Optimisez vos applications avec Google Vertex AI Vizier

Laurent Querel
Distinguished Engineer - F5
Sebastien Soudan
Senior Architect - F5
Vos questions, nos réponses
Où que vous en soyez dans votre parcours Google Cloud ou Google Workspace, nous aimerions avoir vos avis dessus. Soumettez vos questions ici pour avoir la chance de figurer sur notre blog.
SoumettreLes innovations en intelligence artificielle (IA) et en apprentissage machine (ML) profitent aujourd’hui aux entreprises du monde entier. Chez F5, nous utilisons beaucoup l'IA et le ML pour améliorer la sécurité des données, la détection des fraudes ou encore la prévention des attaques de robots, avec des bénéfices à la clef clairement identifiés. Nous utilisons également l'IA et le ML pour optimiser l’ingénierie logicielle.
L’utilisation de l’IA et du ML dans l’ingénierie logicielle en est encore à ses balbutiements. On commence à voir apparaître des cas d’usage autour de la programmation assistée par l’IA (code completion) ou encore autour de la génération automatique de code par les solutions no-code/low-code. Mais, pour l’instant, l’utilisation de l’IA et du ML pour optimiser l’architecture d’une application logicielle reste encore peu répandue. Dans ce billet, nous allons aborder l’amélioration d’un workload de pipeline de données en utilisant les principes d’optimisation d’une « Black-Box » à l’aide de Vertex AI Vizier de Google.
Pour rappel, on appelle « boîte noire » ou « black-box » le principe qui consiste à observer le comportement d’une tâche informatique à travers les résultats qu’elle produit et en fonction de différents paramètres donnés en entrée. Un tel principe est utilisé lorsqu’il n’est pas possible d’accéder à son fonctionnement interne. Les techniques BBO (Black-Box Optimization) cherchent à optimiser le fonctionnement de telles tâches dont on ne peut influer sur la conception mais dont le comportement peut varier en fonction de paramètres passés en entrée. L’optimisation de grands réseaux de neurones est un exemple typique de BBO.
Optimisation des performances
Processus itératif et essentiellement manuel, l'optimisation logicielle repose aujourd’hui surtout sur des « profileurs » (ou outils de profiling) qui identifient les goulots d'étranglement au sein du code source. Ces profileurs mesurent les performances et génèrent des rapports, utilisés ensuite par les développeurs pour optimiser leur code. Cette approche manuelle présente un inconvénient majeur : l’optimisation repose sur les compétences et l’expérience du développeur. Elle est donc très subjective. De plus, le processus est lent, non-exhaustif, et l’optimisation peut comporter des erreurs ou être sujette aux préjugés humains. La nature distribuée des applications cloud natives complique encore le processus d'optimisation manuelle.
En ingénierie de la performance, il existe une autre approche plus globale quoiqu’encore sous exploitée : elle repose sur les expérimentations de performance et les algorithmes d’optimisation des boîtes noires (algorithmes BBO). L’objectif consiste à optimiser le coût opérationnel d’un système complexe doté d’une multitude de paramètres. Signalons qu’il existe d’autres techniques d’optimisation des performances basées sur l’expérimentation, tel le profilage causal (Causal Profiling), mais elles sortent du cadre de cet article.
Un processus BBO d’optimisation des performances est par nature itératif et automatisé, comme l’illustre la figure 1. Une succession d'essais contrôlés est réalisée sur un système pour étudier la valeur d’une fonction « coût » caractérisant le système à optimiser. De nouveaux paramètres possibles sont générés et d’autres essais sont réalisés jusqu’à ce que l’amélioration soit trop infime pour être rentable (cf plus loin).
