Des indicateurs fiables grâce à l’automatisation de la qualité des données
Sandeep Karmarkar
Product lead
Contactez-nous
Si vous êtes une entreprise et que vous souhaitez vous développer, découvrez comment gagner en productivité avec Google Cloud ou contactez notre équipe commerciale.
Commencer iciDataplex s’enrichit deux nouvelles fonctionnalités pour automatiser la qualité des données (AutoDQ) et le profilage (Data Profiling). Elles sont toutes deux disponibles en version preview publique dès aujourd’hui.
Dataplex est une « smart data fabric » qui permet d’unifier vos données distribuées et de gérer, surveiller et gouverner la data à grande échelle. Au sein de cette « fabric », AutoDQ permet de définir et mesurer la qualité des données. La fonctionnalité propose des recommandations de règles, du reporting intégré et une exécution en serverless pour garantir une haute qualité de données. Parallèlement, la nouvelle fonctionnalité de profilage de données (ou Data Profiling) offre une meilleure compréhension des données grâce à l’identification de caractéristiques communes.
Quand elles sont fiables et cohérentes, les données constituent un patrimoine inestimable pour les entreprises, en termes d’innovation mais aussi de prises de décision critiques et d’expériences client innovantes. À l’inverse, des données de mauvaise qualité peuvent entraîner l’inefficacité des processus et même des pertes financières.
La qualité des données était plus facile à gérer autrefois, quand « l’empreinte des données » était de plus faible taille (stockages et traitements limités à une zone géographique ou à une base par exemple) et que les consommateurs de données étaient moins nombreux. Les utilisateurs pouvaient s’entendre plus facilement pour définir des règles et les intégrer dans leurs analyses.
Mais les entreprises éprouvent désormais une difficulté grandissante à adapter ce processus manuel à l’augmentation des volumes et à la diversité croissante des données, sans oublier l’arrivée de nouveaux utilisateurs et la multiplication des cas d’usages. La difficulté est également accentuée par la prolifération de solutions de gestion de la qualité des données en interne qui rend la mise en place de règles de qualité communes et normalisées encore plus complexes. La plupart du temps, cet héritage sème de l’incohérence et de la confusion.
Avec Dataplex AutoDQ et Data Profiling, vous pouvez désormais mettre en place des solutions de nouvelle génération qui automatisent la création de règles et la gestion à grande échelle de la qualité des données. Les fonctionnalités de profilage permettent aussi d'améliorer la découverte et l'auditabilité des données.
Les principaux avantages de ces solutions sont :
Une approche intelligente et intégrée : avec AutoDQ et Data Profiling, la courbe d’apprentissage disparaît. La mise en place de règles est intuitive grâce aux recommandations et ne nécessite aucune configuration. De plus, les rapports « clé en main » fournis permettent de déployer sans effort un reporting standardisé.
Gestion de toutes les catégories de données sans générer de silos : AutoDQ et Data Profiling s’adaptent à tous les types de données, permettant ainsi aux producteurs de s’approprier la gestion de la qualité et aux consommateurs d’enrichir les rapports en fonction de leurs besoins métier spécifiques.
Automatisation à grande échelle : ces solutions sont conçues pour s’adapter automatiquement et de façon transparente à la volumétrie. Elles s’appuient sur les mécanismes de stockage d’attributs de Dataplex (l’Attribute Store de Dataplex qui permet de stocker ensemble métadonnées, règles de qualité et politiques de sécurité) afin d’adapter la définition et la supervision aux besoins, au fur et à mesure que la volumétrie augmente.
Ces fonctionnalités en mode preview constituent le socle d’un futur où la qualité fera partie intégrante de la découverte et de l’analyse de données au quotidien.
"Des données fiables sont incroyablement importantes pour notre prise de décision afin de conserver la confiance de nos clients. Les nouvelles fonctionnalités de qualité des données et de profilage de nouvelle génération de Dataplex nous offrent une automatisation et une intelligence qui nous permettent de simplifier nos processus actuels, de réduire le travail manuel et de normaliser la qualité des données grâce aux rapports et alertes intégrés." - Jyoti Chawla, directeur technique et responsable de l'architecture, CDO, Deutsche Bank.
