Redéfinir les données d’entreprise grâce aux agents et aux fondations IA-natives
Yasmeen Ahmad
Managing Director, Data Cloud, Google Cloud
Le monde ne se contente pas de changer : il se reconstruit, se réinvente, sous nos yeux, propulsé par la donnée et l’intelligence artificielle. Notre rapport aux données se métamorphose. Nous entrons dans une nouvelle ère, l’ère agentique, où l’analyse n’est plus le seul fruit de l’expertise humaine mais repose sur une synergie collaborative avec des agents IA capables d’agir, d’apprendre et de coopérer entre eux et avec l’humain pour libérer des insights à une vitesse et une ampleur inédite.
Depuis le début, chez Google Cloud, nous ne voulons pas rester spectateurs de cette transformation : à l’inverse nous bâtissons les fondations de l’IA, les modèles, les écosystèmes interconnectés et les plateformes de données « IA natives » qui l’alimentent.
Pour rendre cette réalité agentique possible, il faut un autre type de plateforme de données : non pas une collection d’outils en silos, mais un cloud unique, unifié et natif de l’IA. C’est justement ce qu’est Google Data Cloud.
Au cœur de cette plateforme, nos moteurs analytiques et opérationnels unifiés effacent la fracture historique entre données transactionnelles métiers et analyses stratégiques. Google Data Cloud offre ainsi aux agents une compréhension complète et en temps réel de l’entreprise, transformant celle-ci d’un ensemble de processus en une organisation auto-analytique, auto-optimisée et fiable.
Pour donner corps à cette vision, nous lançons trois innovations majeures :