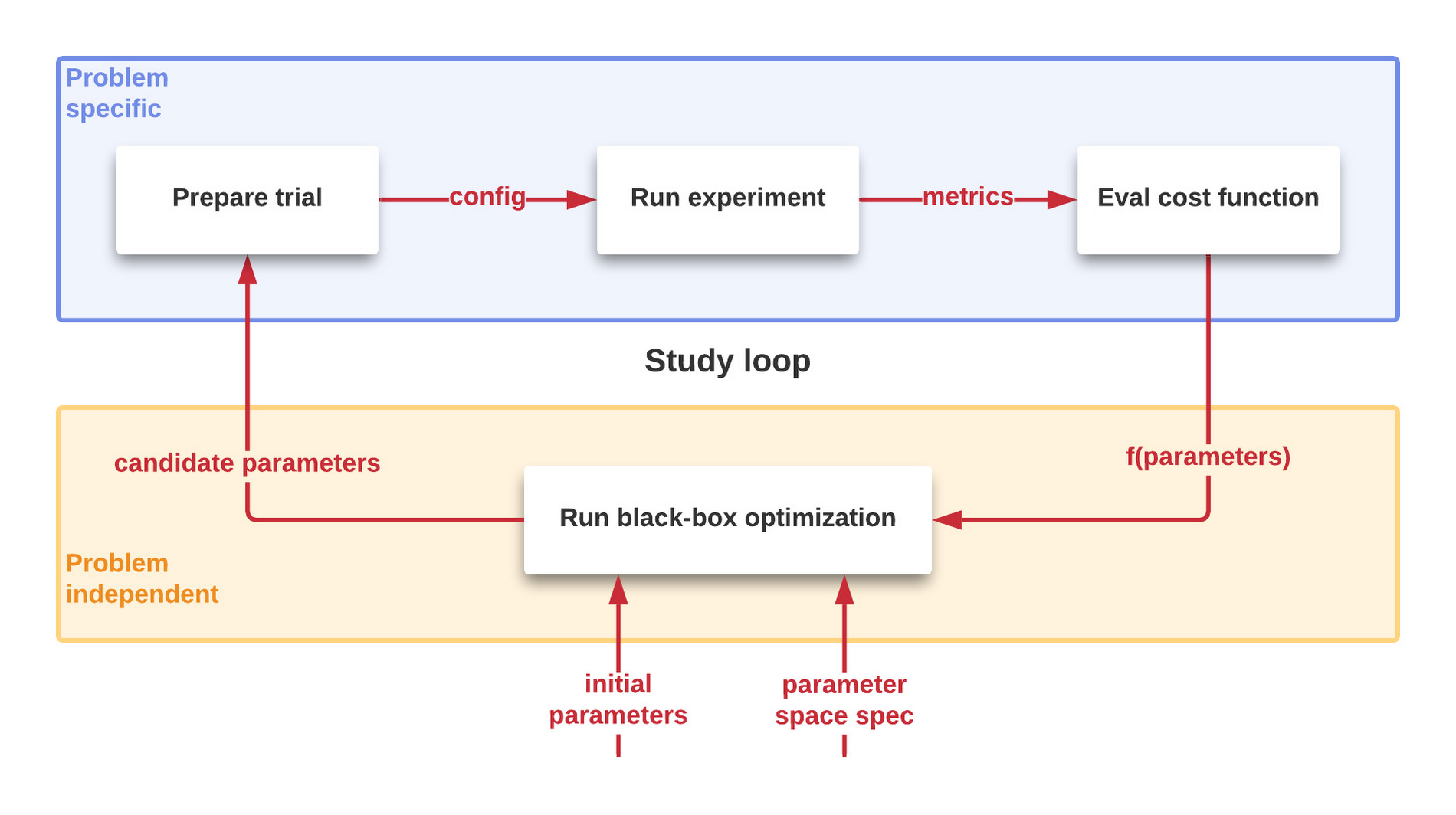
Figure 1 : Optimisation en Boîte Noire : des expérimentations successives pour arriver à un résultat optimal sur une fonction “côut”
Quel est le problème ?
Commençons par planter le décor – inspiré en partie de notre propre expérience mais aussi en partie fictif pour mieux illustrer le propos.
Notre objectif ici est de construire un moyen efficace de transférer des données de PubSub vers BigQuery. Google Cloud propose un service entièrement managé de traitement des données, Dataflow, pour l'exécution d'une grande variété de modèles de traitement des données, que nous utilisons pour de nombreux autres besoins de streaming en temps réel.
Dans le cadre de cet article, nous avons choisi de tirer parti d'un processeur de flux personnalisé simplifié - une sorte de modèle "E(t)LT" - afin de traiter et de transformer les données tout en bénéficiant de l'orientation "en colonnes" de BigQuery.
La configuration mise en œuvre est illustrée plus en détail figure 2. Le notebook central joue le rôle d'orchestrateur pour l'étude du "système à optimiser". Les principaux objectifs (et composants impliqués) sont les suivants :
Reproductibilité : en plus d'un processus automatisé, un snapshot pub/sub est utilisé pour initialiser un abonnement spécifiquement créé pour alimenter le processeur de flux afin de reproduire les mêmes conditions pour chaque expérience.
