Introduzione a BigQuery Omni
Con BigQuery Omni puoi eseguire analisi di BigQuery sui dati archiviati in Amazon Simple Storage Service (Amazon S3) o Archiviazione BLOB di Azure utilizzando le tabelle BigLake.
Molte organizzazioni archiviano i dati in più cloud pubblici. Spesso questi dati finiscono per essere isolati in silos, in quanto è difficile ottenere insight trasversali su tutti i dati. Vuoi poter analizzare i dati con uno strumento multi-cloud che sia economico, veloce e che non crei un overhead aggiuntivo dovuto alla governance dei dati decentralizzata. Grazie a BigQuery Omni, riduciamo questi attriti con un'interfaccia unificata.
Per eseguire l'analisi BigQuery sui tuoi dati esterni, devi prima connetterti ad Amazon S3 o Archiviazione BLOB. Se vuoi eseguire query su dati esterni, devi creare una tabella BigLake che fa riferimento a dati di Amazon S3 o di archiviazione BLOB.
Puoi anche spostare i dati tra cloud per combinarli tra loro utilizzando il trasferimento cross-cloud o eseguire query sui dati tra cloud utilizzando i join cross-cloud. BigQuery Omni offre una soluzione di analisi cross-cloud con la possibilità di analizzare i dati ovunque si trovino e la flessibilità di replicarli quando necessario. Per maggiori informazioni, consulta Caricare dati con trasferimento tra cloud e join tra cloud.
Architettura
L'architettura di BigQuery separa il computing dall'archiviazione, consentendo a BigQuery di fare lo scale out in base alle esigenze per gestire carichi di lavoro di grandi dimensioni. BigQuery Omni estende questa architettura eseguendo il motore di query BigQuery su altri cloud. Di conseguenza, non devi spostare fisicamente i dati nello spazio di archiviazione di BigQuery. L'elaborazione avviene dove si trovano già i dati.
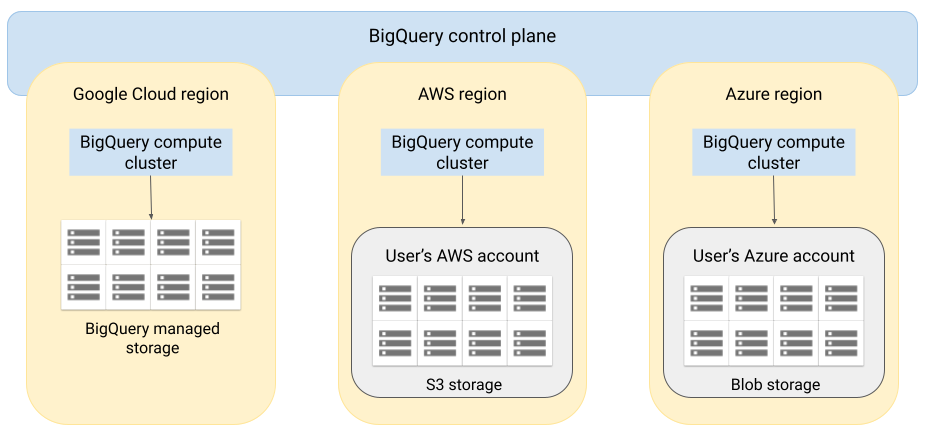
I risultati delle query possono essere restituiti a Google Cloud tramite una connessione sicura, ad esempio per essere visualizzati nella console Google Cloud. In alternativa, puoi scrivere i risultati direttamente nei bucket Amazon S3 o nell'archiviazione BLOB. In questo caso, non si verifica alcun movimento tra cloud dei risultati della query.
BigQuery Omni utilizza ruoli AWS IAM standard o entità Azure Active Directory per accedere ai dati nel tuo abbonamento. Puoi delegare l'accesso in lettura o scrittura a BigQuery Omni e puoi revocarlo in qualsiasi momento.
Flusso di dati durante l'esecuzione di query sui dati
L'immagine seguente descrive come vengono spostati i dati tra Google Cloud e AWS o Azure per le seguenti query:
- Istruzione
SELECT - Istruzione
CREATE EXTERNAL TABLE

- Il piano di controllo BigQuery riceve job di query tramite la console Google Cloud, lo strumento a riga di comando bq, un metodo API o una libreria client.
- Il piano di controllo BigQuery invia job di query per l'elaborazione al piano dati di BigQuery su AWS o Azure.
- Il piano dati BigQuery riceve la query dal piano di controllo tramite una connessione VPN.
- Il piano dati BigQuery legge i dati della tabella dal bucket Amazon S3 o dall'archiviazione BLOB.
- Il piano dati BigQuery esegue il job di query sui dati della tabella. L'elaborazione dei dati della tabella avviene nella regione AWS o Azure specificata.
