Im Rahmen von Abfragejobs enthält BigQuery einen Diagnoseabfrageplan und Zeitinformationen. Dies ähnelt den Informationen, die von Anweisungen wie EXPLAIN in anderen Datenbank- und Analysesystemen bereitgestellt werden. Diese Informationen können aus den API-Antworten von Methoden wie jobs.get abgerufen werden.
Bei Abfragen mit langer Ausführungszeit aktualisiert BigQuery diese Statistiken regelmäßig. Diese Aktualisierungen erfolgen zwar unabhängig von der Häufigkeit, mit der der Jobstatus abgefragt wird, aber in der Regel nicht häufiger als alle 30 Sekunden. Abfragejobs, die keine Ausführungsressourcen nutzen (zum Beispiel Probelaufanfragen oder Ergebnisse, die mithilfe von im Cache gespeicherten Ergebnissen bereitgestellt werden können), enthalten diese zusätzlichen Diagnoseinformationen nicht. Andere Statistiken können allerdings vorhanden sein.
Hintergrund
Bei der Ausführung eines Abfragejobs in BigQuery wird die deklarative SQL-Anweisung in eine Ausführungsgrafik umgewandelt, wobei sie in eine Reihe von Abfragephasen aufgeteilt wird, die sich wiederum aus detaillierten Sätzen von Ausführungsschritten zusammensetzen. BigQuery nutzt eine stark verteilte parallele Architektur zum Ausführen dieser Abfragen. In den Phasen werden dabei die Arbeitseinheiten modelliert, die viele potenzielle Worker parallel ausführen können. Die Phasen kommunizieren über eine schnelle verteilte Shuffle-Architektur miteinander. Diese wird unter In-memory query execution in Google BigQuery weiter erläutert.
Innerhalb des Abfrageplans werden die Begriffe Arbeitseinheiten und Worker verwendet, um Informationen zur Parallelisierung zu liefern. An anderer Stelle in BigQuery kann der Begriff Slot vorkommen, bei dem es sich um eine abstrahierte Darstellung mehrerer Aspekte der Abfrageausführung handelt, einschließlich Rechen-, Arbeitsspeicher- und E/A-Ressourcen. Jobstatistiken der obersten Ebene liefern eine Schätzung der Kosten einzelner Abfragen. Dafür wird die totalSlotMs-Schätzung der Abfrage unter Verwendung dieser abstrahierten Berechnung genutzt.
Eine weitere wichtige Eigenschaft der Architektur für die Abfrageausführung ist, dass sie dynamisch ist. Das bedeutet, dass der Abfrageplan während einer laufenden Abfrage geändert werden kann. Häufig werden während der Ausführung einer Abfrage Phasen eingeführt, um die Datenverteilung auf die Worker der Abfrage zu verbessern. Bei Abfrageplänen, in denen dies der Fall ist, werden diese Phasen normalerweise als Neupartitionierung bezeichnet.
Neben dem Abfrageplan stellen Abfragejobs auch eine Zeitachse für die Ausführung bereit, in der die abgeschlossenen, ausstehenden und aktiven Arbeitseinheiten der Abfrage-Worker aufgeführt sind. Eine Abfrage kann sich gleichzeitig in mehreren Phasen mit aktiven Workern befinden. Die Zeitachse dient dazu, den Gesamtfortschritt der Abfrage anzuzeigen.
Informationen in der Cloud Console ansehen
In der Cloud Console können Sie Details zum Abfrageplan für eine abgeschlossene Abfrage abrufen. Klicken Sie hierzu auf die Schaltfläche Ausführungsdetails (neben der Schaltfläche Ergebnisse).

Informationen des Abfrageplans
Innerhalb der API-Antwort werden Abfragepläne als Liste von Abfragephasen dargestellt. Jedes Element in der Liste enthält eine Übersichtsstatistik pro Phase, detaillierte Informationen zu jedem Schritt und zeitliche Klassifizierungen der Phasen. In der Cloud Console werden nicht alle Details gerendert, können aber in den API-Antworten enthalten sein.