Évolutivité : Vertex AI Workbench met en œuvre un ensemble de procédures automatisées utilisées pour exécuter plusieurs expériences en parallèle avec différents paramètres d'entrée afin d'accélérer le processus d'optimisation global.
Déboguabilité : pour chaque expérience, les identifiants de l'étude et de l'essai sont systématiquement injectés comme étiquettes pour chaque log et métrique produits par le processeur de flux. De cette façon, nous pouvons facilement isoler, analyser et comprendre les raisons de l’échec ou de résultats surprenants ou incohérents d'une expérience.
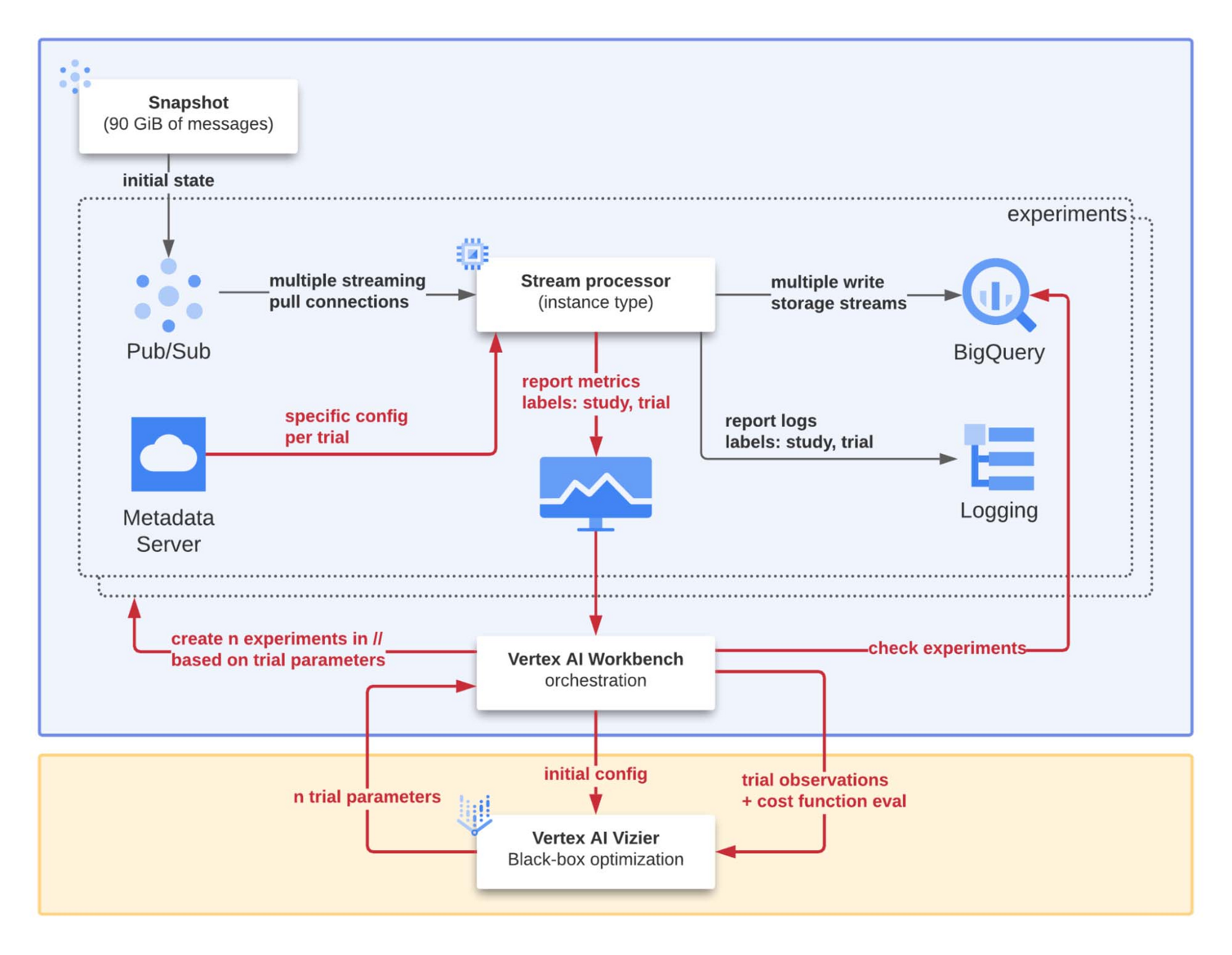
Pour transférer efficacement les données de PubSub vers BigQuery, nous avons conçu et développé un code que nous voulons maintenant affiner pour qu'il soit le plus performant possible. Nous disposons d'un programme que nous voulons l'optimiser en nous basant sur des mesures de performance faciles à obtenir en l'exécutant. Notre question est maintenant de savoir comment sélectionner la meilleure variante.