* Une collection d’agents de données nouvelle génération : des agents d’IA spécialisés, conçus pour agir comme partenaires experts auprès de tous les utilisateurs de données, qu’il s’agisse de data-scientists, d’ingénieurs ou d’analystes métier.
* Un réseau interconnecté pour la collaboration entre agents : un ensemble d’API, d’outils et de protocoles permettant aux développeurs d’intégrer les agents Google à leurs propres agents et projets IA, créant ainsi un écosystème intelligent unifié.
* Une fondation unifiée et IA native : une plateforme qui rend possible l’action d’agents intelligents en unifiant les données, en offrant une mémoire persistante et en intégrant un raisonnement piloté par l’IA.
Des agents de données experts à vos côtés
Bienvenue dans l’ère agentique : une nouvelle force de travail vous assiste, composée d’agents IA spécialisés, conçus pour comprendre vos intentions et les transformer instantanément en actions concrètes grâce à une interface pensée IA dès le départ.
* Pour les data engineers : nous lançons un Data Engineering Agent dans BigQuery afin de simplifier et automatiser les pipelines de données complexes. Il est désormais possible d’utiliser des requêtes en langage naturel pour fluidifier l’ensemble du workflow, depuis l’ingestion des données issues de sources comme Google Cloud Storage jusqu’aux transformations et au contrôle de la qualité des données. Il suffit de décrire ce dont vous avez besoin. Par exemple, il suffit de demander « Crée un pipeline pour charger un fichier CSV, nettoyer ces colonnes et le joindre à une autre table » et l’agent génère et orchestre automatiquement l’ensemble du processus.

