Migrar o esquema e os dados do Teradata
A combinação do serviço de transferência de dados do BigQuery com um agente de migração especial permite que você copie seus dados de uma instância de armazenamento de dados local do Teradata para o BigQuery. Este documento descreve o processo passo a passo de migração de dados do Teradata usando o serviço de transferência de dados do BigQuery.
Antes de começar
- Faça login na sua conta do Google Cloud. Se você começou a usar o Google Cloud agora, crie uma conta para avaliar o desempenho de nossos produtos em situações reais. Clientes novos também recebem US$ 300 em créditos para executar, testar e implantar cargas de trabalho.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
-
Ative as APIs BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub.
-
Crie uma conta de serviço:
-
No Console do Google Cloud, acesse a página Criar conta de serviço.
Acesse "Criar conta de serviço" - Selecione o projeto.
-
No campo Nome da conta de serviço, insira um nome. O Console do Google Cloud preenche o campo ID da conta de serviço com base nesse nome.
No campo Descrição da conta de serviço, insira uma descrição. Por exemplo,
Service account for quickstart. - Clique em Criar e continuar.
-
Conceda os papéis a seguir à conta de serviço: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator
Para conceder um papel, encontre a lista Selecionar um papel e escolha uma opção.
Para conceder outros papéis, clique em Adicionar outro papel e adicione cada papel adicional.
- Clique em Continuar.
-
Clique em Concluído para terminar a criação da conta de serviço.
Não feche a janela do navegador. Você vai usá-la na próxima etapa.
-
-
Crie uma chave de conta de serviço:
- No console do Google Cloud, clique no endereço de e-mail da conta de serviço que você criou.
- Clique em Chaves.
- Clique em Adicionar chave e em Criar nova chave.
- Clique em Criar. O download de um arquivo de chave JSON é feito no seu computador.
- Clique em Fechar.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
-
Ative as APIs BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub.
-
Crie uma conta de serviço:
-
No Console do Google Cloud, acesse a página Criar conta de serviço.
Acesse "Criar conta de serviço" - Selecione o projeto.
-
No campo Nome da conta de serviço, insira um nome. O Console do Google Cloud preenche o campo ID da conta de serviço com base nesse nome.
No campo Descrição da conta de serviço, insira uma descrição. Por exemplo,
Service account for quickstart. - Clique em Criar e continuar.
-
Conceda os papéis a seguir à conta de serviço: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator
Para conceder um papel, encontre a lista Selecionar um papel e escolha uma opção.
Para conceder outros papéis, clique em Adicionar outro papel e adicione cada papel adicional.
- Clique em Continuar.
-
Clique em Concluído para terminar a criação da conta de serviço.
Não feche a janela do navegador. Você vai usá-la na próxima etapa.
-
-
Crie uma chave de conta de serviço:
- No console do Google Cloud, clique no endereço de e-mail da conta de serviço que você criou.
- Clique em Chaves.
- Clique em Adicionar chave e em Criar nova chave.
- Clique em Criar. O download de um arquivo de chave JSON é feito no seu computador.
- Clique em Fechar.
A chave salva tem o seguinte formato:
{
"type": "service_account",
"project_id": "PROJECT_ID",
"private_key_id": "KEY_ID",
"private_key": "-----BEGIN PRIVATE KEY-----\nPRIVATE_KEY\n-----END PRIVATE KEY-----\n",
"client_email": "SERVICE_ACCOUNT_EMAIL",
"client_id": "CLIENT_ID",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/SERVICE_ACCOUNT_EMAIL"
}
Armazene a chave com segurança, porque ela pode ser usada para autenticar como sua conta de serviço. Se precisar, é possível mover e renomear esse arquivo.
Definir as permissões necessárias
Verifique se o principal que cria a transferência tem os papéis a seguir no projeto que contém o job de transferência:
- Visualizador de registros (
roles/logging.viewer) - Administrador de armazenamento (
roles/storage.admin) ou um papel personalizado que concede as seguintes permissões:storage.objects.createstorage.objects.getstorage.objects.list
- Administrador do BigQuery (
roles/bigquery.admin) ou um papel personalizado que concede as seguintes permissões:bigquery.datasets.createbigquery.jobs.createbigquery.jobs.getbigquery.jobs.listAllbigquery.transfers.getbigquery.transfers.update
Criar um conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar os dados. Não é necessário criar tabelas.
