使用导入的 TensorFlow 模型进行预测
概览
本页面介绍如何将 TensorFlow 模型导入 BigQuery ML 数据集以及如何使用它们根据 SQL 查询进行预测。您可以使用以下界面导入 TensorFlow 模型:
- Google Cloud 控制台
- bq 命令行工具中的
bq query命令 - BigQuery API
如需详细了解如何将 TensorFlow 模型导入 BigQuery ML,包括格式和存储要求,请参阅用于导入 TensorFlow 模型的 CREATE
MODEL 语句。
导入 TensorFlow 模型
要将 TensorFlow 模型导入数据集,请执行以下步骤:
控制台
在 Google Cloud 控制台中,转到 BigQuery 页面。
在查询编辑器中输入
CREATE MODEL语句,如下所示。CREATE OR REPLACE MODEL `example_dataset.imported_tf_model` OPTIONS (MODEL_TYPE='TENSORFLOW', MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')
以上查询将位于
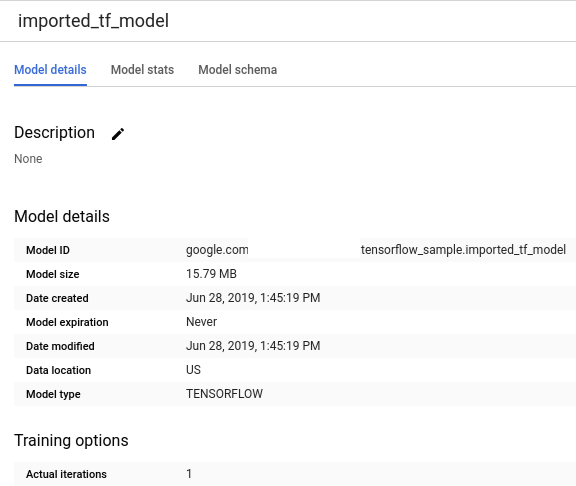
gs://cloud-training-demos/txtclass/export/exporter/1549825580/*的模型作为名为imported_tf_model的 BigQuery ML 模型导入。Cloud Storage URI 以通配符 (*) 结尾,因此 BigQuery ML 也会导入与该模型关联的任何资源。导入的模型是 TensorFlow 文本分类器模型,可预测哪个网站发布了给定文章标题。现在,您的新模型应显示在资源面板中。在展开项目中的每个数据集时,模型将与数据集中的其他 BigQuery 资源一起列出。模型由模型图标
 表示。
表示。如果您在资源面板中选择该新模型,则模型相关信息将显示在查询编辑器下方。
bq
要从 Cloud Storage 导入 TensorFlow 模型,请输入如下命令来运行批量查询:
bq query \
--use_legacy_sql=false \
"CREATE MODEL
`mydataset.mymodel`
OPTIONS
(MODEL_TYPE='TENSORFLOW',
MODEL_PATH='gs://bucket/path/to/saved_model/*')"
例如:
bq query --use_legacy_sql=false \
"CREATE OR REPLACE MODEL
`example_dataset.imported_tf_model`
OPTIONS
(MODEL_TYPE='TENSORFLOW',
MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')"
导入模型后,它应该显示在 bq ls [dataset_name] 的输出中:
$ bq ls example_dataset
tableId Type Labels Time Partitioning
------------------- ------- -------- -------------------
imported_tf_model MODEL
API
插入新作业并填充 jobs#configuration.query 属性,如以下请求正文所示:
{
"query": "CREATE MODEL `project_id:mydataset.mymodel` OPTIONS(MODEL_TYPE='TENSORFLOW' MODEL_PATH='gs://bucket/path/to/saved_model/*')"
}
使用导入的 TensorFlow 模型进行预测
要使用导入的 TensorFlow 模型进行预测,请执行以下步骤。以下示例假定您已导入 TensorFlow 模型,如上面的示例所示。
控制台
在 Google Cloud 控制台中,转到 BigQuery 页面。
在查询编辑器中,使用
ML.PREDICT输入查询,如下所示:SELECT * FROM ML.PREDICT(MODEL
example_dataset.imported_tf_model, ( SELECT title AS input FROMbigquery-public-data.hacker_news.full) )上述查询使用前项目的