Sans surprise, il s'agit là d'un problème typique d'optimisation : le monde en est rempli ! Essentiellement, ces problèmes consistent à optimiser (minimiser ou maximiser) une fonction « objectif » sous certaines contraintes et à trouver où les minima ou maxima se produisent.
De telles pratiques d’optimisation sont applicables à de nombreux domaines.
La formule est classique :
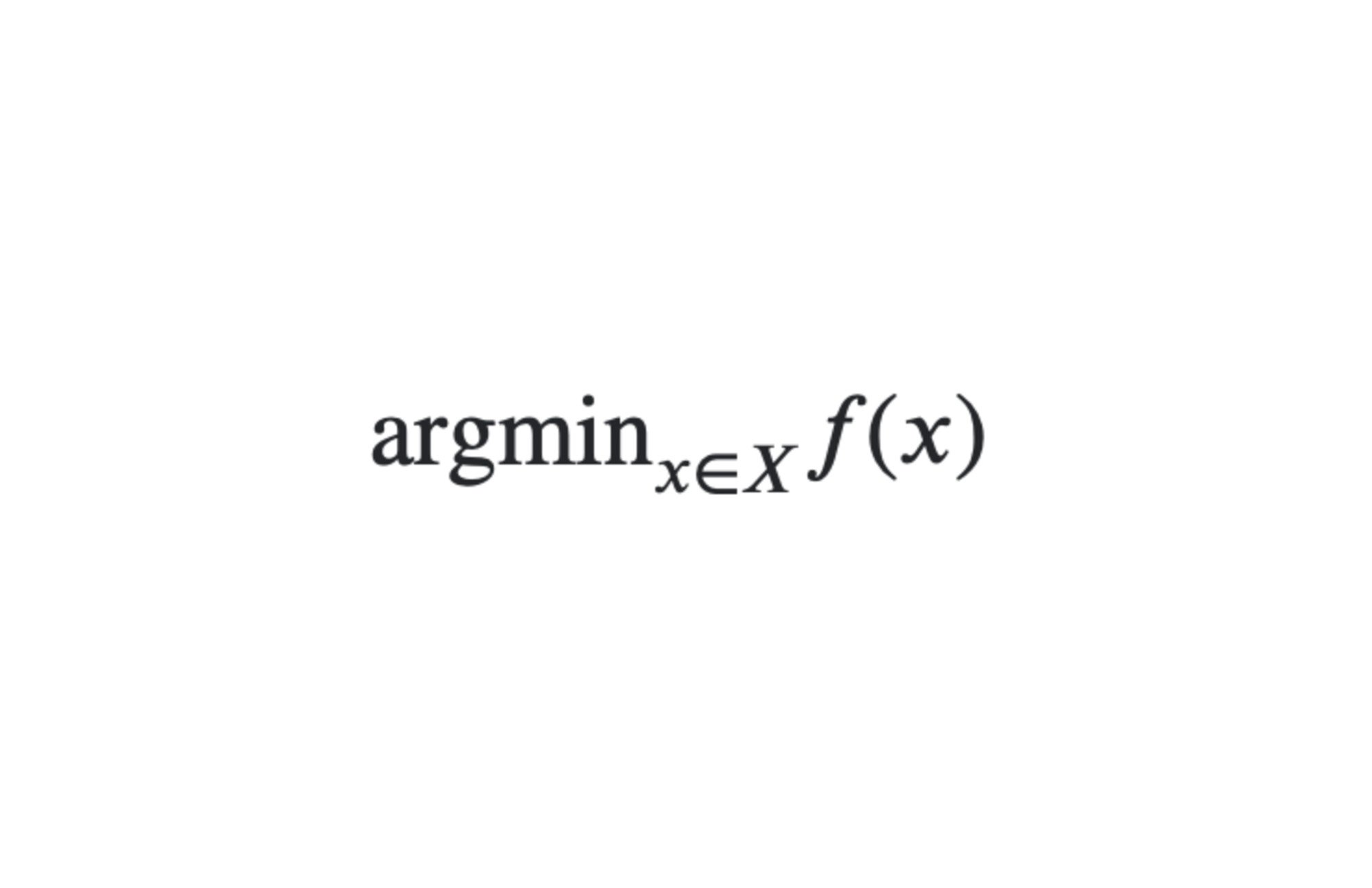
En d'autres termes, nous voulons les x d'un certain domaine X qui minimisent une fonction « coût » f. Comme il s'agit ici d'un problème de minimisation, de tels x sont appelés minima. Les minima n'existent pas nécessairement et lorsqu'ils existent, ils ne sont pas nécessairement uniques.
