データセットの作成
このドキュメントでは、BigQuery でデータセットを作成する方法について説明します。
次の方法でデータセットを作成できます。
- Google Cloud コンソールを使用する。
- SQL クエリを使用する。
- bq コマンドライン ツールの
bq mkコマンドを使用する。 datasets.insertAPI メソッドを呼び出す。- クライアント ライブラリを使用する。
- 既存のデータセットをコピーする。
データセットをコピーする手順(リージョン間でのコピーを含む)については、データセットのコピーをご覧ください。
一般公開データセット内のテーブルをクエリする方法については、Google Cloud コンソールを使用して一般公開データセットに対してクエリを実行するをご覧ください。
データセットの制限事項
BigQuery データセットには次の制限があります。
- データセットのロケーションは、作成時にのみ設定できます。データセットの作成後はそのロケーションを変更できません。
1 つのクエリで参照されるすべてのテーブルは、同じロケーションにあるデータセット内に保存されている必要があります。
テーブルをコピーする場合、コピー元とコピー先のテーブルが同じロケーションに存在する必要があります。
データセット名は各プロジェクトで一意である必要があります。
始める前に
このドキュメントの各タスクを実行するために必要な権限をユーザーに与える Identity and Access Management(IAM)のロールを付与します。
必要な権限
データセットを作成するには、bigquery.datasets.create IAM 権限が必要です。
次の IAM 事前定義ロールには、データセットの作成に必要な権限が含まれています。
roles/bigquery.dataEditorroles/bigquery.dataOwnerroles/bigquery.userroles/bigquery.admin
BigQuery での IAM のロールの詳細については、事前定義ロールと権限をご覧ください。
データセットに名前を付ける
BigQuery でデータセットを作成するとき、データセット名はプロジェクトごとに一意である必要があります。データセット名には次のものを含めることができます。
- 1,024 文字まで。
- 文字(大文字または小文字)、数字、アンダースコア。
データセット名では、デフォルトで大文字と小文字が区別されます。mydataset と MyDataset は、いずれかで大文字と小文字の区別が無効になっていない限り、同じプロジェクトで共存できます。
データセット名にはスペースや特殊文字(-、&、@、% など)を含めることはできません。
非表示のデータセット
非表示のデータセットは、名前がアンダースコアで始まるデータセットです。非表示のデータセット内のテーブルとビューは、他のデータセットと同じ方法でクエリできます。非表示のデータセットには以下の制限があります。
- Google Cloud コンソールの [エクスプローラ] パネルには表示されない。
INFORMATION_SCHEMAビューには表示されない。- リンクされたデータセットでは使用できない。
- Data Catalog には表示されない。
データセットの作成
データセットを作成するには:
コンソール
Google Cloud コンソールで [BigQuery] ページを開きます。
[エクスプローラ] パネルで、データセットを作成するプロジェクトを選択します。
アクション オプションを開いて、[データセットを作成] をクリックします。
[データセットを作成] ページで次の操作を行います。
- [データセット ID] に、データセットの一意の名前を入力します。
[ロケーション タイプ] で、データセットの地理的なロケーションを選択します。データセットの作成後はロケーションを変更できません。
省略可: このデータセットのテーブルに有効期限を設定するには、[テーブルの有効期限を有効にする] を選択してから、[デフォルトのテーブル最長存続期間] を日数で指定します。
省略可: 顧客管理の暗号鍵(CMEK)を使用する場合は、[詳細オプション] を開いて [顧客管理の暗号鍵(CMEK)] を選択します。
省略可: 大文字と小文字を区別しないテーブル名を使用する場合は、[詳細オプション] を開いて [大文字と小文字を区別しないテーブル名を有効にする] を選択します。
省略可: デフォルトの照合順序を使用する場合は、[詳細オプション] を開いて [デフォルトの照合を有効にする] を選択し、使用するデフォルトの照合を選択します。
省略可: デフォルトの丸めモードを使用する場合は、[詳細オプション] を開いて [デフォルトの丸めモード] を選択します。
省略可: 物理ストレージの課金モデルを有効にする場合は、[詳細オプション] を開いて [物理ストレージの課金モデルを有効にする] を選択します。
データセットの課金モデルを変更した場合は、変更が反映されるまでに 24 時間を要します。
データセットのストレージ課金モデルを変更した後、再度ストレージ課金モデルを変更するには、14 日間お待ちいただく必要があります。
省略可: データセットのタイムトラベル期間を設定する場合は、[詳細オプション] を開いて使用するタイムトラベル期間を選択します。
[データセットを作成] をクリックします。
SQL
CREATE SCHEMA ステートメントを使用します。
デフォルト プロジェクト以外のプロジェクト内にデータセットを作成するには、PROJECT_ID.DATASET_ID の形式でそのプロジェクト ID をデータセット ID に追加します。