Fig. 1 – Data Engineering Agent en action pour l’automatisation de pipelines de données complexes
* Pour les data scientists : nous repensons l’expérience Colab Enterprise Notebook avec une logique IA-native, intégrée à BigQuery et Vertex AI. Au cœur de cette évolution : le Data Science Agent, propulsé par Gemini, prend en charge des workflows entiers, de l’analyse exploratoire au nettoyage, de la création de features aux prédictions ML. Il planifie, code, interprète les résultats et restitue ses insights, tout en restant interactif : vous pouvez corriger, commenter et collaborer en temps réel avec lui.
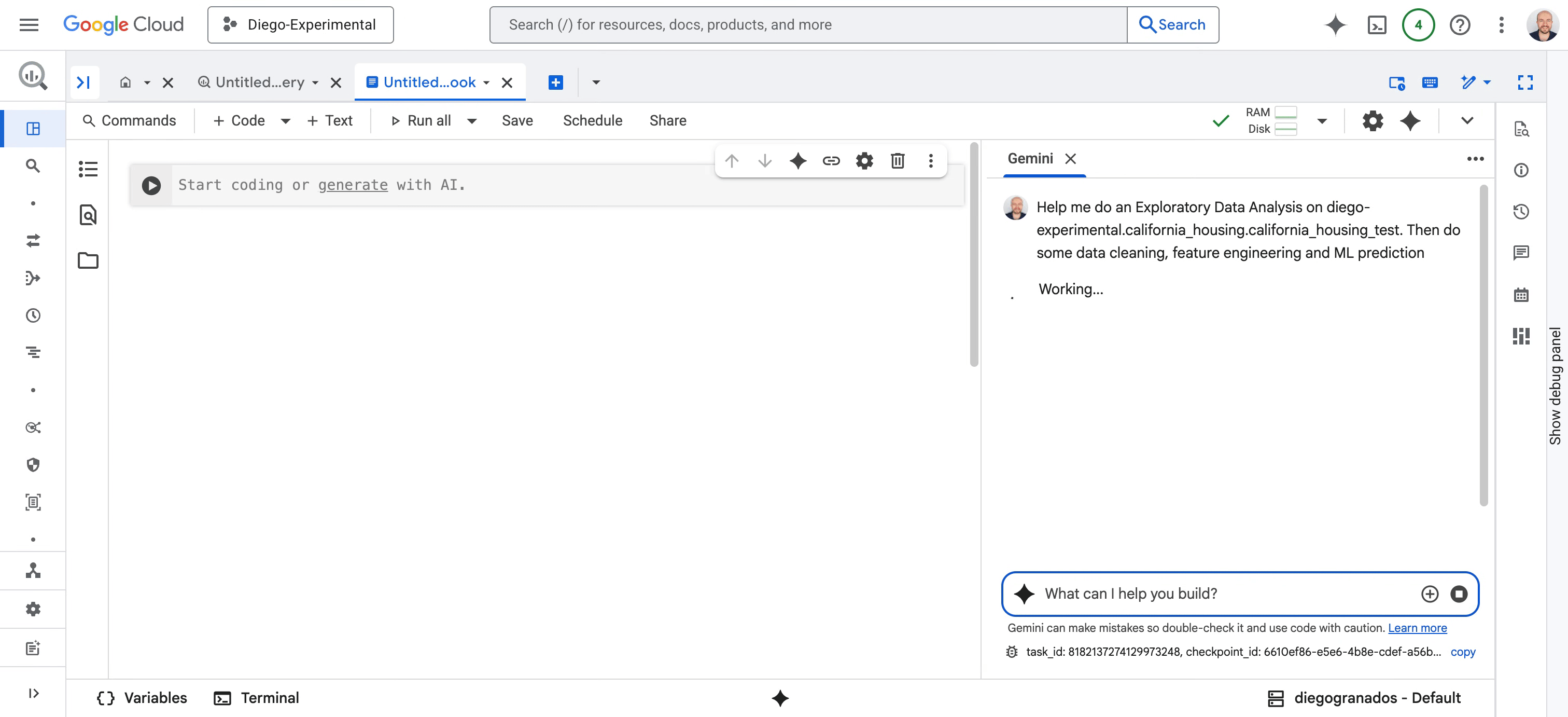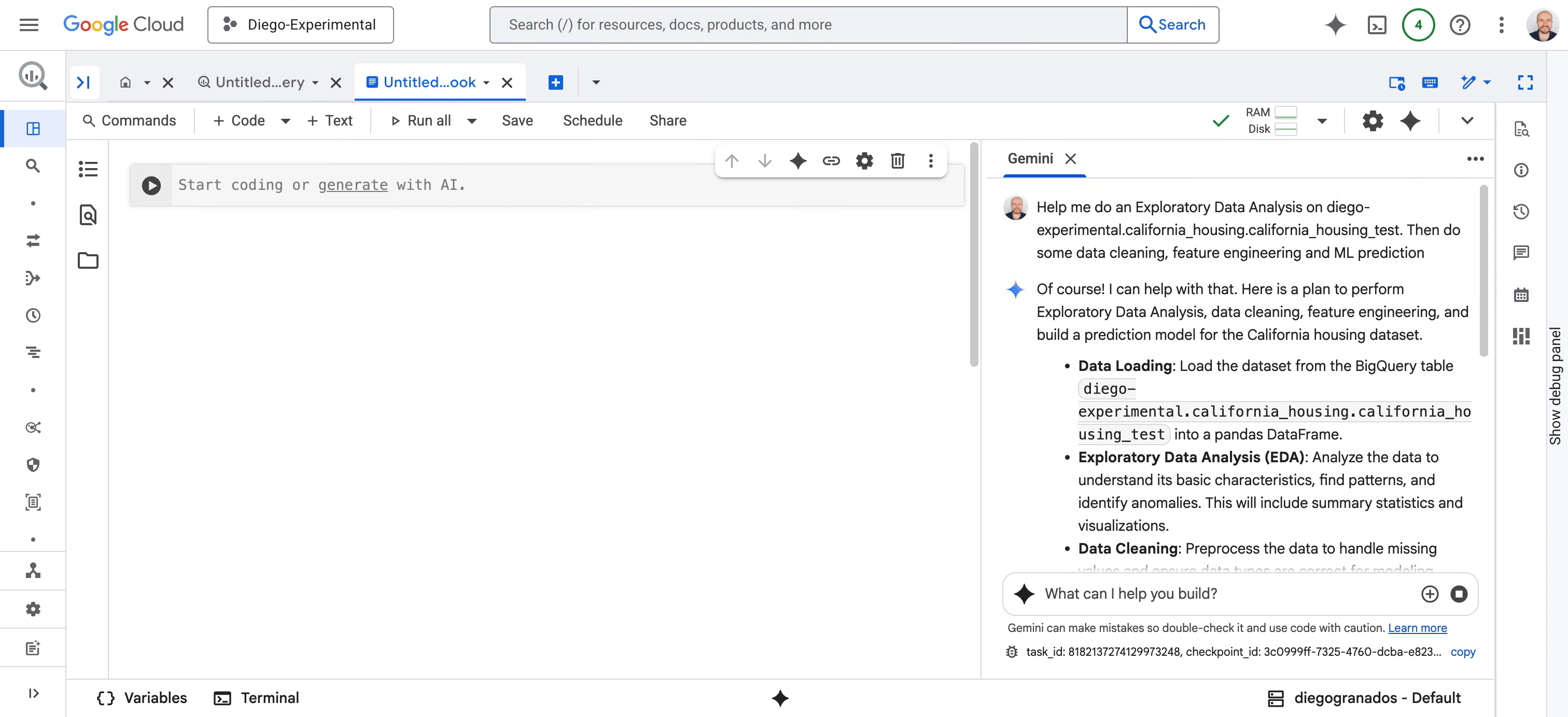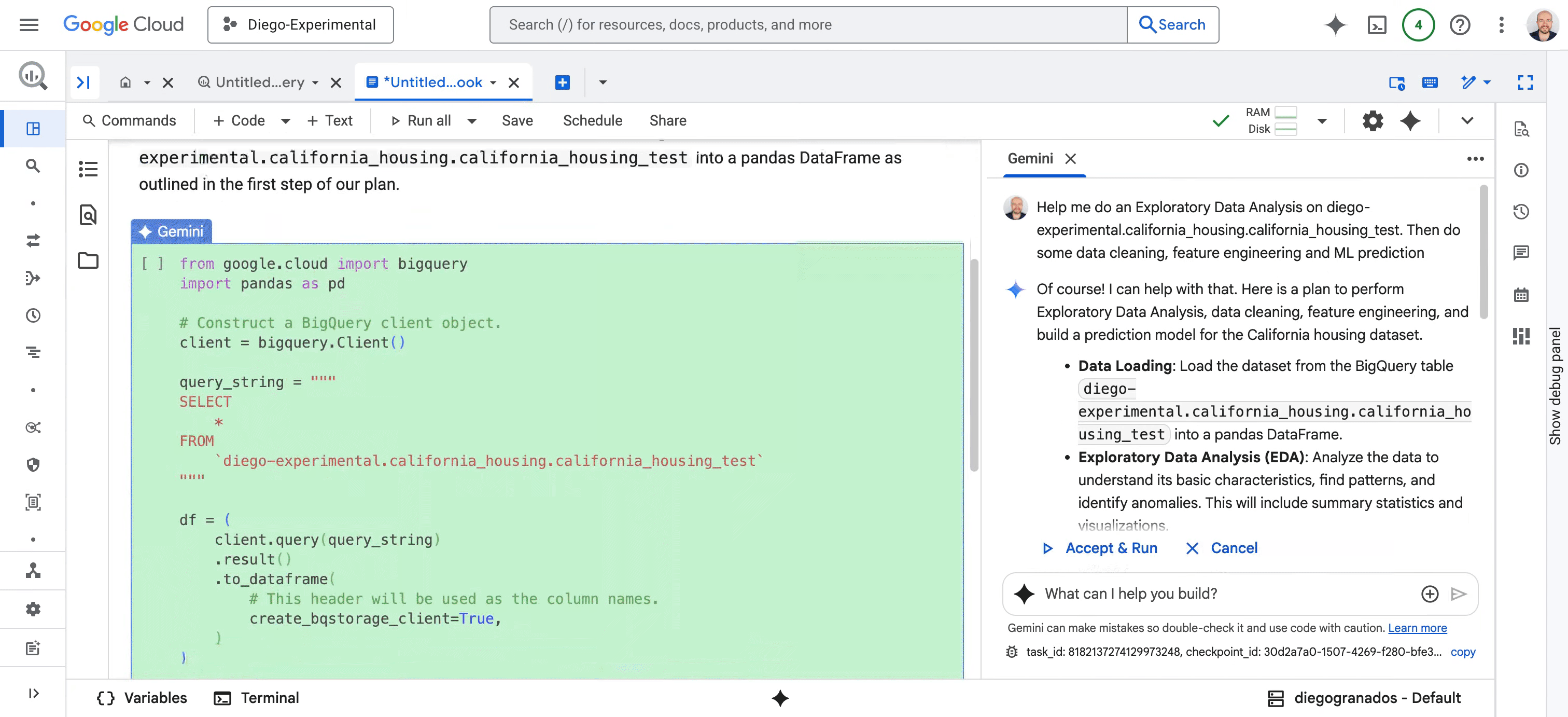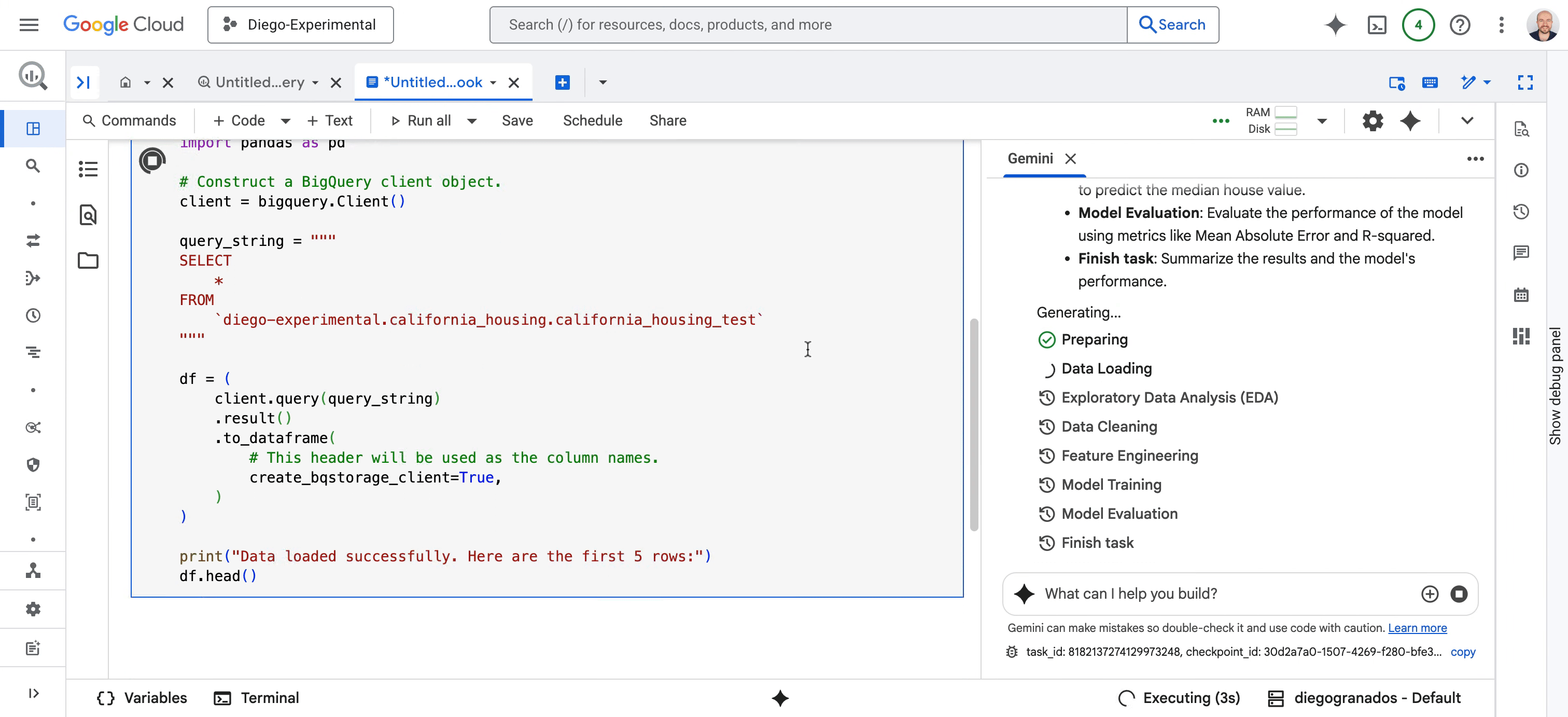
Fig. 2 – Data science agent métamorphose chaque étape des tâches de science des données
* Pour les utilisateurs métiers et les analystes : l’an dernier, nous avions lancé le Conversational Analytics Agent, permettant d’interroger ses données en langage naturel. Place désormais à Code Interpreter, pensé pour répondre aux questions stratégiques qu’une requête SQL simple ne suffit pas à résoudre. Par exemple : « Réaliser une analyse de segmentation client pour regrouper les clients en cohortes distinctes ». Grâce au raisonnement avancé de Gemini 2.5 et au savoir-faire de DeepMind, l’agent Code Interpreter traduit des questions en langage naturel en code Python exécutable, explique clairement chaque étape et génère des visualisations interactives. out ça, directement dans l’environnement gouverné et sécurisé de Google Data Cloud.