Phasenübersicht
Die Übersichtsfelder für jede Phase können Folgendes enthalten:
| API-Feld | Beschreibung |
|---|---|
id |
Eindeutige numerische ID für die Phase. |
name |
Einfacher zusammenfassender Name für die Phase. Die steps innerhalb der Phase liefern zusätzliche Details zu den Ausführungsschritten. |
status |
Ausführungsstatus der Phase. Folgende Status sind möglich: PENDING, RUNNING, COMPLETE, FAILED und CANCELLED. |
inputStages |
Eine Liste der IDs, die die Abhängigkeitsgrafik der Phase bilden. Eine JOIN-Phase benötigt zum Beispiel oft zwei abhängige Phasen, die die Daten auf der linken und rechten Seite der JOIN-Beziehung vorbereiten. |
startMs |
Zeitstempel in Millisekunden der Epoche, der angibt, wann der erste Worker in der Phase mit der Ausführung begonnen hat. |
endMs |
Zeitstempel in Millisekunden der Epoche, der angibt, wann der letzte Worker die Ausführung abgeschlossen hat. |
steps |
Detaillierte Liste der Ausführungsschritte innerhalb der Phase. Weitere Informationen finden Sie im nächsten Abschnitt. |
recordsRead |
Eingabegröße der Phase als Anzahl der Datensätze aller Worker der Phase. |
recordsWritten |
Ausgabegröße der Phase als Anzahl der Datensätze aller Worker der Phase. |
parallelInputs |
Anzahl der parallelisierbaren Arbeitseinheiten für die Phase. Je nach Phase und Abfrage kann hiermit die Anzahl der Spaltensegmente innerhalb einer Tabelle oder die Anzahl der Partitionen innerhalb eines Zwischen-Shuffles dargestellt sein. |
completedParallelInputs |
Anzahl der Arbeitseinheiten innerhalb der Phase, die abgeschlossen wurden. Bei einigen Abfragen müssen nicht alle Eingaben in einer Phase abgeschlossen sein, damit die Phase abgeschlossen werden kann. |
shuffleOutputBytes |
Stellt die Gesamtzahl der Byte dar, die in allen Workern in einer Abfragephase geschrieben wurden. |
shuffleOutputBytesSpilled |
Abfragen, die erhebliche Datenmengen zwischen Phasen übertragen, müssen möglicherweise auf eine laufwerkbasierte Übertragung zurückgreifen. Die Statistik zur Menge der übergebenen Byte informiert darüber, wie viele Daten an das Laufwerk übergeben wurden. Hängt von einem Optimierungsalgorithmus ab, sodass er nicht für jede Abfrage deterministisch ist. |
Informationen zu den einzelnen Schritten in einer Phase
Jeder Worker muss innerhalb einer Phase detaillierte Vorgänge ausführen, die als Schritte bezeichnet werden. Diese werden als sortierte Liste von Vorgängen dargestellt. Die Schritte sind kategorisiert, wobei einige Vorgänge ausführlichere Informationen liefern. Im Abfrageplan können folgende Kategorien von Vorgängen vorhanden sein:
| Schritt | Beschreibung |
|---|---|
| READ | Ein Lesevorgang von einer oder mehreren Spalten aus einer Eingabetabelle oder einem Zwischen-Shuffle. |
| WRITE | Ein Schreibvorgang von einer oder mehreren Spalten in eine Ausgabetabelle oder ein Zwischenergebnis. Bei HASH-partitionierten Ausgaben aus einer Phase umfasst dies auch die Spalten, die als Partitionsschlüssel verwendet werden. |
| COMPUTE | Vorgänge wie das Auswerten von Ausdrücken sowie SQL-Funktionen. |
| FILTER | Operator, der die WHERE-, OMIT IF- und HAVING-Klauseln implementiert. |
| SORT | "Sortieren"- und "Sortieren nach"-Vorgang; enthält die Spaltenschlüssel und die Richtung. |
| AGGREGATE | Ein Aggregationsvorgang, z. B. GROUP BY oder COUNT. |
| LIMIT | Operator, der die LIMIT-Klausel implementiert. |
| JOIN | Ein JOIN-Vorgang, der den Join-Typ und die verwendeten Spalten umfasst. |
| ANALYTIC_FUNCTION | Ein Aufruf einer analytischen Funktion (auch als "Fensterfunktion" bezeichnet). |
| USER_DEFINED_FUNCTION | Ein Aufruf einer benutzerdefinierten Funktion. |
Zeitliche Klassifizierung pro Phase
Die Abfragephasen ermöglichen auch eine zeitliche Klassifizierung, sowohl in absoluter als auch relativer Form. Da jede Ausführungsphase Aktivitäten von einem oder mehreren unabhängigen Workern beinhaltet, werden sowohl die durchschnittliche als auch die längste Zeitdauer angegeben. Diese Werte geben die durchschnittliche Leistung aller Worker einer Phase sowie die Leistung des langsamsten Workers einer bestimmten Klassifizierung wieder. Die durchschnittliche und maximale Zeitdauer wird darüber hinaus absolut und relativ dargestellt. Bei den verhältnisbasierten Statistiken werden die Daten als Anteil der längsten Zeit geliefert, die ein Worker in einem Segment verbracht hat.
