生まれました。10 年ほど前は、AlexNet が最先端の画像分類モデルでした。そして、そのデータベースである Imagenet の誕生の瞬間に、ディープ ラーニングの爆発的な普及が始まったとされています。現在、BERT(Bidirectional Encoder Representations from Transformers)および関連するモデル ファミリーは、テキスト分類から問題と解答(Q&A)まで、さまざまな複雑な自然言語のユースケースを可能にしています。トップレベルの研究者が、億単位以上のパラメータを持つ最先端のモデルを作成している一方で、これらのモデルの大規模な本番環境を実現するには、解決しなければならない課題がさらにあります。
Google Kubernetes Engine の NVIDIA Triton Inference Server での推論のスケーリング
最近の ML フレームワークでは、モデルのトレーニングやテストがより利用しやすくなっていますが、ML モデルのサービング、特に本番環境でのサービングは依然として困難です。推論環境を構築する際、一般的に次のような問題が発生します。
DL フレームワーク バックエンドの複雑な依存関係と API
本番環境ワークフローにモデル推論だけでなく、前処理の手順も含まれる
アクセラレータのパフォーマンスを最大限に引き出すためのポイントを見つけにくい
堅牢な Ingress や負荷分散を実現するのに必要なスクリプトや構成が多すぎる
このブログでは、Google Kubernetes Engine(GKE)の One-Click Triton Inference Server を紹介し、このソリューションがいかに ML モデルをスケーリングして、厳しいレイテンシの予算を満たし、運用コストを最適化するかを示します。
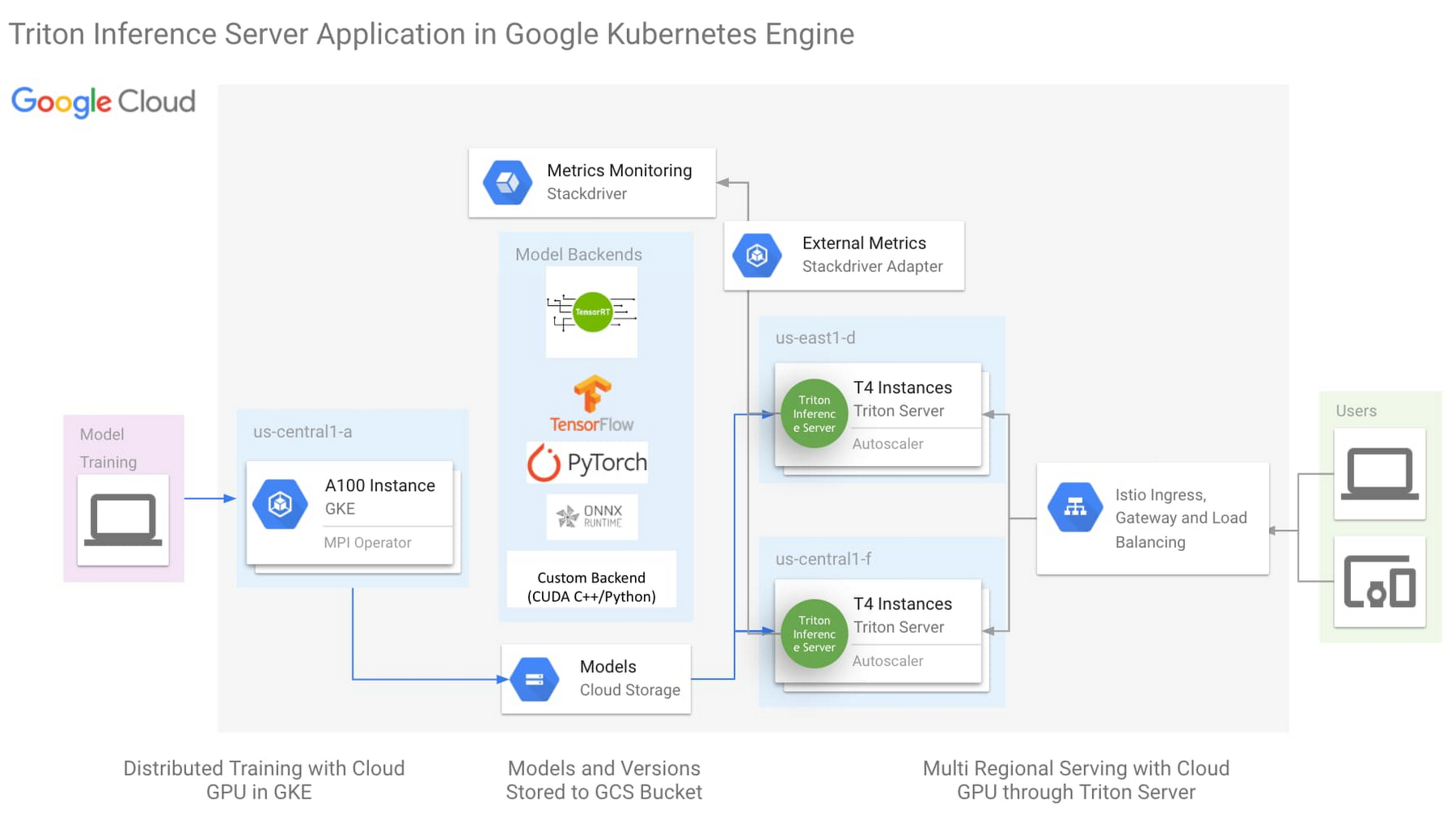
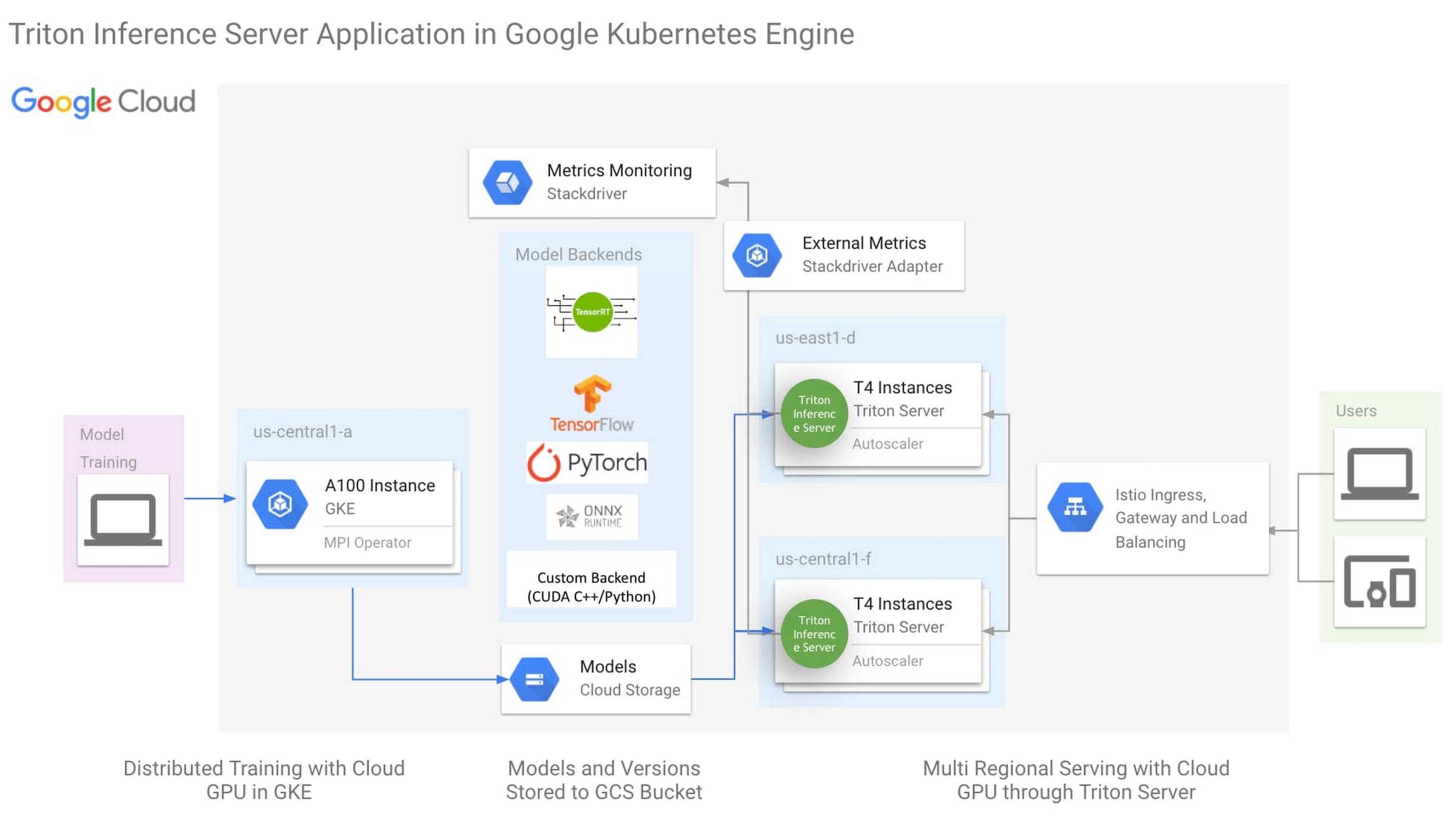
上のアーキテクチャは、次の重要な要素を使用した One-Click NVIDIA Triton Inference Server ソリューション(こちらをクリックして今すぐお試しください)です。
NVIDIA Triton Inference Server
Istio による Ingress と負荷分散の簡素化
HorizontalPodAutoscaler(HPA)による Stackdriver を介した外部指標のモニタリング
Triton Inference Server は、NVIDIA のオープンソース推論サーバーで、ほとんどの ML フレームワークのバックエンド、および Python や C++ のカスタム バックエンドをサポートしています。この柔軟性により、異なるフレームワークに対応するために異なる推論サーバーを実行する必要性を軽減し、ML インフラストラクチャを簡素化します。Triton は、GPU のあらゆる高度な機能を活用するために作成されましたが、同時に CPU でも高いパフォーマンスを発揮するように設計されています。