O BigQuery ML oferece suporte ao aprendizado não supervisionado. É possível aplicar o algoritmo k-means para agrupar seus dados em clusters. Ao contrário do machine learning supervisionado, que tem a ver com análise preditiva, o aprendizado supervisionado tem a ver com análise descritiva. Trata-se de entender os dados para que seja possível tomar decisões orientadas a dados.
Neste tutorial, você usará um modelo k-means simples no BigQuery ML para identificar clusters de dados no conjunto de dados público de Locações de Bicicletas de Londres. Os dados de Locações de Bicicletas de Londres contêm o número de locações do Santander Cycle Hire Scheme de Londres de 2011 até o presente. Os dados incluem carimbos de data/hora iniciais e finais, nomes das estações e duração dos passeios.
As consultas neste tutorial usam Funções geográficas disponíveis na análise geoespacial. Para mais informações sobre análise geoespacial, consulte esta página.
Objetivos
Neste tutorial, você verá como realizar as seguintes ações:- Criar um modelo de agrupamento k-means.
- Tomar decisões orientadas por dados usando como base a visualização de clusters do BigQuery ML.
Custos
Neste tutorial, há componentes faturáveis do Google Cloud, entre eles:
- BigQuery
- BigQuery ML
Para mais informações sobre os custos do BigQuery, consulte a página de preços do BigQuery.
Para mais sobre os custos do BigQuery ML, consulte Preços do BigQuery ML.
Antes de começar
- Faça login na sua conta do Google Cloud. Se você começou a usar o Google Cloud agora, crie uma conta para avaliar o desempenho de nossos produtos em situações reais. Clientes novos também recebem US$ 300 em créditos para executar, testar e implantar cargas de trabalho.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
- O BigQuery é ativado automaticamente em novos projetos.
Para ativar o BigQuery em um projeto preexistente, acesse
Ative a API BigQuery.
Introdução
Seus dados podem conter agrupamentos naturais ou clusters de dados, e convém identificar esses agrupamentos de maneira descritiva para tomar decisões baseadas em dados. Por exemplo, se você é um varejista, convém identificar agrupamentos naturais de clientes que têm hábitos de compra ou locais semelhantes. Esse processo é chamado de segmentação de clientes.
Os dados usados para realizar a segmentação de clientes podem incluir a loja que eles visitaram, quais itens compraram e quanto pagaram. Os modelos são criados para tentar entender como são esses grupos de perfis de clientes. Assim, é possível projetar itens atrativos para membros dos grupos.
Também é possível encontrar grupos de produtos entre os itens comprados. Nesse caso, você agruparia os itens com base em quem os comprou, quando foram comprados, onde foram comprados e outras características semelhantes. Os modelos são criados para determinar as características de um grupo de produtos. Assim, é possível tomar decisões informadas, como a melhor forma de melhorar a venda cruzada.
Neste tutorial, você usa o BigQuery ML para criar um modelo k-means que agrupa os dados de Locações de Bicicletas de Londres com base nos atributos das estações de bicicletas.
A criação do modelo k-means consiste nos passos a seguir.
- Primeiro passo: criar um conjunto de dados para armazenar o modelo.
- O primeiro passo é criar um conjunto de dados que armazene o modelo.
- Segundo passo: examinar os dados de treinamento.
- A próxima etapa é examinar os dados usados para treinar seu modelo de cluster executando uma consulta na tabela
london_bicycles. Como k-means é uma técnica de aprendizado não supervisionado, o treinamento do modelo não requer rótulos ou a divisão de dados entre treinamento e avaliação.
- Terceiro passo: criar um modelo k-means.
- O terceiro passo é criar o modelo k-means. Ao criar o modelo, o campo de clustering é
station_name. É possível agrupar dados com base no atributo da estação como, por exemplo, a distância da estação do centro da cidade.
- Etapa 4: usar a função
ML.PREDICTpara prever o cluster de uma estação. - Em seguida, é possível usar a função
ML.PREDICTpara prever o cluster de um determinado conjunto de estações. A previsão de clusters é feita para todos os nomes de estação que contêm a stringKennington.
- Etapa 4: usar a função
- Etapa 5: usar o modelo para tomar decisões orientadas por dados.
- O último passo é usar o modelo para tomar decisões orientadas por dados. Por exemplo, com base nos resultados do modelo, é possível determinar quais estações se beneficiariam de capacidade adicional.
Etapa 1: criar conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar o modelo de ML:
No console do Google Cloud, acesse a página do BigQuery.
No painel Explorer, clique no nome do seu projeto.
Clique em Conferir ações > Criar conjunto de dados.