In der Cloud Console werden die zeitlichen Informationen der Phasen mithilfe relativer Zeitdarstellungen angegeben.
Die zeitlichen Informationen der Phasen werden folgendermaßen dargestellt:
| Relative Zeitdauer | Absolute Zeitdauer | Verhältniszähler |
|---|---|---|
waitRatioAvg |
waitMsAvg |
Zeit, die der durchschnittliche Worker auf die Planung gewartet hat. |
waitRatioMax |
waitMsMax |
Zeit, die der langsamste Worker auf die Planung gewartet hat. |
readRatioAvg |
readMsAvg |
Zeit, die der durchschnittliche Worker mit dem Lesen von Eingabedaten verbracht hat. |
readRatioMax |
readMsMax |
Zeit, die der langsamste Worker mit dem Lesen von Eingabedaten verbracht hat. |
computeRatioAvg |
computeMsAvg |
Zeit, die der durchschnittliche Worker CPU-gebunden verbracht hat. |
computeRatioMax |
computeMsMax |
Zeit, die der langsamste Worker CPU-gebunden verbracht hat. |
writeRatioAvg |
writeMsAvg |
Zeit, die der durchschnittliche Worker mit dem Schreiben von Ausgabedaten verbracht hat. |
writeRatioMax |
writeMsMax |
Zeit, die der langsamste Worker mit dem Schreiben von Ausgabedaten verbracht hat. |
Metadaten der Zeitachse
Die Abfragezeitachse zeigt den Fortschritt zu bestimmten Zeitpunkten und bietet aktuelle Ansichten des gesamten Abfragefortschritts. Die Zeitachse wird als eine Reihe von Stichproben dargestellt, die folgende Details enthalten:
| Feld | Beschreibung |
|---|---|
elapsedMs |
Seit Beginn der Abfrageausführung verstrichene Millisekunden. |
totalSlotMs |
Eine kumulative Darstellung der von der Abfrage verwendeten Slot-Millisekunden. |
pendingUnits |
Gesamtzahl der geplanten Arbeitseinheiten, die auf Ausführung warten. |
activeUnits |
Gesamtzahl der aktiven Arbeitseinheiten, die derzeit von den Workern verarbeitet werden. |
completedUnits |
Gesamtzahl der Arbeitseinheiten, die während der Ausführung dieser Abfrage abgeschlossen wurden. |
Beispielabfrage
Die folgende Abfrage zählt die Anzahl der Zeilen im öffentlichen Shakespeare-Dataset und hat eine zweite bedingte Zählung, deren Ergebnisse auf Zeilen beschränkt sind, die auf "Hamlet" verweisen:
#StandardSQL
SELECT
COUNT(1) as rowcount,
COUNTIF(corpus = 'hamlet') as rowcount_hamlet
FROM `publicdata.samples.shakespeare`
Dieses Beispiel umfasst eine sehr kleine Beispieltabelle und eine einfache Abfrage, sodass insgesamt nur zwei Arbeitseinheiten vorhanden sind. Die gesamte Arbeit ist fast sofort abgeschlossen.
Klicken Sie auf Ausführungsdetails, um den Abfrageplan anzuzeigen:
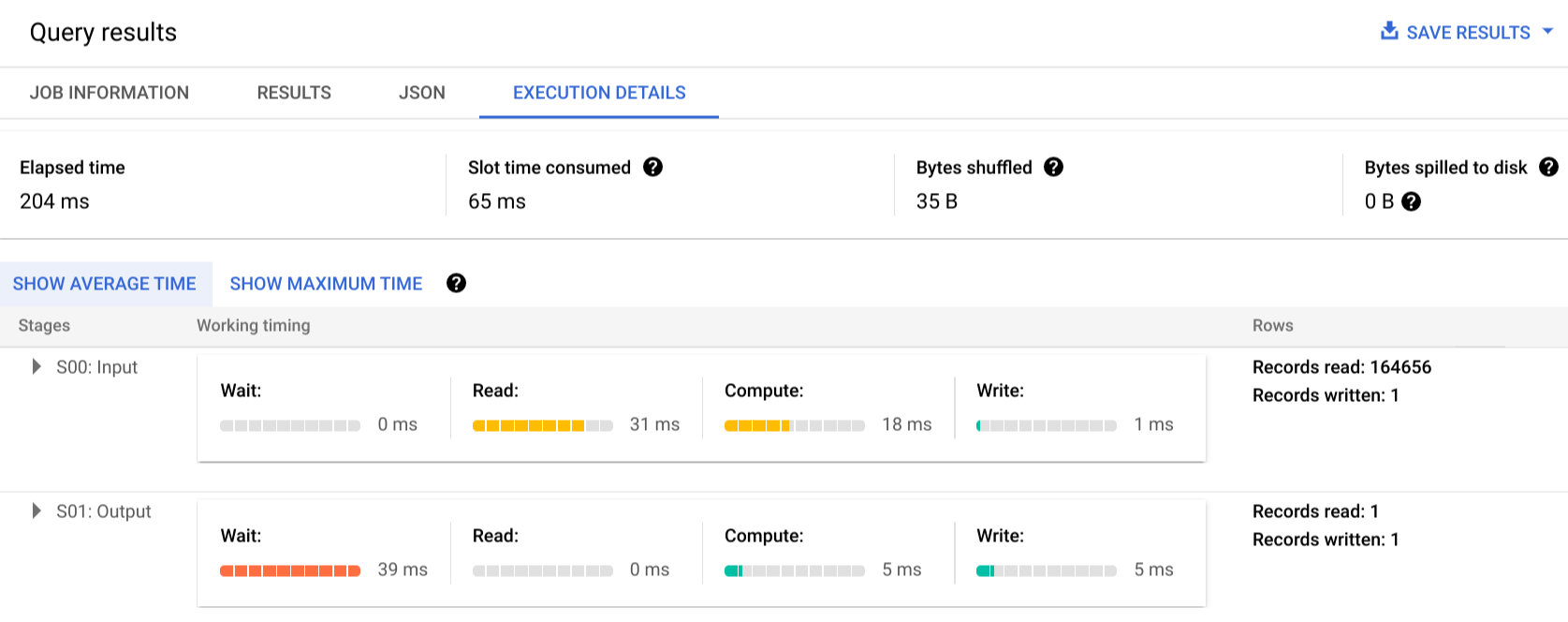
Die Farbindikatoren zeigen die relative Zeitdauer für alle Schritte in allen Phasen an. Beispielsweise zeigt der COMPUTE-Schritt von Phase 00 einen Balken, dessen Farbabstufung 21/30 beträgt, da 30 ms die maximale Zeit ist, die für einen einzelnen Schritt einer beliebigen Phase benötigt wird. Die Informationen zur parallelen Eingabe zeigen, dass für jede Phase nur ein einzelner Worker erforderlich war. Daher gibt es keine Unterschiede zwischen der durchschnittlichen und der maximalen Zeitdauer.
Um mehr über die Schritte der Ausführungsphasen zu erfahren, klicken Sie auf das Dreieck, woraufhin die Details für die Phase maximiert werden:
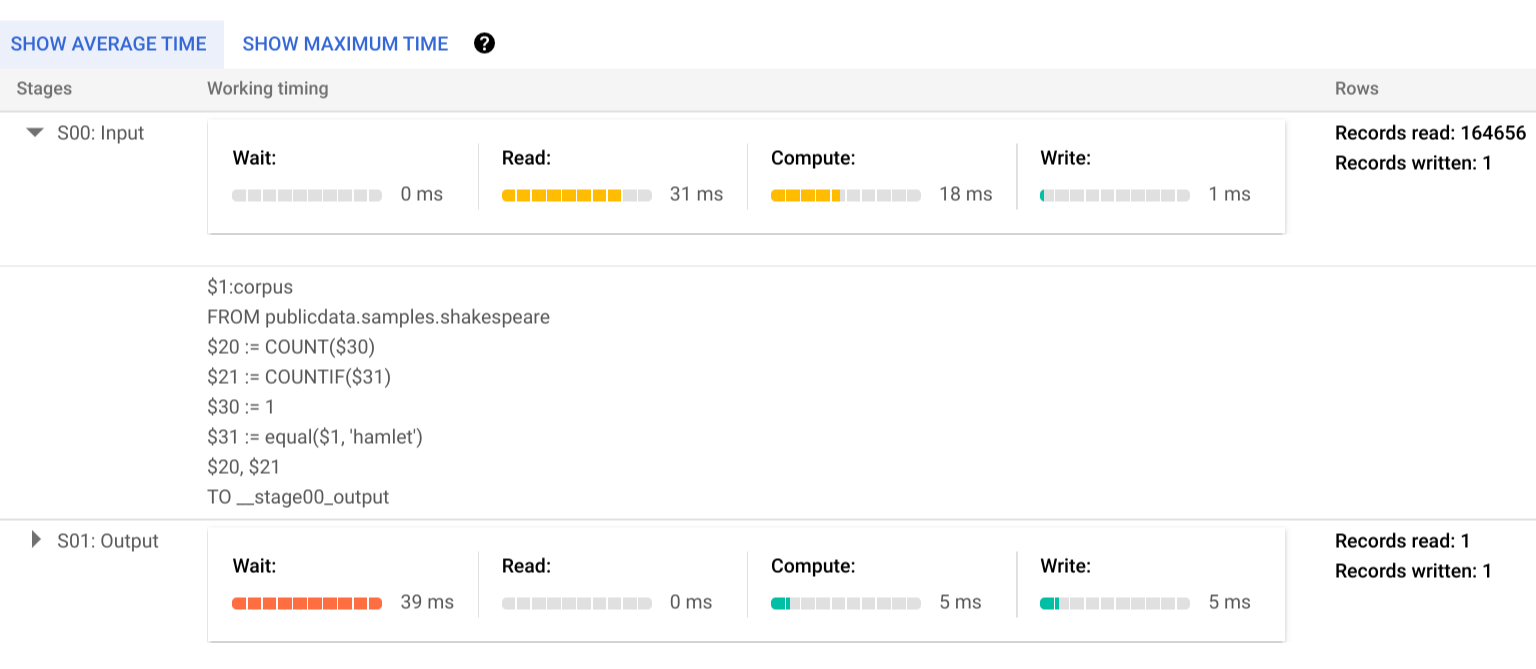
In diesem Beispiel war die längste Zeit in einem Segment die Zeit, die der einzelne Worker in Phase 01 auf den Abschluss von Phase 00 gewartet hat. Dies liegt daran, dass Phase 01 von der Eingabe von Phase 00 abhängig war und erst gestartet werden konnte, nachdem die Ausgabedaten in der ersten Phase (1 Zeile, ~18 Byte) in den Zwischen-Shuffle geschrieben wurden.
Der Ausführungsplan für den einzelnen Worker, der die Arbeit für Phase 00 erledigt hat, zeigt, dass zuerst Daten aus der Spalte "Corpus" der referenzierten Shakespeare-Tabelle gelesen wurden (READ). Als Nächstes wurden die Projektionen COUNT und COUNTIF aggregiert (AGGREGATE). Für das Scannen der Daten war ein Berechnungsschritt (COMPUTE) erforderlich, der Daten sowohl für die normalen als auch für die bedingten Zählungen lieferte. Die Ausgabedaten wurden in den Zwischen-Shuffle geschrieben (WRITE), der in diesem Plan als __stage00_output bezeichnet wurde.
Fehlerberichte
Abfragejobs können während der Ausführung fehlschlagen. Da die Informationen des Abfrageplans regelmäßig aktualisiert werden, können Sie sehen, an welcher Stelle innerhalb der Ausführungsgrafik der Fehler aufgetreten ist. In der Cloud Console wird durch ein Häkchen bzw. ein Ausrufezeichen neben den Phasennamen angezeigt, ob eine Phase erfolgreich war oder fehlgeschlagen ist.
Weitere Informationen zum Interpretieren und Beheben von Fehlern finden Sie in der Anleitung zur Fehlerbehebung.
API-Beispieldarstellung
Die Informationen des Abfrageplans sind in der Jobantwort enthalten und können durch Aufrufen von jobs.get abgerufen werden. Der folgende Code ist ein Auszug aus einer JSON-Antwort für einen Job, der die Beispielabfrage zu Hamlet zurückgibt und Informationen sowohl zum Abfrageplan als auch zur Zeitachse anzeigt.
"statistics": {
"creationTime": "1576544129234",
"startTime": "1576544129348",
"endTime": "1576544129681",
"totalBytesProcessed": "2464625",
"query": {
"queryPlan": [
{
"name": "S00: Input",
"id": "0",
"startMs": "1576544129436",
"endMs": "1576544129465",
"waitRatioAvg": 0.04,
"waitMsAvg": "1",
"waitRatioMax": 0.04,
"waitMsMax": "1",
"readRatioAvg": 0.32,
"readMsAvg": "8",
"readRatioMax": 0.32,
"readMsMax": "8",
"computeRatioAvg": 1,
"computeMsAvg": "25",
"computeRatioMax": 1,
"computeMsMax": "25",
"writeRatioAvg": 0.08,
"writeMsAvg": "2",
"writeRatioMax": 0.08,
"writeMsMax": "2",
"shuffleOutputBytes": "18",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "164656",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$1:corpus",
"FROM publicdata.samples.shakespeare"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$20 := COUNT($30)",
"$21 := COUNTIF($31)"
]
},
{
"kind": "COMPUTE",
"substeps": [
"$30 := 1",
"$31 := equal($1, 'hamlet')"
]
},
{
"kind": "WRITE",
"substeps": [
"$20, $21",
"TO __stage00_output"
]
}
]
},
{
"name": "S01: Output",
"id": "1",
"startMs": "1576544129465",
"endMs": "1576544129480",
"inputStages": [
"0"
],
"waitRatioAvg": 0.44,
"waitMsAvg": "11",
"waitRatioMax": 0.44,
"waitMsMax": "11",
"readRatioAvg": 0,
"readMsAvg": "0",
"readRatioMax": 0,
"readMsMax": "0",
"computeRatioAvg": 0.2,
"computeMsAvg": "5",
"computeRatioMax": 0.2,
"computeMsMax": "5",
"writeRatioAvg": 0.16,
"writeMsAvg": "4",
"writeRatioMax": 0.16,
"writeMsMax": "4",
"shuffleOutputBytes": "17",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "1",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$20, $21",
"FROM __stage00_output"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$10 := SUM_OF_COUNTS($20)",
"$11 := SUM_OF_COUNTS($21)"
]
},
{
"kind": "WRITE",
"substeps": [
"$10, $11",
"TO __stage01_output"
]
}
]
}
],
"estimatedBytesProcessed": "2464625",
"timeline": [
{
"elapsedMs": "304",
"totalSlotMs": "50",
"pendingUnits": "0",
"completedUnits": "2"
}
],
"totalPartitionsProcessed": "0",
"totalBytesProcessed": "2464625",
"totalBytesBilled": "10485760",
"billingTier": 1,
"totalSlotMs": "50",
"cacheHit": false,
"referencedTables": [
{
"projectId": "publicdata",
"datasetId": "samples",
"tableId": "shakespeare"
}
],
"statementType": "SELECT"
},
"totalSlotMs": "50"
},
Ausführungsinformationen verwenden
BigQuery-Abfragepläne liefern Informationen darüber, wie der Dienst Abfragen ausführt. Da es sich um einen verwalteten Dienst handelt, sind die Möglichkeiten, einige Details direkt zu verwerten, jedoch begrenzt. Viele Optimierungen erfolgen automatisch durch Nutzung des Dienstes. Dies kann sich von anderen Umgebungen unterscheiden, in denen Optimierung, Bereitstellung und Monitoring spezialisiertes, fachkundiges Personal erfordern.
Informationen zu konkreten Verfahren, die die Ausführung und Leistung von Abfragen verbessern können, finden Sie in der Dokumentation zu Best Practices. Anhand des Abfrageplans und der Zeitachsenstatistiken können Sie nachvollziehen, ob die Ressourcenauslastung in bestimmten Phasen besonders hoch ist. Eine JOIN-Phase, in der weit mehr Ausgabezeilen als Eingabezeilen generiert werden, könnte zum Beispiel darauf hindeuten, dass früher in der Abfrage gefiltert werden sollte.
Darüber hinaus können Sie mithilfe der Informationen der Zeitachse feststellen, ob eine bestimmte Abfrage langsam ist, weil sie isoliert ausgeführt wird oder weil sie mit anderen Abfragen um dieselben Ressourcen konkurriert. Wenn die Anzahl der aktiven Einheiten während der gesamten Lebensdauer der Abfrage begrenzt ist, die Menge der in der Warteschlange enthaltenen Arbeitseinheiten jedoch hoch bleibt, spricht dies möglicherweise dafür, dass durch Reduzierung der Anzahl gleichzeitiger Abfragen die Ausführungszeit für bestimmte Abfragen erheblich verkürzt werden kann.