Introducción a BigQuery Omni
Con BigQuery Omni, puedes ejecutar análisis de BigQuery sobre datos almacenados en Amazon Simple Storage Service (Amazon S3) o Azure Blob Storage mediante tablas de BigLake.
Muchas organizaciones almacenan datos en múltiples nubes públicas. A menudo, estos datos permanecen aislados, ya que es difícil obtener estadísticas de todos los datos. Es recomendable que puedas analizar los datos con una herramienta de datos de múltiples nubes que sea económica, rápida y no cree una sobrecarga adicional de la administración de datos descentralizada. Mediante el uso de BigQuery Omni, redujimos estas complicaciones con una interfaz unificada.
Para ejecutar estadísticas de BigQuery en tus datos externos, primero debes conectarte a Amazon S3 o Blob Storage. Si quieres consultar datos externos, debes crear una tabla de BigLake que haga referencia a los datos de Amazon S3 o Blob Storage.
También puedes mover datos entre nubes para combinar datos entre nubes a través de la transferencia entre nubes o consultar los datos entre nubes con uniones entre nubes. BigQuery Omni ofrece una solución de estadísticas entre nubes con la capacidad de analizar datos en cualquier lugar y la flexibilidad de replicar los datos cuando sea necesario. Para obtener más información, consulta Carga datos con la transferencia entre nubes y Uniones entre nubes.
Arquitectura
La arquitectura de BigQuery separa el procesamiento del almacenamiento, lo que permite que BigQuery escale horizontalmente según sea necesario para controlar cargas de trabajo muy grandes. BigQuery Omni extiende esta arquitectura mediante la ejecución del motor de consultas de BigQuery en otras nubes. Como resultado, no es necesario mover los datos físicamente al almacenamiento de BigQuery. El procesamiento ocurre donde ya se encuentran esos datos.
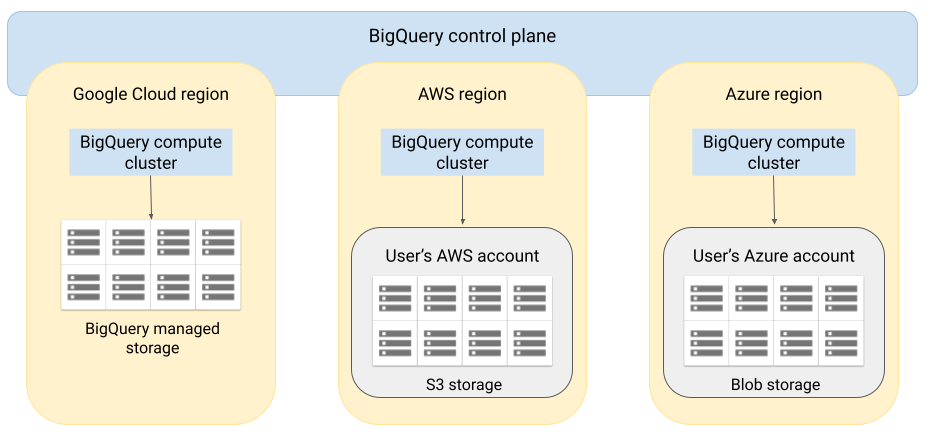
Los resultados de las consultas se pueden mostrar en Google Cloud a través de una conexión segura, por ejemplo, para mostrarlos en la consola de Google Cloud. Como alternativa, puedes escribir los resultados directamente en el almacenamiento de Amazon S3 o en Blob Storage. En ese caso, no habrá un movimiento entre nubes de los resultados de las consultas.
BigQuery Omni usa los roles estándar de IAM de AWS o las principales de Azure Active Directory para acceder a los datos de tu suscripción. Puedes delegar el acceso de lectura o escritura a BigQuery Omni, y puedes revocar el acceso en cualquier momento.
Flujo de datos cuando se consultan datos
En la siguiente imagen, se describe cómo se transfieren los datos entre Google Cloud y AWS o Azure para las siguientes consultas:
- Declaración
SELECT - Declaración
CREATE EXTERNAL TABLE

- El plano de control de BigQuery recibe trabajos de consulta desde la consola de Google Cloud, la herramienta de línea de comandos de bq, un método de API o una biblioteca cliente.
- En el plano de control de BigQuery, se envían trabajos de consulta para procesarlos en el plano de datos de BigQuery en AWS o Azure.
- El plano de datos de BigQuery recibe consultas desde el plano de control a través de una conexión de VPN.