ML フレームワークとハードウェア処理のサポートにおける Triton の柔軟性により、モデルをサービングするインフラストラクチャの複雑さを軽減できます。
One-Click Triton ソリューションの詳細については、こちらをご覧ください。
ミッション クリティカルな ML モデル サービングを実現するための NVIDIA Triton Inference Server
現在の組織は、ビジネス ユニット全体で ML をだれでも利用できるようにするために、共有サービスとしての ML プラットフォーム構築を検討しています。共有サービス型の ML サービング プラットフォームが成功するためには、信頼性と優れた費用対効果が必要です。このような要求に応えるために、NVIDIA は Triton Inference Server 特有の 2 つの機能を作成しました。
モデルの優先度
TensorRT
モデルの優先度を使用した使用率と ROI の最大化
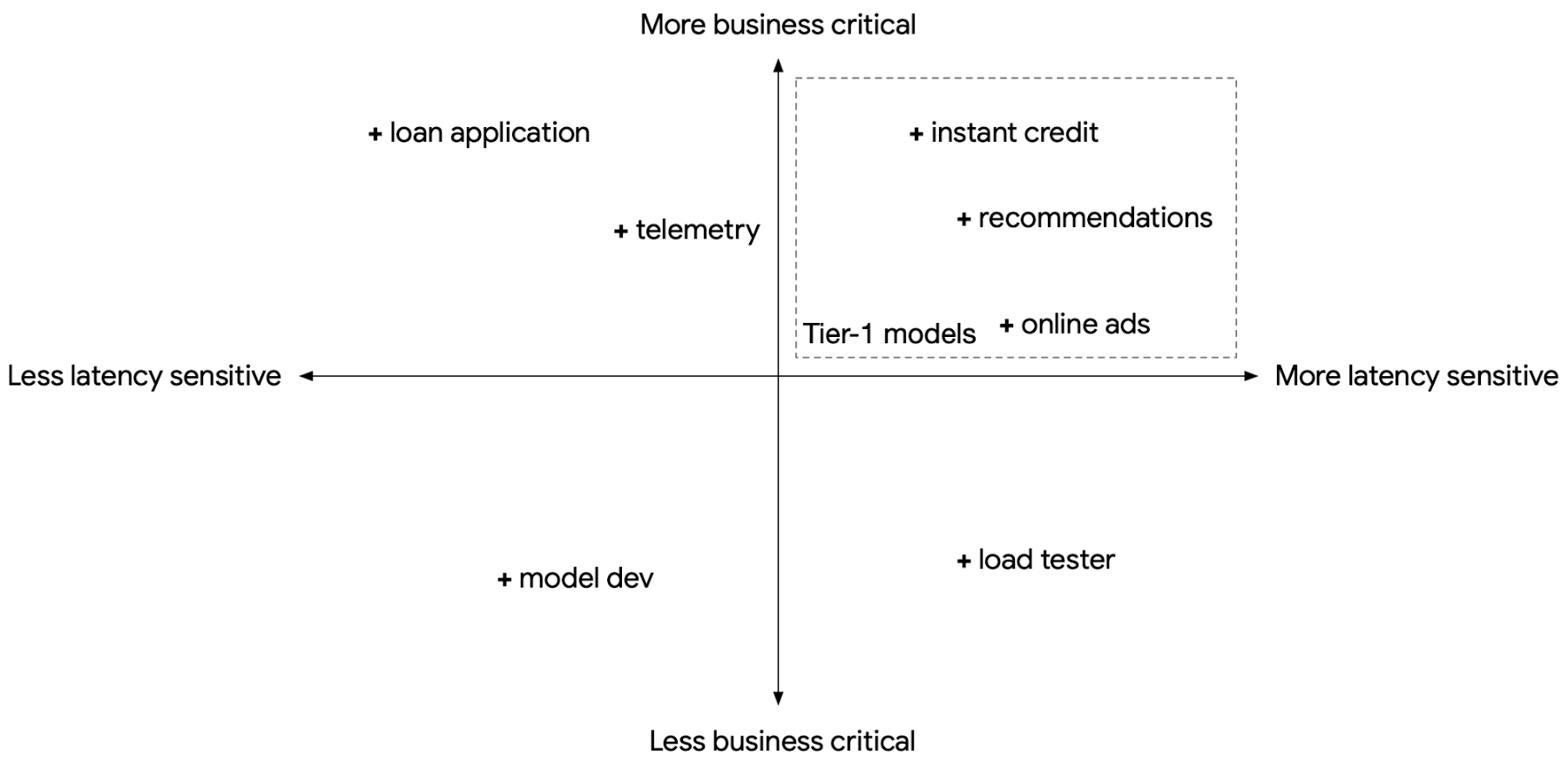
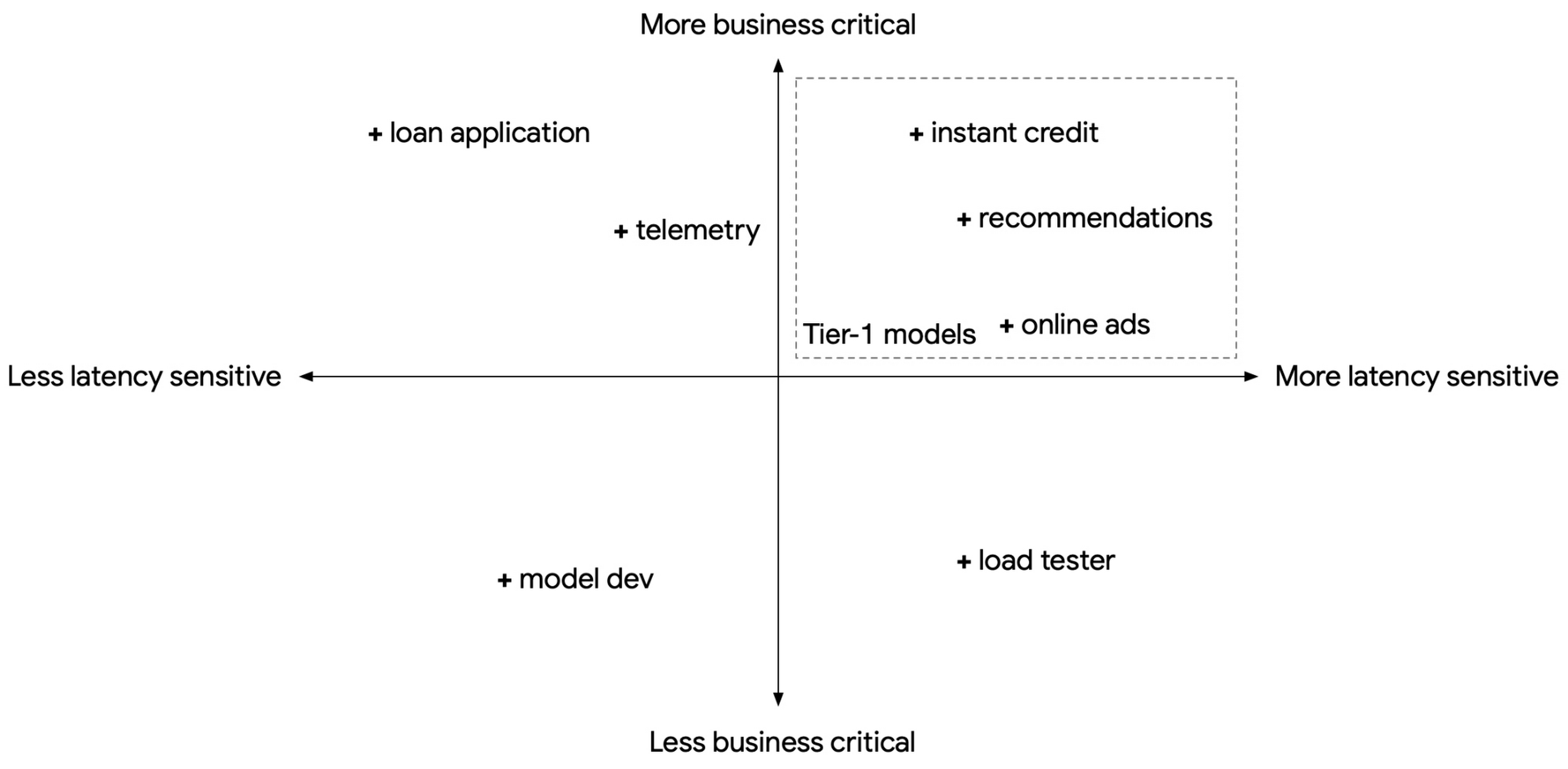
共有サービス型推論プラットフォームを構築する際には、複数のユースケースのモデルをサポートすることを想定する必要があり、それぞれのユースケースは、レイテンシ感度、ビジネス上の重要性、一時的な負荷変動の度合いが異なります。