Bien sûr, tous les problèmes d'optimisation ne sont pas égaux : la programmation linéaire et continue est "facile", l'optimisation convexe est aussi relativement facile, mais l'optimisation combinatoire est un art plus complexe... Elle présuppose que l’on puisse décrire la fonction « objectif » que nous voulons optimiser - même partiellement, par exemple en étant capable de calculer les gradients.
Dans notre cas, la fonction « objectif » (autrement dit la fonction qui modélise l’objectif recherché) est une certaine performance (qui reste encore à déterminer à ce stade) d'un programme dans un certain environnement d'exécution.
On est donc loin ici d’un classique « f(x)=x2 » : nous n'avons pas d'expression analytique pour la performance de notre programme, pas de dérivées, aucune garantie que la fonction est convexe, l'évaluation est coûteuse et l'observation peut être « bruitée ».
Ce type d'optimisation est appelé « optimisation en boîte noire » pour la raison que nous ne pouvons pas décrire notre fonction « objectif » en termes mathématiques simples. Néanmoins, nous sommes très intéressés par la recherche des paramètres qui donnent le meilleur résultat.
Avant d'introduire l'optimisation de la boîte noire, commençons d’abord par définir notre situation comme un problème d'optimisation concret.
Nous évoquerons ensuite les outils utilisés car il nous faut un moyen d'automatiser la résolution de ce type de problèmes plutôt que de le faire manuellement : "le temps, c'est de l'argent", comme on dit.
Définition d’un problème d'optimisation
Notre problème comporte de nombreux éléments « mobiles », mais tous n'ont pas la même nature.
Objectif
Tout d'abord, l'objectif. Dans notre cas, nous voulons minimiser le coût par octet du transfert des données de PubSub vers BigQuery. En supposant que le système évolue linéairement dans le domaine qui nous intéresse, le coût par octet traité est indépendant du nombre d'instances. Ce qui permet d'extrapoler précisément le coût pour atteindre un débit défini.
Comment y arriver ?
Nous exécutons notre programme sur un volume significatif et connu de données dans un environnement d'exécution spécifié - pensez à un type de machine, un emplacement et une configuration de programme spécifiques -. Nous mesurons alors le temps qu'il faut pour traiter ce volume de données et nous calculons le coût des ressources - nommé `cost_dollar` ci-dessous. C'est notre fonction « coût » f.
Comme nous l'avons mentionné précédemment, il n'existe pas d'expression mathématique simple pour définir la fonction « coût » de notre système. Son évaluation implique donc l'exécution d'un programme, ce qui est en soi "coûteux".
Espace des paramètres
Notre système comporte de nombreux boutons sur lesquels agir : le programme possède de nombreux paramètres de configuration correspondant à des façons alternatives de faire les choses que nous voulons explorer et des paramètres de dimensionnement tels que la taille de la file d'attente ou le nombre de workers.
L'environnement d'exécution définit encore plus de paramètres : La configuration de la VM, le type de machine, l'image du système d'exploitation, l'emplacement, ...
En général, le nombre de paramètres peut varier énormément - pour ce scénario, nous en avons une douzaine.
Au final, notre espace de paramètres est décrit par la Table 1 qui pour chaque `parameter_id` donne le type de valeur (entier, discret ou catégorique).