Criar um bucket do Cloud Storage
Crie um bucket do Cloud Storage para preparar os dados durante o job de transferência.
Preparar o ambiente local
Conclua as tarefas nesta seção para preparar seu ambiente local para o job de transferência.
Requisitos de máquina local
- O agente de migração usa uma conexão JDBC com a instância do Teradata e as APIs do Google Cloud. Verifique se o acesso à rede não está bloqueado por um firewall.
- Certifique-se de que o Java Runtime Environment 8 ou posterior esteja instalado.
- Verifique se você tem espaço de armazenamento suficiente para o método de extração escolhido, conforme descrito em Método de extração.
- Se você decidiu usar a extração do Parallel Transporter (TPT) do Teradata,
verifique se o
utilitário
tbuildestá instalado. Para mais informações sobre como escolher um método de extração, consulte Método de extração.
Detalhes da conexão do Teradata
Verifique se você tem o nome de usuário e a senha de um usuário do Teradata com acesso de leitura às tabelas do sistema e às tabelas que estão sendo migradas.
Confira o nome do host e o número da porta para se conectar à instância do Teradata.
Fazer o download do driver JDBC
Faça o download do arquivo de driver JDBC terajdbc4.jar do Teradata
para uma máquina que pode se conectar ao armazenamento de dados.
Defina a variável GOOGLE_APPLICATION_CREDENTIALS
Defina a variável de ambiente GOOGLE_APPLICATION_CREDENTIALS
para a chave da conta de serviço que você fez o download na seção Antes de começar.
Atualizar a regra de saída do VPC Service Controls
Adicione um projeto do Google Cloud gerenciado ao serviço de transferência de dados do BigQuery (número do projeto: 990232121269) à regra de saída no perímetro do VPC Service Controls.
O canal de comunicação entre o agente em execução no local e o serviço de transferência de dados do BigQuery é publicando mensagens do Pub/Sub em um tópico por transferência. O serviço de transferência de dados do BigQuery precisa enviar comandos ao agente para extrair dados, e o agente precisa publicar mensagens no serviço de transferência de dados do BigQuery para atualizar o status e retornar respostas de extração de dados.
Criar um arquivo de esquema personalizado
Para usar um arquivo de esquema personalizado em vez de detecção automática de esquema, crie um manualmente ou faça com que o agente de migração crie um quando você inicializar o agente.
Se você criar um arquivo de esquema manualmente e pretende usar o console do Google Cloud para criar uma transferência, faça upload do arquivo de esquema para um bucket do Cloud Storage no mesmo projeto que você planeja usar para a transferência.
Faça o download do agente de migração
Faça o download do agente de migração em uma máquina que possa se conectar ao armazenamento em data warehouse. Mova o arquivo JAR do agente de migração para o mesmo diretório que o arquivo JAR do driver JDBC do Teradata.
Configurar uma transferência
Crie uma transferência com o serviço de transferência de dados do BigQuery.
Se você quiser que um arquivo de esquema personalizado seja criado automaticamente, use o agente de migração para configurar a transferência.
Não é possível criar uma transferência sob demanda usando a ferramenta de linha de comando bq. Em vez disso, use o console do Google Cloud ou a API de serviço de transferência de dados do BigQuery.
Se você estiver criando uma transferência recorrente, recomendamos especificar um arquivo de esquema para que os dados das transferências subsequentes sejam particionados corretamente quando forem carregados no BigQuery. Sem um arquivo de esquema, o serviço de transferência de dados do BigQuery infere o esquema da tabela a partir dos dados de origem que estão sendo transferidos. Todas as informações sobre particionamento, clustering, chaves primárias e rastreamento de alterações são perdidas. Além disso, as transferências subsequentes pulam as tabelas migradas anteriormente após a transferência inicial. Para mais informações sobre como criar um arquivo de esquema, consulte Arquivo de esquema personalizado.
Console
No console do Google Cloud, acesse a página do BigQuery.
Clique em Transferências de dados.
Clique em Criar transferência.
Na seção Tipo de origem, faça o seguinte:
- Escolha Migração: Teradata.
- Em Nome da configuração de transferência, digite um nome de exibição para a transferência, como
My Migration. Ele pode ter qualquer valor facilmente identificável, caso precise modificar a transferência no futuro. - Opcional: em Opções de programação, deixe o valor padrão Diária (com base no horário de criação) ou escolha outro horário se quiser uma transferência recorrente, incremental. Caso contrário, escolha Sob demanda para uma transferência única.