同時に、標準化や規模の経済性により費用をコントロールすることも考慮する必要があります。ただし、これらの要件は往々にして相反します。たとえば、サービスレベル目標(SLO)が厳格に設定されたビジネス クリティカルでレイテンシの影響を受けやすいモデルでは、一時的な負荷変動を見越してコンピューティング リソースを事前にプロビジョニングし、余った未使用のコンピューティングに料金を支払うのか、それともプロビジョニングするコンピューティング リソースを典型的なケースにおける必要量に抑えて費用を節約するか、一時的な負荷が急増したときにレイテンシ SLO に違反するリスクを負うのかの 2 つの選択肢があります。
Google がさまざまなモデルをサービングする際、その一部がレイテンシの影響を受けやすく、ビジネス クリティカルな性質を持っていることは多くあります。これらをティア 1 モデル、残りをティア 2 モデルとして扱うことができます。
Triton Inference Server では、モデルを PRIORITY_MAX としてマークする機能があります。複数のモデルを同じ Triton インスタンスに統合し、一時的に負荷が急増した場合、Triton は PRIORITY_MAX モデル(ティア 1)からのリクエストを優先し、他のモデル(ティア 2)を犠牲にします。
以下は、一般的な 3 つの負荷の急増のシナリオを示したものです。最初の(1)のシナリオでは負荷の急増が発生していますが、プロビジョニングされたコンピューティングの上限内に納まっています。どちらのモデルも正常に動作を継続しています。2 つ目の(2)のシナリオでは、ティア 1 モデルの負荷が急増し、コンピューティング負荷の合計がプロビジョニングされた上限を超えます。Triton は、ティア 2 モデルのコンピューティングを減らすことで、ティア 1 モデルを優先します。3 つ目の(3)のシナリオでは、ティア 2 モデルの負荷が急増しています。Triton は、ティア 1 モデルが必要とするコンピューティング リソースを3 つのシナリオのすべてで確実に提供します。
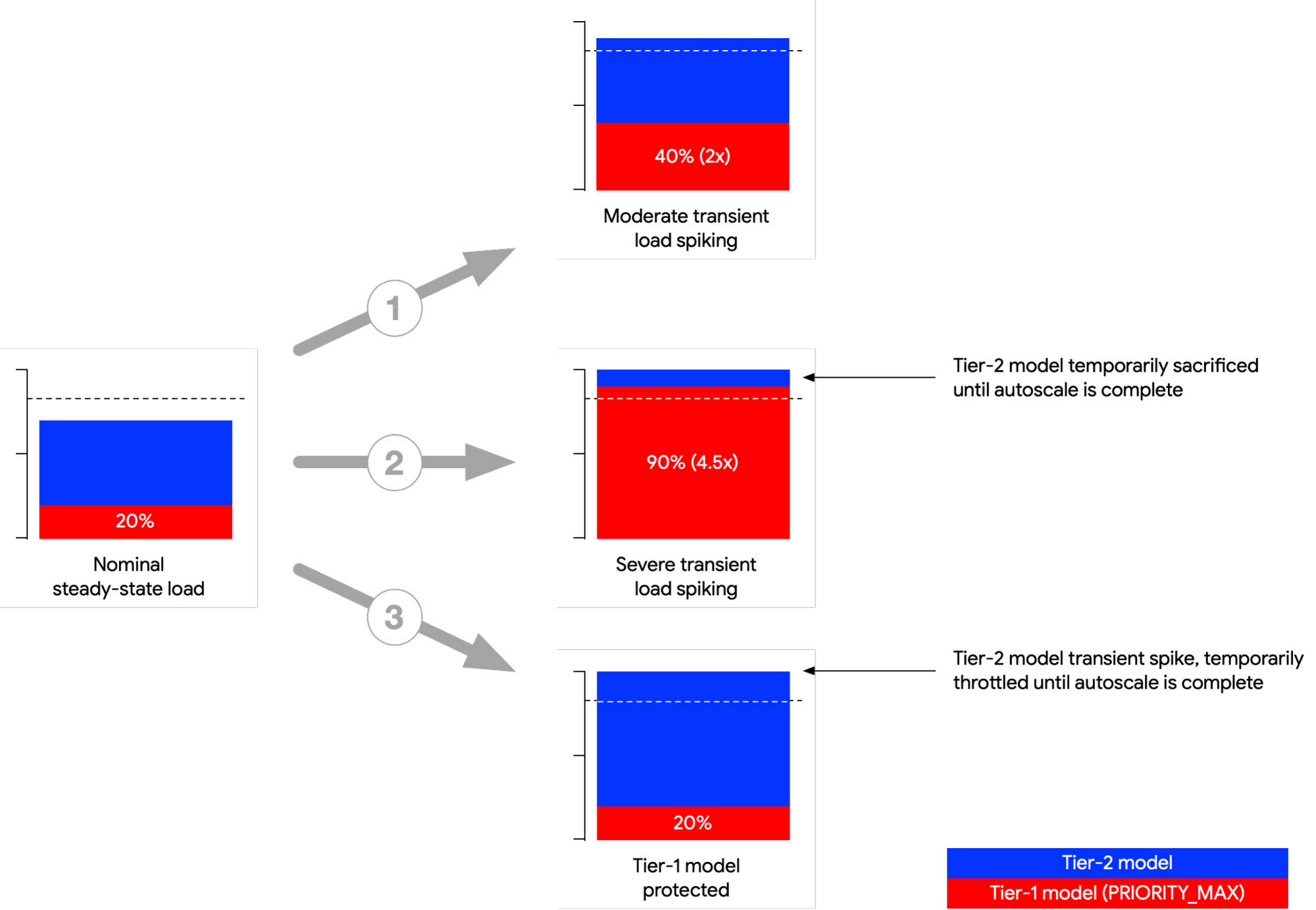
GKE は自動スケーリングを提供しますが、一時的な負荷の急増の自動スケーリングで GKE のみに依存すると、負荷の急増が数秒単位で現れるのに対し GKE は数分単位で自動スケーリングを行うため、SLO 違反になる可能性があります。「モデルの優先度」機能は一時的な負荷急増に対し短期間のバッファリングを行うため、GKE がそのノードプールを自動スケーリングする間、ティア 1 モデルの SLO を維持できます。一時的な負荷の急増に対応するためのオプションについて詳しくは、リファレンス ガイドの一時的な負荷による ML サービングのレイテンシを軽減するをご覧ください。
NVIDIA TensorRT によるパフォーマンスと費用対効果の最大化
Triton が多数のバックエンド フレームワークをサポートし、高度にプラガブルなアーキテクチャを提供する一方で、TensorRT バックエンドは非常に優れたパフォーマンスを提供します。