- Il risultato della query viene trasmesso dal piano dati al piano di controllo tramite la connessione VPN.
- Il piano di controllo BigQuery riceve i risultati del job di query per visualizzarli in risposta al job della query. Questi dati vengono archiviati per un massimo di 24 ore.
- Il risultato della query ti viene restituito.
Per ulteriori informazioni, vedi Eseguire query sui dati di Amazon S3 e Dati di archiviazione BLOB.
Flusso di dati durante l'esportazione dei dati
L'immagine seguente descrive come i dati si spostano tra Google Cloud e AWS o Azure durante un'istruzione EXPORT DATA.

- Il piano di controllo BigQuery riceve i job di query di esportazione da te tramite la console Google Cloud, lo strumento a riga di comando bq, un metodo API o una libreria client. La query contiene il percorso di destinazione del risultato della query nel bucket Amazon S3 o nell'archiviazione BLOB.
- Il piano di controllo BigQuery invia i job di query di esportazione per l'elaborazione al piano dati BigQuery (su AWS o Azure).
- Il piano dati BigQuery riceve la query di esportazione dal piano di controllo tramite la connessione VPN.
- Il piano dati BigQuery legge i dati della tabella dal bucket Amazon S3 o dall'archiviazione BLOB.
- Il piano dati BigQuery esegue il job di query sui dati della tabella. L'elaborazione dei dati della tabella avviene nella regione AWS o Azure specificata.
- BigQuery scrive il risultato della query nel percorso di destinazione specificato nel bucket Amazon S3 o nell'archiviazione BLOB.
Per ulteriori informazioni, consulta Esportazione dei risultati delle query in Amazon S3 e Archiviazione BLOB.
Vantaggi
Rendimento. Puoi ottenere insight più rapidamente poiché i dati non vengono copiati tra i cloud e le query vengono eseguite nella stessa regione in cui si trovano i dati.
Costo. Poiché i dati non vengono spostati, risparmi sui costi di trasferimento dei dati in uscita. Al tuo account AWS o Azure non sono previsti addebiti aggiuntivi relativi all'analisi di BigQuery Omni, poiché le query vengono eseguite su cluster gestiti da Google. Ti vengono addebitati solo i costi per l'esecuzione delle query, utilizzando il modello di prezzi di BigQuery.
Sicurezza e governance dei dati. Puoi gestire i dati nel tuo abbonamento AWS o Azure. Non devi spostare o copiare i dati non elaborati fuori dal cloud pubblico. Tutte le operazioni di calcolo vengono eseguite nel servizio multi-tenant di BigQuery che viene eseguito all'interno della stessa regione dei dati.
Architettura serverless. Come del resto di BigQuery, BigQuery Omni è un'offerta serverless. Google esegue il deployment e gestisce i cluster che eseguono BigQuery Omni. Non è necessario eseguire il provisioning di risorse o gestire i cluster.
Facilità di gestione. BigQuery Omni offre un'interfaccia di gestione unificata tramite Google Cloud. BigQuery Omni può utilizzare il tuo account Google Cloud e i progetti BigQuery esistenti. Puoi scrivere una query GoogleSQL nella console Google Cloud per eseguire query sui dati in AWS o Azure e visualizzare i risultati nella console Google Cloud.
Trasferimento tra cloud. Puoi caricare i dati in tabelle BigQuery standard dai bucket S3 e dall'archiviazione BLOB. Per maggiori informazioni, vedi Trasferimento dei dati di Amazon S3 e Dati di Archiviazione BLOB in BigQuery.
Memorizzazione nella cache dei metadati per migliorare le prestazioni
Puoi utilizzare i metadati memorizzati nella cache per migliorare le prestazioni delle query sulle tabelle BigLake che fanno riferimento a dati Amazon S3. È particolarmente utile nei casi in cui si lavora con un numero elevato di file o se i dati sono partizionati ad hive.
I metadati includono nomi dei file, informazioni sul partizionamento e metadati fisici dei file, come il numero di righe. Puoi scegliere se attivare o meno la memorizzazione nella cache dei metadati su una tabella. Le query con un numero elevato di file e con filtri di partizione Hive traggono maggiore vantaggio dalla memorizzazione nella cache dei metadati.
Se non abiliti la memorizzazione nella cache dei metadati, le query nella tabella devono leggere l'origine dati esterna per ottenere i metadati degli oggetti che aumentano la latenza delle query. La creazione di elenchi di milioni di file dall'origine dati esterna può richiedere diversi minuti. Se attivi la memorizzazione nella cache dei metadati, le query possono evitare di elencare i file dell'origine dati esterna e ottenere un'eliminazione più rapida delle partizioni e dei file.