Para Configurações de destino, escolha o conjunto de dados apropriado.
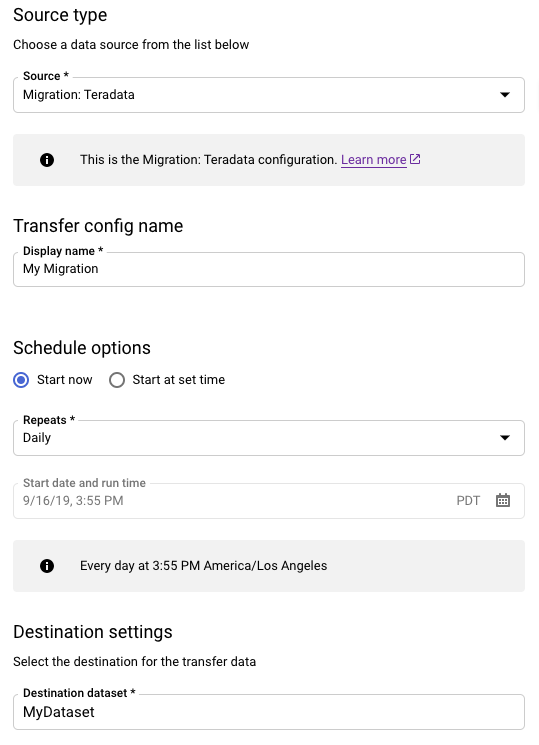
Na seção Detalhes da fonte de dados, continue inserindo detalhes específicos da transferência do Teradata.
- Em Tipo de banco de dados, escolha Teradata.
- Em bucket do Cloud Storage, procure o nome do bucket do Cloud Storage para preparar os dados de migração. Não digite o prefixo
gs://: insira apenas o nome do bucket. - Em Nome do banco de dados, digite o nome do banco de dados de origem no Teradata.
Em Padrões de nome da tabela, insira um padrão para corresponder aos nomes das tabelas no banco de dados de origem. Você pode usar expressões regulares para especificar o padrão. Exemplo:
sales|expensescorresponde às tabelas chamadassaleseexpenses..*corresponde a todas as tabelas.
Em E-mail da conta de serviço, insira o endereço de e-mail associado às credenciais da conta de serviço usadas por um agente de migração.
Opcional: se você estiver usando um arquivo de esquema personalizado, insira o caminho e o nome do arquivo no campo Caminho do arquivo de esquema. Se você não fornecer um arquivo de esquema personalizado, o BigQuery detectará automaticamente o esquema da tabela usando os dados de origem que estão sendo transferidos. Você pode criar seu próprio arquivo de esquema, conforme mostrado na imagem a seguir, ou usar o agente de migração para criar um arquivo de esquema. Para informações sobre como criar um arquivo de esquema, consulte Como inicializar o agente de migração.
No menu Conta de serviço, selecione uma conta de serviço nas contas de serviço associadas ao seu projeto do Google Cloud. É possível associar uma conta de serviço à transferência em vez de usar suas credenciais de usuário. Para mais informações sobre o uso de contas de serviço com transferências de dados, consulte Usar contas de serviço.
- Se você fez login com uma identidade federada, é necessário uma conta de serviço para criar uma transferência. Se você fez login com uma Conta do Google, uma conta de serviço para a transferência é opcional.
- A conta de serviço precisa ter as permissões necessárias.
Opcional: na seção Opções de notificação, faça o seguinte:
- Clique no botão Notificações por e-mail se quiser que o administrador de transferência receba uma notificação por e-mail quando uma execução de transferência falhar.
- Clique no botão de Notificações do Pub/Sub para configurar as notificações de execução do Pub/Sub para sua transferência. Em Selecionar um tópico do Pub/Sub, escolha o nome do tópico ou clique em Criar um tópico.
Clique em Save.
Na página Detalhes da transferência, clique na guia Configuração.
Anote o nome do recurso dessa transferência porque você precisa dela para executar o agente de migração.
bq
Ao criar uma transferência do Cloud Storage usando a ferramenta bq, a configuração de transferência é definida como recorrente a cada 24 horas. Para transferências sob demanda, use o console do Google Cloud ou a API BigQuery Data Transfer Service.