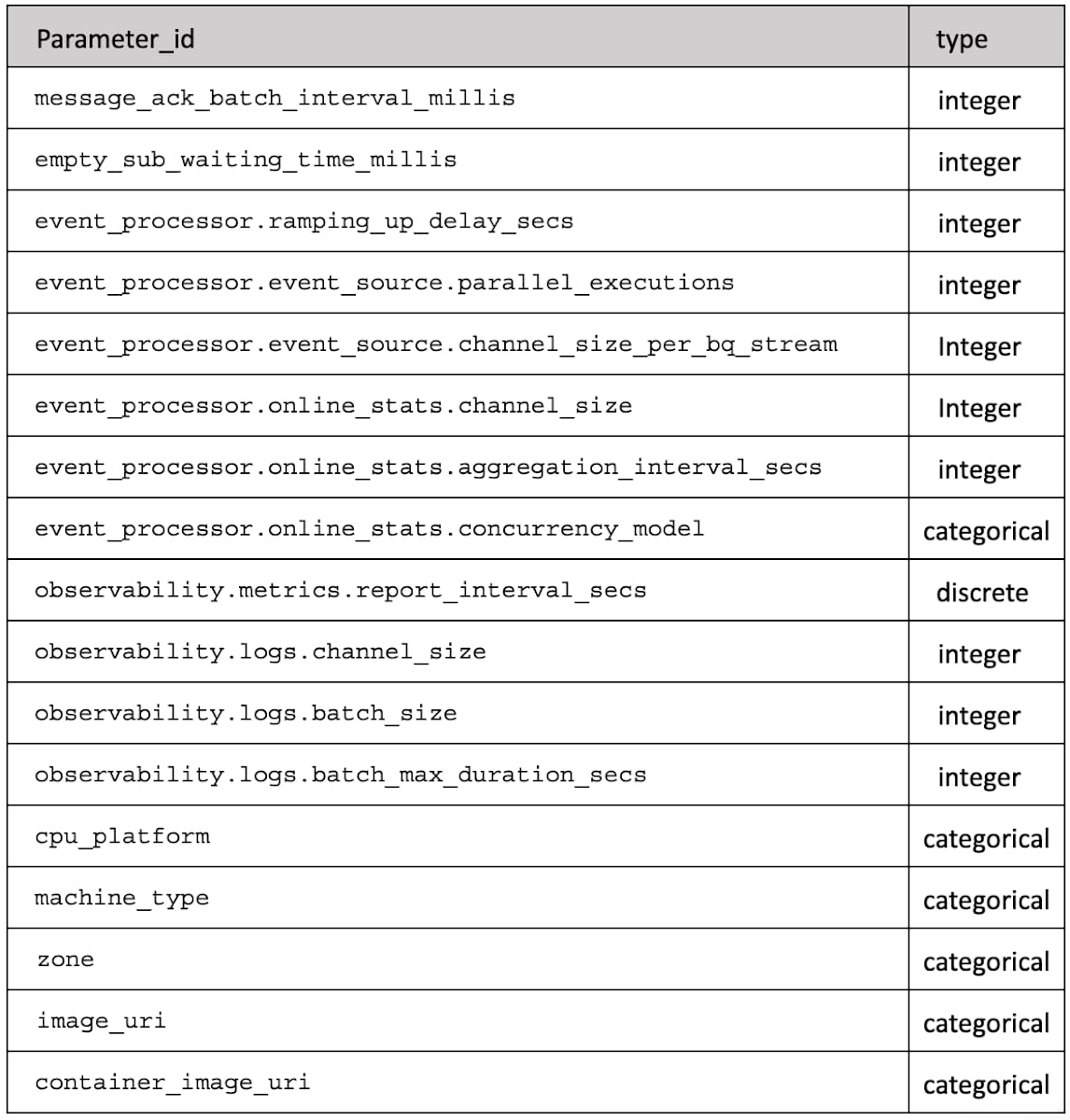
Voilà donc notre objectif identifié. Et nous savons comment l'évaluer en affectant une collection de paramètres identifiés. Nous avons même défini le domaine de ces paramètres.
Tout est donc désormais en place pour nous permettre de réaliser une optimisation en boîte noire.
Notre Approche
Maintenant que le décor est planté, revenons à nos moutons : l'optimisation en boîte noire. Comme déjà évoqué, il s'agit d'un problème de minimisation/maximisation d'une fonction pour laquelle nous n'avons pas d'expression. Nous pouvons néanmoins l'évaluer ! Il nous suffit de réaliser une expérience et d'en déterminer le coût.