NVIDIA TensorRT(TRT)は、NVIDIA GPU 上で高パフォーマンスなディープ ラーニングを実行するための SDK で、レイヤの融合、混合精度、構造化されたスパース性などの最適化を適用することで、これまでにないパフォーマンスを活用できます。最新の NVIDIA A100 GPU を例に挙げると、TensorRT には FP16 および INT8 の行列演算に最適化された GPU 内ユニットである Tensor Cores が組み込まれており、構造的スパース性をサポートしています。TensorRT を BERT モデルに適用した最適化については、こちらのブログをご参照ください。
次の Triton の構成を TensorRT と併用することにより GPU 推論のパフォーマンスと使用率を向上させることができます。
同時実行: モデルの別のコピーが別々の CUDA ストリームで実行されるため、同時に CUDA カーネルの同時実行ができます。これにより、並列化を向上できます。
動的バッチ処理: Triton は指定されたレイテンシ要件を守りつつ、複数の推論リクエストをサーバーサイドで動的にグループ化します。
BERT 推論パフォーマンスに対する TensorRT の影響
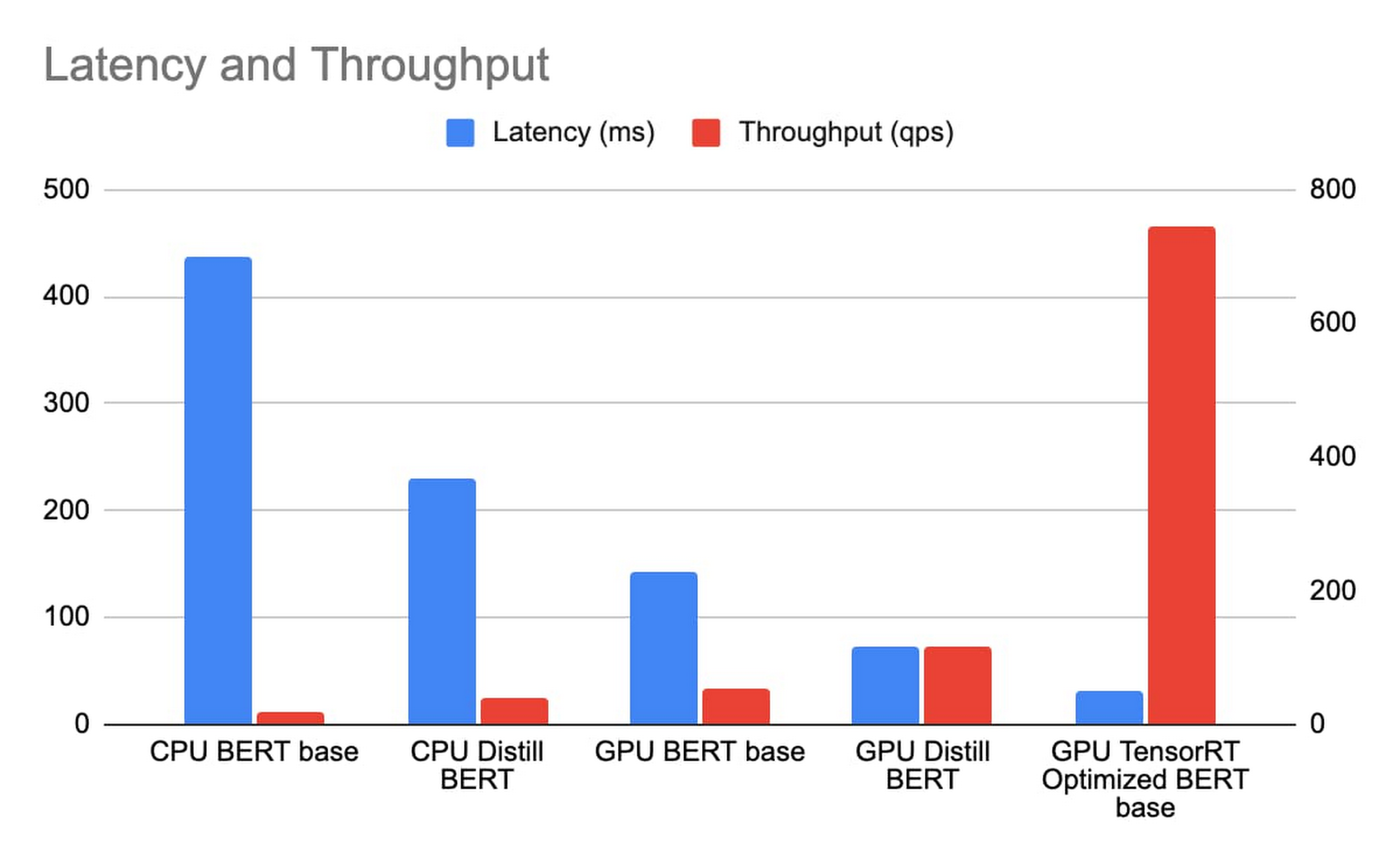