Não é possível configurar notificações usando a ferramenta bq.
Digite o comando
bq mk
e forneça a sinalização de criação da transferência
--transfer_config. As sinalizações abaixo também são obrigatórias:
--data_source--display_name--target_dataset--params
bq mk \ --transfer_config \ --project_id=project ID \ --target_dataset=dataset \ --display_name=name \ --service_account_name=service_account \ --params='parameters' \ --data_source=data source
Em que:
- project ID é o ID do projeto. Se
--project_idnão for fornecido para especificar um projeto específico, o projeto padrão será usado. - dataset é o conjunto de dados que você quer segmentar (
--target_dataset) para a configuração de transferência. - name é o nome de exibição (
--display_name) da configuração de transferência. O nome de exibição pode ser qualquer valor que permita identificar a transferência, caso seja necessário modificá-la mais tarde. - service_account é o nome da conta de serviço usado para autenticar a transferência. A conta de serviço precisa pertencer ao mesmo
project_idusado para criar a transferência e ter todas as permissões necessárias listadas. - parameters contém os parâmetros (
--params) da configuração da transferência criada no formato JSON. Por exemplo:--params='{"param":"param_value"}'.- Para migrações do Teradata, use os seguintes parâmetros:
bucketé o bucket do Cloud Storage que atuará como uma área de preparo durante a migração;database_typeé o Teradata;agent_service_accounté o endereço de e-mail associado à conta de serviço que você criou;database_nameé o nome do banco de dados de origem no Teradata;table_name_patternsé um padrão para correspondência dos nomes das tabelas no banco de dados de origem. Você pode usar expressões regulares para especificar o padrão. Esse padrão precisa seguir a sintaxe da expressão regular do Java. Por exemplo:sales|expensescorresponde às tabelas chamadassaleseexpenses..*corresponde a todas as tabelas.
- Para migrações do Teradata, use os seguintes parâmetros:
- data_source é a fonte de dados (
--data_source):on_premises.
Por exemplo, o comando a seguir cria uma transferência do Teradata chamada My Transfer usando o bucket mybucket do Cloud Storage e o conjunto de dados de destino mydataset. A transferência migrará todas as tabelas do armazenamento de dados do Teradata mydatabase, e o arquivo de esquema opcional será myschemafile.json.
bq mk \
--transfer_config \
--project_id=123456789876 \
--target_dataset=MyDataset \
--display_name='My Migration' \
--params='{"bucket": "mybucket", "database_type": "Teradata",
"database_name":"mydatabase", "table_name_patterns": ".*",
"agent_service_account":"myemail@mydomain.com", "schema_file_path":
"gs://mybucket/myschemafile.json"}' \
--data_source=on_premises
Após executar o comando, você recebe uma mensagem semelhante a esta:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Siga as instruções e cole o código de autenticação na linha de comando.
API
Use o método projects.locations.transferConfigs.create
e forneça uma instância do recurso
TransferConfig.
Java
Antes de testar esta amostra, siga as instruções de configuração do Java no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Java.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Agente de migração
Também é possível configurar a transferência diretamente do agente de migração. Para mais informações, consulte Inicializar o agente de migração.
Inicializar o agente de migração
É necessário inicializar o agente de migração para uma nova transferência. A inicialização é necessária apenas uma vez para uma transferência, independentemente de ser recorrente. A inicialização apenas configura o agente de migração. Ela não inicia a transferência.
Se você for usar o agente de migração para criar um arquivo de esquema personalizado,
verifique se tem um diretório gravável no
diretório de trabalho com o mesmo nome do projeto que você quer usar para a
transferência. É aqui que o agente de migração cria o arquivo de esquema.
Por exemplo, se você estiver trabalhando em /home e estiver configurando
a transferência no projeto myProject, crie o diretório /home/myProject
e verifique se ele pode ser gravado pelos usuários.
Abra uma nova sessão. Na linha de comando, emita o comando de inicialização, que segue este formulário:
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --initialize
O exemplo a seguir mostra o comando de inicialização quando os arquivos JAR do driver JDBC e do agente de migração estão em um diretório
migrationlocal:Unix, Linux, Mac OS
java -cp \ /usr/local/migration/terajdbc4.jar:/usr/local/migration/mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --initialize
Windows
Copie todos os arquivos para a pasta
C:\migration(ou ajuste os caminhos no comando) e execute:java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --initialize
Quando solicitado, configure as seguintes opções:
- Escolha se quer salvar o modelo do Teradata Parallel Transporter (TPT) no disco. Se você planeja usar o método de extração de TPT, é possível modificar o modelo salvo com parâmetros adequados à sua instância do Teradata.