Google Cloud コンソールで [BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
CREATE SCHEMA PROJECT_ID.DATASET_ID OPTIONS ( default_kms_key_name = 'KMS_KEY_NAME', default_partition_expiration_days = PARTITION_EXPIRATION, default_table_expiration_days = TABLE_EXPIRATION, description = 'DESCRIPTION', labels = [('LABEL_1','VALUE_1'),('LABEL_2','VALUE_2')], location = 'LOCATION', max_time_travel_hours = HOURS, storage_billing_model = BILLING_MODEL);次のように置き換えます。
PROJECT_ID: プロジェクト IDDATASET_ID: 作成するデータセットの IDKMS_KEY_NAME: 作成時に別の鍵が指定されていない限り、このデータセットで新しく作成されたテーブルの保護に使用されるデフォルトの Cloud Key Management Service 鍵の名前です。このパラメータが設定されたデータセットには、Google 暗号化テーブルを作成できません。PARTITION_EXPIRATION: 新しく作成されるパーティション分割テーブルのパーティションのデフォルトの存続期間(日数)です。デフォルトのパーティション有効期限には最小値はありません。パーティションの日付にこの整数値を足した値が有効期限になります。データセット内のパーティション分割テーブルに作成されたパーティションは、パーティションの日付からPARTITION_EXPIRATION日後に削除されます。パーティション分割テーブルの作成時または更新時にtime_partitioning_expirationフラグを指定した場合、データセット レベルのデフォルトのパーティション有効期限よりもテーブルレベルのパーティション有効期限が優先されます。TABLE_EXPIRATION: 新しく作成されるテーブルのデフォルトの存続期間(日数)。最小値は 0.042 日(1 時間)です。現在時刻にこの整数値を足した値が有効期限になります。データセット内に作成されたテーブルは、作成時点からTABLE_EXPIRATION日後に削除されます。この値は、テーブルの作成時にテーブルの有効期限を設定しなかった場合に適用されます。DESCRIPTION: データセットの説明LABEL_1:VALUE_1: このデータセットの最初のラベルとして設定する Key-Value ペアLABEL_2:VALUE_2: 2 番目のラベルとして設定する Key-Value ペアLOCATION: データセットのロケーション。データセットの作成後はロケーションを変更できません。HOURS: 新しいデータセットのタイムトラベル期間の長さ(時間)。HOURS値は、24 の倍数(48、72、96、120、144、168)であり、48(2 日)~168(7 日)の範囲にする必要があります。このオプションを指定しない場合のデフォルトは 168 時間です。BILLING_MODEL: データセットのストレージ課金モデルを設定します。ストレージ料金の計算時に物理バイトを使用する場合はBILLING_MODEL値をPHYSICALに設定し、論理バイトを使用する場合はLOGICALに設定します。デフォルトはLOGICALです。データセットの課金モデルを変更した場合は、変更が反映されるまでに 24 時間を要します。
データセットのストレージ課金モデルを変更した後、再度ストレージ課金モデルを変更するには、14 日間お待ちいただく必要があります。
[実行] をクリックします。
クエリの実行方法については、インタラクティブ クエリを実行するをご覧ください。
bq
新しいデータセットを作成するには、--location フラグを指定した bq mk コマンドを使用します。
デフォルト プロジェクト以外のプロジェクト内にデータセットを作成するには、PROJECT_ID:DATASET_ID の形式でそのプロジェクト ID をデータセット名に追加します。
bq --location=LOCATION mk \
--dataset \
--default_kms_key=KMS_KEY_NAME \
--default_partition_expiration=PARTITION_EXPIRATION \
--default_table_expiration=TABLE_EXPIRATION \
--description="DESCRIPTION" \
--label=LABEL_1:VALUE_1 \
--label=LABEL_2:VALUE_2 \
--max_time_travel_hours=HOURS \
--storage_billing_model=BILLING_MODEL \
PROJECT_ID:DATASET_ID
次のように置き換えます。