- El plano de datos de BigQuery lee los datos de las tablas de tu bucket de Amazon S3 o Blob Storage.
- El plano de datos de BigQuery ejecuta el trabajo de consulta en los datos de la tabla. El procesamiento de los datos de las tablas se hace en la región de AWS o Azure especificada.
- El resultado de la consulta se transmite del plano de datos al plano de control a través de la conexión de VPN.
- El plano de control de BigQuery recibe los resultados del trabajo de consulta para mostrarlos en respuesta al trabajo de consulta. Estos datos se almacenan por hasta 24 horas.
- Se muestra el resultado de la consulta.
Para obtener más información, lee Consulta datos de Amazon S3 y Datos de Blob Storage.
Flujo de datos en la exportación de datos
En la siguiente imagen, se describe cómo se transfieren datos entre Google Cloud y AWS o Azure durante una declaración EXPORT DATA.

- El plano de control de BigQuery recibe trabajos de consulta de exportación desde la consola de Google Cloud, la herramienta de línea de comandos de bq, un método de API o una biblioteca cliente. La consulta contiene la ruta de destino para el resultado de consulta en tu bucket de Amazon S3 o Blob Storage.
- El plano de control de BigQuery envía trabajos de consulta de exportación para procesarlos en el plano de datos de BigQuery (en AWS o Azure).
- El plano de datos de BigQuery recibe la consulta de exportación del plano de control a través de la conexión de VPN.
- El plano de datos de BigQuery lee los datos de las tablas de tu bucket de Amazon S3 o Blob Storage.
- El plano de datos de BigQuery ejecuta el trabajo de consulta en los datos de la tabla. El procesamiento de los datos de las tablas se hace en la región especificada de AWS o Azure.
- BigQuery escribe el resultado de la consulta en la ruta de destino especificada en el bucket de Amazon S3 o Blob Storage.
Para obtener más información, consulta Exporta resultados de consultas a Amazon S3 y Blob Storage.
Beneficios
Rendimiento. Puedes obtener estadísticas más rápido, ya que los datos no se copian en diferentes nubes y las consultas se ejecutan en la misma región en la que residen tus datos.
Costo. Ahorras en costos de transferencia de datos salientes porque los datos no se mueven. No se aplican cargos adicionales a tu cuenta de AWS o Azure relacionados con el análisis de BigQuery Omni, ya que las consultas se ejecutan en clústeres administrados por Google. Solo se te facturará por ejecutar las consultas, con el modelo de precios de BigQuery.
Seguridad y administración de datos. Administras los datos en tu propia suscripción a AWS o Azure. No es necesario trasladar o copiar los datos sin procesar de la nube pública. Todo el procesamiento se hace en el servicio de múltiples usuarios de BigQuery que se ejecuta dentro de la misma región que tus datos.
Arquitectura sin servidores. Al igual que el resto de BigQuery, BigQuery Omni es una oferta sin servidores. Google implementa y administra los clústeres que ejecutan BigQuery Omni. No es necesario aprovisionar recursos ni administrar clústeres.
Administración sencilla. BigQuery Omni proporciona una interfaz de administración unificada a través de Google Cloud. BigQuery Omni puede usar tu cuenta de Google Cloud y los proyectos de BigQuery existentes. Puedes escribir una consulta en GoogleSQL en la consola de Google Cloud para consultar datos en AWS o Azure, y ver los resultados que se muestran en la consola de Google Cloud.
Transferencia entre nubes. Puedes cargar datos en tablas estándar de BigQuery desde buckets S3 y Blob Storage. Para obtener más información, consulta Transfiere datos de Amazon S3 y Blob Storage a BigQuery.
Almacenamiento en caché de metadatos para rendimiento
Puedes usar metadatos almacenados en caché para mejorar el rendimiento de las consultas en las tablas de BigLake que hacen referencia a los datos de Amazon S3. Es muy útil en los casos en que trabajas con grandes cantidades de archivos o si los datos están particionados como subárbol.
Las tablas de BigLake y de los objetos admiten el almacenamiento en caché de metadatos sobre archivos de fuentes de datos externas, como Cloud Storage y Amazon Simple Storage Service (Amazon S3) (vista previa). Los metadatos incluyen nombres de archivo, información de partición y metadatos físicos de archivos, como recuentos de filas. Puedes elegir si deseas habilitar o no el almacenamiento de metadatos en caché en una tabla. Las consultas con una gran cantidad de archivos y con filtros de partición de subárbol se benefician más del almacenamiento de metadatos en caché.