Na página Criar conjunto de dados, faça o seguinte:
Para o código do conjunto de dados, insira
bqml_tutorial.Em Tipo de local, selecione Multirregional e selecione UE (várias regiões na União Europeia).
O conjunto de dados público de Locações de Bicicletas de Londres é armazenado na multirregião
EU. O conjunto de dados precisa estar no mesmo local.Mantenha as configurações padrão restantes e clique em Criar conjunto de dados.

Etapa 2: examinar os dados de treinamento
Em seguida, são examinados os dados usados para treinar o modelo k-means. Neste tutorial, as estações de bicicletas são agrupadas com base nos seguintes atributos:
- Duração das locações
- Número de viagens por dia
- Distância do centro da cidade
SQL
A consulta GoogleSQL a seguir é usada para examinar os dados usados para treinar o modelo k-means.
#standardSQL
WITH
hs AS (
SELECT
h.start_station_name AS station_name,
IF
(EXTRACT(DAYOFWEEK
FROM
h.start_date) = 1
OR EXTRACT(DAYOFWEEK
FROM
h.start_date) = 7,
"weekend",
"weekday") AS isweekday,
h.duration,
ST_DISTANCE(ST_GEOGPOINT(s.longitude,
s.latitude),
ST_GEOGPOINT(-0.1,
51.5))/1000 AS distance_from_city_center
FROM
`bigquery-public-data.london_bicycles.cycle_hire` AS h
JOIN
`bigquery-public-data.london_bicycles.cycle_stations` AS s
ON
h.start_station_id = s.id
WHERE
h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP)
AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ),
stationstats AS (
SELECT
station_name,
isweekday,
AVG(duration) AS duration,
COUNT(duration) AS num_trips,
MAX(distance_from_city_center) AS distance_from_city_center
FROM
hs
GROUP BY
station_name, isweekday )
SELECT
*
FROM
stationstats
ORDER BY
distance_from_city_center ASC
Detalhes da consulta
Essa consulta extrai dados sobre locações de bicicletas, incluindo start_station_name e duration, e os associa às informações da estação, como distance-from-city-center. Em seguida, ela calcula os atributos da estação em stationstats, incluindo a duração média e o número de viagens, e passa pelo atributo da estação distance_from_city_center.
Essa consulta usa a cláusula WITH para definir subconsultas. A consulta também usa as funções de análise geoespacial ST_DISTANCE e ST_GEOGPOINT. Para mais informações sobre essas funções, consulte Funções geográficas. Para mais informações sobre a análise geoespacial, consulte esta página.
Executar a consulta
A consulta a seguir compila os dados de treinamento e também é usada na instrução CREATE MODEL posteriormente neste tutorial.
Para executar a consulta, faça o seguinte:
- Acessar a página do BigQuery.
No painel Editor, execute a seguinte instrução SQL:
WITH hs AS ( SELECT h.start_station_name AS station_name, IF (EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, "weekend", "weekday") AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5))/1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * FROM stationstats ORDER BY distance_from_city_center ASCApós concluir a consulta, clique na guia Resultados abaixo da área de texto da consulta. A guia Resultados mostra as colunas consultada que são usadas para treinar o modelo:
station_name,duration,num_trips,distance_from_city_center. Os resultados terão a aparência abaixo.

BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Etapa 3: criar um modelo k-means
Agora que você examinou os dados de treinamento, o próximo passo será criar um modelo k-means usando os dados.
SQL
É possível criar e treinar um modelo k-means usando o CREATE MODEL com a opção model_type=kmeans.
Detalhes da consulta
A instrução CREATE MODEL especifica o número de clusters a serem usados: quatro. Na instrução SELECT, a cláusula EXCEPT exclui a coluna station_name porque station_name não é um recurso. A consulta cria uma linha única por station_name, e somente os recursos são mencionados na instrução SELECT.
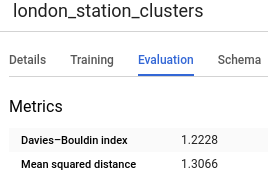
Se a opção num_clusters for omitida, o BigQuery ML escolherá um padrão razoável com base no número total de linhas dos dados de treinamento. Também é possível realizar o ajuste de hiperparâmetros para encontrar um bom número. Para determinar um número ideal de clusters, execute a consulta CREATE MODEL para obter valores diferentes de num_clusters, localize a medida de erro e escolha o ponto em que a medida de erro está no valor mínimo. A medida de erro pode ser extraída selecionando o modelo e clicando na guia Avaliação. Essa guia mostra o índice Davies–Bouldin (em inglês).
Executar a consulta
A consulta a seguir adiciona uma instrução CREATE MODEL à consulta usada para examinar os dados de treinamento e também remove os campos id dos dados.
Para executar a consulta e criar um modelo k-means:
- Acessar a página do BigQuery.
No painel Editor, execute a seguinte instrução SQL:
CREATE OR REPLACE MODEL `bqml_tutorial.london_station_clusters` OPTIONS(model_type='kmeans', num_clusters=4) AS WITH hs AS ( SELECT h.start_station_name AS station_name, IF (EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, "weekend", "weekday") AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5))/1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday) SELECT * EXCEPT(station_name, isweekday) FROM stationstatsNo painel de navegação, na seção Recursos, expanda o nome do projeto, clique em bqml_tutorial e, depois, em london_station_clusters.
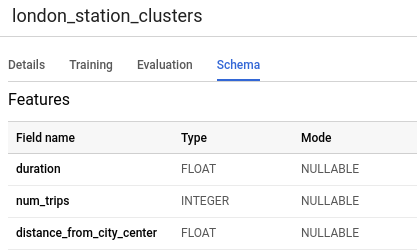
Clique na guia Esquema. O esquema do modelo lista os quatro atributos de estação que o BigQuery ML usou para realizar o clustering. O esquema será semelhante a este:
- Clique na guia Avaliação. Essa guia mostra visualizações dos clusters identificados pelo modelo k-means. Em Recursos numéricos, os gráficos de barras exibem até 10 dos valores de atributos numéricos mais importantes para cada centroide. É possível selecionar quais recursos visualizar no menu suspenso.

BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Etapa 4: usar a função ML.PREDICT para prever o cluster de uma estação
Para identificar o cluster ao qual uma estação específica pertence, use a função ML.PREDICT SQL ou a função predict DataFrames do BigQuery
SQL
Detalhes da consulta
Essa consulta usa a função REGEXP_CONTAINS para encontrar todas as entradas da coluna station_name que contêm a string "Kennington". A função ML.PREDICT usa esses valores para prever quais clusters conteriam essas estações.
Executar a consulta
A consulta a seguir prevê o cluster de todas as estações que têm a string "Kennington" no nome.
Para executar a consulta ML.PREDICT:
- Acessar a página do BigQuery.
No painel Editor, execute a seguinte instrução SQL:
WITH hs AS ( SELECT h.start_station_name AS station_name, IF (EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, "weekend", "weekday") AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5))/1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT(nearest_centroids_distance) FROM ML.PREDICT( MODEL `bqml_tutorial.london_station_clusters`, ( SELECT * FROM stationstats WHERE REGEXP_CONTAINS(station_name, 'Kennington')))Após concluir a consulta, clique na guia Resultados abaixo da área de texto da consulta. Os resultados terão a aparência abaixo.

BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Etapa 5: usar o modelo para tomar decisões orientadas por dados
Os resultados da avaliação podem ajudá-lo a interpretar os diferentes clusters. No exemplo a seguir, o centroide 3 mostra uma estação de cidade movimentada perto do centro da cidade. O Centroide 2 mostra a segunda estação da cidade, que é menos movimentada e usada para aluguéis por mais tempo. O Centroide 1 mostra uma estação menos movimentada, com aluguéis de menor duração. O Centroide 4 mostra uma estação suburbana com viagens mais longas.
Com base nesses resultados, é possível usar os dados para informar as suas decisões. Exemplo:
Vamos supor que você precise experimentar um novo tipo de trava. Qual cluster de estações precisa ser escolhido como tema desse experimento? As estações no centroide 1, no centroide 2 ou no centroide 4 parecem ser escolhas lógicas, porque não são as estações mais movimentadas.
Vamos supor que você queira abastecer algumas estações com bicicletas de corrida. Quais estações deve escolher? Centroide 4 é o grupo de estações que estão longe do centro da cidade, cujas viagens são as mais longas. Elas são as candidatas mais prováveis a bicicletas de corrida.
Limpeza
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
- exclua o projeto que você criou; ou
- Mantenha o projeto e exclua o conjunto de dados.
Excluir o conjunto de dados
A exclusão do seu projeto removerá todos os conjuntos de dados e tabelas no projeto. Caso prefira reutilizá-lo, exclua o conjunto de dados criado neste tutorial:
Se necessário, abra a página do BigQuery no console do Google Cloud.
Na navegação, clique no conjunto de dados bqml_tutorial criado.
Clique em Excluir conjunto de dados no lado direito da janela. Essa ação exclui o conjunto de dados e o modelo.
Na caixa de diálogo Excluir conjunto de dados, confirme o comando de exclusão digitando o nome do seu conjunto de dados (
bqml_tutorial). Em seguida, clique em Excluir.
Excluir o projeto
Para excluir o projeto:
- No Console do Google Cloud, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir .
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
A seguir
- Para uma visão geral sobre ML do BigQuery, consulte Introdução ao ML do BigQuery.
- Para mais informações sobre como criar modelos, consulte a página de sintaxe
CREATE MODEL.