"Nous utilisons des données sur l’énergie pour construire des modèles innovants de prévision de la puissance, de planification des ressources et de recommandations pour le marché de l'énergie. Pour valider les données d'entraînement et de prédiction, nous évaluons activement la fonction ‘Qualité automatique des données (AutoDQ)’ de Dataplex. Jusqu'à présent, nous avons été impressionnés par sa simplicité, son intuitivité et ses recommandations intelligentes". - João Caldas, responsable de l'analyse et de l'innovation à Casa dos Ventos.
Un modèle de données flexible
Ces nouvelles fonctionnalités de Dataplex s’appuient sur un modèle capable de s’adapter à de multiples catégories de données et différents types de déploiement, En tant qu’utilisateur, vous pouvez créer un ou plusieurs « data scans » pour une table.
Ces data scans :
sont de type « profilage des données » ou de type « qualité des données » ;
reposent entièrement sur une exécution serverless ;
peuvent être déclenchés à l’aide d’un scheduler (outil de planification) serverless intégré ou à la demande avec des schedulers externes ;
peuvent être exécutées de manière incrémentale (sur les données les plus récentes) ou sur l'ensemble des données ;
Et, si vous êtes un producteur de données, vous pouvez configurer la solution, de façon à publier les résultats dans le catalogue de données (fonctionnalité à venir prochainement !).
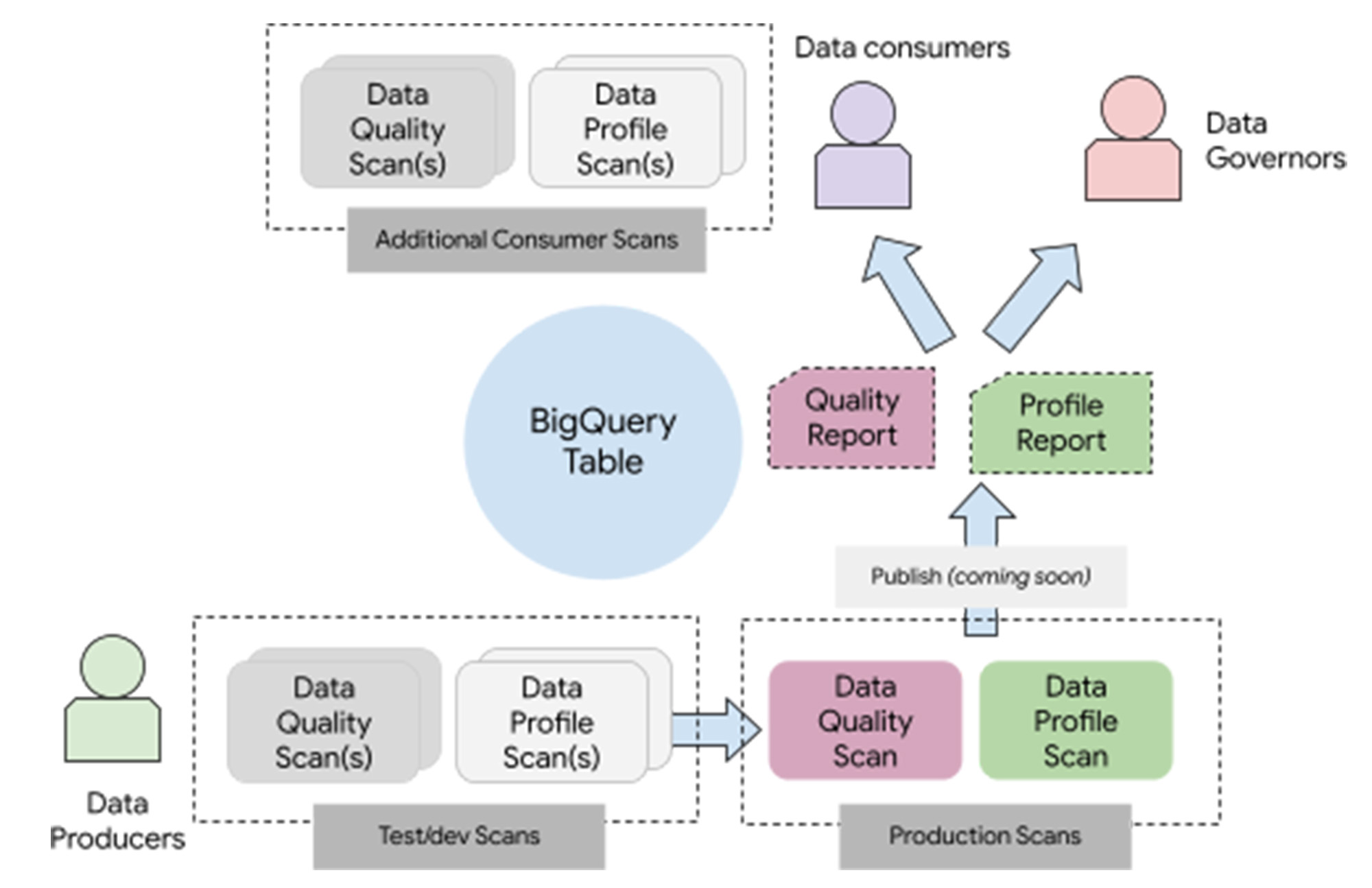
Avec ce modèle, les producteurs peuvent aisément créer et tester de nouveaux « data scans » avant de les passer en production en publiant les résultats. Les consommateurs peuvent exploiter les résultats publiés et ajouter leur propres « data scans » si nécessaire.
Ce modèle est enrichi « d’intelligence » et d’une interface utilisateur pensée pour un usage intuitif et une prise en main simplifiée.
Afin d’aller plus loin dans l’utilisation de ces nouvelles fonctionnalités, nous vous proposons un exemple d’application, basé sur « Taxi Trips » tiré des jeux de données publiques de BigQuery public datasets (source : -chicago-taxi-trips). Nous allons passer en revue les capacités de définition, d'exécution, de supervision et de dépannage des règles offertes par ces nouvelles fonctionnalités.
Profilage de vos données en quelques clics
Il suffit de quelques clics pour créer un scan de profilage de données pour cette table dans Dataplex. Les résultats du scan sont ensuite disponibles dans l'interface utilisateur et comprennent des statistiques et graphiques sur les colonnes. La capture d’écran suivante affiche par exemple le pourcentage de données Null, de données uniques et autres statistiques sur les colonnes, ainsi que les 10 valeurs les plus récurrentes de chaque colonne.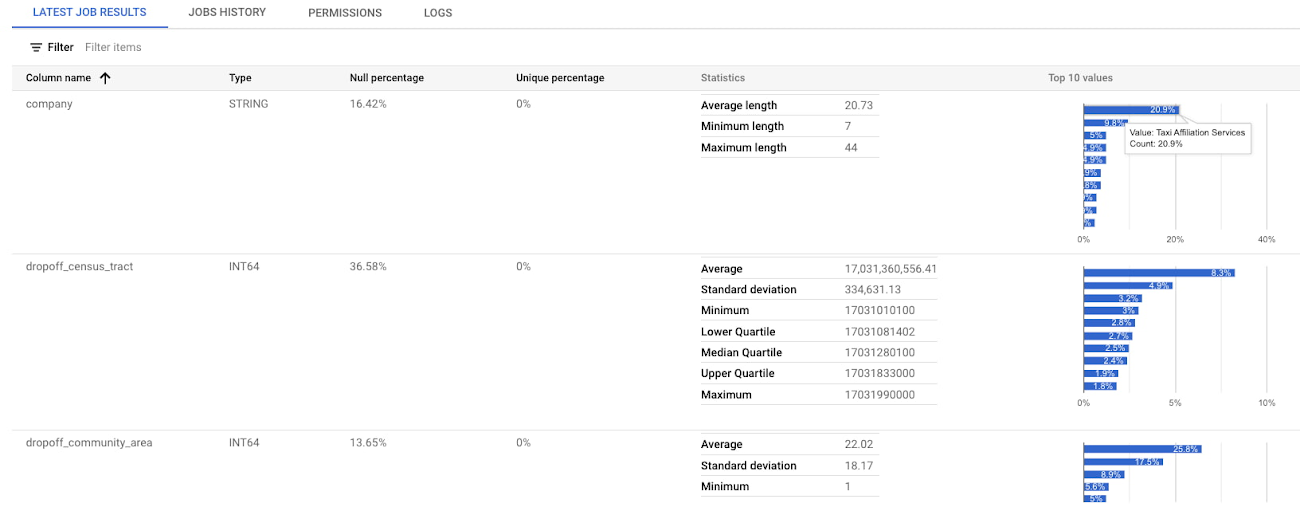
