インポートされた TensorFlow モデルで予測を行う
概要
このページでは、TensorFlow モデルを BigQuery ML データセットにインポートする方法と、そのモデルを使用して SQL クエリから予測を行う方法について説明します。TensorFlow モデルのインポートに使用できるインターフェースは次のとおりです。
- Google Cloud コンソール
- bq コマンドライン ツールの
bq queryコマンド - BigQuery API
形式やストレージの要件など、BigQuery ML への TensorFlow モデルのインポートの詳細は、TensorFlow モデルをインポートする CREATE
MODEL ステートメントをご覧ください。
TensorFlow モデルをインポートする
TensorFlow モデルをデータセットにインポートする手順は次のとおりです。
コンソール
Google Cloud コンソールで [BigQuery] ページに移動します。
クエリエディタで、次のような
CREATE MODELステートメントを入力します。CREATE OR REPLACE MODEL `example_dataset.imported_tf_model` OPTIONS (MODEL_TYPE='TENSORFLOW', MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')
上記のクエリでは、
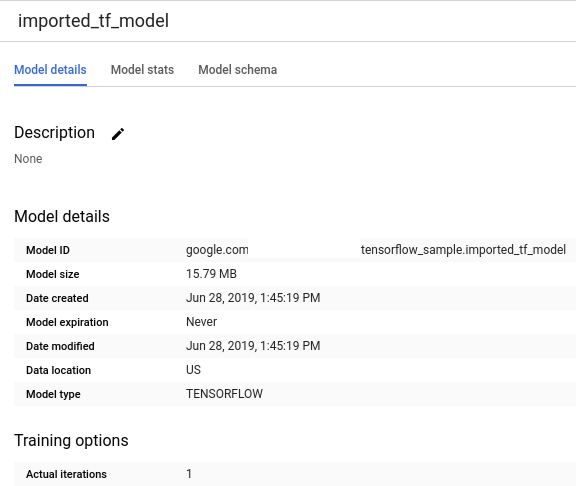
gs://cloud-training-demos/txtclass/export/exporter/1549825580/*にあるモデルがimported_tf_modelという BigQuery ML モデルとしてインポートされます。Cloud Storage の URI はワイルドカード文字(*)で終わるため、BigQuery ML はモデルに関連付けられているアセットもすべてインポートします。インポートしたモデルは、所定の記事タイトルをどのウェブサイトが公開したかを予測する TensorFlow テキスト分類モデルです。新しいモデルが [リソース] パネルに表示されます。プロジェクト内の各データセットを展開すると、データセット内の他の BigQuery リソースとともに、モデルが一覧表示されます。モデルにはモデルアイコン
 がついています。
がついています。[リソース] パネルで新しいモデルを選択すると、そのモデルに関する情報がクエリエディタの下に表示されます。
bq
TensorFlow モデルを Cloud Storage からインポートするには、次のようなコマンドを入力して、バッチクエリを実行します。
bq query \
--use_legacy_sql=false \
"CREATE MODEL
`mydataset.mymodel`
OPTIONS
(MODEL_TYPE='TENSORFLOW',
MODEL_PATH='gs://bucket/path/to/saved_model/*')"
例:
bq query --use_legacy_sql=false \
"CREATE OR REPLACE MODEL
`example_dataset.imported_tf_model`
OPTIONS
(MODEL_TYPE='TENSORFLOW',
MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')"
モデルをインポートすると、bq ls [dataset_name] の出力に表示されます。
$ bq ls example_dataset
tableId Type Labels Time Partitioning
------------------- ------- -------- -------------------
imported_tf_model MODEL
API
新しいジョブを挿入し、次に示すリクエストの本文のように jobs#configuration.query プロパティに値を入力します。
{
"query": "CREATE MODEL `project_id:mydataset.mymodel` OPTIONS(MODEL_TYPE='TENSORFLOW' MODEL_PATH='gs://bucket/path/to/saved_model/*')"
}
インポートされた TensorFlow モデルで予測を行う
インポートした TensorFlow モデルで予測を行う手順は次のとおりです。次の例では、上記の例のように TensorFlow モデルがインポートされていることを前提としています。
コンソール
Google Cloud コンソールで [BigQuery] ページに移動します。
クエリエディタで、次のように
ML.PREDICTを使用してクエリを入力します。SELECT * FROM ML.PREDICT(MODEL
example_dataset.imported_tf_model, ( SELECT title AS input FROMbigquery-public-data.hacker_news.full) )上記のクエリでは、現在のプロジェクトの