Le problème est que l'exécution de l'expérience a elle-même un coût. Étant donné l'étendue des paramètres, les explorer tous n'est pas une option viable. En supposant que vous ne choisissiez que 3 valeurs pour chacun des 12 paramètres environ, cela donne 312, autrement dit 531 441 combinaisons possibles et donc 531 441 expérimentations à tester. C'est déjà beaucoup trop ! Cette méthode d'exploration systématique de toutes les combinaisons générées à partir d'un sous-ensemble de chaque paramètre pris individuellement est appelée « recherche par grille » (ou Grid Search).
À la place, nous allons utiliser une forme d'optimisation de substitution : Dans un cas comme celui-ci où il n'y a pas de représentation commode de notre fonction « objectif », il peut être bénéfique d'introduire une fonction de substitution avec de meilleures propriétés qui modélise la fonction réelle.
Certes, au lieu d'un seul problème : minimiser notre fonction « coût », nous en avons désormais deux : adapter une fonction à notre problème et la minimiser.
Mais nous avons acquis une recette pour aller de l'avant : adapter un modèle aux observations et utiliser ce modèle pour aider à choisir un candidat prometteur pour lequel nous devons mener une expérience. Une fois que nous avons le résultat de l'expérience, le modèle peut être affiné et de nouveaux candidats peuvent être générés, jusqu'à ce que les améliorations se révèlent marginales et ne valent plus la peine.
Et justement, Google Cloud Vertex AI Vizier propose ce type d'optimisation sous forme « as a service ». Si vous voulez en savoir plus sur ce qui se cache derrière - spoiler : Google s'appuie sur l'optimisation par processus gaussien (GP) - consultez cette publication pour une description complète : Google Vizier : un service d'optimisation en boîte noire.
En pratique, nous avons réalisé 148 expériences différentes avec différentes combinaisons de paramètres d'entrée. Qu'avons-nous appris ?
Les résultats de notre étude
Le but de ce billet n'est pas de détailler précisément les paramètres que nous avons utilisés pour obtenir le meilleur coût - ce n'est en effet pas une information transférable car votre programme, votre configuration et à peu près tout le reste seront différents.
Ce que nous souhaitons, c’est vous donner une idée du potentiel de la méthode : dans notre cas, avec 148 cycles, notre fonction « coût » est passée de 0,0780 $/cycle avec notre configuration initiale supposée à 0,0443 $/cycle avec les meilleurs paramètres - soit une réduction des coûts de 43 % ! Sans surprise, le paramètre `machine_type` joue ici un rôle majeur ici. Mais même avec le même type de machine que celui offrant les meilleurs résultats, la partie (explorée) de notre fonction « coût » varie entre $0.0443/run et $0.0531/run - une variation de 16% qui est loin d’être négligeable.
Les runs les plus prometteurs sont représentés dans la figure 3. Tous les axes, sauf les deux derniers, correspondent à des paramètres. Les deux derniers représentent respectivement l'objectif `cost_dollar`, et si le run s'est terminé ou non. Les lignes représentent les runs successifs et relient entre elles les valeurs de chaque axe qui leur correspondent.
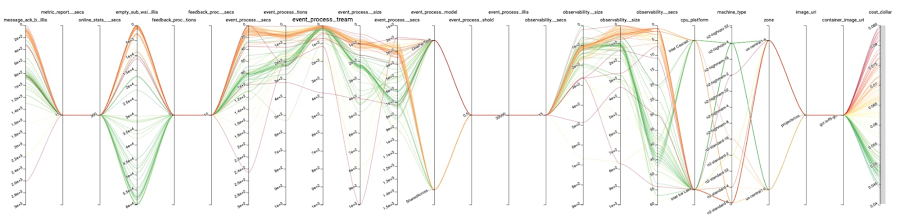
Dit autrement, nous avons découvert une amélioration substantielle des coûts avec presque aucune intervention de notre part. Nous allons explorer cet aspect plus en détail dans la section suivante.
Qu’avons-nous appris ?
L'un des principaux avantages de cette méthode est qu'elle peut fonctionner de manière autonome et ne nécessiter que peu ou pas d'intervention humaine. À condition, bien sûr, d’avoir fait l'effort initial de configurer les choses correctement.
L'optimisation en boîte noire suppose que l'évaluation de f(x) ne dépende que de x et non de ce qui se passe au même moment. Nous ne voulons pas voir d'interactions entre les différentes évaluations de f(x).