Obtenir des recommandations de règles pour gérer la qualité des données
Pour mettre en place un scan de qualité de données, nous proposons à la fois des recommandations de règles et une expérience visuelle de création de règles. Vous pouvez créer de nouvelles règles directement en code SQL ou en partant des quelques types de règles prédéfinies.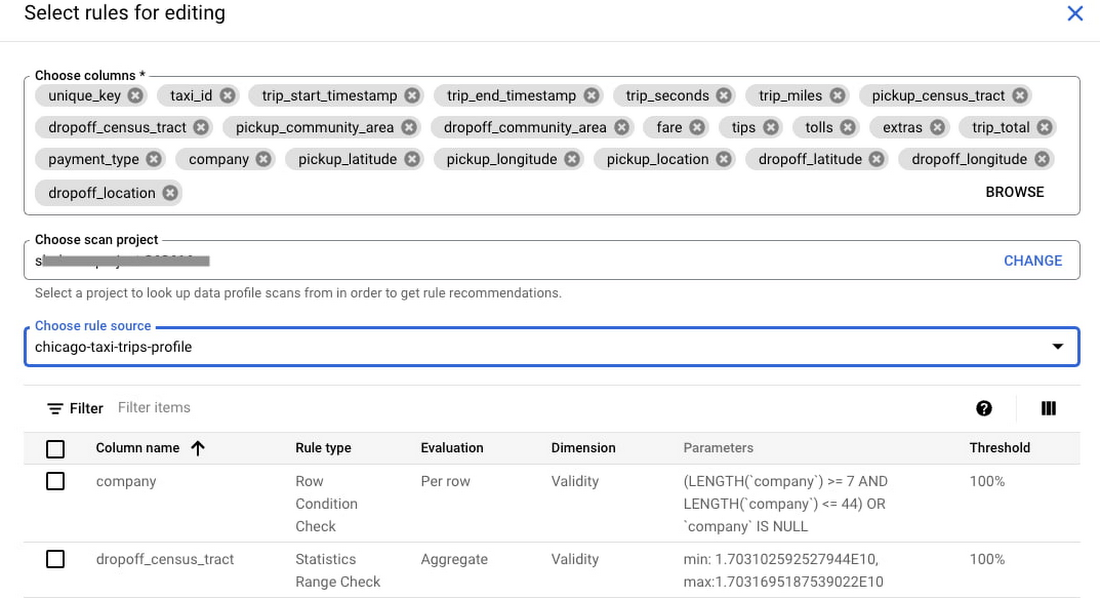
Notez que chaque règle est associée à une dimension « qualité des données » et possède un seuil de validation.
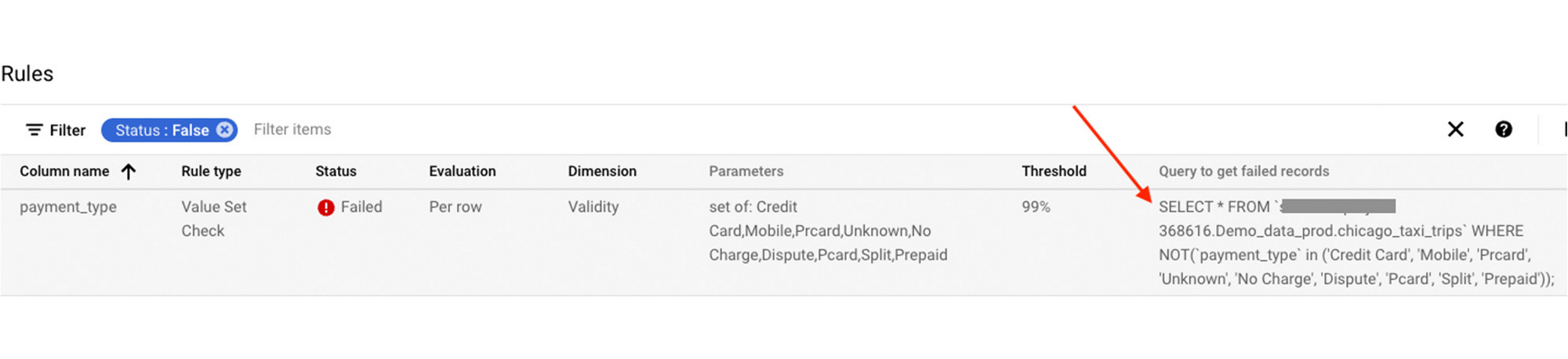
Par exemple, voici une règle recommandée qui reconnaît que payment_type doit absolument adopter l'une des quelques valeurs automatiquement détectées dans la colonne.

Une exécution sans copie des données
Les contrôles de qualité des données sont exécutés de la manière la plus performante directement sur les ressources internes Bigquery, et aucune copie de données n'est pratiquée lors de l'exécution de ces requêtes.