- Digite o caminho para um diretório local que o job de transferência possa usar para extração de arquivos. Verifique se você tem o espaço de armazenamento mínimo recomendado, conforme descrito em Método de extração.
- Digite o nome do host do banco de dados.
- Digite a porta do banco de dados.
- Escolha se quer usar o Teradata Parallel Transporter (TPT) como o método de extração.
- Opcional: digite o caminho de um arquivo de credenciais do banco de dados.
Escolha se quer especificar um nome de configuração do serviço de transferência de dados do BigQuery.
Se você estiver inicializando o agente de migração de uma transferência que já configurou, faça o seguinte:
- Digite o nome de recurso da transferência. Isso pode ser encontrado na guia Configuração da página Detalhes da transferência.
- Quando solicitado, digite um caminho e o nome do arquivo do arquivo de configuração do agente de migração que será criado. Consulte esse arquivo ao executar o agente de migração para iniciar a transferência.
- Ignore as demais etapas.
Se você estiver usando o agente de migração para configurar uma transferência, pressione Enter para pular para a próxima solicitação.
Digite o ID do projeto do Google Cloud.
Digite o nome do banco de dados de origem no Teradata.
Insira um padrão para corresponder os nomes das tabelas no banco de dados de origem. Você pode usar expressões regulares para especificar o padrão. Exemplo:
sales|expensescorresponde às tabelas chamadassaleseexpenses..*corresponde a todas as tabelas.
Opcional: digite o caminho de um arquivo de esquema JSON local. Isso é altamente recomendado para transferências recorrentes.
Se você não estiver usando um arquivo de esquema ou quiser que o agente de migração crie um para você, pressione Enter para pular para a próxima solicitação.
Escolha se você quer criar um novo arquivo de esquema.
Se você quiser criar um arquivo de esquema, faça o seguinte:
- Digite
yes. - Digite o nome de usuário de um usuário do Teradata que tem acesso de leitura às tabelas do sistema e das tabelas que você quer migrar.
Digite a senha do usuário.
O agente de migração cria o arquivo de esquema e gera o local dele.
Modifique o arquivo de esquema para marcar o particionamento, o clustering, as chaves primárias e as colunas de controle de alterações e verifique se você quer usar esse esquema para a configuração de transferência. Consulte Arquivo de esquema personalizado para ver dicas.
Pressione
Enterpara pular para a próxima solicitação.
Se você não quiser criar um arquivo de esquema, digite
no.- Digite
Digite o nome do bucket de destino do Cloud Storage para preparar os dados de migração antes de carregar no BigQuery. Se você tiver feito o agente de migração criar um arquivo de esquema personalizado, ele também será enviado para esse bucket.
Digite o nome do conjunto de dados de destino no BigQuery.
Digite um nome de exibição para a configuração de transferência.
Digite um caminho e o nome do arquivo do arquivo de configuração do agente de migração que será criado.
Depois que todos os parâmetros solicitados são inseridos, o agente de migração cria um arquivo de configuração e o envia para o caminho local especificado. Consulte a próxima seção para ver mais detalhes sobre o arquivo de configuração.