Si no habilitas el almacenamiento de metadatos en caché, las consultas en la tabla deben leer la fuente de datos externa para obtener metadatos de objeto, lo que aumenta la latencia de la consulta. ya que enumerar millones de archivos de la fuente de datos externa puede tardar varios minutos. Si habilitas el almacenamiento de metadatos en caché , las consultas pueden evitar la enumeración de archivos de la fuente de datos externa y lograr una reducción más rápida de las particiones y los archivos.
Hay dos propiedades que controlan esta característica:
- Inactividad máxima, que controla cuándo las consultas usan metadatos almacenados en caché
- Modo de almacenamiento de metadatos en caché, que controla cómo se recopilan los metadatos
Cuando tienes habilitado el almacenamiento de metadatos en caché, debes especificar el intervalo máximo de inactividad de metadatos que es aceptable para las operaciones en la tabla. Por ejemplo, si especificas un intervalo de 1 hora, las operaciones en la tabla usan metadatos almacenados en caché si se actualizaron en la última hora. Si los metadatos almacenados en caché son más antiguos que eso, la operación recurre a la recuperación de metadatos desde Cloud Storage. Puedes especificar un intervalo de inactividad de entre 30 minutos y 7 días.
Puedes actualizar la caché de forma automática o manual:
- Para las actualizaciones automáticas, la caché se actualiza a un intervalo definido por el sistema, que suele estar entre 30 y 60 minutos. Actualizar la caché de automática es una buena estrategia si los archivos de la fuente de datos externa se agregan, borran o modifican a intervalos aleatorios. Si necesitas controlar el momento de la actualización, por ejemplo, para activarla al final de un trabajo de extracción, transformación y carga, usa la actualización manual.
En el caso de las actualizaciones manuales, ejecuta el procedimiento del sistema
BQ.REFRESH_EXTERNAL_METADATA_CACHEpara actualizar la caché de metadatos en una programación que cumpla con tus requisitos. Actualizar la caché de forma manual es una buena estrategia si se agregan, se borran o se modifican los archivos en Cloud Storage, a intervalos conocidos, por ejemplo, como resultado de una canalización.Si emites varias actualizaciones manuales simultáneas, solo una tendrá éxito.
La caché de metadatos vence después de 7 días si no se actualiza.
Debes considerar cómo interactuarán los valores del intervalo de inactividad y el modo de almacenamiento de metadatos en caché antes de configurarlos. Considera los siguientes ejemplos:
- Si actualizas la caché de metadatos de una tabla de manual y estableces el intervalo de inactividad en 2 días, debes ejecutar el procedimiento del sistema
BQ.REFRESH_EXTERNAL_METADATA_CACHEcada 2 días o menos si deseas operaciones en la tabla para usar metadatos almacenados en caché. - Si actualizas de foma automática la caché de metadatos de una tabla y estableces el intervalo de inactividad en 30 minutos, es posible que algunas de las operaciones para la tabla lean desde Cloud Storage si los metadatos La actualización de la caché lleva más tiempo del período habitual de 30 a 60 minutos.
Para obtener información sobre los trabajos de actualización de metadatos, consulta la
vista INFORMATION_SCHEMA.JOBS,
como se muestra en el siguiente ejemplo:
SELECT * FROM `region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT` WHERE job_id LIKE '%metadata_cache_refresh%' AND creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 6 HOUR) ORDER BY start_time DESC LIMIT 10;
Para obtener más información, consulta Almacenamiento en caché de metadatos.
Tablas habilitadas para caché con vistas materializadas
Puedes usar vistas materializadas en las tablas habilitadas de caché de metadatos de Amazon Simple Storage Service (Amazon S3) para mejorar el rendimiento y la eficiencia cuando se consultan datos estructurados almacenados en Amazon S3. Estas vistas materializadas funcionan como vistas materializadas en tablas de almacenamiento administradas por BigQuery, incluidos los beneficios de actualización automática y ajuste inteligente.
Para que los datos de Amazon S3 en una vista materializada estén disponibles en una región de BigQuery compatible para uniones, crea una réplica de la vista materializada. Solo puedes crear réplicas de vistas materializadas en vistas de materiales autorizadas.
Limitaciones
Además de las limitaciones de las tablas de BigLake, se aplican las siguientes limitaciones a BigQuery Omni, lo que incluye tablas de BigLake basadas en datos de Amazon S3 y Blob Storage:
- Trabajar con datos en cualquiera de las regiones de BigQuery Omni no es compatible con las ediciones Standard y Enterprise Plus. Para obtener más información sobre las ediciones, consulta Introducción a las ediciones de BigQuery.