今回、CPU 版の BERT BASE と Distill BERT を n1-standard-96 に、そして GPU 版の BERT BASE、Distill BERT、BERT BASE(TRT 最適化有効)を n1-standard-4(T4 GPU 1 基搭載)にそれぞれデプロイしています。BERT モデルのシーケンス長は 384 トークンとしました。Triton のパフォーマンス アナライザを使用した同時実行スイープで、レイテンシとスループットを測定しています。レイテンシには Istio Ingress / 負荷分散が含まれており、同じ GCP ゾーンにおける実際のエンドツーエンドの費用に反映されます。
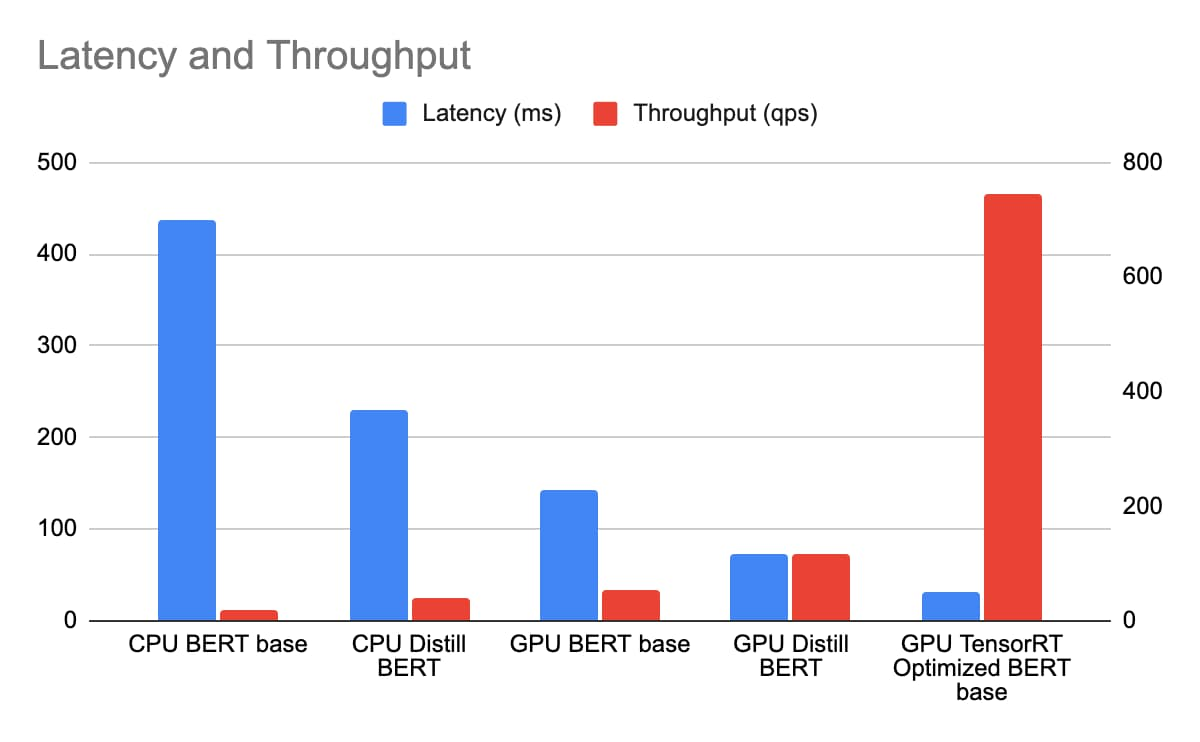
n1-standard-96 の料金は 1 時間 4.56 ドル、n1-standard-4 の料金は 1 時間 0.19 ドル、T4 の料金は 1 時間 0.35 ドルで、合計で 1 時間 0.54 ドルになります。T4 で TensorRT を使用して実行する BERT 推論は、n1-standard-96 で実行する Distill BERT 推論よりはるかに低いレイテンシと同時に、TCO については 163 倍以上の改善を実現します。
結論
GPU と TensorRT を搭載した GKE 上で動作する NVIDIA Triton Inference Server は、エンタープライズ規模の共有サービス型 ML 推論プラットフォームを構築するうえで、費用対効果に優れた高パフォーマンスな基盤を提供します。また、ML 推論プロジェクトの開始をサポートする One-Click Triton Inference Server ソリューションもご紹介しました。最後に、GPU を使用した推論プロジェクトを軌道に乗せるための推奨事項をいくつか挙げました。
TensorRT を使用してディープ ラーニング モデルの推論パフォーマンスを最適化する。
Triton の同時実行サービングや動的バッチ処理機能を活用する。
新しい GPU を最大限に活用するために、TensorRT モデルに FP16 または INT8 の精度を使用する。
ティア 1 モデルのレイテンシ SLO コンプライアンスを確保するために、モデルの優先度を使用する。
関連情報
謝辞: NVIDIA プリンシパル ソフトウェア エンジニア David Goodwin 氏、NVIDIA Triton プロダクト マネージャー Mahan Salehi 氏、NVIDIA シニア アカウント マネージャー Jill Milton 氏、GCP および GKE Marketplace チーム技術ソリューション コンサルタント Dinesh Mudrakola 氏
-NVIDIA ソリューション アーキテクト Dong Meng 氏
-Google Cloud データ管理兼 AI ソリューション アーキテクチャ責任者 Kevin Tsai




{kind=link}
{kind=link}
{kind=link}
{kind=link}