Data-Science-Workflows mit Looker beschleunigen und kostenloses Training für den Einstieg nutzen

Shingi Samudzi
Data Analyst Consultant, Google Cloud
GCP testen
Profitieren Sie von einem 300 $-Guthaben, um Google Cloud und mehr als 20 zu jeder Zeit kostenlose Produkte kennenzulernen.
JETZT TESTENLooker, die moderne Plattform für Business Intelligence (BI) und Analysen, und jetzt Teil von Google Cloud, ist mehr als ein BI-Reporting-Tool. Es ist eine vollwertige Plattform für die Datenanwendung- und visualisierung. Mit Looker können Sie Daten aufbereiten und veröffentlichen, wobei die Einbindung in eine Vielzahl von Endpunkten in vielen verschiedenen Formaten möglich ist: von CSV-, JSON- und Excel®-Dateien über SaaS bis hin zu selbst erstellten benutzerdefinierten Anwendungen.
In diesem Beitrag erkläre ich, wie Sie Looker in der Datenanalyse und Data Science für Data Governance nutzen können, also für die Verwaltung der Verfügbarkeit, Nutzbarkeit, Integrität und Sicherheit von Daten in Unternehmenssystemen. Data Governance ist der erste, notwendige Schritt zur Unterstützung von skalierbaren, automatisierten Machine-Learning-Vorgängen. Wenn Sie anhand einer Live-Demo und Praxisbeispielen erfahren möchten, wie Looker zur Automatisierung und Rationalisierung von Data-Science-Workflows eingesetzt wird, sehen Sie sich unser On-Demand-Webinar zum Thema „Automating advanced analytics with Looker and Google Cloud“ an.
Data Scientists verbringen 45 % ihrer Zeit mit Aufgaben zur Datenvorbereitung wie dem Laden und Bereinigen von Daten, was einen großen Arbeitsaufwand und eine finanzielle Belastung darstellt. Data Analysts und Data Scientists stehen außerdem oft unter dem Druck verschiedener Interessenvertretungen im Unternehmen, die skeptisch gegenüber der Investitionsrendite in diesen Bereichen sind, sodass der Geschäftswert schnell aufgezeigt werden muss. Wenn sie sich die Zeit nehmen müssen, ihre eigenen Datenpipelines für jedes Projekt aufzubauen, ist das gar nicht so einfach.
Gleichzeitig besteht das Problem der Datensilos fort, da verschiedene Teams konkurrierende Berichte mit unterschiedlichen Datenquellen und sogar unterschiedlichen Reporting-Tools erstellen. Wenn Unternehmen wachsen und für die Erstellung von Berichten Machine Learning oder KI erforderlich ist, erschwert das die Lage weiter. In diesen Situationen besteht ein großer Bedarf an Data Governance, was jedoch oft vergessen oder viel zu spät berücksichtigt wird.