Arquivo de configuração do agente de migração
O arquivo de configuração criado na etapa de inicialização é semelhante a este exemplo:
{
"agent-id": "81f452cd-c931-426c-a0de-c62f726f6a6f",
"transfer-configuration": {
"project-id": "123456789876",
"location": "us",
"id": "61d7ab69-0000-2f6c-9b6c-14c14ef21038"
},
"source-type": "teradata",
"console-log": false,
"silent": false,
"teradata-config": {
"connection": {
"host": "localhost"
},
"local-processing-space": "extracted",
"database-credentials-file-path": "",
"max-local-storage": "50GB",
"gcs-upload-chunk-size": "32MB",
"use-tpt": true,
"transfer-views": false,
"max-sessions": 0,
"spool-mode": "NoSpool",
"max-parallel-upload": 4,
"max-parallel-extract-threads": 1,
"session-charset": "UTF8",
"max-unload-file-size": "2GB"
}
}
Opções do job de transferência no arquivo de configuração do agente de migração
transfer-configuration: informações sobre essa configuração de transferência no BigQuery.teradata-config: informações específicas para esta extração do Teradata:connection: informações sobre o nome do host e a portalocal-processing-space: a pasta de extração em que o agente extrairá os dados da tabela antes de fazer upload para o Cloud Storage.database-credentials-file-path: (Opcional) O caminho para um arquivo que contém credenciais para se conectar ao banco de dados Teradata automaticamente. O arquivo precisa conter duas linhas para as credenciais. É possível usar um nome de usuário/senha, conforme mostrado no exemplo a seguir:username=abc password=123
Também é possível usar um secret do SecretManager ao invés:username=abc secret_resource_id=projects/my-project/secrets/my-secret-name/versions/1
Ao usar um arquivo de credenciais, tome cuidado para controlar o acesso à pasta onde você o armazena no sistema de arquivos local, pois ele não será criptografado. Se nenhum caminho for fornecido, você será solicitado a fornecer um nome de usuário e uma senha quando iniciar um agente.max-local-storage: a quantidade máxima de armazenamento local a ser usada para a extração no diretório de preparo especificado. O valor padrão é50GB. O formato compatível é:numberKB|MB|GB|TB.Em todos os modos de extração, os arquivos serão excluídos do diretório de preparo local após serem enviados para o Cloud Storage.
use-tpt: orienta o agente de migração a usar o Teradata Parallel Transporter (TPT) como um método de extração.Para cada tabela, o agente de migração gera um script TPT, inicia um processo
tbuilde aguarda a conclusão. Depois que o processotbuildfor concluído, o agente listará e fará upload dos arquivos extraídos para o Cloud Storage e, em seguida, excluirá o script TPT. Para mais informações, consulte Método de extração.transfer-views: direciona o agente de migração para também transferir dados de visualizações. Use essa opção apenas se você precisar personalizar os dados durante a migração. Em outros casos, migre visualizações para Visualizações do BigQuery. Essa opção tem os seguintes pré-requisitos:- Essa opção só pode ser usada nas versões 16.10 e mais recentes do Teradata.
- Uma visualização precisa ter uma coluna de números inteiros "partition" definida, apontando para um ID de partição para a linha especificada na tabela subjacente.
max-sessions: especifica o número máximo de sessões usadas pelo job de exportação (FastExport ou TPT). Se definido como 0, o banco de dados do Teradata determinará o número máximo de sessões para cada job de exportação.gcs-upload-chunk-size: um arquivo grande é enviado em blocos para o Cloud Storage. Esse parâmetro emax-parallel-uploadsão usados para controlar quantos dados são enviados ao Cloud Storage ao mesmo tempo. Por exemplo, segcs-upload-chunk-sizefor 64 MB emax-parallel-uploadfor 10 MB, teoricamente, um agente de migração poderá fazer upload de 640 MB (64 MB * 10) de dados ao mesmo tempo. Se o upload do bloco falhar, ele precisará fazer novas tentativas. O tamanho da parte precisa ser pequeno.max-parallel-upload: esse valor determina o número máximo de linhas de execução usadas pelo agente de migração para fazer upload de arquivos no Cloud Storage. Caso não seja especificado, o padrão será o número de processadores disponíveis para a máquina virtual Java. A regra geral é escolher o valor com base no número de núcleos que você tem na máquina que executa o agente. Portanto, se você tiver núcleosn, o número ideal de linhas de execução precisará sern. Se os núcleos forem hyperthread, o número ideal será(2 * n). Há também outras configurações como a largura de banda da rede que você precisa considerar ao ajustarmax-parallel-upload. Ajustar esse parâmetro pode melhorar o desempenho do upload para o Cloud Storage.spool-mode: na maioria dos casos, o modo NoSpool é a melhor opção.NoSpoolé o valor padrão na configuração do agente. É possível alterar esse parâmetro se uma das desvantagens do NoSpool se aplicarem ao seu caso.max-unload-file-size: determina o tamanho máximo do arquivo extraído. Esse parâmetro não é aplicado a extrações TPT.max-parallel-extract-threads: essa configuração é usada apenas no modo FastConnect. Ele determina o número de linhas de execução paralelas usadas para extrair os dados do Teradata. Ajustar esse parâmetro pode melhorar o desempenho da extração.tpt-template-path: use essa configuração para fornecer um script de extração de TPT personalizado como entrada. Use esse parâmetro para aplicar transformações aos dados de migração.schema-mapping-rule-path: (opcional) o caminho para um arquivo de configuração que contém um mapeamento de esquema para substituir as regras de mapeamento padrão. Alguns tipos de mapeamento funcionam apenas com o modo Teradata Parallel Transporter (TPT).Exemplo: mapeamento do tipo
TIMESTAMPdo Teradata para o tipoDATETIMEdo BigQuery:{ "rules": [ { "database": { "name": "database.*", "tables": [ { "name": "table.*" } ] }, "match": { "type": "COLUMN_TYPE", "value": "TIMESTAMP" }, "action": { "type": "MAPPING", "value": "DATETIME" } } ] }Atributos:
database: (opcional)nameé uma expressão regular para bancos de dados a serem incluídos. Todos os bancos de dados são incluídos por padrão.tables: (opcional) contém uma matriz de tabelas.nameé uma expressão regular para tabelas a serem incluídas. Todas as tabelas estão incluídas por padrão.match: (Obrigatório)- Valores aceitos
type:COLUMN_TYPE. - Valores aceitos:
value:TIMESTAMP,DATETIME.