LOCATION: データセットのロケーション。データセットの作成後はロケーションを変更できません。ロケーションのデフォルト値は、.bigqueryrcファイルを使用して設定できます。KMS_KEY_NAME: 作成時に別の鍵が指定されていない限り、このデータセットで新しく作成されたテーブルの保護に使用されるデフォルトの Cloud Key Management Service 鍵の名前です。このパラメータが設定されたデータセットには、Google で暗号化されたテーブルを作成できません。PARTITION_EXPIRATION: 新しく作成されるパーティション分割テーブルのパーティションのデフォルトの存続時間(秒)。デフォルトのパーティション有効期限には最小値はありません。パーティションの日付にこの整数値を足した値が有効期限になります。データセット内のパーティション分割テーブルに作成されたパーティションは、パーティションの日付からPARTITION_EXPIRATION秒後に削除されます。パーティション分割テーブルの作成時または更新時に--time_partitioning_expirationフラグを指定した場合、データセット レベルのデフォルトのパーティション有効期限よりもテーブルレベルのパーティション有効期限が優先されます。TABLE_EXPIRATION: 新しく作成されるテーブルのデフォルトの存続期間(秒)。最小値は 3,600 秒(1 時間)です。現在時刻にこの整数値を足した値が有効期限になります。データセット内に作成されたテーブルは、作成時点からTABLE_EXPIRATION秒後に削除されます。この値が適用されるのは、テーブルの作成時にテーブルの有効期限を設定しなかった場合です。DESCRIPTION: データセットの説明LABEL_1:VALUE_1: このデータセットに最初のラベルとして設定する Key-Value ペアです。LABEL_2:VALUE_2は、2 番目のラベルとして設定する Key-Value ペアです。HOURS: 新しいデータセットのタイムトラベル期間の長さ(時間)。HOURS値は、24 の倍数(48、72、96、120、144、168)であり、48(2 日)~168(7 日)の範囲にする必要があります。このオプションを指定しない場合のデフォルトは 168 時間です。BILLING_MODEL: データセットのストレージ課金モデルを設定します。ストレージの変更の計算時に物理バイトを使用する場合はBILLING_MODEL値をPHYSICALに設定し、論理バイトを使用する場合はLOGICALに設定します。デフォルトはLOGICALです。データセットの課金モデルを変更した場合は、変更が反映されるまでに 24 時間を要します。
データセットのストレージ課金モデルを変更した後、再度ストレージ課金モデルを変更するには、14 日間お待ちいただく必要があります。
PROJECT_ID: プロジェクト ID。DATASET_IDは、作成するデータセットの ID です。
たとえば、次のコマンドを実行すると mydataset という名前のデータセットが作成され、データのロケーションは US、デフォルトのテーブル存続期間は 3,600 秒(1 時間)、説明は This is my dataset に設定されます。このコマンドでは、--dataset フラグの代わりに -d ショートカットを使用しています。-d と --dataset を省略した場合、このコマンドはデフォルトでデータセットを作成します。
bq --location=US mk -d \
--default_table_expiration 3600 \
--description "This is my dataset." \
mydataset
データセットが作成されたことを確認するには、bq ls コマンドを入力します。また、新しいデータセットを作成するときに、bq mk -t dataset.table の形式を使用してテーブルを作成することもできます。テーブルの作成方法については、テーブルの作成をご覧ください。
Terraform
google_bigquery_dataset リソースを使用します。
データセットを作成する
次の例では、mydataset という名前のデータセットを作成します。
google_bigquery_dataset リソースを使用してデータセットを作成すると、プロジェクト レベルの基本ロールのメンバーであるすべてのアカウントに、データセットへのアクセス権が自動的に付与されます。データセットの作成後に terraform show コマンドを実行すると、データセットの access ブロックは次のようになります。
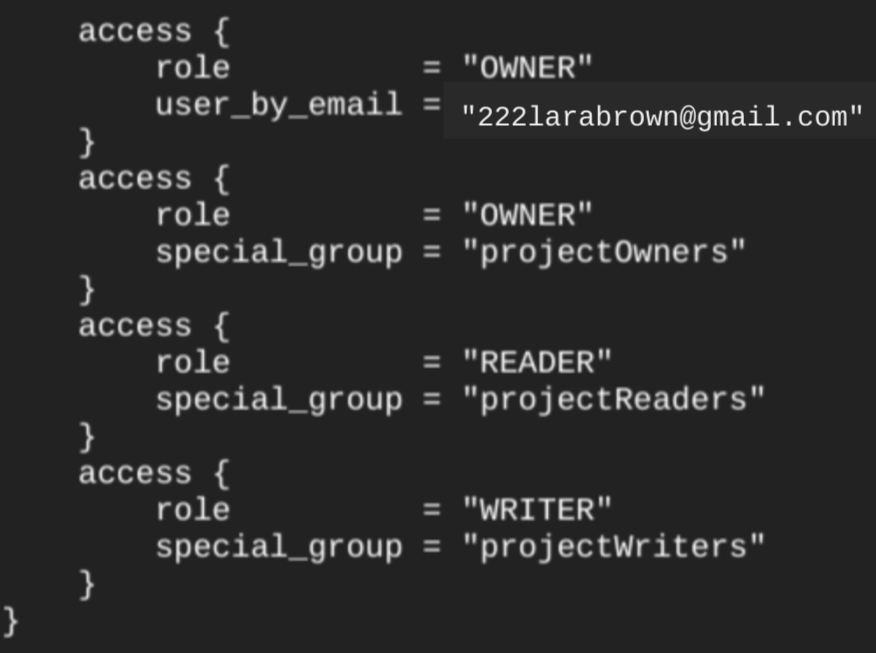
データセット内に承認済みビューなどの承認済みオブジェクトを作成する予定がない場合、データセットへのアクセス権を付与するには、次の例に示すように、google_bigquery_iam リソースのうちのひとつを使うことをおすすめします。その場合は、google_bigquery_dataset_access リソースを使用します。例については、該当するドキュメントをご覧ください。
データセットを作成してアクセス権を付与する
次の例では、mydataset という名前のデータセットを作成し、google_bigquery_dataset_iam_policy リソースを使用してそのデータセットへのアクセス権を付与します。
顧客管理の暗号鍵でデータセットを作成する
次の例では、mydataset という名前のデータセットを作成します。また、google_kms_crypto_key と google_kms_key_ring リソースを使用し、データセットに Cloud Key Management Service の鍵を指定します。この例を実行する前に、Cloud Key Management Service API を有効にする必要があります。
Google Cloud プロジェクトで Terraform 構成を適用するには、次のセクションの手順を完了します。
Cloud Shell を準備する
- Cloud Shell を起動します。
-
Terraform 構成を適用するデフォルトの Google Cloud プロジェクトを設定します。