Visualisation des rapports dans Dataplex
Vous pouvez planifier ces contrôles de qualité directement dans Dataplex ou les exécuter à l’aide de schedulers externes. Dans les deux cas, les résultats s’affichent dans Dataplex sous forme d'un rapport sur la qualité des données.
Un tableau de bord permet de visualiser les exécutions (7 dans notre exemple) :
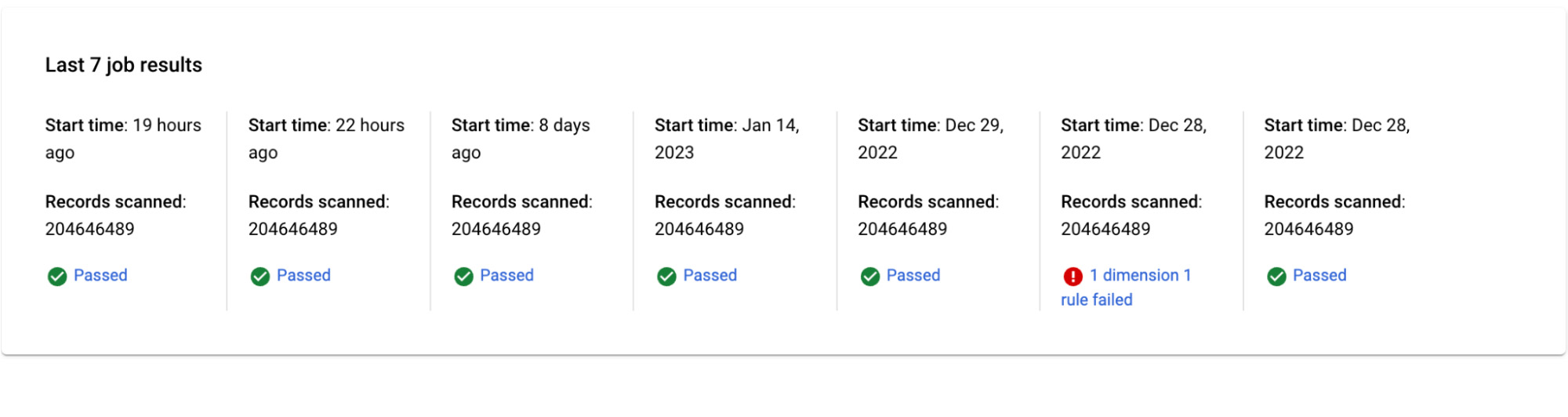
Vous pouvez également effectuer des recherches dans les exécutions précédentes.
Les règles utilisées pour chaque exécution sont conservées.
Définir des alertes avec Google Cloud Logging
Les scans de qualité des données génèrent des entrées dans les journaux Google Cloud sur lesquelles vous pouvez vous appuyer pour définir des alertes en cas d’échec d’un scan spécifique ou d’échec sur une dimension particulière. Votre alerte, communiquée par email, pourrait ressemble à ceci :
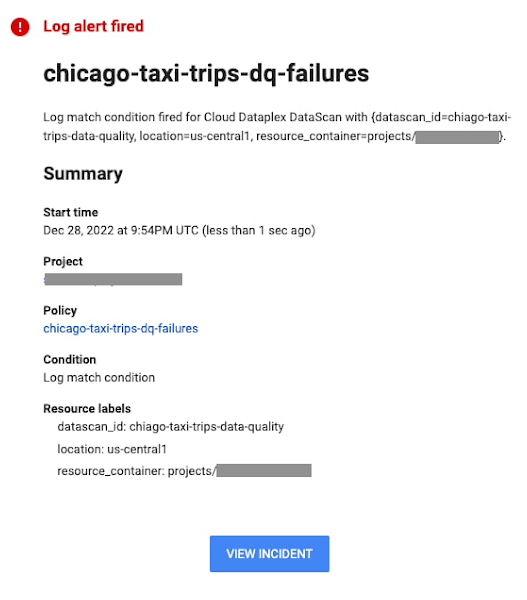
Résolution des problèmes
Pour résoudre un problème sur une règle de qualité en échec, nous accompagnons les utilisateurs en proposant automatiquement une requête SQL permettant de retrouver les enregistrements qui ont provoqué cet échec (autrement dit, les enregistrements qui ne respectent pas la règle de qualité).
Pour plus d’information, reportez-vous à :