- Valores aceitos
action: (Obrigatório)- Valores aceitos
type:MAPPING. - Valores aceitos:
value:TIMESTAMP,DATETIME.
- Valores aceitos
compress-output: (opcional) determina se os dados precisam ser compactados antes de armazenar no Cloud Storage. Isso é aplicado apenas em tpt-mode. Por padrão, esse valor éfalse.
Execute o agente de migração
Depois de inicializar o agente de migração e criar o arquivo de configuração, use as seguintes etapas para executar o agente e iniciar a migração:
Execute o agente especificando os caminhos para o driver JDBC, o agente de migração e o arquivo de configuração criado na etapa de inicialização anterior.
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=path to configuration file
Unix, Linux, Mac OS
java -cp \ /usr/local/migration/Teradata/JDBC/terajdbc4.jar:mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=config.json
Windows
Copie todos os arquivos para a pasta
C:\migration(ou ajuste os caminhos no comando) e execute:java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --configuration-file=config.json
Se você estiver pronto para continuar a migração, pressione
Enter, e o agente prosseguirá se o caminho de classe fornecido durante a inicialização for válido.Quando solicitado, digite o nome de usuário e a senha da conexão do banco de dados. Se o nome de usuário e a senha forem válidos, a migração de dados será iniciada.
Opcional No comando para iniciar a migração, você também pode usar uma sinalização que transmita um arquivo de credenciais para o agente, em vez de digitar toda vez o nome de usuário e a senha. Consulte o parâmetro opcional
database-credentials-file-pathno arquivo de configuração do agente para obter mais informações. Ao usar um arquivo de credenciais, siga as etapas apropriadas para controlar o acesso à pasta onde você o armazena no sistema de arquivos local, porque ele não será criptografado.Deixe esta sessão aberta até que a migração seja concluída. Se você tiver criado uma transferência de migração recorrente, mantenha esta sessão aberta indefinidamente. Se esta sessão for interrompida, as execuções de transferência atuais e futuras falham.
Monitore periodicamente se o agente está em execução. Se uma execução de transferência estiver em andamento e nenhum agente responder em 24 horas, a execução da transferência falhará.
Se o agente de migração parar de funcionar enquanto a transferência estiver em andamento ou programada, o console do Google Cloud mostrará o status do erro e solicitará que você reinicie o agente. Para iniciar o agente de migração novamente, retome a partir do início desta seção, executando o agente de migração, com o comando para executar o agente de migração. Não é necessário repetir o comando de inicialização. A transferência é retomada do ponto em que as tabelas não foram concluídas.