Esistono due proprietà che controllano questa funzionalità:
- Inattività massima, che controlla quando le query utilizzano i metadati memorizzati nella cache.
- Modalità cache dei metadati, che controlla il modo in cui i metadati vengono raccolti.
Se la memorizzazione nella cache dei metadati è abilitata, devi specificare l'intervallo massimo di inattività dei metadati accettabile per le operazioni sulla tabella. Ad esempio, se specifichi un intervallo di 1 ora, le operazioni sulla tabella utilizzano i metadati memorizzati nella cache se sono stati aggiornati nell'ultima ora. Se i metadati memorizzati nella cache sono precedenti, l'operazione esegue invece il recupero dei metadati da Cloud Storage. Puoi specificare un intervallo di inattività compreso tra 30 minuti e 7 giorni.
Puoi scegliere di aggiornare la cache automaticamente o manualmente:
- Per gli aggiornamenti automatici, la cache viene aggiornata a un intervallo definito dal sistema, di solito tra 30 e 60 minuti. L'aggiornamento automatico della cache è un buon approccio se i file in Cloud Storage vengono aggiunti, eliminati o modificati a intervalli casuali. Se hai bisogno di controllare la tempistica dell'aggiornamento, ad esempio per attivare l'aggiornamento al termine di un job di estrazione, trasformazione e caricamento, utilizza l'aggiornamento manuale.
Per gli aggiornamenti manuali, esegui la procedura di sistema
BQ.REFRESH_EXTERNAL_METADATA_CACHEper aggiornare la cache dei metadati in base a una pianificazione che soddisfi i tuoi requisiti. L'aggiornamento manuale della cache è un buon approccio se i file in Cloud Storage vengono aggiunti, eliminati o modificati a intervalli noti, ad esempio come output di una pipeline.Se emetti più aggiornamenti manuali contemporanei, solo uno avrà esito positivo.
Se non viene aggiornata, la cache dei metadati scade dopo sette giorni.
Prima di impostarli, devi considerare come interagiranno i valori dell'intervallo di inattività e della modalità di memorizzazione nella cache dei metadati. Considera i seguenti esempi:
- Se aggiorni manualmente la cache dei metadati di una tabella e imposti l'intervallo di inattività su due giorni, devi eseguire la procedura di sistema
BQ.REFRESH_EXTERNAL_METADATA_CACHEogni due giorni o meno se vuoi che le operazioni sulla tabella utilizzino i metadati memorizzati nella cache. - Se aggiorni automaticamente la cache dei metadati per una tabella e imposti l'intervallo di inattività su 30 minuti, è possibile che alcune operazioni sulla tabella vengano lette da Cloud Storage se l'aggiornamento della cache dei metadati richiede il lato più lungo della solita finestra di 30-60 minuti.
Per trovare informazioni sui job di aggiornamento dei metadati, esegui una query sulla vista INFORMATION_SCHEMA.JOBS, come mostrato nell'esempio seguente:
SELECT * FROM `region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT` WHERE job_id LIKE '%metadata_cache_refresh%' AND creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 6 HOUR) ORDER BY start_time DESC LIMIT 10;
Per ulteriori informazioni, consulta la sezione Memorizzazione nella cache dei metadati.
Tabelle abilitate per la cache con viste materializzate
Puoi utilizzare le viste materializzate sulle tabelle di metadati Amazon Simple Storage Service (Amazon S3) abilitate per la cache per migliorare le prestazioni e l'efficienza durante l'esecuzione di query sui dati strutturati archiviati in Amazon S3. Queste viste materializzate funzionano come le viste materializzate sulle tabelle di archiviazione gestite da BigQuery, inclusi i vantaggi dell' aggiornamento automatico e dell'ottimizzazione intelligente.
Per rendere disponibili i dati di Amazon S3 in una vista materializzata in una regione BigQuery supportata per i join, crea una replica della vista materializzata. Puoi creare repliche con vista materializzata solo su viste materiali autorizzate.
Limitazioni
Oltre alle limitazioni per le tabelle BigLake, si applicano le seguenti limitazioni a BigQuery Omni, che include le tabelle BigLake basate su dati di Amazon S3 e Archiviazione BLOB:
- L'utilizzo dei dati in una qualsiasi delle aree geografiche di BigQuery Omni non è supportato dalle versioni Standard ed Enterprise Plus. Per ulteriori informazioni sulle versioni, consulta la presentazione delle versioni di BigQuery.