example_datasetデータセットにあるimported_tf_modelという名前のモデルを使用して、プロジェクトbigquery-public-dataのデータセットhacker_newsにある公開テーブルfullの入力データから予測を行います。この場合、TensorFlow モデルのserving_input_fn関数は、モデルがinputという単一の入力文字列を想定することを指定しているため、サブクエリはエイリアスinputをサブクエリのSELECTステートメントの列に割り当てます。このクエリは次のような結果を出力します。この例では、モデルは確率値の配列を含む列
dense_1と、入力テーブルの対応する文字列値を含むinput列を出力します。各配列要素の値は、対応する入力文字列が特定の公開物の記事タイトルである確率を表します。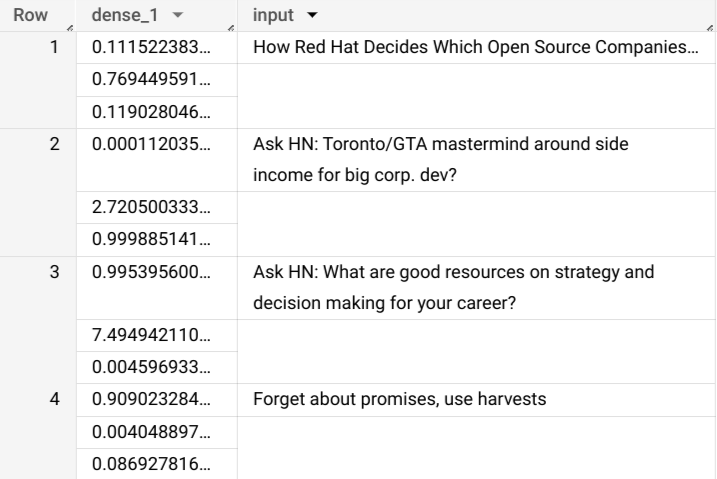
bq
テーブル input_data の入力データから予測を行うには、インポートした TensorFlow モデル my_model を使用して、次のようなコマンドを入力します。
bq query \
--use_legacy_sql=false \
'SELECT *
FROM ML.PREDICT(
MODEL `my_project.my_dataset.my_model`,
(SELECT * FROM input_data))'
例:
bq query \
--use_legacy_sql=false \
'SELECT *
FROM ML.PREDICT(
MODEL `tensorflow_sample.imported_tf_model`,
(SELECT title AS input FROM `bigquery-public-data.hacker_news.full`))'
この例では次のような結果が返されます。
+------------------------------------------------------------------------+----------------------------------------------------------------------------------+
| dense_1 | input |
+------------------------------------------------------------------------+----------------------------------------------------------------------------------+
| ["0.6251608729362488","0.2989124357700348","0.07592673599720001"] | How Red Hat Decides Which Open Source Companies t... |
| ["0.014276246540248394","0.972910463809967","0.01281337533146143"] | Ask HN: Toronto/GTA mastermind around side income for big corp. dev? |
| ["0.9821603298187256","1.8601855117594823E-5","0.01782100833952427"] | Ask HN: What are good resources on strategy and decision making for your career? |
| ["0.8611106276512146","0.06648492068052292","0.07240450382232666"] | Forget about promises, use harvests |
+------------------------------------------------------------------------+----------------------------------------------------------------------------------+
API
新しいジョブを挿入し、次に示すリクエストの本文のように jobs#configuration.query プロパティに値を入力します。
{
"query": "SELECT * FROM ML.PREDICT(MODEL `my_project.my_dataset.my_model`, (SELECT * FROM input_data))"
}
次のステップ
- TensorFlow モデルのインポートの詳細については、TensorFlow モデルをインポートする
CREATE MODELステートメントをご覧ください。 - BigQuery ML の概要で BigQuery ML の概要を確認する。
- BigQuery ML の使用を開始するには、BigQuery ML で機械学習モデルを作成するをご覧ください。
- モデルの操作の詳細については、次のリソースをご覧ください。