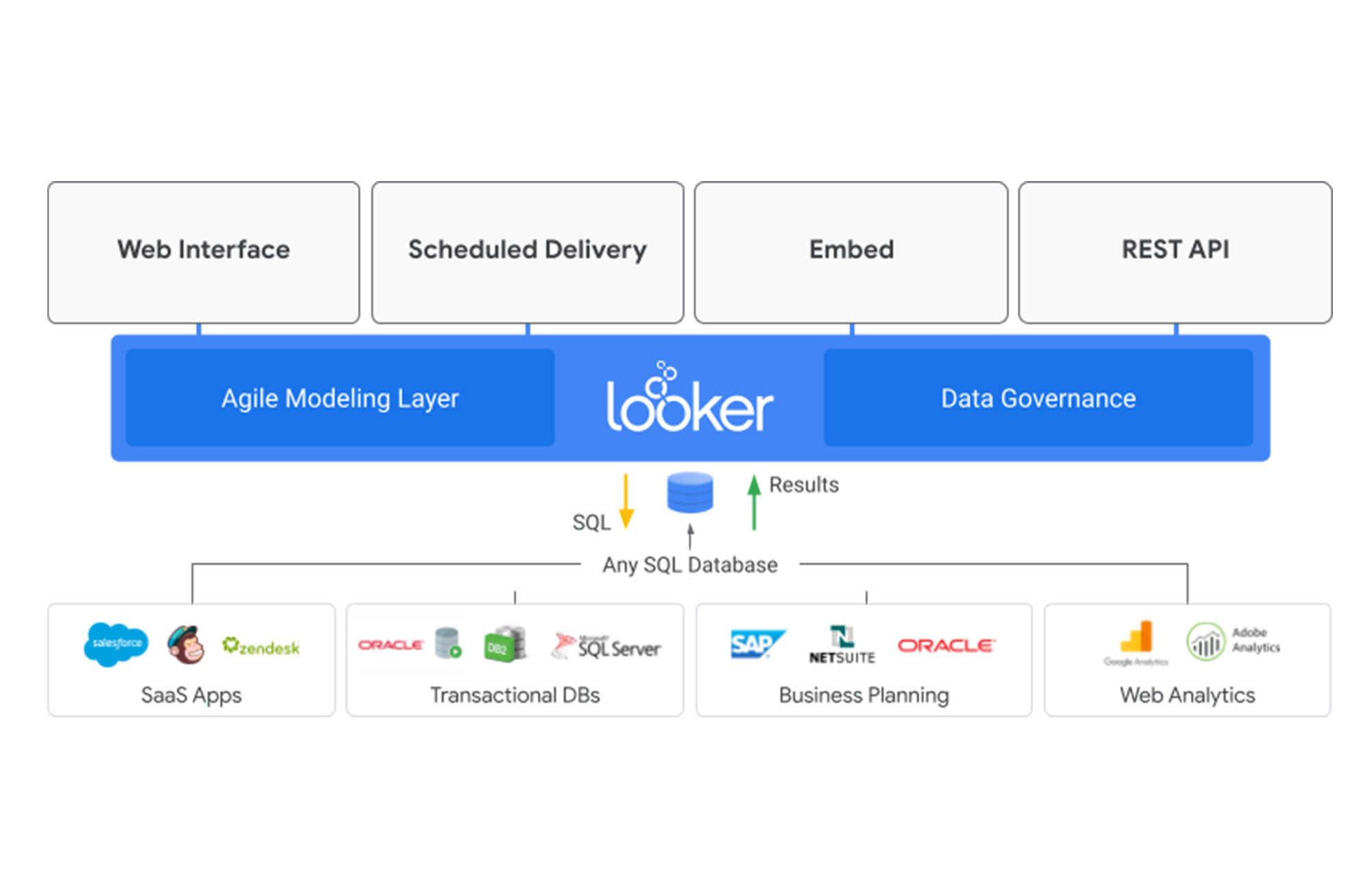
Mit der Plattform und den Publishing-Funktionen von Looker können geschäftliche Datenanalyse- und Data-Science-Teams diese als zentrales Daten-Clearinghouse für das gesamte Unternehmen nutzen. Darüber hinaus können Sie mit der Modellierungssprache LookML von Looker SQL-Abfragen abstrahieren und haben so eine einfache Möglichkeit, Data Governance als Service zu implementieren, der auf mehreren SQL-basierten Data Warehouses aufbaut.
Mit einer zentralen Anlaufstelle für Data Governance und Data Publishing können Sie die Zeit deutlich reduzieren, die Datenanalyst*innen und Data Scientists für die Aufnahme und grundlegende Bereinigung von Daten benötigen.
Sehen wir uns zur Verdeutlichung eine Analogie an. Stellen Sie sich einen Raum mit drei Personen vor: Jemand möchte ein Haus bauen, jemand möchte ein Möbelstück bauen und jemand möchte einen Bilderrahmen bauen. Was ist effizienter: Jede Person fällt ihren eigenen Baum, bereitet das Holz separat auf und stellt jedes Mal, wenn sie etwas bauen will, ein eigenes Holzstück her. Oder: Sie gehen in einen Baumarkt, kaufen das gewünschte, fertig zugeschnittene Stück Holz und verbringen die gesamte Arbeitszeit damit, an ihrem Projekt zu bauen?
Im ersten Szenario muss jede Person die gesamte Arbeit der Aufbereitung des Rohmaterials in nutzbare Holzstücke erledigen, bevor sie das gewünschte Projekt umsetzen kann. Es ist effizienter, wenn alle dieselben in der Lieferkette vorgelagerten Prozesse nutzen, da ihr Arbeitsmaterial aus derselben Quelle stammt.
In dieser Analogie ist Looker der Baumarkt. Looker ist Ihr „Daten-Baumarkt”, der den Prozess der Aufnahme, Qualitätssicherung, Lagerung und schließlich Bereitstellung von Daten in einem für jede Art von Endnutzung verwendbaren Format zentralisiert. Dazu fungiert Looker als semantische Schicht, die Daten aus einem zugrunde liegenden Data Warehouse flexibel in die jeweils passenden Formate für jede Art von Endnutzung umwandelt, sodass sie direkt konsumiert werden können.
Anstatt dass jede Organisation oder Abteilung innerhalb Ihres Unternehmens ihre eigenen Datenpipelines, Excel®-Berichte oder Reporting-Tools erstellt, können nun alle ihre Daten von der gleichen Stelle beziehen und sich auf die Verteilung oder für den jeweiligen Endzweck spezifische Anwendung der Transformation auf der letzten Meile konzentrieren.
Wer bei der Datenakquise grundlegende Qualitätsstandards erfüllen will, verbringt oft viele Stunden mit der Säuberung von Datensätzen unterschiedlicher Herkunft (Umwandlung von Spaltentypen, Zuordnung von Spaltennamen, Umgang mit fehlenden Werten). Eine einheitliche Datenhaltung im Unternehmen macht aus diesem mühevollen Prozess einen Besuch in einem übersichtlichen Daten-Baumarkt, wo geprüfte Datensätze im Handumdrehen in KI-Projekten genutzt werden können (z.B. mit AI Notebooks).
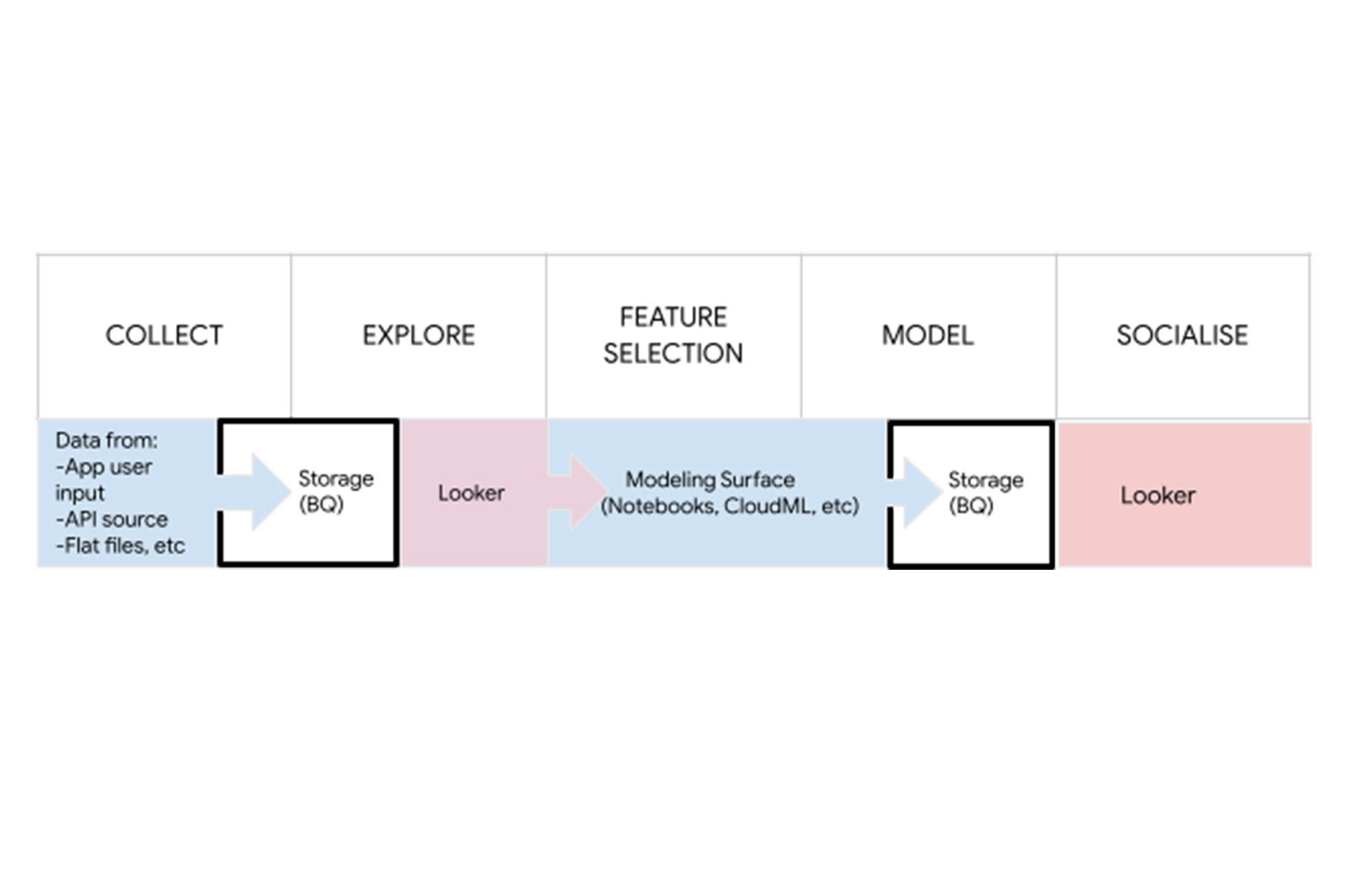
Looker fügt sich auch in das Back-End von Data-Science-Workflows ein, sowohl bei der gemeinsamen Nutzung der Modellleistung als auch bei der gemeinsamen Nutzung der Modellergebnisse – in einer im gesamten Unternehmen einfach umzusetzenden Art und Weise.