- Las vistas
OBJECT_PRIVILEGES,STREAMING_TIMELINE_BY_*,TABLE_SNAPSHOTS,TABLE_STORAGEyPARTITIONSINFORMATION_SCHEMAno están disponibles para las tablas de BigLake basadas en datos de Amazon S3 y Blob Storage. - Las vistas materializadas no son compatibles con el almacenamiento de BLOB.
- Las UDF de JavaScript no son compatibles.
No se admiten las siguientes instrucciones de SQL:
- Sentencias de BigQuery ML.
- Declaraciones de lenguaje de definición de datos (DDL) que requieren datos administrados en BigQuery. Por ejemplo, se admiten
CREATE EXTERNAL TABLE,CREATE SCHEMAoCREATE RESERVATION, pero noCREATE MATERIALIZED VIEW. - Declaraciones de lenguaje de manipulación de datos (DML).
Se aplican las siguientes limitaciones a las consultas y a la lectura de tablas temporales de destino (vista previa):
- No se admite la consulta de tablas temporales de destino con la declaración
SELECT. - No se admite el uso de la API de lectura de BigQuery Storage para leer datos de tablas temporales de destino.
- Cuando se usa el controlador ODBC, no se admiten las lecturas de alta capacidad de procesamiento (opción
EnableHTAPI).
- No se admite la consulta de tablas temporales de destino con la declaración
Las consultas programadas solo se admiten mediante la API o el método de la CLI. La opción tabla de destino está inhabilitada para las consultas. Solo se permiten consultas
EXPORT DATA.La API de BigQuery Storage no está disponible en regiones de BigQuery Omni.
Si tu consulta usa la cláusula
ORDER BYy tiene un tamaño de resultado superior a 256 MB, tu consulta falla. Para resolver esto, reduce el tamaño del resultado o quita la cláusulaORDER BYde la consulta. Para obtener más información sobre las cuotas de BigQuery Omni, consulta Cuotas y límites.No se admite el uso de claves de encriptación administradas por el cliente (CMEK) con conjuntos de datos y tablas externas.
Precios
Para obtener información sobre los precios y las ofertas de tiempo limitado en BigQuery Omni, consulta Precios de BigQuery Omni.
Cuotas y límites
Para obtener más información sobre las cuotas de BigQuery Omni, consulta Cuotas y límites.
Si el resultado de tu consulta es mayor a 20 GiB, considera exportar los resultados a Amazon S3 o Blob Storage. Para obtener información sobre las cuotas de la API de BigQuery Connection, consulta API de BigQuery Connection.
Ubicaciones
BigQuery Omni procesa las consultas en la misma ubicación en la que se encuentra el conjunto de datos que contiene las tablas que deseas consultar. Después de crear el conjunto de datos, la ubicación no se puede cambiar. Tus datos residen dentro de tu propia cuenta de AWS o Azure. Las regiones de BigQuery Omni admiten las reservas de la edición Enterprise y los precios del procesamiento a pedido (análisis). Para obtener más información sobre las ediciones, consulta Introducción a las ediciones de BigQuery.| Descripción de la región | Nombre de la región | Región de BigQuery ubicada | |
|---|---|---|---|
| AWS | |||
| AWS - US East (N. Norte) | aws-us-east-1 |
us-east4 |
|
| AWS: Oeste de EE.UU. (Oregón) | aws-us-west-2 |
us-west1 |
|
| AWS: Asia-Pacífico (Seúl) | aws-ap-northeast-2 |
asia-northeast3 |
|
| AWS: Europa (Irlanda) | aws-eu-west-1 |
europe-west1 |
|
| Azure | |||
| Azure - East US 2 | azure-eastus2 |
us-east4 |
|
¿Qué sigue?
- Aprende a conectarte a Amazon S3 y Blob Storage.
- Aprende a crear tablas de BigLake de Amazon S3 y Blob Storage.
- Aprende a consultar las tablas de BigLake de Amazon S3 y Blob Storage.
- Aprende a unir tablas de BigLake de Amazon S3 y Blob Storage con tablas de Google Cloud a través de uniones entre nubes.
- Obtén información sobre cómo exportar resultados de consultas a Amazon S3 y Blob Storage.
- Aprende a transferir datos de Amazon S3 y Blob Storage a BigQuery.
- Obtén más información sobre cómo configurar el perímetro de Controles del servicio de VPC.
- Obtén más información sobre cómo especificar tu ubicación