L'une des principales applications de Vizier est l'optimisation des hyperparamètres des modèles d'apprentissage profond. La formation et l'évaluation sont essentiellement dépourvues d'effets secondaires - coût mis à part, mais nous avons déjà dit que les méthodes d'optimisation en boîte noire supposent que l'évaluation est coûteuse et sont conçues de sorte à réduire le nombre d'exécutions nécessaires pour trouver les paramètres optimaux. Notre scénario a définitivement des effets secondaires : il déplace des données d'un endroit à un autre.
Donc, si nous nous assurons que tous les effets secondaires sont supprimés de notre expérience de performance, la vie devrait être facile pour nous. Dès lors, les méthodes d'optimisation de type boîte noire peuvent s'appliquer et Vizier en particulier peut être utilisé.
Pour supprimer les effets secondaires, nous avons enveloppé l'exécution de notre scénario dans une logique de mise en place et de démantèlement d'un environnement isolé.
Quelques leçons sur l'exécution de ce type de tests méritent d'être soulignées :
Il faut tout paramétrer, même s'il n'y a qu'une seule valeur au départ : si une autre valeur devient nécessaire, il est facile de l'ajouter. Dans le pire des cas, les valeurs sont enregistrées avec vos données, ce qui facilite la comparaison entre différentes expériences si nécessaire.
Il faut veiller à l’isolation entre les exécutions (runs) et d'autres choses : si une telle isolation n'est pas paramétrée et qu'elle a un impact sur l'objectif, les mesures seront « bruitées » et il sera plus difficile pour le processus d'optimisation d'être décisif lors de la prochaine exploration.
Il faut veiller à l’isolation entre les exécutions (runs) simultanées : de sorte que l’on puisse exécuter plusieurs expériences à la fois.
Il faut s’assurer de la robustesse des exécutions (runs) : toutes les combinaisons de paramètres ne sont pas réalisables, et Vizier permet de les signaler comme telles.
Il faut s’assurer d’un nombre suffisant d’exécutions (runs) : Vizier s'appuie sur les résultats des expériences précédentes pour décider de ce qu'il faut explorer ensuite et vous pouvez demander à ce qu'un certain nombre d'expériences soient exécutées en même temps - sans avoir à fournir les mesures. C'est utile pour commencer à exécuter des expériences en parallèle, mais d'après notre expérience, c'est aussi utile pour s'assurer que vous avez une large couverture de l'espace des paramètres avant que l'exploration ne commence pour essayer d'identifier les extrema locaux. Par exemple, dans la série d'exécutions que nous avons décrite plus haut dans ce billet, 'n2-highcpu-4' n'a pas été essayé avant l'exécution 107.
Des outils existent aujourd'hui : Vizier est un exemple disponible sous forme de service. Il existe également de nombreuses bibliothèques Python pour l'optimisation en boîte noire. Il s'agit d'un outil à avoir dans sa boîte à outils si l'on ne veut pas passer des heures à manipuler manuellement des paramètres et que l'on préfère une machine pour le faire.
Conclusion et prochaines étapes
L'optimisation en boîte noire est inévitable pour le réglage des hyperparamètres ML. Google Vertex AI Vizier est un service d'optimisation en boîte noire avec une gamme d'applications plus large. Nous pensons qu'il s'agit également d'un excellent outil pour l'ingénierie de systèmes complexes caractérisés par de nombreux paramètres dont les interactions sont essentiellement inconnues ou difficiles à décrire.
Bien sûr, pour les petits systèmes, l'exploration manuelle et/ou systématique des paramètres peut être possible, mais l'intérêt de ce billet est de rappeler qu'elle peut aussi être automatisée !
L'optimisation des performances est un défi récurrent car tout change et de nouvelles options et/ou de nouveaux modes d'utilisation apparaissent.
La configuration présentée dans ce billet est relativement simple et très statique. Il existe des extensions naturelles de cette configuration à l'optimisation continue en ligne qui méritent d'être explorées du point de vue du génie logiciel, comme les « bandits à bras multiples ».
Et si l'avenir de l'optimisation des applications était déjà là, mais pas très bien réparti, pour paraphraser William Gibson ?
Vous pensez que tout ceci est définitivement très cool ? Alors, sachez que le groupe AI & Data de F5 recrute !