example_dataset数据集中名为imported_tf_model的模型,以便根据full公共表中的输入数据进行预测,该公共表位于bigquery-public-data项目的hacker_news数据集中。在本例中,TensorFlow 模型的serving_input_fn函数指定,模型需要名为input的单个输入字符串,因此子查询会向子查询的SELECT语句中的列分配别名input。该查询的输出结果如下所示。在本示例中,模型输出
dense_1列(包含概率值数组)以及input列(包含输入表中的相应字符串值)。每个数组元素值代表相应输入字符串是某特定出版物中的文章标题的概率。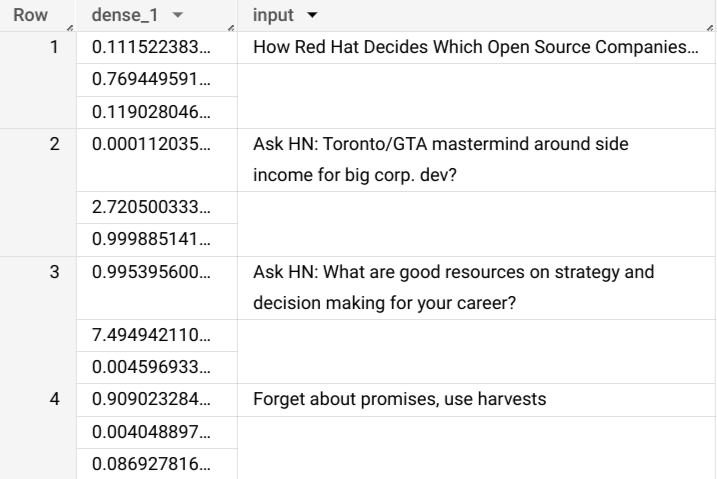
bq
要使用 input_data 表中的输入数据进行预测,请使用导入的 TensorFlow 模型 my_model 输入如下所示的命令:
bq query \
--use_legacy_sql=false \
'SELECT *
FROM ML.PREDICT(
MODEL `my_project.my_dataset.my_model`,
(SELECT * FROM input_data))'
例如:
bq query \
--use_legacy_sql=false \
'SELECT *
FROM ML.PREDICT(
MODEL `tensorflow_sample.imported_tf_model`,
(SELECT title AS input FROM `bigquery-public-data.hacker_news.full`))'
该示例会返回如下所示的结果:
+------------------------------------------------------------------------+----------------------------------------------------------------------------------+
| dense_1 | input |
+------------------------------------------------------------------------+----------------------------------------------------------------------------------+
| ["0.6251608729362488","0.2989124357700348","0.07592673599720001"] | How Red Hat Decides Which Open Source Companies t... |
| ["0.014276246540248394","0.972910463809967","0.01281337533146143"] | Ask HN: Toronto/GTA mastermind around side income for big corp. dev? |
| ["0.9821603298187256","1.8601855117594823E-5","0.01782100833952427"] | Ask HN: What are good resources on strategy and decision making for your career? |
| ["0.8611106276512146","0.06648492068052292","0.07240450382232666"] | Forget about promises, use harvests |
+------------------------------------------------------------------------+----------------------------------------------------------------------------------+
API
插入新作业并填充 jobs#configuration.query 属性,如以下请求正文所示:
{
"query": "SELECT * FROM ML.PREDICT(MODEL `my_project.my_dataset.my_model`, (SELECT * FROM input_data))"
}
后续步骤
- 如需详细了解如何导入 TensorFlow 模型,请参阅用于导入 TensorFlow 模型的
CREATE MODEL语句。 - 如需大致了解 BigQuery ML,请参阅 BigQuery ML 简介。
- 如需开始使用 BigQuery ML,请参阅在 BigQuery ML 中创建机器学习模型。
- 如需详细了解如何使用模型,请参阅以下资源: