Oracle から BigQuery への移行
このドキュメントは、Oracle から BigQuery への移行方法の全体的なガイダンスを提供します。アーキテクチャの基本的な違いについて説明します。また、Oracle RDBMS で実行されているデータ ウェアハウスやデータマート(Exadata を含む)から BigQuery に移行する方法についても説明します。このドキュメントで説明する詳細は、互換性のある Oracle ソフトウェアを使用している Exadata、ExaCC、Oracle Autonomous Data Warehouse にも適用できます。
このドキュメントは、Oracle から BigQuery に移行し、移行プロセスの技術的な課題を解決したいと考えているエンタープライズ アーキテクト、DBA、アプリケーション デベロッパー、IT セキュリティ専門家を対象としています。
また、バッチ SQL 変換を使用して複数の SQL スクリプトを一括で移行することも、インタラクティブ SQL 変換を使用してアドホック クエリ変換することもできます。Oracle SQL、PL/SQL、Exadata は、プレビューの両方のツールでサポートされています。
移行前
データ ウェアハウスの移行を確実に成功させるには、プロジェクトのタイムラインの早期段階で移行戦略の計画を始めてください。移行作業を体系的に計画する方法については、移行の対象と方法: 移行フレームワークをご覧ください。
BigQuery のキャパシティ プランニング
内部的に、BigQuery の分析スループットはスロット単位で測定されます。BigQuery スロットとは、SQL クエリの実行に必要なコンピューティング能力を表す Google 独自の単位です。
BigQuery では、クエリの実行に必要なスロット数が継続的に計算されますが、スロットはフェア スケジューラに基づいて割り当てられます。
BigQuery スロットのキャパシティ プランニングでは、次の料金モデルのいずれかを選択できます。
オンデマンド料金: オンデマンド料金では、BigQuery は処理したバイト数(データサイズ)に基づいて課金されるため、実行したクエリに対してのみ支払いが発生します。BigQuery のデータサイズを決定する方法については、データサイズの計算を参照してください。基本となる計算容量はスロットで決まるため、BigQuery の使用に対する支払いは、処理したバイト数ではなく必要なスロットの数を単位とします。デフォルトでは、Google Cloud プロジェクトの最大スロット数は 2,000 に制限されています。
容量ベースの料金: 容量ベースの料金では、実行するクエリによって処理されたバイト数に対して料金を支払うのではなく、BigQuery スロットの予約(最低 100 個)を購入します。エンタープライズ データ ウェアハウスのワークロードには容量ベースの料金をおすすめします。このようなワークロードでは通常、消費量が予測可能な多数の同時レポートや抽出 / 読み込み / 変換(ELT)クエリが発生します。
スロットの見積もりを行う場合は、Cloud Monitoring を使用した BigQuery のモニタリングおよび BigQuery を使用した監査ログの分析をセットアップすることをおすすめします。多くのお客様は、Looker Studio(例については Looker Studio ダッシュボードのオープンソースの例を参照)、Looker、Tableau をフロントエンドとして使用して BigQuery 監査ログデータ(特にクエリとプロジェクト全体におけるスロット使用率)を可視化しています。また、BigQuery システム テーブルデータを利用して、ジョブと予約でのスロット使用状況をモニタリングすることもできます。例については、Looker Studio ダッシュボードのオープンソースの例をご覧ください。
スロット使用率を定期的にモニタリングし、分析することで、組織の成長に合わせて Google Cloud に必要となる合計スロット数を見積もることができます。
たとえば、最初に 4,000 個の BigQuery スロットを予約して、複雑さが中程度の 100 個のクエリを同時に実行すると仮定します。クエリの実行プランの待機時間が長く、ダッシュボードに表示されるスロット使用率が高い場合、ワークロードをサポートするために BigQuery スロットが追加で必要になる可能性があります。1 年間または 3 年間の契約でスロットの購入をご希望の場合、Google Cloud コンソールまたは bq コマンドライン ツールを使用して BigQuery Reservations を開始できます。
現在のプランと上記のオプションに関する質問については、営業担当者までお問い合わせください。
Security in Google Cloud
以降のセクションでは、Oracle の一般的なセキュリティ管理と、Google Cloud 環境でデータ ウェアハウスを確実に保護する方法について説明します。
Identity and Access Management(IAM)
Oracle には、リソースへのアクセスを管理するためのユーザー、権限、ロール、プロファイルがあります。
BigQuery では IAM を使用して、リソースへのアクセスの管理と、リソースとアクションに対する一元的なアクセス管理を行います。BigQuery で使用できるリソースには、組織、プロジェクト、データセット、テーブル、ビューがあります。IAM ポリシー階層では、データセットはプロジェクトの子リソースになります。テーブルに対する権限は、そのテーブルを含むデータセットから継承されます。
リソースへのアクセス権を付与するには、ユーザー、グループ、サービス アカウントに 1 つ以上のロールを割り当てます。組織とプロジェクトのロールは、ジョブの実行またはプロジェクトの管理に関して可能な操作を制御します。データセットのロールは、プロジェクト内のデータへのアクセスまたは変更に関して可能な操作を制御します。
IAM には次のタイプのロールがあります。
- 事前定義ロールは、一般的なユースケースとアクセス制御パターンをサポートすることを目的としています。事前定義ロールによって、特定のサービスへのアクセスが細かく制御されます。事前定義ロールは Google Cloud により管理されます。
基本ロールには、オーナー、編集者、閲覧者のロールが含まれます。
カスタムロールは、ユーザー指定の権限のリストに応じたきめ細かなアクセス権を提供します。
事前定義ロールと基本ロールの両方をユーザーに割り当てると、それぞれのロールの権限を結合した権限が付与されます。
行レベルのセキュリティ
Oracle Label Security(OLS)では、行単位でデータアクセスを制限できます。行レベルのセキュリティの一般的な使用例として、営業担当者が管理するアカウントへのアクセスを制限することがあります。行レベルのセキュリティを実装すると、きめ細かなアクセス制御が可能になります。
BigQuery で行レベルのセキュリティを実現するには、承認済みビューと行レベルのアクセス ポリシーを使用できます。これらのポリシーの設計と実装の方法については、BigQuery の行レベルのセキュリティの概要をご覧ください。
フルディスク暗号化
Oracle では、保存データと転送中のデータの暗号化に透過的データ暗号化(TDE)とネットワーク暗号化を使用できます。TDE には Advanced Security オプションが必要です。このオプションを使用するには別途ライセンスを取得する必要があります。
BigQuery は、ソースやその他の条件に関係なく、すべての保存データと転送中のデータをデフォルトで暗号化します。これはオフにできません。Cloud Key Management Service で鍵暗号鍵を制御および管理する場合、BigQuery では顧客管理の暗号鍵(CMEK)もサポートされています。Google Cloud での暗号化の詳細については、デフォルトの保存データの暗号化と転送データの暗号化をご覧ください。
データのマスキングと秘匿化
Oracle は、Real Application Testing のデータ マスキングとデータ秘匿化を使用します。データ秘匿化では、アプリケーションから発行されたクエリから返されるデータをマスク(秘匿化)できます。
BigQuery は、列レベルでの動的データ マスキングをサポートしています。データ マスキングを使用すると、列へのアクセスは許可しながら、ユーザー グループの列データを選択的に難読化できます。
BigQuery で個人情報(PII)を識別して秘匿化するには、機密データの保護を使用します。
BigQuery と Oracle の比較
このセクションでは、BigQuery と Oracle の主な違いについて説明します。これらのハイライトは、移行の障害を特定し、必要な変更を計画する際に役立ちます。
システム アーキテクチャ
Oracle と BigQuery の主な違いの 1 つは、BigQuery は、クエリのニーズに基づいてスケーリングできる個別のストレージ レイヤとコンピューティング レイヤを備えたサーバーレス クラウド EDW である点です。サーバーレス ソリューションという BigQuery の性質上、ハードウェアに関する決定に制限されることはありません。予約を通じてクエリやユーザーのための追加リソースをリクエストできます。BigQuery では、オペレーティング システム(OS)、ネットワーク システム、ストレージ システムの基礎となるソフトウェアやインフラストラクチャ(スケーリングや高可用性など)を構成する必要もありません。BigQuery がスケーラビリティと管理のオペレーションを行います。次の図は、BigQuery のストレージ階層を示しています。
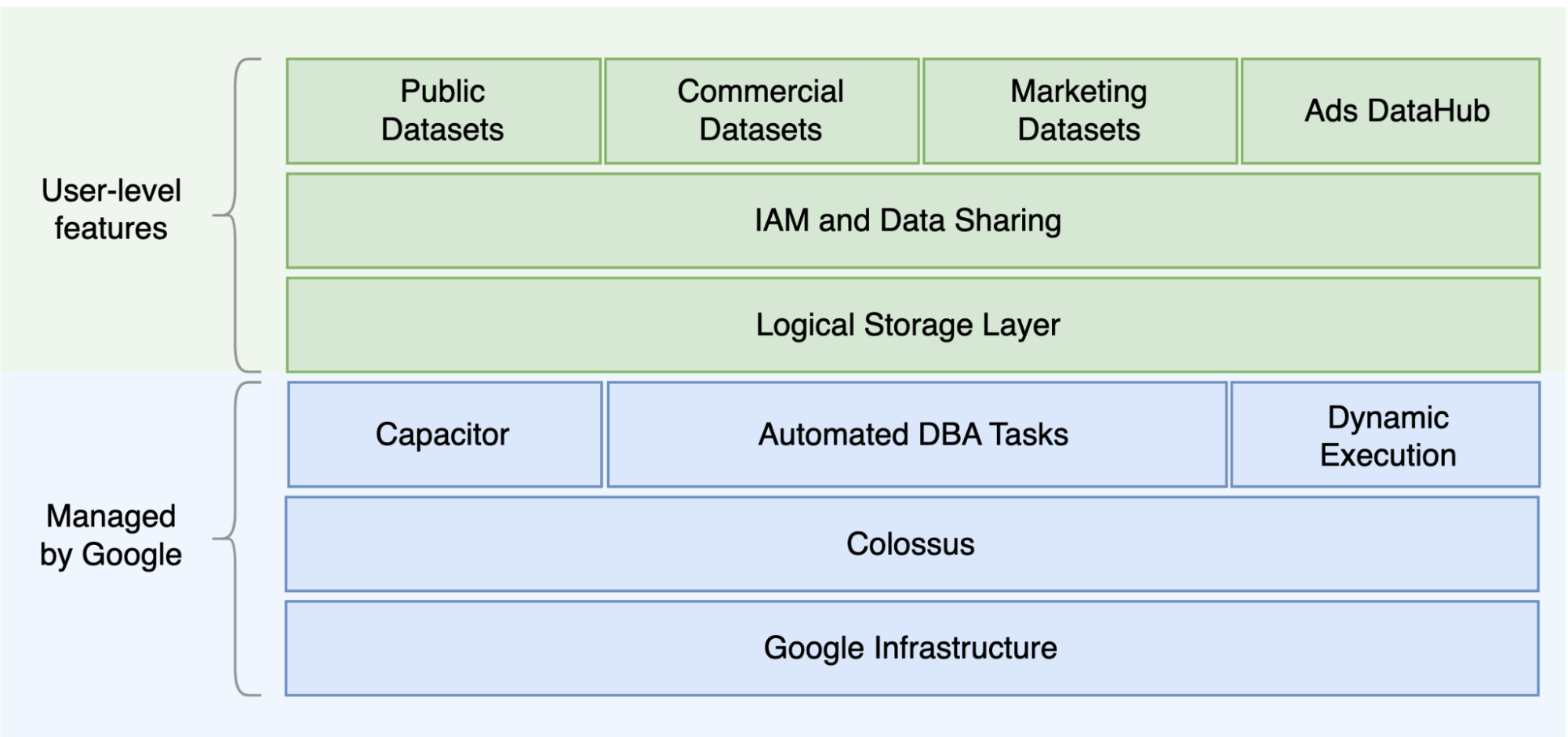
ストレージ(Colossus)とクエリ実行(Dremel)の分離や、Google Cloud がリソースを割り当てる仕組み(Borg)など、基盤となるストレージとクエリ処理のアーキテクチャに関する知識は、動作の違いを理解し、クエリのパフォーマンスとコスト効率を最適化するのに役立ちます。詳細については、BigQuery、Oracle、Exadata のリファレンス システム アーキテクチャをご覧ください。
データとストレージのアーキテクチャ
データとストレージの構造は、クエリのパフォーマンス、コスト、スケーラビリティ、効率性に影響するため、あらゆるデータ分析システムにおける重要な部分です。
BigQuery はデータ ストレージとコンピューティングを分離して、Colossus にデータを保存します。Colossus では、データは Capacitor と呼ばれるカラム型形式で圧縮、保存されます。
BigQuery は Capacitor を使用して圧縮データを解凍することなく、圧縮データを直接操作します。前の図に示すように、BigQuery には、テーブルへのアクセスを整理するための最上位レベルの抽象化としてデータセットが用意されています。テーブルをさらに整理するために、スキーマとラベルを使用できます。BigQuery のパーティショニングにより、クエリのパフォーマンスとコストを改善し、情報ライフサイクルを管理できます。ストレージ リソースはリソースの消費量に応じて割り当てられ、データまたはテーブルを削除したときに割り当てが解除されます。
Oracle では、セグメントに編成されているOracle ブロック形式を使用してデータが行形式で格納されます。スキーマ(ユーザー所有)は、テーブルやその他のデータベース オブジェクトを整理するために使用されます。Oracle 12c では、さらに分離するためにマルチテナントを使用して 1 つのデータベース インスタンス内にプラガブル データベースを作成します。パーティショニングを使用すると、クエリのパフォーマンスと情報ライフサイクル オペレーションを改善できます。Oracle には、ASM、OS ファイル システム、クラスタ ファイル システムなど、スタンドアロン データベースと Real Application Clusters(RAC)データベース向けにストレージ オプションがいくつか用意されています。
Exadata は、ストレージ セルサーバーに最適化されたストレージ インフラストラクチャを提供し、Oracle サーバーが ASM を利用してこのデータに透過的にアクセスできるようにします。Exadata のハイブリッド カラム型圧縮(HCC)オプションにより、ユーザーはテーブルとパーティションを圧縮できます。
Oracle では、ストレージ容量の事前プロビジョニング、慎重なサイズ設定、セグメント、データファイル、およびテーブルスペースでの自動増分構成を行う必要があります。
クエリの実行とパフォーマンス
BigQuery はパフォーマンスを管理し、クエリレベルでスケーリングして、コストに対するパフォーマンスを最大化します。BigQuery では次のようなさまざまな最適化が使用されます。
- インメモリ クエリの実行
- Dremel 実行エンジンに基づくマルチレベル ツリー アーキテクチャ
- Capacitor 内での自動ストレージ最適化
- Jupiter で 1 ペタビット/秒の全二分割帯域幅
- リソース管理の自動スケーリングでペタバイト規模のクエリを高速化
BigQuery はデータの読み込み中に列の統計情報を収集し、診断用のクエリプランとタイミング情報を含めます。クエリリソースはクエリのタイプと複雑度に応じて割り当てられます。クエリごとにいくつかのスロットが使用されます。スロットとは、一定量の CPU と RAM で構成されるコンピューティング能力の単位です。
Oracle には、データ統計情報収集ジョブがあります。データベース オプティマイザーは、統計情報を使用して最適な実行プランを提供します。行の高速検索と結合オペレーションにインデックスが必要になる場合があります。Oracle にはインメモリ分析用のインメモリ列ストアも用意されています。Exadata には、セルのスマート スキャン、ストレージ インデックス、フラッシュ キャッシュ、ストレージ サーバーとデータベース サーバー間の InfiniBand 接続など、さまざまなパフォーマンス改善機能があります。Real Application Clusters(RAC)を使用すると、サーバーの高可用性を実現し、基盤となる同じストレージを使用して CPU 負荷の高いデータベース アプリケーションをスケーリングできます。
Oracle でのクエリのパフォーマンスを最適化するには、これらのオプションとデータベース パラメータを慎重に検討する必要があります。Oracle には、Active Session History(ASH)、Automatic Database Diagnostic Monitor(ADDM)、Automatic Workload Repository(AWR)レポート、SQL Monitoring と Tuning Advisor、Undo Advisor と Memory Tuning Advisor などのパフォーマンス チューニング用のツールが用意されています。
アジャイル分析
BigQuery では、さまざまなプロジェクト、ユーザー、グループがさまざまなプロジェクトのデータセットに対してクエリを実行できるように設定できます。クエリ実行の分離により、自律型チームは、スロット割り当てを分離し、データセットをホストするプロジェクトやほかのプロジェクトからの請求をクエリすることで、他のユーザーやプロジェクトに影響を与えることなく各自のプロジェクト内で作業できます。
高可用性、バックアップ、障害復旧
Oracle は、障害復旧とデータベース レプリケーション ソリューションとして Data Guard を提供しています。Real Application Clusters(RAC) を構成してサーバーの可用性を高めることができます。Recovery Manager(RMAN)バックアップは、データベースとアーカイブログのバックアップ用に構成でき、リストアとリカバリのオペレーションにも使用できます。フラッシュバック データベース機能をデータベースのフラッシュバックに使用して、データベースを特定の時点に戻すことができます。Undo テーブルスペース、テーブルのスナップショットを保持します。以前に実行された DML/DDL オペレーションとUndo 保存設定に応じて、フラッシュバック クエリと「as of」クエリ句を使用して古いスナップショットをクエリできます。Oracle では、システム メタデータ、Undo、対応するテーブルスペースに依存するテーブルスペース内でデータベースの整合性を管理する必要があります。これは、Oracle のバックアップでは強整合性が重要であり、リカバリ手順に完全なプライマリ データを含める必要があるためです。Oracle でポイントインタイム リカバリが不要な場合は、テーブル スキーマレベルでエクスポートをスケジュールできます。
BigQuery はフルマネージド サービスであり、バックアップ機能全体が従来のデータベース システムとは異なります。サーバー、ストレージ障害、システムバグ、物理的なデータ破損を考慮する必要はありません。BigQuery は、信頼性と可用性を最大化するために、データセットのロケーションに応じて異なるデータセンターにデータを複製します。BigQuery のマルチリージョン機能は、異なるリージョン間でデータを複製し、リージョン内の単一ゾーンが使用不能になることを防ぎます。BigQuery のシングルリージョン機能は、同じリージョン内の異なるゾーン間でデータを複製します。
BigQuery では、最大 7 日間のテーブルの履歴スナップショットをクエリできます。また、タイムトラベルを使用して、2 日以内に削除されたテーブルを復元できます。削除されたテーブルは、スナップショット構文(dataset.table@timestamp)を使用して(復元の目的で)コピーできます。追加のバックアップのニーズ(偶発的なユーザー オペレーションからの復元など)に対応するために、BigQuery テーブルからデータをエクスポートできます。バックアップには、既存のデータ ウェアハウス(DWH)システムで使用されている実績のあるバックアップ戦略とスケジュールを使用できます。
バッチ オペレーションとスナップショット手法では、BigQuery にさまざまなバックアップ戦略を利用できるので、変更されていないテーブルやパーティションを頻繁にエクスポートする必要がありません。読み込みまたは ETL オペレーションの完了後は、パーティションまたはテーブルのバックアップのエクスポート バックアップは 1 つで十分です。バックアップのコストを削減するには、エクスポート ファイルを Cloud Storage の Nearline Storage または Coldline Storage に保存して、データ保持要件に応じて特定の時間の経過後にファイルを削除するためのライフサイクル ポリシーファイルを定義できます。
キャッシュ
BigQuery ではユーザーごとのキャッシュが用意されています。データが変更されない場合、クエリの結果は約 24 時間キャッシュに保存されます。結果がキャッシュから取得される場合、クエリのコストは発生しません。
Oracle には、バッファ キャッシュ、結果キャッシュ、Exadata フラッシュ キャッシュ、インメモリ列ストアなど、データとクエリ結果のための各種キャッシュがあります。
接続
BigQuery が接続管理を処理するため、サーバー側の構成を行う必要はありません。BigQuery には JDBC ドライバと ODBC ドライバ が用意されています。インタラクティブ クエリを実行するには Google Cloud コンソールまたは bq command-line tool を使用できます。REST APIとクライアント ライブラリを使用して、BigQuery をプログラマティックに操作できます。BigQuery に直接 Google スプレッドシートを接続できます。また、Excel 用の BigQuery コネクタもあります。デスクトップ クライアントをお探しの場合は、DBeaver などの無料ツールをご利用いただけます。
Oracle では、データベースの接続を処理するための リスナー、サービス、サービス ハンドラ、構成と調整のパラメータ、共有サーバーと専用サーバーが提供されます。Oracle では、JDBC ドライバ、JDBC Thin クライアント、ODBC ドライバ、Oracle クライアント、TNS 接続を使用できます。RAC 構成には、スキャン リスナー、スキャン IP アドレス、スキャン名が必要です。
料金とライセンス
Oracle では、Database エディションのコア数と データベース オプション(RAC、マルチテナント、Active Data Guard、パーティショニング、インメモリ、Real Application Testing、GoldenGate、Spatial and Graph など)に基づくライセンスとサポート料金が必要です。
BigQuery では、ストレージ、クエリ、ストリーミング挿入の使用量に基づく柔軟な料金オプションが用意されています。BigQuery では、特定のリージョンで予測可能な費用とスロット容量が必要なお客様向けに 容量ベースの料金が用意されています。ストリーミング挿入と読み込みに使用されるスロットは、プロジェクト スロットの容量にはカウントされません。データ ウェアハウス用に購入するスロット数を決定するには、BigQuery のキャパシティ プランニングをご覧ください。
また BigQuery では、保存期間が 90 日を超える未変更のデータについて、ストレージ費用が自動的に半分に削減されます。
ラベル付け
BigQuery のデータセット、テーブル、ビューには、Key-Value ペアでラベル付けできます。ラベルは、ストレージ費用と内部チャージバックを区別するために使用できます。
モニタリングと監査ロギング
Oracle は、さまざまなレベルと種類のデータベース監査オプションと Audit Vault および Database Firewall 機能(別途ライセンスが必要)を提供しています。Oracle はデータベース モニタリング用の Enterprise Manager を提供しています。
BigQuery では、データアクセス ログと監査ログの両方に Cloud Audit Logs が使用されます。これはデフォルトで有効になっています。データアクセス ログは 30 日間、その他のシステム イベントと管理アクティビティ ログは 400 日間利用できます。これよりも長い期間にわたって保持する必要がある場合は、Google Cloud におけるセキュリティ ログ分析に説明されているように、ログを BigQuery、Cloud Storage、Pub/Sub にエクスポートできます。既存のインシデント モニタリング ツールと統合する必要がある場合は、エクスポートに Pub/Sub を使用できます。Pub/Sub からログを読み取るには、既存のツールでカスタム開発を行う必要があります。
監査ログには、すべての API 呼び出し、クエリ ステートメント、ジョブ ステータスが記録されます。Cloud Monitoring を使用して、スロットの割り当て、クエリでスキャンされて保存されたバイト数、その他の BigQuery 指標をモニタリングできます。BigQuery のクエリプランとタイムラインを使用して、クエリのステージとパフォーマンスを分析できます。
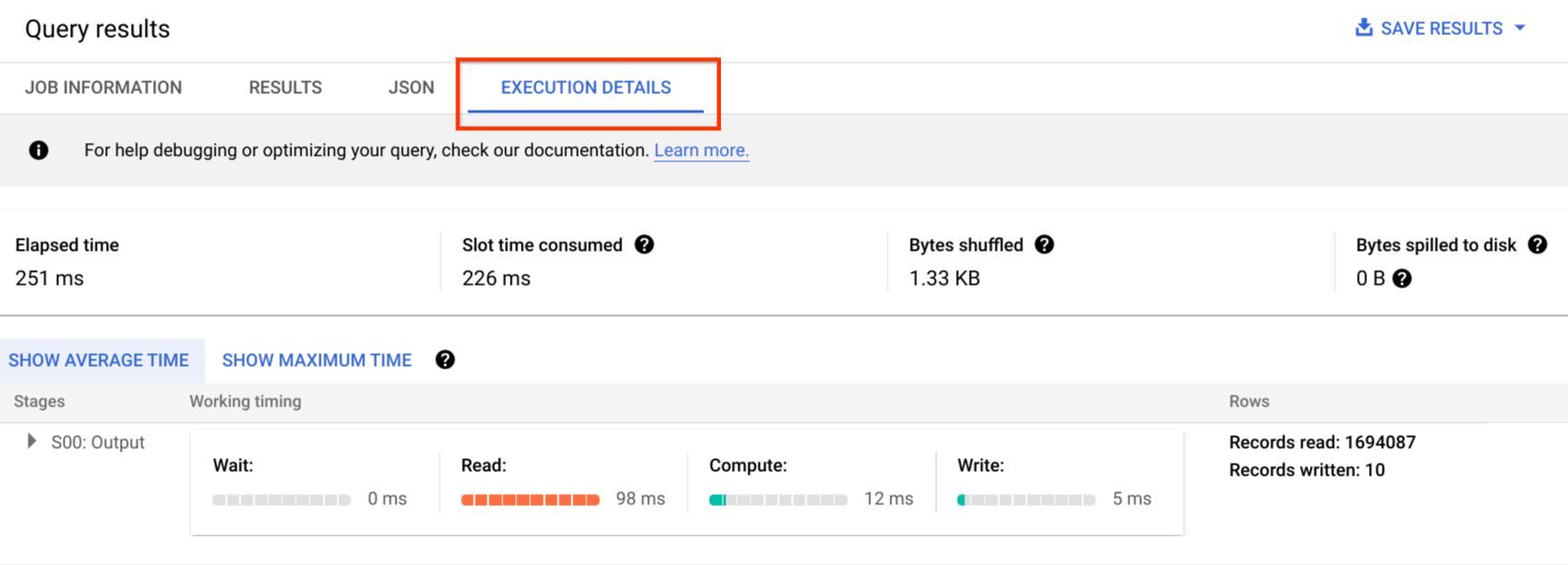
クエリジョブと API エラーのトラブルシューティングには、エラー メッセージの表を使用できます。クエリまたはジョブごとにスロットの割り当てを区別するには、このユーティリティを使用します。このユーティリティは、容量ベースの料金を利用し、多数のプロジェクトが複数のチームに分散しているお客様にとって有益です。
メンテナンス、アップグレード、バージョン
BigQuery はフルマネージド サービスであり、メンテナンスやアップグレードを行う必要はありません。BigQuery は複数のバージョンを提供していません。アップグレードは継続的に行わるため、ダウンタイムは発生せず、システム パフォーマンスは低下しません。詳細については、リリースノートをご覧ください。
Oracle と Exadata では、データベースと基盤となるインフラストラクチャのレベルでパッチ適用、アップグレード、メンテナンスが必要です。Oracle には複数のバージョンがあり、新しいメジャー バージョンが毎年リリースされる予定です。新しいバージョンには下位互換性がありますが、クエリのパフォーマンス、コンテキスト、機能が変更される可能性があります。
アプリケーションによっては特定のバージョン(10g、11g、12c など)を必要となることがあります。データベースのメジャー アップグレードの際には、入念な計画とテストが必要です。異なるバージョンからの移行では、クエリ句とデータベース オブジェクトについてさまざまな技術的な変換が必要となることがあります。
ワークロード
Oracle Exadata では、OLTP ワークロードを含む混合ワークロードがサポートされています。BigQuery は分析用に設計されており、OLTP ワークロードを処理するようには設計されていません。同じ Oracle を使用する OLTP ワークロードを、Google Cloud の Cloud SQL、Spanner、または Firestore に移行する必要があります。Oracle は、Advanced Analytics や Spatial and Graph などの追加オプションを提供しています。これらのワークロードを BigQuery に移行するには、書き換えが必要となる場合があります。詳細については、Oracle オプションの移行をご覧ください。
パラメータと設定
Oracle には多数のパラメータがあり、OS、データベース、RAC、ASM、リスナーのレベルで、さまざまなワークロードとアプリケーションに対応してこれらのパラメータを構成および調整する必要があります。BigQuery はフルマネージド サービスであり、初期化パラメータを構成する必要はありません。
制限と割り当て
Oracle では、インフラストラクチャ、ハードウェア容量、パラメータ、ソフトウェア バージョン、ライセンスに基づくハードリミットとソフトリミットがあります。BigQuery では、特定のアクションとオブジェクトに対する割り当てと上限があります。
BigQuery のプロビジョニング
BigQuery は Platform as a Service(PaaS)であり、Cloud の超並列処理データ ウェアハウスです。Google によりバックエンドが管理されるため、ユーザーの介入なしで容量がスケールアップまたはスケールダウンされます。その結果、多くの RDBMS システムとは異なり、BigQuery では使用する前にリソースをプロビジョニングしておく必要はありません。BigQuery は、使用パターンを基準に、ストレージ リソースとクエリリソースを動的に割り当てます。ストレージ リソースはリソースの消費量に応じて割り当てられ、データまたはテーブルを削除したときに割り当てが解除されます。クエリリソースはクエリのタイプと複雑度に応じて割り当てられます。各クエリはスロットを使用します。最終的な公平性を確保するスケジューラが使用されているので、短期的にいくつかのクエリでスロットの割り当てが不均衡になることもありますが、これはスケジューラによって最終的に是正されます。
従来の VM の用語で言えば、BigQuery では次の 2 つを両立していることになります。
- 秒単位の課金
- 秒単位のスケーリング
このタスクを完了するために BigQuery は次の処理を行います。
- 急激にスケーリングしなければならない状況を回避するために、膨大な数のリソースをデプロイし続けています。
- マルチテナント リソースを使用して、一度に数秒間、大きなチャンクを瞬間的に割り当てます。
- スケール メリットを活用して、各ユーザーにリソースを効率的に割り当てます。
- 課金対象は、デプロイされたリソースではなく、実行したジョブであるため、使用したリソースのみに対して支払います。
料金の詳細については、BigQuery の高速スケーリングとシンプルな料金設定についてをご覧ください。
スキーマの移行
Oracle から BigQuery にデータを移行するには、Oracle のデータ型と BigQuery のマッピングを把握している必要があります。
Oracle のデータ型と BigQuery のマッピング
Oracle のデータ型は、BigQuery のデータ型と異なります。BigQuery のデータ型の詳細については、公式ドキュメントをご覧ください。
Oracle と BigQuery のデータ型の詳細な比較については、Oracle SQL 変換ガイドをご覧ください。
インデックス
多くの分析ワークロードでは、行ストアの代わりにカラム型テーブルが使用されます。これにより、列ベースのオペレーションが大幅に増加し、バッチ分析でインデックスを使用する必要がなくなります。また、BigQuery はカラム型形式でデータを保存するため、BigQuery ではインデックスは不要です。分析ワークロードに 1 つの小さな行ベースのアクセス権のセットが必要な場合は、Bigtable を使用することをおすすめします。ワークロードに優れたリレーショナル整合性のあるトランザクション処理が必要な場合は、代わりに Spanner または Cloud SQL を使用することをおすすめします。
要約すると、BigQuery ではバッチ分析用にインデックスは不要であり、提供されていません。パーティショニングとクラスタリングを使用できます。BigQuery でクエリ パフォーマンスを調整して改善する方法については、クエリ パフォーマンスの最適化の概要をご覧ください。
ビュー
Oracle と同様に BigQuery でもカスタムビューを作成できます。ただし、BigQuery のビューは DML ステートメントをサポートしていません。
マテリアライズド ビュー
マテリアライズド ビューは、書き込みが 1 回で何度でも読み取りできるタイプのレポートとワークロードでのレポートのレンダリング時間を短縮するためによく使用されます。
Oracle のマテリアライズド ビューは、クエリ結果のデータセットを保持するテーブルを作成、維持することでビューのパフォーマンスを改善できるようにする目的で提供されています。Oracle でマテリアライズド ビューをリフレッシュする方法には、コミット時とオンデマンドの 2 種類があります。
BigQuery でもマテリアライズド ビュー機能を使用できます。BigQuery は、事前に計算されたマテリアライズド ビューの結果を利用し、可能な場合にはベーステーブルからの差分のみを読み取って最新の結果を計算します。
Looker Studio やその他の最新の BI ツールのキャッシュ機能を使用することで、パフォーマンスが向上し、同じクエリを再実行する必要がなくなるため、コストを削減できます。
テーブルのパーティショニング
テーブルのパーティショニングは、Oracle データ ウェアハウスで広く使用されています。Oracle とは異なり、BigQuery では階層型パーティショニングはサポートされていません。
BigQuery は、3 種類のテーブル パーティショニングを実装しています。これにより、パーティショニング列に基づく述語フィルタをクエリで指定して、スキャンされるデータの量を減らすことができます。
- 取り込み時間で分割されたテーブル: データの取り込み時間に基づいてテーブルが分割されます。
- 列で分割されたテーブル:
TIMESTAMPまたはDATE列に基づいてテーブルが分割されます。 - 整数範囲で分割されたテーブル: 整数列に基づいて分割されたテーブルです。
BigQuery のパーティション分割テーブルに適用される上限と割り当てについては、パーティション分割テーブルの概要をご覧ください。
BigQuery の制限が移行されたデータベースの機能に影響する場合は、パーティショニングではなくシャーディングの使用を検討してください。
さらに、BigQuery では EXCHANGE PARTITION、SPLIT PARTITION がサポートされていません。パーティション分割されていないテーブルからパーティション分割テーブルへの変換もサポートされていません。
クラスタリング
クラスタリングは、一緒にアクセスされることが多い複数の列に保存されているデータを効率的に整理して取得するのに役立ちます。ただし、Oracle と BigQuery ではクラスタリングが最適に機能する状況が異なります。テーブルがフィルタリングされ、特定の列で集計されることが一般的な場合、BigQuery ではクラスタリングを使用します。Oracle からリスト パーティションテーブルまたは索引構成テーブルを移行する場合は、クラスタリングを検討できます。
一時テーブル
一時テーブルは Oracle ETL パイプラインでよく使用されます。一時テーブルは、ユーザー セッション中のデータを保持します。このデータは、セッションの終了時に自動的に削除されます。
BigQuery は、永続的なテーブルに書き込まれていない一時テーブルを使用してクエリ結果をキャッシュに保存します。クエリの終了後、一時テーブルは最大 24 時間存在します。テーブルは、特別なデータセット内に作成され、ランダムに名前が付けられます。独自に使用するために、一時テーブルを作成することもできます。詳細については、一時テーブルをご覧ください。
外部テーブル
Oracle と同様に、BigQuery でも外部データソースに対してクエリを実行できます。BigQuery では、次のような外部データソースのデータに対して直接クエリを実行できます。
- Amazon Simple Storage Service(Amazon S3)
- Azure Blob Storage
- Bigtable
- Spanner
- Cloud SQL
- Cloud Storage
- Google ドライブ
データ モデリング
スター データモデルまたはスノーフレーク データモデルは、分析用のストレージとして効率的であり、Oracle Exadata のデータ ウェアハウスによく使用されます。
非正規化テーブルにより、コストの高い結合オペレーションが不要になり、ほとんどの場合は BigQuery での分析のパフォーマンスが向上します。BigQuery でもスター データモデルとスノーフレーク データモデルがサポートされています。BigQuery のデータ ウェアハウス設計の詳細については、スキーマの設計をご覧ください。
行形式と列形式の違いとサーバー制限とサーバーレスの違い
Oracle では行形式を使用して、テーブルの行をデータブロックに保存します。このため、特定の列のフィルタリングと集計に基づいて、分析クエリのブロック内で不要な列が取得されます。
Oracle のアーキテクチャは「すべて共有」型であり、メモリやストレージなどの固定ハードウェア リソース依存関係がサーバーに割り当てられます。これらは、ストレージの効率と分析クエリのパフォーマンスの改善のために進化してきた多くのデータ モデリング手法の基盤となる 2 つの要素です。スタースキーマ、スノーフレーク スキーマ、データボルトモデリングなどはその一例です。
BigQuery はカラム型形式でデータを格納し、ストレージとメモリの上限は固定されていません。このアーキテクチャにより、読み取りとビジネスニーズに基づいてスキーマをさらに非正規化して設計できるため、複雑さが軽減され、柔軟性、スケーラビリティ、パフォーマンスが向上します。
非正規化
リレーショナル データベースの正規化の主な目的の 1 つに、データの冗長性を減らすことがあります。このモデルは行形式を使用するリレーショナル データベースに最適ですが、カラム型データベースにはデータの非正規化が適しています。BigQuery でのデータを非正規化するメリットやその他のクエリ最適化戦略については、非正規化をご覧ください。
既存のスキーマをフラット化する手法
BigQuery テクノロジーは、カラム型データへのアクセスと処理、インメモリ ストレージ、分散処理を組み合わせて、高品質のクエリ パフォーマンスを実現します。
BigQuery DWH スキーマを設計する際は、ファクト テーブルをフラットなテーブル構造で作成する(すべてのディメンション テーブルをファクト テーブルの単一のレコードに統合する)方が、複数の DWH ディメンションを使用するよりもストレージ使用率が良くなります。BigQuery でフラット テーブルを使用すると、ストレージ使用率の削減の他に、JOIN の使用量も削減できます。次の図は、スキーマをフラット化する例を示しています。
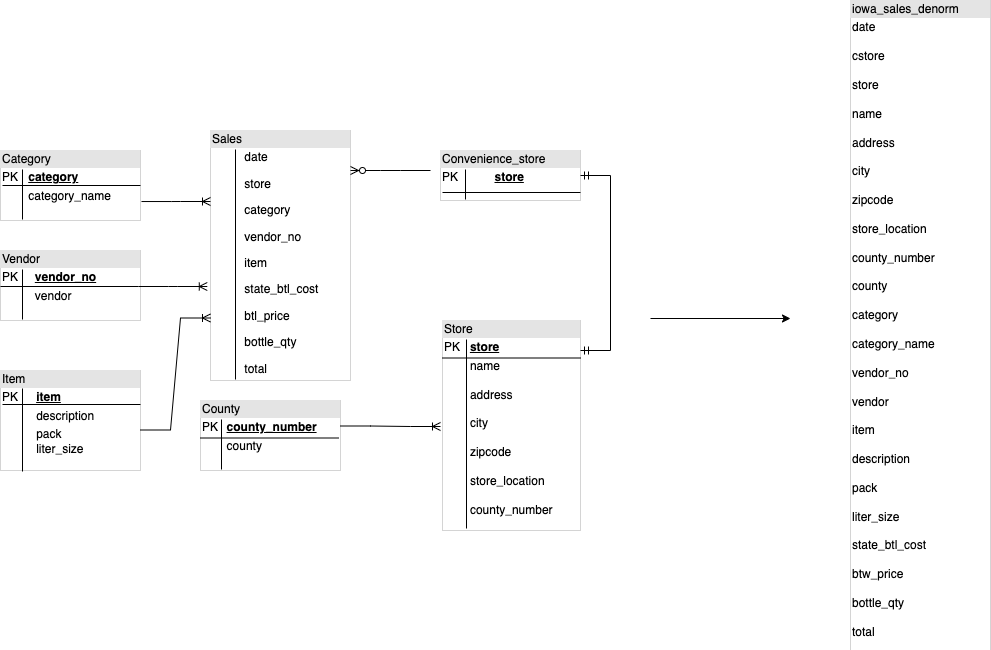
スタースキーマのフラット化の例
図 1 は、4 つのテーブルを含む架空の販売管理データベースを示しています。
- Orders / 販売テーブル(ファクト テーブル)
- Employee テーブル
- Location テーブル
- Customer テーブル
販売テーブルの主キーは OrderNum です。これには他の 3 つのテーブルの外部キーも含まれます。
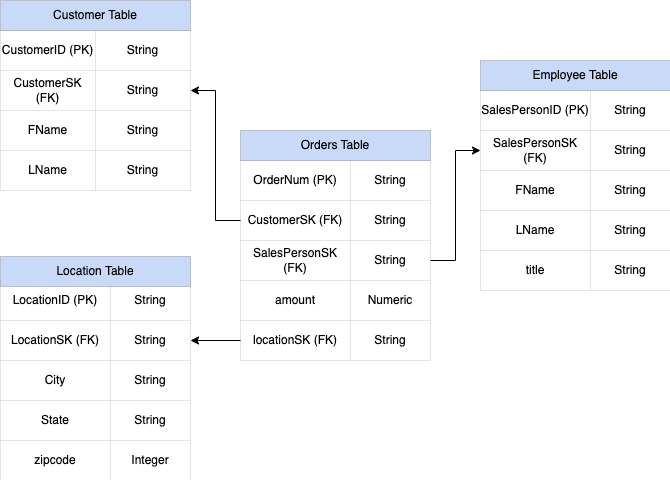
図 1: スタースキーマでの販売データのサンプル
サンプルデータ
Orders / ファクト テーブルの内容
| OrderNum | CustomerID | SalesPersonID | amount | Location |
| O-1 | 1234 | 12 | 234.22 | 18 |
| O-2 | 4567 | 1 | 192.10 | 27 |
| O-3 | 12 | 14.66 | 18 | |
| O-4 | 4567 | 4 | 182.00 | 26 |
Employee テーブルの内容
| SalesPersonID | FName | LName | title |
| 1 | Alex | Smith | Sales Associate |
| 4 | Lisa | Doe | Sales Associate |
| 12 | John | Doe | Sales Associate |
Customer テーブルの内容
| CustomerID | FName | LName |
| 1234 | Amanda | Lee |
| 4567 | Matt | Ryan |
Location テーブルの内容
| Location | City | City | City |
| 18 | Bronx | NY | 10452 |
| 26 | Mountain View | CA | 90210 |
| 27 | Chicago | IL | 60613 |
LEFT OUTER JOIN を使用してデータをフラット化するクエリ
#standardSQL INSERT INTO flattened SELECT orders.ordernum, orders.customerID, customer.fname, customer.lname, orders.salespersonID, employee.fname, employee.lname, employee.title, orders.amount, orders.location, location.city, location.state, location.zipcode FROM orders LEFT OUTER JOIN customer ON customer.customerID = orders.customerID LEFT OUTER JOIN employee ON employee.salespersonID = orders.salespersonID LEFT OUTER JOIN location ON location.locationID = orders.locationID
フラット化されたデータの出力
| OrderNum | CustomerID | FName | LName | SalesPersonID | FName | LName | amount | Location | City | State | zipcode |
| O-1 | 1234 | Amanda | Lee | 12 | John | Doe | 234.22 | 18 | Bronx | NY | 10452 |
| O-2 | 4567 | Matt | Ryan | 1 | Alex | Smith | 192.10 | 27 | Chicago | IL | 60613 |
| O-3 | 12 | John | Doe | 14.66 | 18 | Bronx | NY | 10452 | |||
| O-4 | 4567 | Matt | Ryan | 4 | Lisa | Doe | 182.00 | 26 | Mountain View |
CA | 90210 |
ネストされたフィールドと繰り返しフィールド
リレーショナル スキーマ(ディメンション テーブルとファクト テーブルを保持するスタースキーマやスノーフレーク スキーマなど)から DWH スキーマを設計して作成するために、BigQuery にはネストされたフィールドと繰り返しフィールドの機能が用意されています。したがって、パフォーマンスに影響を与えることなく、正規化(または部分正規化)されたリレーショナル DWH スキーマと同様の方法で関係を保持できます。詳細については、パフォーマンスに関するベスト プラクティスをご覧ください。
ネストされたフィールドと繰り返しフィールドの実装を詳しく理解するには、CUSTOMERS テーブルと ORDER/SALES テーブルの単純なリレーショナル スキーマをご覧ください。これらは、2 つの異なるテーブル(エンティティごとに 1 つ)です。JOIN を使用したクエリの実行時に、キー(主キーや外部キーなど)をテーブル間のリンクとして使用して、関係が定義されます。BigQuery のネストされたフィールドと繰り返しフィールドを使用すると、1 つのテーブルのエンティティ間で同じ関係を維持できます。これは、すべての顧客データを含めることで実装できます。また、注文データは顧客ごとにネストされています。詳しくは、ネストされた列と繰り返し列の指定をご覧ください。
フラット構造をネストされたスキーマまたは繰り返しスキーマに変換するには、フィールドを次のようにネストします。
- 新しいフィールド
Customerの中にCustomerID、FName、LNameをネストする。 - 新しいフィールド
Salespersonの中にSalesPersonID、FName、LNameをネストする。 - 新しいフィールド
Locationの中にLocationID、city、state、zip codeをネストする。
フィールド OrderNum と amount は一意の要素を表すため、ネストされません。
すべての注文に複数の顧客(プライマリとセカンダリ)を割り当てることができるように、スキーマに柔軟性を持たせる必要があります。Customer フィールドは繰り返しとしてマークされています。結果のスキーマを図 2 に示します。これは、ネストされたフィールドと繰り返しフィールドを示しています。
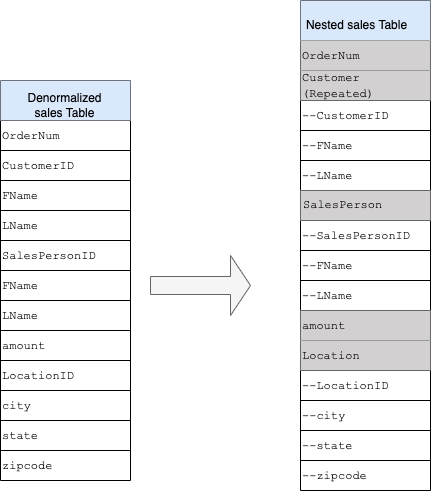
図 2: ネスト構造の論理表現
ネストされたフィールドと繰り返しフィールドを使用して非正規化しても、パフォーマンスの向上につながらない場合があります。ネストされたフィールドと繰り返しフィールドの制限の詳細については、非正規化されたデータ、ネストされたデータ、繰り返しデータの読み込みをご覧ください。
サロゲート キー
テーブル内で一意のキーを含む行を指定することは一般的です。Oracle では、一意のキーを作成するためにシーケンスがよく使用されます。BigQuery では、row_number 関数と partition by 関数を使用してサロゲートキーを作成できます。詳細については、BigQuery とサロゲートキー: 実践的なアプローチをご覧ください。
変更と履歴の追跡
BigQuery DWH の移行を計画する際には、変化が緩やかなディメンション(SCD)のコンセプトを考慮してください。一般に SCD という用語は、ディメンション テーブルに変更を加えるプロセス(DML オペレーション)を表します。
いくつかの理由から、従来のデータ ウェアハウスでは、変化が緩やかなディメンションでのデータ変更の処理と過去のデータの保存にさまざまなタイプが使用されています。このようなタイプの使用は、前述のハードウェアの制限と効率性の要件で必要となります。ストレージはコンピューティングよりもはるかに低価格で、無制限にスケーラブルであるため、データの冗長性と複製によって BigQuery でクエリが高速化する場合には、これらが推奨されます。データ スナップショット手法を使用できます。この手法では、データ全体が新しい日次パーティションに読み込まれます。
ロール固有のビューとユーザー固有のビュー
ユーザーが異なるチームに所属しており、ユーザーに対して必要なレコードと結果のみを表示する場合は、ロール固有のビューとユーザー固有のビューを使用します。
BigQuery は列レベルのセキュリティと行レベルのセキュリティをサポートしています。列レベルのセキュリティでは、データのポリシータグ(型ベースの分類)を使用し、機密性の高い列に対してきめ細かいアクセスを行うことができます。行レベルのセキュリティでは、データをフィルタリングし、ユーザーの資格条件に基づいてテーブル内の特定の行へのアクセスを許可できます。
データの移行
このセクションでは、Oracle から BigQuery へのデータ移行(初期読み込み、変更データ キャプチャ(CDC)、ETL/ELT のツールとアプローチなど)について説明します。
移行作業
移行の適切なユースケースを特定して、段階的に移行を実施することをおすすめします。Oracle から Google Cloud にデータを移行するためのツールとサービスは複数あります。このリストはすべてを網羅したものではありませんが、移行作業の規模と範囲を把握するのに役立ちます。
Oracle からのデータのエクスポート: 詳細については、初期読み込みと Oracle から BigQuery への CDC とストリーミング取り込みをご覧ください。初期読み込みには ETL ツールを使用できます。
データのステージング(Cloud Storage): Oracle からデータをエクスポートする際のランディング用の場所(ステージング領域)として、Cloud Storage をおすすめします。Cloud Storage は、構造化データまたは非構造化データを迅速かつ柔軟に取り込めるように設計されています。
ETL プロセス: 詳しくは、ETL/ELT の移行をご覧ください。
BigQuery へのデータの直接読み込み: Cloud Storage から直接、Dataflow またはリアルタイム ストリーミングを介して BigQuery にデータを読み込むことができます。データ変換が必要な場合は、Dataflow を使用します。
初期読み込み
既存の Oracle データ ウェアハウスから BigQuery への初期データの移行は、データサイズとネットワーク帯域幅によっては、増分 ETL/ELT パイプラインとは異なる場合があります。データサイズが数テラバイトの場合は、同じ ETL/ELT パイプラインを使用できます。
データが数テラバイト以下の場合は、データをダンプして gsutil を使用して転送する方が、JdbcIO のようなプログラムによるデータベース抽出手法を使用するよりもはるかに効率的です。これは、プログラムによる手法ではパフォーマンスを細かく調整する必要があるためです。データサイズが数テラバイトを超え、データがクラウドまたはオンライン ストレージ(Amazon Simple Storage Service(Amazon S3)など)に保存されている場合は、BigQuery Data Transfer Service の使用を検討してください。大規模な転送(特にネットワーク帯域幅が限られている転送)では、Transfer Appliance が便利です。
初期読み込みの制約
データの移行を計画する際には次の点を考慮してください。
- Oracle DWH のデータサイズ: スキーマのソースサイズは、特にデータサイズが大きい場合(テラバイト以上)、選択したデータ転送方法に大きく影響します。データサイズが比較的小さい場合、データ転送プロセスはより少ないステップで完了できます。大規模なデータサイズを扱う場合、プロセス全体が複雑になります。
ダウンタイム: BigQuery への移行でダウンタイムが許容可能かどうかを判断することが重要です。ダウンタイムを削減するには、安定した過去のデータを一括で読み込み、転送プロセス中に発生した変更に追いつくための CDC ソリューションを用意します。
料金: シナリオによっては、追加のライセンスを必要とするサードパーティ統合ツール(ETL やレプリケーション ツールなど)が必要になる場合があります。
初期データ転送(バッチ)
バッチ方式を使用したデータ転送では、1 つのプロセスでデータが確実にエクスポートされます(たとえば、Oracle DWH スキーマデータを CSV、Avro、Parquet ファイルにエクスポートすることや、BigQuery でデータセットを作成するために Cloud Storage にインポートすることなどです)。初期読み込みでは、ETL/ELT の移行で説明されているすべての ETL ツールとコンセプトをすべて使用できます。
初期読み込みに ETL/ELT ツールを使用しない場合は、カスタムスクリプトを作成してデータをファイル(CSV、Avro、Parquet)にエクスポートし、gsutil、BigQuery Data Transfer Service、または Transfer Appliance を使用して Cloud Storage にアップロードできます。大規模なデータ転送のパフォーマンス調整と転送オプションの詳細については、大規模なデータセットの転送をご覧ください。次に、Cloud Storage から BigQuery にデータを読み込みます。
Cloud Storage は、データの初回取り込みの処理に最適です。Cloud Storage は高可用性と耐久性を備えたオブジェクト ストレージ サービスであり、保存できるファイル数に制限はありません。料金は使用したストレージのみを対象に発生します。このサービスは、BigQuery や Dataflow などの他の Google Cloud サービスと連携するように最適化されています。
Oracle から BigQuery への CDC とストリーミング取り込み
変更されたデータを Oracle からキャプチャする方法はいくつかあります。それぞれの方法にはトレードオフがあります。これは主に、移行元システムのパフォーマンスへの影響、開発と構成の要件、料金とライセンスに関するトレードオフです。
ログベースの変更データ キャプチャ(CDC)
Oracle GoldenGate は、REDO ログ抽出ツールとして Oracle が推奨するツールです。BigQuery にログをストリーミングするには、GoldenGate for Big Data を使用できます。GoldenGate には CPU ごとのライセンスが必要です。料金については、Oracle Technology Global Price List をご覧ください。Oracle GoldenGate for Big Data が利用可能な場合(ライセンス取得済みの場合)、GoldenGate を使用して、データ パイプラインを作成してデータを転送し(初期読み込み)、すべてのデータ変更を同期することをおすすめします。
Oracle XStream
Oracle では、すべての commit が REDO ログファイルに保存されます。これらの REDO ファイルを CDC に使用できます。Oracle XStream Out は LogMiner の上に構築され、Debezium(バージョン 0.8 以降)などのサードパ―ティツールにより提供されます。また Alooma や Striim などのツールを使用している場合には別途購入可能です。XStream API を使用するには、GoldenGate をインストールして使用していない場合でも、Oracle GoldenGate のライセンスを購入する必要があります。XStream を使用すると、Oracle と他のソフトウェアの間でストリーム メッセージを効率的に伝播できます。
Oracle LogMiner
LogMiner には特別なライセンスは必要ありません。LogMiner オプションは Debezium コミュニティ コネクタで使用できます。Attunity、Striim、StreamSets などのツールを使用している場合は別途購入可能です。LogMiner は、非常にアクティブなソース データベースのパフォーマンスに影響する可能性があるため、サーバーの CPU、メモリ、I/O 容量、使用率に応じて 1 時間あたりの変更量(REDO のサイズ)が 10 GB を超える場合は、慎重に使用する必要があります。
SQL ベースの CDC
これは増分 ETL アプローチであり、単調に増加するキーと、最終更新日時または挿入日を保持するタイムスタンプ列に基づいて、SQL クエリでソーステーブルを継続的にポーリングし、変更を確認します。単調に増加するキーがない場合、小さな精度(秒)のタイムスタンプ列(変更日)を使用すると、ボリュームと比較演算子(>、>= など)によっては重複レコードや欠落データが発生する可能性があります。
このような問題に対処するには、タイムスタンプ列で 6 桁の小数桁数(マイクロ秒、BigQuery でサポートされている最大精度)などの高精度を使用するか、ビジネスキーとデータの特性に応じて ETL/ELT パイプラインに重複排除タスクを追加します。
抽出パフォーマンスを改善し、ソース データベースへの影響を抑えるには、キーまたはタイムスタンプ列にインデックスを作成する必要があります。削除オペレーションは、ソース アプリケーションでは復元可能な削除の手法(削除フラグの設定や last_modified_date の更新など)で処理する必要があるため、この方法においては課題となります。代わりに、トリガーを使用してこのオペレーションを別のテーブルに記録できます。
トリガー
ソーステーブルにデータベース トリガーを作成して、変更をシャドー ジャーナル テーブルに記録できます。ジャーナル テーブルには、すべての列の変更を追跡するために行全体を保持するか、または主キーとオペレーションのタイプ(挿入、更新、削除)のみを保持することができます。変更されたデータは、SQL ベースの CDC で説明されている SQL ベースのアプローチでキャプチャできます。行全体が格納されている場合にトリガーを使用すると、トランザクションのパフォーマンスに影響し、単一行の DML オペレーションのレイテンシが 2 倍になる可能性があります。主キーのみを格納すると、このオーバーヘッドを削減できますが、SQL ベースの抽出では元のテーブルに対する JOIN オペレーションが必要になり、中間の変更が失われます。
ETL/ELT の移行
Google Cloud で ETL/ELT を処理する方法は多数あります。特定の ETL ワークロード変換に関する技術ガイダンスは、このドキュメントでは扱いません。費用や時間などの制約に応じて、リフト&シフト アプローチを検討するか、またはデータ統合プラットフォームを再設計できます。データ パイプラインを Google Cloud に移行する方法と、その他のさまざまな移行コンセプトの詳細については、データ パイプラインの移行をご覧ください。
リフト&シフト アプローチ
既存のプラットフォームが BigQuery をサポートしており、既存のデータ統合ツールを引き続き使用する場合は、次のようになります。
- ETL/ELT プラットフォームはそのまま維持し、ETL/ELT ジョブで BigQuery を使用して必要なストレージ ステージを変更できます。
- ETL/ELT プラットフォームも Google Cloud に移行する場合は、ツールが Google Cloud でライセンスされているかどうかをベンダーに確認できます。ライセンスされている場合は、Compute Engine にインストールするか、Google Cloud Marketplace を確認できます。
データ統合ソリューション プロバイダの詳細については、BigQuery パートナーをご覧ください。
ETL/ELT プラットフォームの再設計
データ パイプラインを再設計する場合は、Google Cloud サービスの使用を積極的に検討することをおすすめします。
Cloud Data Fusion
Cloud Data Fusion は Google Cloud 上のマネージド CDAP です。ドラッグ&ドロップやパイプライン開発などの作業向けの多数のプラグインを備えたビジュアル インターフェースを提供します。Cloud Data Fusion は、さまざまな種類のソースシステムからデータをキャプチャするために使用でき、バッチ レプリケーション機能とストリーミング レプリケーション機能を備えています。Oracle からのデータをキャプチャするには、Cloud Data Fusion または Oracle のプラグインを使用します。データを BigQuery に読み込み、スキーマの更新を処理するには、BigQuery プラグインを使用します。
ソース プラグインとシンク プラグインのいずれでも出力スキーマは定義されていません。新しい列を複製するには、ソース プラグインで select * from を使用します。
データのクリーニングと準備には、Cloud Data Fusion の Wrangle 機能を使用できます。
Dataflow
Dataflow は、自動スケーリング、バッチデータ処理、ストリーミング データ処理が可能なサーバーレス データ処理プラットフォームです。Dataflow は、データ パイプラインをコーディングし、ストリーミング ワークロードとバッチ ワークロードの両方で同じコードを使用する Python と Java のデベロッパーにとって適しています。Oracle やその他のリレーショナル データベースからデータを抽出し、BigQuery に読み込むには、JDBC to BigQuery テンプレートを使用します。リレーショナル データベースから BigQuery データセットにデータを読み込む例については、Dataflow を使用してリレーショナル データベースから BigQuery に ETL を実行するをご覧ください。
Cloud Composer
Cloud Composer は、Apache Airflow をベースに構築された Google Cloud のフルマネージド ワークフロー オーケストレーション サービスです。これにより、クラウド環境とオンプレミス データセンターにまたがるパイプラインの作成、スケジューリング、モニタリングを行うことができます。Cloud Composer には、ELT の抽出、読み込み、変換などのユースケースと REST API の呼び出しに使用できるマルチクラウド テクノロジーを実行できるオペレーターとコントリビューションが用意されています。
Cloud Composer は、ワークフローのスケジューリングとオーケストレーションに有向非巡回グラフ(DAG)を使用します。Airflow の一般的なコンセプトについては、Airflow Apache のコンセプトをご覧ください。DAG の詳細については、DAG(ワークフロー)の作成をご覧ください。Apache Airflow を使用した ETL ベスト プラクティスのサンプルについては、Airflow を使用した ETL ベスト プラクティスのドキュメント サイトをご覧ください。このサンプルの Hive 演算子を BigQuery 演算子に置き換えることができ、同じコンセプトが適用されます。
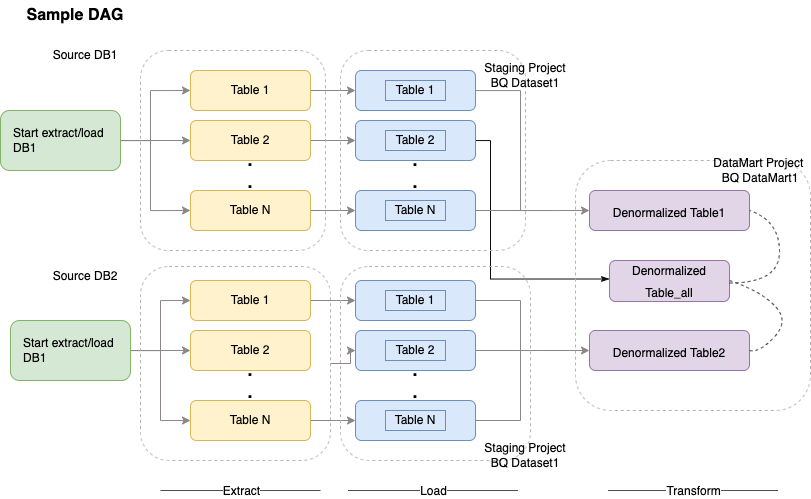
次のサンプルコードは、上の図のサンプル DAG の概要です。
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(2),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 2,
'retry_delay': timedelta(minutes=10),
}
schedule_interval = "00 01 * * *"
dag = DAG('load_db1_db2',catchup=False, default_args=default_args,
schedule_interval=schedule_interval)
tables = {
'DB1_TABLE1': {'database':'DB1', 'table_name':'TABLE1'},
'DB1_TABLE2': {'database':'DB1', 'table_name':'TABLE2'},
'DB1_TABLEN': {'database':'DB1', 'table_name':'TABLEN'},
'DB2_TABLE1': {'database':'DB2', 'table_name':'TABLE1'},
'DB2_TABLE2': {'database':'DB2', 'table_name':'TABLE2'},
'DB2_TABLEN': {'database':'DB2', 'table_name':'TABLEN'},
}
start_db1_daily_incremental_load = DummyOperator(
task_id='start_db1_daily_incremental_load', dag=dag)
start_db2_daily_incremental_load = DummyOperator(
task_id='start_db2_daily_incremental_load', dag=dag)
load_denormalized_table1 = BigQueryOperator(
task_id='load_denormalized_table1',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db1.TABLEN` as tN on t1.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt1', dag=dag)
load_denormalized_table2 = BigQueryOperator(
task_id='load_denormalized_table2',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db2.TABLE2` as t2 on t1.ID = t2.ID
left join `ingest-project.ingest_db2.TABLEN` as tN on t2.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt2', dag=dag)
load_denormalized_table_all = BigQueryOperator(
task_id='load_denormalized_table_all',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),t3.* except (ID)
from `datamart-project.dm1.dt1` as t1
left join `ingest-project.ingest_db1.TABLE2` as t2 on t1.ID = t2.ID
left join `datamart-project.dm1.dt2` as t3 on t2.ID = t3.ID
''', destination_dataset_table='datamart-project.dm1.dt_all', dag=dag)
def start_pipeline(database,table,...):
#start initial or incremental load job here
#you can write your custom operator to integrate ingestion tool
#or you can use operators available in composer instead
for table,table_attr in tables.items():
tbl=table_attr['table_name']
db=table_attr['database'])
load_start = PythonOperator(
task_id='start_load_{db}_{tbl}'.format(tbl=tbl,db=db),
python_callable=start_pipeline,
op_kwargs={'database': db,
'table':tbl},
dag=dag
)
load_monitor = HttpSensor(
task_id='load_monitor_{db}_{tbl}'.format(tbl=tbl,db=db),
http_conn_id='ingestion-tool',
endpoint='restapi-endpoint/',
request_params={},
response_check=lambda response: """{"status":"STOPPED"}""" in
response.text,
poke_interval=1,
dag=dag,
)
load_start.set_downstream(load_monitor)
if table_attr['database']=='db1':
load_start.set_upstream(start_db1_daily_incremental_load)
else:
load_start.set_upstream(start_db2_daily_incremental_load)