Acompanhar o progresso da migração
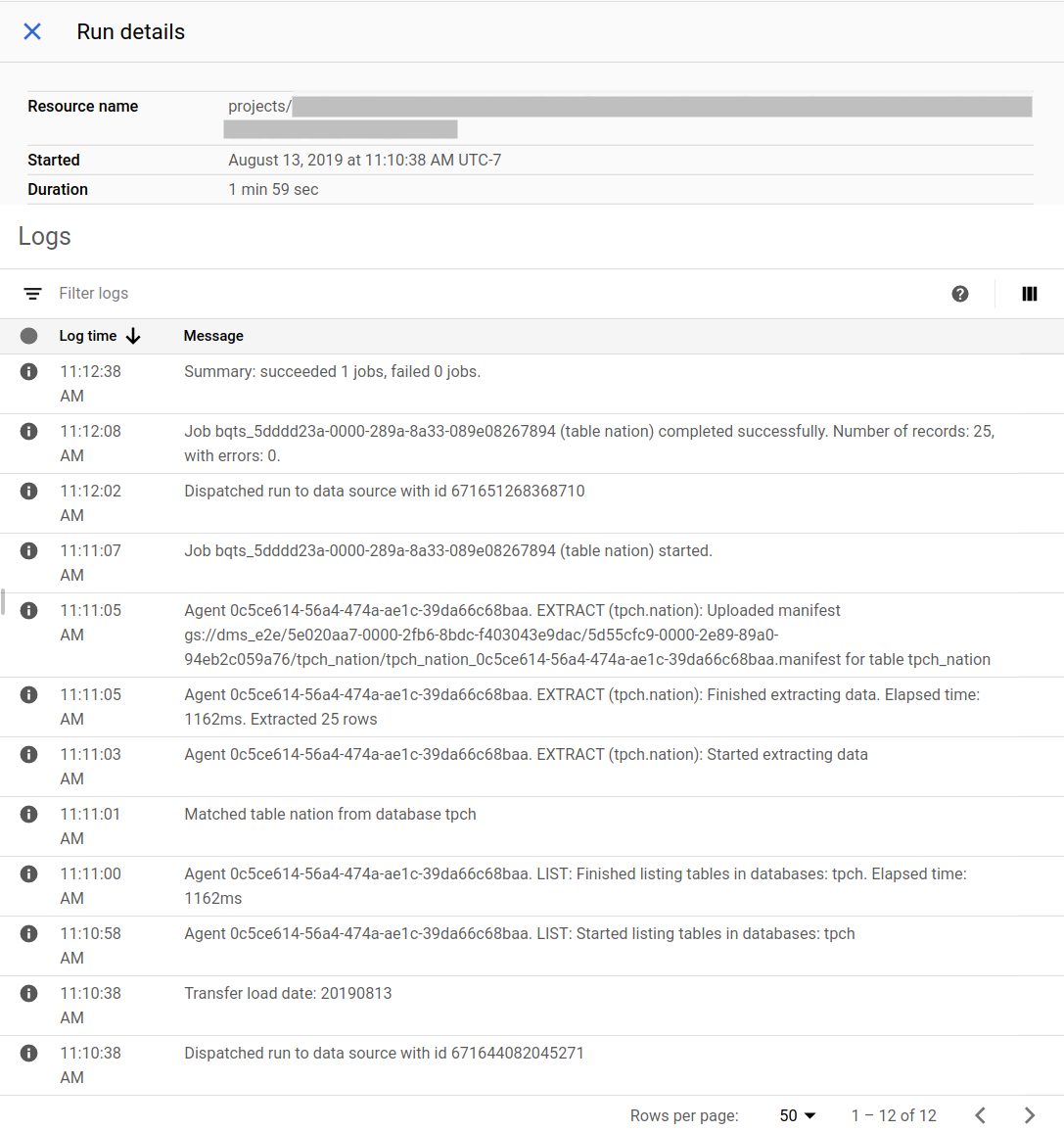
Veja o status da migração no console do Google Cloud. Também é possível configurar as notificações do Pub/Sub ou por e-mail. Consulte Notificações do serviço de transferência de dados do BigQuery.
O serviço de transferência de dados do BigQuery programa e inicia uma execução de transferência conforme uma programação especificada na criação da configuração de transferência. É importante que o agente de migração esteja em execução quando uma execução de transferência estiver ativa. Se não houver atualizações do agente em 24 horas, uma execução de transferência falha.
Exemplo de status da migração no console do Google Cloud:
Fazer upgrade do agente de migração
Se uma nova versão do agente de migração estiver disponível, você precisará atualizá-lo manualmente. Para receber avisos sobre o serviço de transferência de dados do BigQuery, inscreva-se nas Notas de lançamento.
A seguir
- Faça uma migração de teste do Teradata para o BigQuery.
- Saiba mais sobre o serviço de transferência de dados do BigQuery.
- Migrar o código SQL com a translação de SQL em lote.