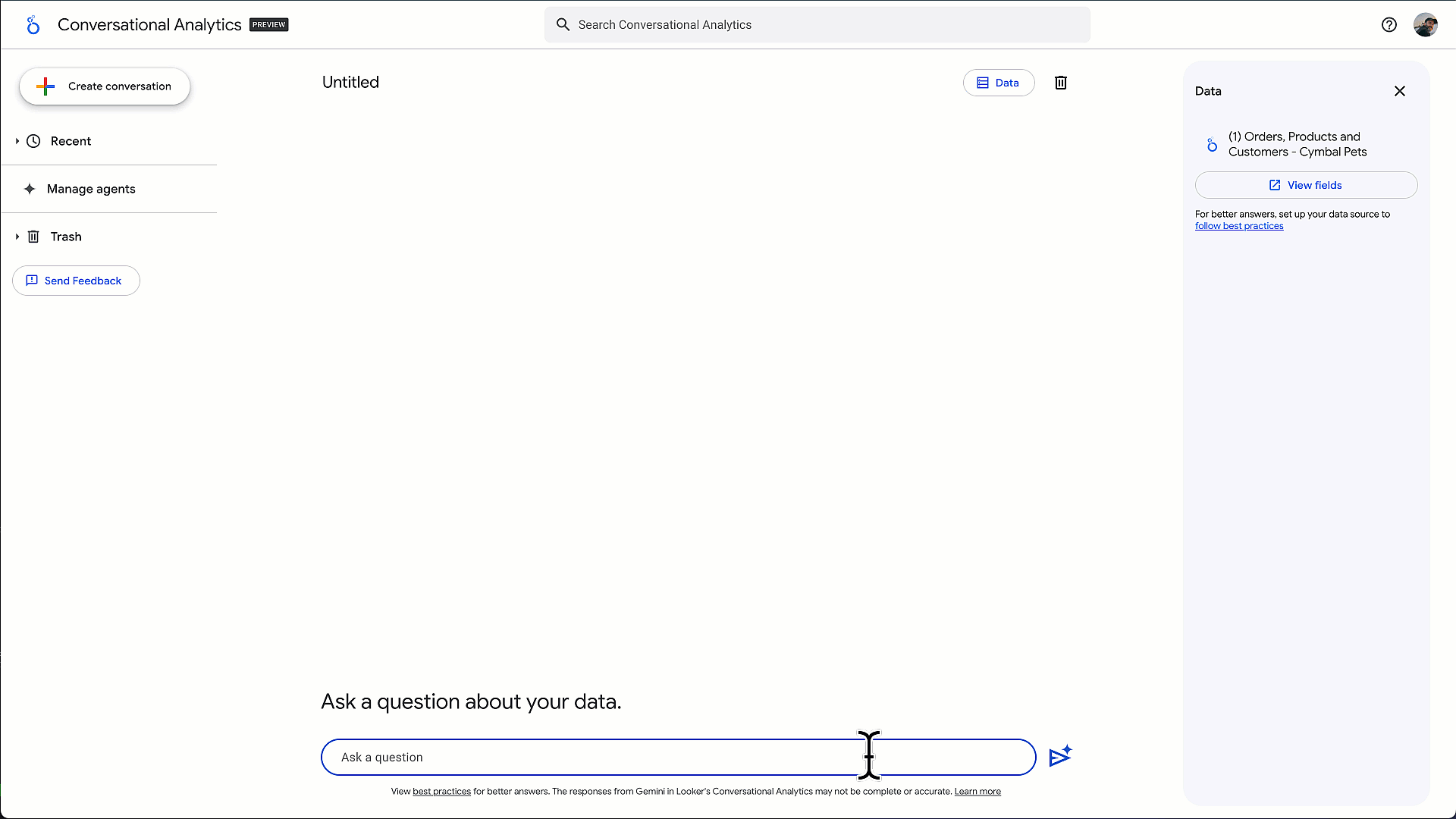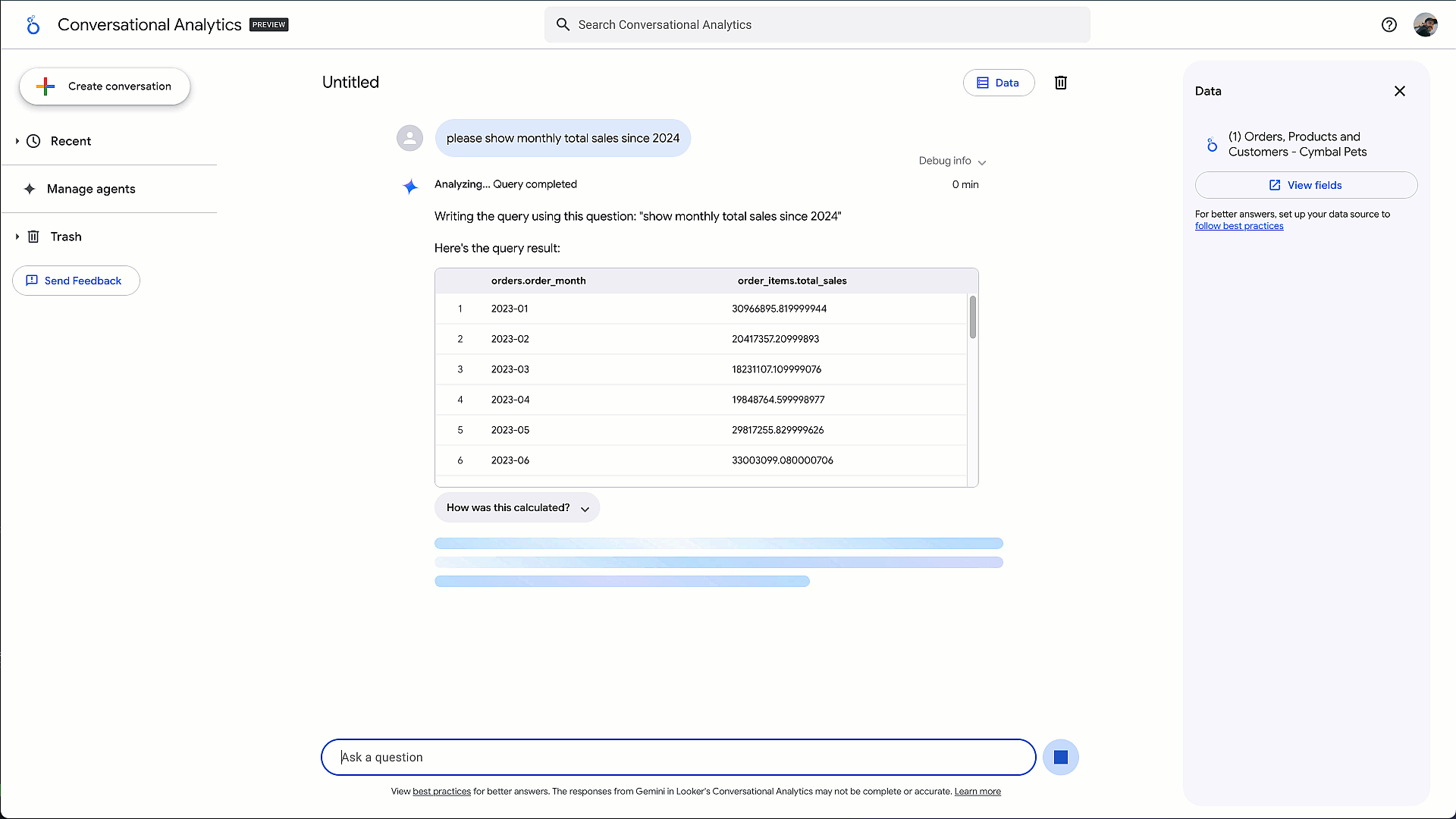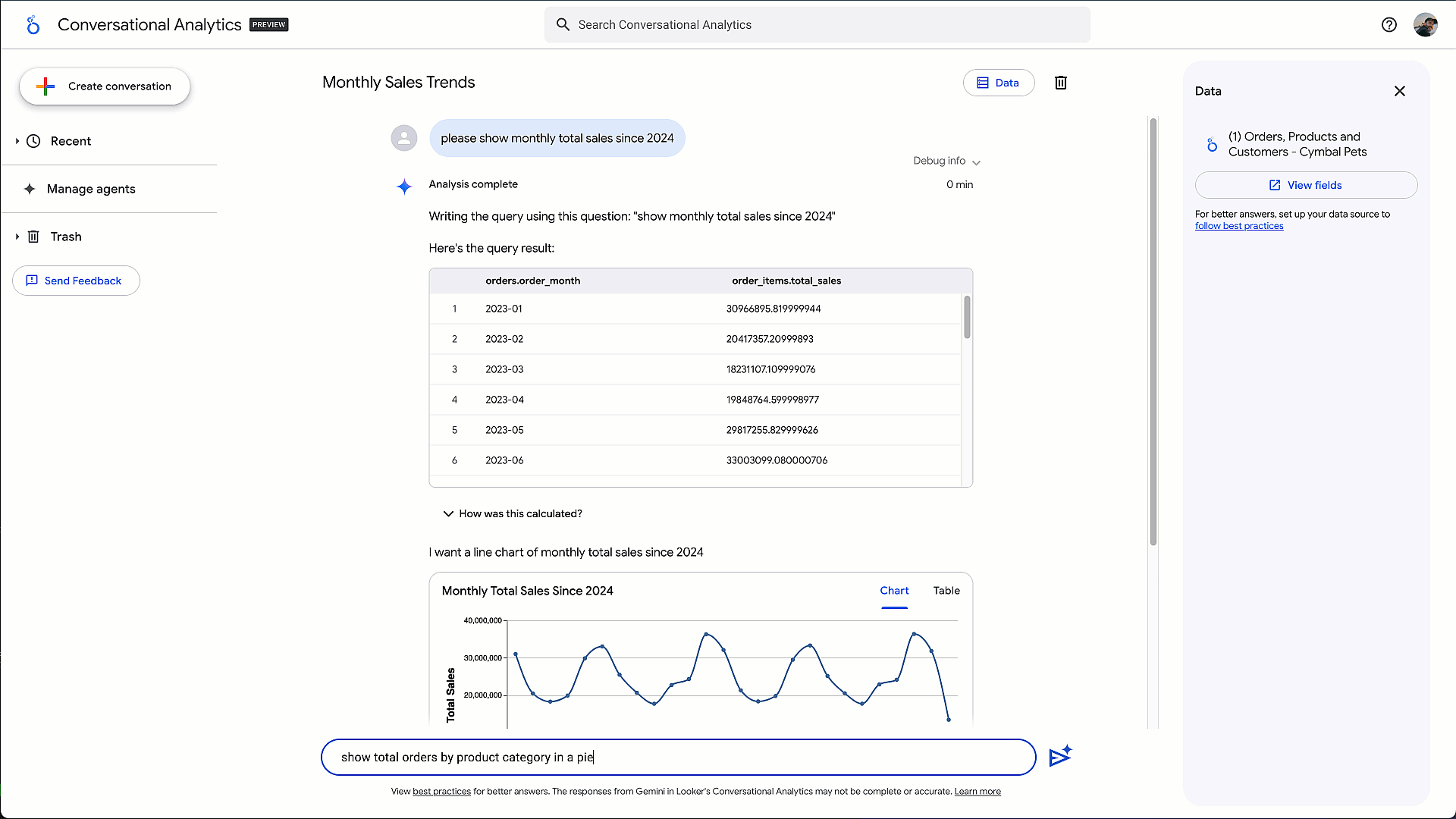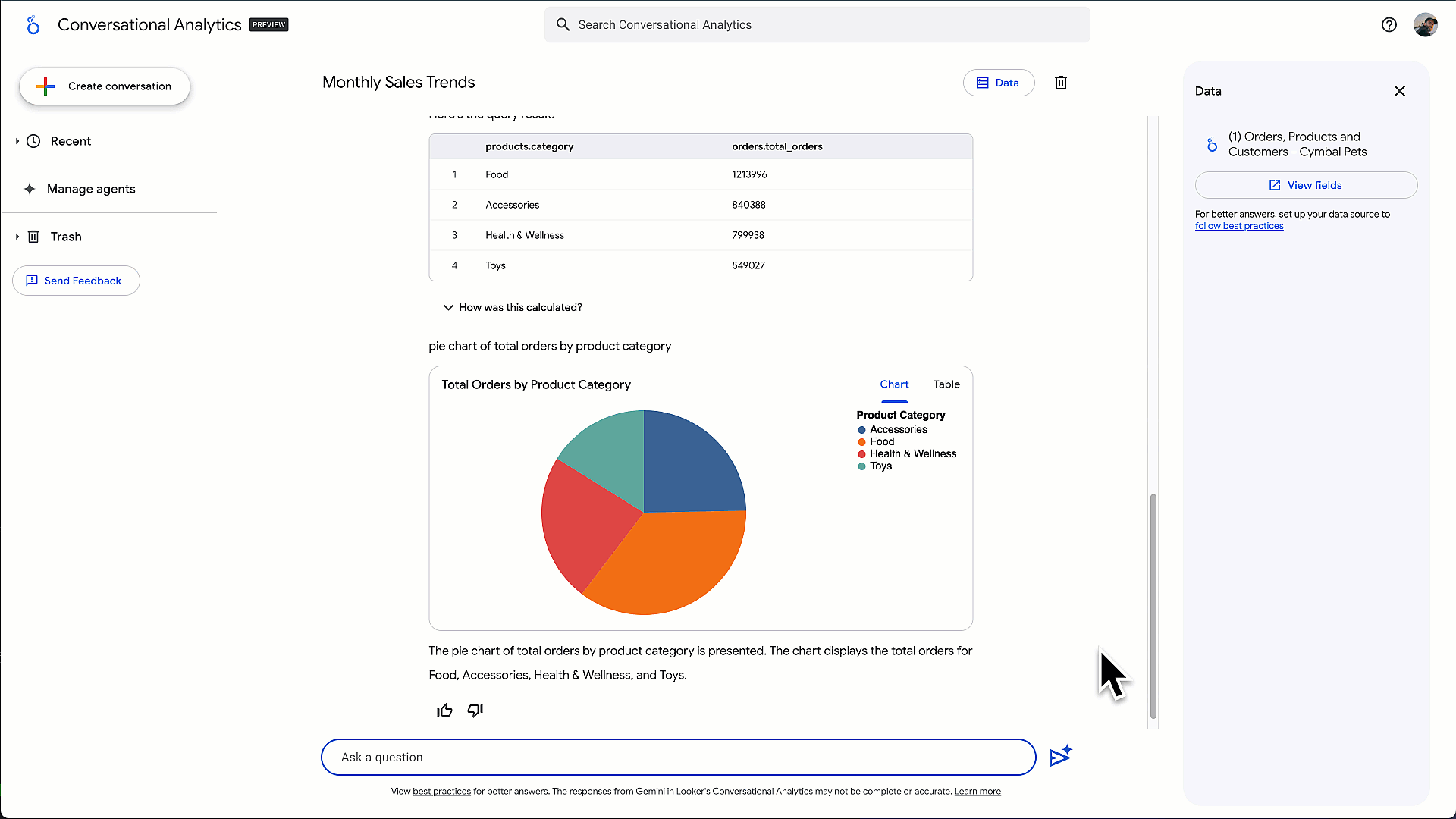
Fig. 3 – Exemple de BI conversationnelle avec Code Interpreter pour des analyses avancées
Construire un écosystème d'agents IA interconnectés
Imaginez un monde où les agents intelligents ne travaillent pas en vase clos, mais se connectent, s’enrichissent mutuellement et s’intègrent à vos propres outils. Google Cloud propose une plateforme ouverte où les développeurs ne se contentent pas d’utiliser ce qui existe, mais créent des liens, ajoutent leurs briques et bâtissent un réseau plus vaste et puissant d’agents collaborants.
Nos agents propriétaires offrent des fonctionnalités puissantes, prêtes à l’emploi, ainsi que des éléments fondamentaux — API, outils et protocoles — permettant de créer des agents personnalisés, d’intégrer l’intelligence conversationnelle dans des applications existantes et d’orchestrer des flux de travail complexes, multi-agents, capables de résoudre des problématiques métier uniques.
Et pour concrétiser cette vision, nous lançons les Gemini Data Agents APIs, dont la première est la nouvelle Conversational Analytics API. Cette API fournit les briques nécessaires pour intégrer directement dans vos applications, produits et workflows, les puissantes capacités de traitement du langage naturel de Looker ainsi que celles de l’agent Code Interpreter. Elle permet ainsi de créer des expériences data uniques, taillées pour vos besoins métiers spécifiques.
Il est temps d’aller plus loin que les simples expériences conversationnelles : place à la création d’agents sur mesure, bâtis de toutes pièces. Avec la Data Agents API et l’ADK (Agent Development Kit), les entreprises peuvent façonner des agents spécialisés qui épousent leurs propres processus métier. Le tout repose sur un socle de confiance solide et sécurisé : le Model Context Protocol (MCP), renforcé par notre boîte à outils MCP Toolbox for Databases et par notre nouveau Looker MCP Server.
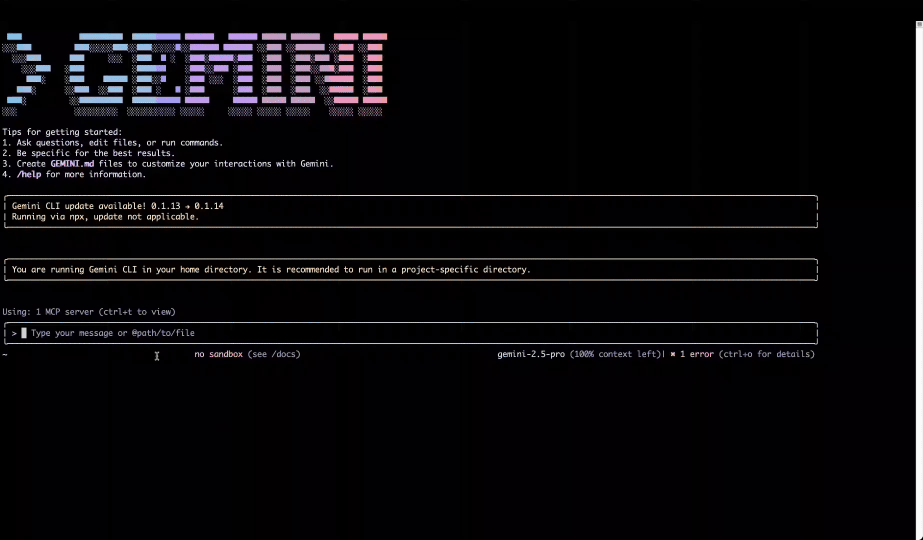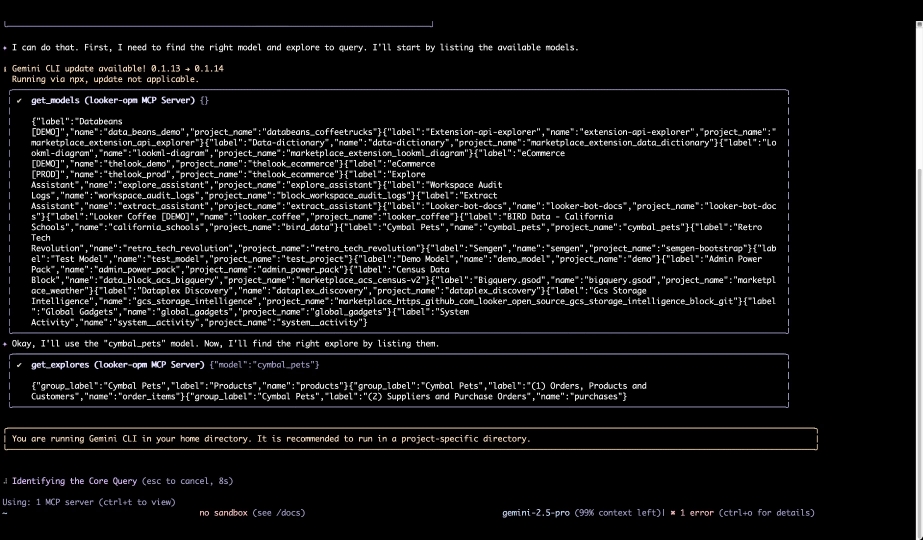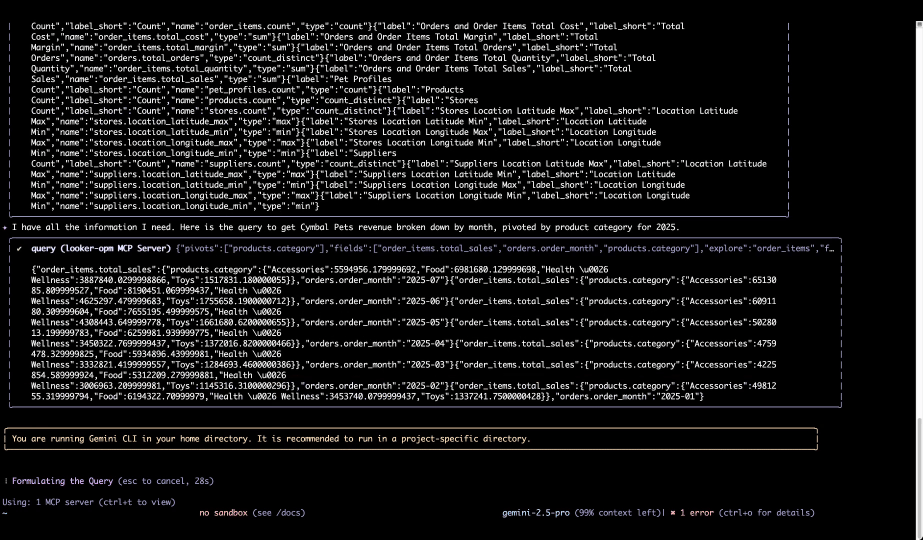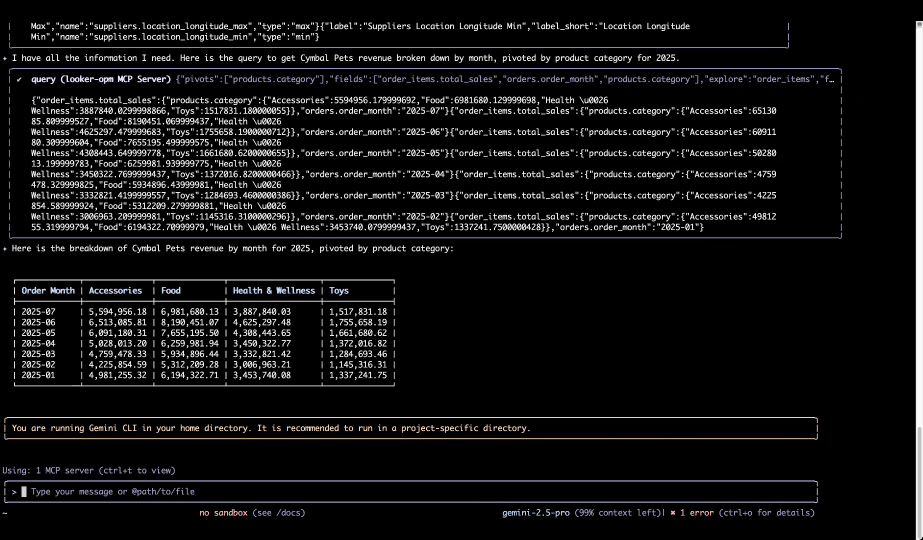
Une base de données unifiée et native à l’IA
Les agents intelligents, ainsi que les réseaux qu’ils forment, ne peuvent se contenter d’une infrastructure de données traditionnelle. Ils ont besoin d’un socle “cognitif” qui rassemble toutes les données de l’entreprise, offre de nouvelles capacités pour comprendre le sens et procure une mémoire persistante sur laquelle raisonner.
Pour que cette base « native IA » tienne toutes ses promesses, elle doit réconcilier données transactionnelles temps réel et données analytiques historiques et donc combiner systèmes OLTP et OLAP. Nous avons ouvert la voie avec un moteur en colonnes pour AlloyDB, qui a boosté l’analytique des workloads PostgreSQL.
Aujourd’hui nous franchissons un nouveau cap de performances : avec notre nouveau moteur colonnaire pour Spanner (le Spanner Columnar Engine), notre base de données à très grande échelle, certaines requêtes analytiques s’exécutent jusqu’à 200 fois plus vite (que sur le stockage en ligne classique) directement sur vos données transactionnelles.
Dans le cadre de notre Data Cloud unifié, cette innovation profite aussi directement à notre moteur analytique Data Boost dans BigQuery, qui exploite le moteur colonnaire de Spanner pour réduire l’écart entre charges transactionnelles et analytiques et accélérer l’analyse des données opérationnelles en temps réel.
Un tel plan de données unifié en place, un autre enjeu clé demeure : doter les agents IA d’une mémoire solide, enracinée dans les faits de l’entreprise. Pour être fiables et éviter les hallucinations, ces derniers doivent s’appuyer sur le RAG (Retrieval-Augmented Generation). Son efficacité dépend d’une recherche vectorielle capable de naviguer aussi bien dans les données opérationnelles en temps réel que dans les archives analytiques profondes. C’est pourquoi nous avons intégré ces capacités de recherche et de génération directement au cœur de nos fondations data : vos agents peuvent ainsi puiser, en un instant, dans toute la mémoire transactionnelle et analytique de l’entreprise.
Optimiser la recherche vectorielle est un vrai casse-tête : son usage implique souvent de douloureux compromis entre vitesse, précision et complexité opérationnelle. Dans AlloyDB AI, de nouvelles fonctionnalités, comme le filtrage adaptatif (Preview) résolvent ce défi pour la mémoire transactionnelle, en maintenant automatiquement les index vectoriels et en optimisant les requêtes rapides sur les données opérationnelles en temps réel.
Parallèlement, pour offrir une mémoire analytique plus profonde, nous introduisons des vector embeddings autonomes et la génération dans BigQuery. Désormais, BigQuery peut automatiquement préparer et indexer des données multimodales pour la recherche vectorielle, une étape essentielle pour construire une mémoire sémantique riche et durable pour vos agents IA.
Enfin, par‑dessus ces données unifiées et accessibles, nous intégrons directement des capacités de raisonnement de l’IA dans nos moteurs de requêtes. Avec le nouveau AI Query Engine dans BigQuery (Preview), tous les professionnels de la donnée peuvent exécuter des calculs enrichis par l’IA, aussi bien sur des données structurées que non structurées, directement au sein de BigQuery. Ils obtiennent ainsi rapidement et simplement des réponses à des questions subjectives et complexes, comme : « Parmi ces avis clients, lesquels semblent exprimer le plus de frustration ? »

AI Query Engine apporte la puissance des LLM (Large Language Models) directement dans SQL.
L’avenir est agentique
Toutes ces annonces — des agents spécialisés pour chaque utilisateur jusqu’à la fondation native IA qui les alimente — représentent bien plus qu’une simple feuille de route. Elles constituent les briques essentielles d’une nouvelle entreprise « agentique ». Désormais, toute une main-d’œuvre d’agents intelligents peut collaborer dans un réseau ouvert, interconnecté et s’appuyer sur un cloud unifié qui gomme la frontière entre données opérationnelles et analytiques. Vous disposez ainsi d’une plateforme qui vous met en position d’innovateur, pas seulement d’intégrateur.
C’est une rupture majeure : l’analyse des données ne repose plus sur les seuls efforts humains, mais sur un puissant partenariat entre vos équipes et des agents IA.
L’ère agentique est là. Nous avons hâte de voir ce que vous en ferez — et vous invitons à embarquer dans ce passionnant voyage dès aujourd’hui pour redéfinir les possibles de la donnée.