if table_attr['database']=='db1':
load_monitor.set_downstream(load_denormalized_table1)
else:
load_monitor.set_downstream(load_denormalized_table2)
load_denormalized_table1.set_downstream(load_denormalized_table_all)
load_denormalized_table2.set_downstream(load_denormalized_table_all)
上記のコードはデモ目的で提供されており、そのまま使用することはできません。
Dataprep by Trifacta
Dataprep は分析、レポート、ML に使用する構造化データと非構造化データを視覚的に探索、クリーニング、準備できるデータサービスです。ソースデータを JSON ファイルまたは CSV ファイルにエクスポートし、Dataprep を使用してデータを変換してから、Dataflow を使用してデータを読み込みます。例については、Oracle data (ETL) to BigQuery using Dataflow and Dataprepをご覧ください。
Dataproc
Dataproc は Google が管理する Hadoop サービスです。Sqoop を使用して、Oracle やその他の多数のリレーショナル データベースから Cloud Storage にデータを Avro ファイルとしてエクスポートできます。その後、bq tool を使用して Avro ファイルを BigQuery に読み込むことができます。CDAP のような ETL ツールを Hadoop にインストールすることは非常に一般的です。これらの ETL ツールは、JDBC を使用してデータを抽出し、Apache Spark または MapReduce を使用してデータの変換を行います。
データ移行のためのパートナー ツール
抽出、変換、読み込み(ETL)の分野には数多くのベンダーが存在します。Informatica、Talend、Matillion、Alooma、Infoworks、Stitch、Fivetran、Striim などの ETL 市場のリーダーは、BigQuery と Oracle の両方と緊密に統合されており、データの抽出、変換、読み込みと、処理ワークフローの管理を支援します。
ETL ツールはかなり以前から存在しています。一部の組織では、信頼できる ETL スクリプトへのこれまでの投資を容易に活用できることがあります。主要なパートナー ソリューションの一部は、BigQuery パートナー ウェブサイトに掲載されています。Google Cloud の組み込みユーティリティではなくパートナー ツールを選択するタイミングは、現在のインフラストラクチャと、IT チームが Java または Python のコードでデータ パイプラインを開発できるかどうかに応じて決まります。
ビジネス インテリジェンス(BI)ツールの移行
BigQuery では、レポートや分析に利用できるビジネス インテリジェント(BI)ソリューションの柔軟なスイートがサポートされています。BI ツールの移行と BigQuery インテグレーションの詳細については、BigQuery 分析の概要をご覧ください。
クエリ(SQL)変換
BigQuery の GoogleSQL は、SQL 2011 標準に準拠し、ネストされたデータと繰り返しデータのクエリをサポートする拡張機能を備えています。最小限の変更で、ANSI 準拠の SQL 関数と演算子をすべて使用できます。Oracle と BigQuery の SQL 構文と関数の詳細な比較については、Oracle から BigQuery への SQL 変換リファレンスをご覧ください。
バッチ SQL 変換を使用して SQL コードを一括で移行することも、インタラクティブ SQL 変換を使用してアドホック クエリを変換することもできます。
Oracle オプションの移行
このセクションでは、Oracle Data Mining、R、Spatial and Graph の各機能を使用するアプリケーションの変換に関するアーキテクチャの推奨事項とリファレンスについて説明します。
Oracle Advanced Analytics オプション
Oracle は、データ マイニング、基本的な機械学習(ML)アルゴリズム、R の使用のための Advanced Analytics オプションを提供しています。Advanced Analytics オプションを使用するにはライセンスが必要です。Google の AI/ML プロダクトの包括的なリストから、開発から大規模な本番環境まで、ニーズに応じてプロダクトを選択できます。
Oracle R Enterprise
Oracle R Enterprise(ORE)は Oracle Advanced Analytics オプションのコンポーネントであり、オープンソースの R 統計プログラミング言語を Oracle Database と統合します。標準の ORE デプロイでは、R が Oracle サーバーにインストールされます。
非常に大規模なデータやウェアハウジング アプローチの場合は、R を BigQuery と統合することをおすすめします。オープンソースの bigrquery R ライブラリを使用して、R を BigQuery と統合できます。
Google は RStudio と提携して、この分野の最先端ツールをユーザーに提供しています。RStudio を使用すると、TensorFlow で BigQuery 適合モデルのテラバイト単位のデータにアクセスし、AI Platform を使用して ML モデルを大規模に実行できます。Google Cloud では、Compute Engine に大規模に R をインストールできます。
Oracle Data Mining
Oracle Data Mining(ODM)は Oracle Advanced Analytics オプションのコンポーネントです。ODM によりデベロッパーは Oracle で Oracle PL/SQL Developer を使用して ML モデルを構築できます。
BigQuery ML では、デベロッパーは線形回帰、バイナリ ロジスティック回帰、多クラス ロジスティック回帰、K 平均法クラスタリング、TensorFlow モデルのインポートなど、さまざまなタイプのモデルを実行できます。詳細については、BigQuery ML の概要をご覧ください。
ODM ジョブを変換するときにコードの書き換えが必要になる場合があります。BigQuery ML、AI API(Speech-to-Text、Text-to-Speech、Dialogflow、Cloud Translation、Cloud Natural Language API、Cloud Vision、Timeseries Insights API など)、Vertex AIなど、包括的な Google AI プロダクト サービスから選択できます。
Vertex AI Workbench をデータ サイエンティストの開発環境として使用し、Vertex AI Training を使用してトレーニングとスコア付けのワークロードを実行できます。
Spatial and Graph オプション
Oracle は、ジオメトリとグラフのクエリに使用できる Spatial and Graph オプションを提供しています。このオプションにはライセンスが必要です。BigQuery のジオメトリ関数は、追加の費用やライセンスなしで使用できます。また他のグラフ データベースも Google Cloud で使用できます。
Spatial
BigQuery には地理空間分析の関数とデータ型があります。詳細については、地理空間分析データの操作をご覧ください。Oracle Spatial のデータ型と関数は、BigQuery 標準 SQL の地理関数に変換できます。地理関数によって BigQuery の標準料金に追加費用がかかることはありません。
Graph
JanusGraph は、Bigtable をストレージ バックエンドとして使用できるオープンソースのグラフ データベース ソリューションです。詳細については、Bigtable を使用して GKE で JanusGraph を実行するをご覧ください。
Neo4j は、Google Kubernetes Engine(GKE)で動作する Google Cloud サービスとして提供されるもう 1 つのグラフ データベース ソリューションです。
Oracle Application Express
Oracle Application Express(APEX)アプリケーションは Oracle に固有であり、書き換えが必要です。レポート作成とデータの可視化機能は、Looker Studioや BI エンジンを使用して開発できます。行の作成や編集などのアプリケーション レベルの機能は、AppSheet で Cloud SQL を使用してコーディングなしで開発できます。
次のステップ
- 全体的なパフォーマンスの最適化と費用削減に向けてワークロードを最適化する方法を確認する。
- BigQuery でストレージを最適化する方法を確認する。
- BigQuery の更新内容については、リリースノートをご覧ください。
- Oracle SQL 変換ガイドを参照する。