このコマンドは、プロジェクトごとに 1 回だけ実行する必要があります。これは任意のディレクトリで実行できます。
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Terraform 構成ファイルに明示的な値を設定すると、環境変数がオーバーライドされます。
ディレクトリを準備する
Terraform 構成ファイルには独自のディレクトリ(ルート モジュールとも呼ばれます)が必要です。
-
Cloud Shell で、ディレクトリを作成し、そのディレクトリ内に新しいファイルを作成します。ファイルの拡張子は
.tfにする必要があります(例:main.tf)。このチュートリアルでは、このファイルをmain.tfとします。mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
チュートリアルを使用している場合は、各セクションまたはステップのサンプルコードをコピーできます。
新しく作成した
main.tfにサンプルコードをコピーします。必要に応じて、GitHub からコードをコピーします。Terraform スニペットがエンドツーエンドのソリューションの一部である場合は、この方法をおすすめします。
- 環境に適用するサンプル パラメータを確認し、変更します。
- 変更を保存します。
-
Terraform を初期化します。これは、ディレクトリごとに 1 回だけ行います。
terraform init
最新バージョンの Google プロバイダを使用する場合は、
-upgradeオプションを使用します。terraform init -upgrade
変更を適用する
-
構成を確認して、Terraform が作成または更新するリソースが想定どおりであることを確認します。
terraform plan
必要に応じて構成を修正します。
-
次のコマンドを実行します。プロンプトで「
yes」と入力して、Terraform 構成を適用します。terraform apply
Terraform に「Apply complete!」というメッセージが表示されるまで待ちます。
- Google Cloud プロジェクトを開いて結果を表示します。Google Cloud コンソールの UI でリソースに移動して、Terraform によって作成または更新されたことを確認します。
API
定義済みのデータセット リソースを使用して datasets.insert メソッドを呼び出します。
C#
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートの C# の手順に沿って設定を行ってください。詳細については、BigQuery C# API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Go
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートの Go の手順に沿って設定を行ってください。詳細については、BigQuery Go API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートの Java の手順に沿って設定を行ってください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Node.js
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートの Node.js の手順に沿って設定を行ってください。詳細については、BigQuery Node.js API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
PHP
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートの PHP の手順に沿って設定を行ってください。詳細については、BigQuery PHP API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートの Python の手順に沿って設定を行ってください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Ruby
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートの Ruby の手順に沿って設定を行ってください。詳細については、BigQuery Ruby API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
データセットのセキュリティ
BigQuery でデータセットへのアクセスを制御するには、データセットへのアクセスの制御をご覧ください。データ暗号化の詳細については、保存データの暗号化をご覧ください。
次のステップ
- プロジェクト内のデータセットを一覧表示する方法については、データセットの一覧表示をご覧ください。
- データセット メタデータの詳細については、データセットに関する情報の取得をご覧ください。
- データセット プロパティの変更方法については、データセットの更新をご覧ください。
- ラベルの作成と管理の詳細は、ラベルの作成と管理をご覧ください。
使ってみる
Google Cloud を初めて使用される方は、アカウントを作成して、実際のシナリオでの BigQuery のパフォーマンスを評価してください。新規のお客様には、ワークロードの実行、テスト、デプロイができる無料クレジット $300 分を差し上げます。
BigQuery の無料トライアル