- Le viste
OBJECT_PRIVILEGES,STREAMING_TIMELINE_BY_*,TABLE_SNAPSHOTS,TABLE_STORAGE,TABLE_CONSTRAINTS,KEY_COLUMN_USAGE,CONSTRAINT_COLUMN_USAGEePARTITIONSINFORMATION_SCHEMAnon sono disponibili per le tabelle BigLake basate sui dati di Amazon S3 e Blob Storage. - Le viste materializzate non sono supportate per l'archiviazione BLOB.
- Le funzioni JavaScript definite dall'utente non sono supportate.
Le seguenti istruzioni SQL non sono supportate:
- Istruzioni BigQuery ML.
- Istruzioni DDL (Data Definition Language) che richiedono la gestione di dati in BigQuery. Ad esempio, sono supportati i criteri
CREATE EXTERNAL TABLE,CREATE SCHEMAoCREATE RESERVATION, al contrario diCREATE MATERIALIZED VIEW. - Istruzioni DML (Data Manipulation Language).
Le seguenti limitazioni si applicano all'esecuzione di query e alla lettura delle tabelle temporanee di destinazione (anteprima):
- L'esecuzione di query sulle tabelle temporanee di destinazione con l'istruzione
SELECTnon è supportata. - L'utilizzo dell'API BigQuery Storage Read per leggere i dati dalle tabelle temporanee di destinazione non è supportato.
- Quando utilizzi il driver ODBC, le letture ad alta velocità effettiva (opzione
EnableHTAPI) non sono supportate.
- L'esecuzione di query sulle tabelle temporanee di destinazione con l'istruzione
Le query pianificate sono supportate solo tramite il metodo API o interfaccia a riga di comando. L'opzione della tabella di destinazione è disabilitata per le query. Sono consentite solo query
EXPORT DATA.L'API BigQuery Storage non è disponibile nelle regioni BigQuery Omni.
Se la query utilizza la clausola
ORDER BYe ha una dimensione dei risultati superiore a 256 MB, la query non va a buon fine. Per risolvere il problema, riduci la dimensione dei risultati o rimuovi la clausolaORDER BYdalla query. Per saperne di più sulle quote di BigQuery Omni, consulta Quote e limiti.L'utilizzo di chiavi di crittografia gestite dal cliente (CMEK) con set di dati e tabelle esterne non è supportato.
Prezzi
Per informazioni sui prezzi e sulle offerte a tempo limitato in BigQuery Omni, consulta Prezzi di BigQuery Omni.
Quote e limiti
Per informazioni sulle quote di BigQuery Omni, consulta Quote e limiti.
Se il risultato della query supera i 20 GiB, valuta la possibilità di esportarlo in Amazon S3 o Archiviazione BLOB. Per saperne di più sulle quote per l'API BigQuery Connection, vedi API BigQuery Connection.
Località
BigQuery Omni elabora le query nella stessa posizione del set di dati che contiene le tabelle su cui esegui le query. Una volta creato il set di dati, la località non può essere modificata. I dati si trovano all'interno del tuo account AWS o Azure. Le regioni BigQuery Omni supportano le prenotazioni della versione Enterprise e i prezzi di computing (analisi) on demand. Per ulteriori informazioni sulle versioni, consulta Introduzione alle versioni di BigQuery.| Descrizione regione | Nome regione | Regione BigQuery condivisa | |
|---|---|---|---|
| AWS | |||
| AWS - Stati Uniti, costa orientale (Virginia del Nord) | aws-us-east-1 |
us-east4 |
|
| AWS - Stati Uniti occidentali (Oregon) | aws-us-west-2 |
us-west1 |
|
| AWS - Asia Pacifico (Seul) | aws-ap-northeast-2 |
asia-northeast3 |
|
| AWS - Asia Pacifico (Sydney) | aws-ap-southeast-2 |
australia-southeast1 |
|
| AWS - Europa (Irlanda) | aws-eu-west-1 |
europe-west1 |
|
| AWS - Europa (Francoforte) | aws-eu-central-1 |
europe-west3 |
|
| Azure | |||
| Azure - Stati Uniti orientali 2 | azure-eastus2 |
us-east4 |
|
Passaggi successivi
- Scopri come connetterti ad Amazon S3 e Archiviazione BLOB.
- Scopri come creare tabelle BigLake Amazon S3 e Archiviazione BLOB.
- Scopri come eseguire query sulle tabelle BigLake di Amazon S3 e Archiviazione BLOB.
- Scopri come unire le tabelle BigLake di Amazon S3 e Blob Storage con le tabelle Google Cloud utilizzando i join cross-cloud.
- Scopri come esportare i risultati delle query in Amazon S3 e nell'archiviazione BLOB.
- Scopri come trasferire dati da Amazon S3 e archiviazione BLOB a BigQuery.
- Scopri di più sulla configurazione del perimetro dei Controlli di servizio VPC.
- Scopri come specificare la tua posizione