In dieser Anleitung erfahren Sie, wie Sie in BigQuery ML die Hyperparameter-Abstimmung verwenden. Dazu geben Sie die Trainingsoption NUM_TRIALS an, um eine Reihe von Modelltrainingstests zu aktivieren.
In dieser Anleitung verwenden Sie die Beispieltabelle tlc_yellow_trips_2018 zum Erstellen eines Modells zur Vorhersage der Spitze einer Taxifahrt. Mit der Hyperparameter-Abstimmung zeigt das Modell eine Leistungsverbesserung von ca. 40% im Hyperparameter-Abstimmungsziel R2_SCORE.
Lernziele
In dieser Anleitung verwenden Sie:
- BigQuery ML zur Erstellung eines linearen Regressionsmodells unter Verwendung der
CREATE MODEL-Anweisung, wobeiNUM_TRIALSauf 20 gesetzt ist. - Die
ML.TRIAL_INFO-Funktion, mit der die Übersicht über alle 20 Tests geprüft wird - Die
ML.EVALUATE-Funktion zur Bewertung des ML-Modells - Die Funktion
ML.PREDICTzum Erstellen von Vorhersagen mithilfe des ML-Modells
Kosten
In dieser Anleitung werden kostenpflichtige Komponenten von Google Cloud verwendet, darunter:
- BigQuery
- BigQuery ML
Weitere Informationen zu den Kosten von BigQuery finden Sie auf der Seite BigQuery-Preise.
Vorbereitung
- Melden Sie sich bei Ihrem Google Cloud-Konto an. Wenn Sie mit Google Cloud noch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
- BigQuery ist in neuen Projekten automatisch aktiviert.
Zum Aktivieren von BigQuery in einem vorhandenen Projekt wechseln Sie zu
BigQuery API aktivieren.
.
Schritt 1: Trainings-Dataset erstellen
Erstellen Sie ein BigQuery-Dataset zum Speichern Ihres ML-Modells:
Rufen Sie in der Google Cloud Console die Seite „BigQuery“ auf.
Klicken Sie im Bereich Explorer auf den Namen Ihres Projekts.
Klicken Sie auf Aktionen ansehen > Dataset erstellen.
Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
Geben Sie unter Dataset-ID
bqml_tutorialein.Wählen Sie als Standorttyp die Option Mehrere Regionen und dann USA (mehrere Regionen in den USA) aus.
Die öffentlichen Datasets sind am multiregionalen Standort
USgespeichert. Der Einfachheit halber sollten Sie Ihr Dataset am selben Standort speichern.Übernehmen Sie die verbleibenden Standardeinstellungen unverändert und klicken Sie auf Dataset erstellen.

Schritt 2: Trainingseingabetabelle erstellen
In diesem Schritt erfassen Sie die Trainingseingabetabelle mit 100.000 Zeilen.
Schema der Quelltabelle
tlc_yellow_trips_2018ansehen.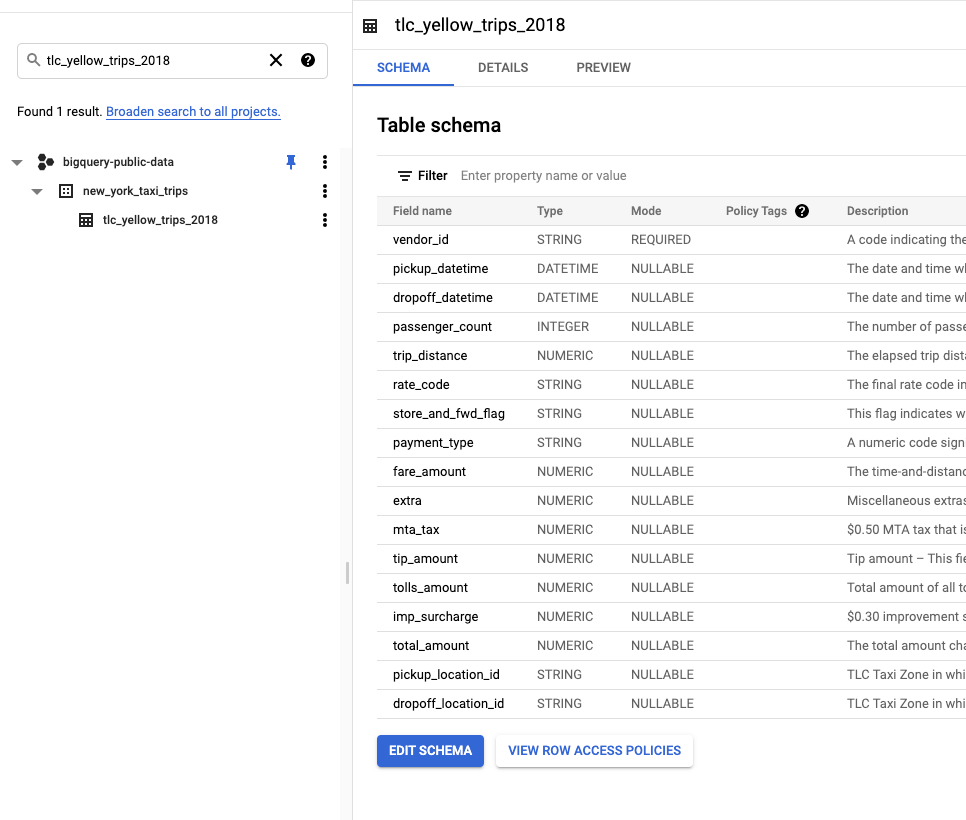
Erstellen Sie die Trainingseingabedatentabelle.
CREATE TABLE `bqml_tutorial.taxi_tip_input` AS SELECT * EXCEPT(tip_amount), tip_amount AS label FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2018` WHERE tip_amount IS NOT NULL LIMIT 100000
Schritt 3: Modell erstellen
Erstellen Sie als Nächstes mit der Beispieltabelle tlc_yellow_trips_2018 in BigQuery ein lineares Regressionsmodell mit Hyperparameter-Abstimmung. Die folgende GoogleSQL-Abfrage wird verwendet, um das Modell mit Hyperparameter-Abstimmung zu erstellen.
CREATE MODEL `bqml_tutorial.hp_taxi_tip_model` OPTIONS (MODEL_TYPE='LINEAR_REG', NUM_TRIALS=20, MAX_PARALLEL_TRIALS=2) AS SELECT * FROM `bqml_tutorial.taxi_tip_input`
Abfragedetails
Das Modell LINEAR_REG hat zwei einstellbare Hyperparameter: l1_reg und l2_reg.
Die obige Abfrage verwendet den Standardsuchbereich. Sie können den Suchbereich auch explizit angeben:
OPTIONS
(...
L1_REG=HPARAM_RANGE(0, 20),
L2_REG=HPARAM_CANDIDATES([0, 0.1, 1, 10]))
Darüber hinaus verwenden diese anderen Trainingsoptionen für Hyperparameter-Abstimmung auch ihre Standardwerte:
- HPARAM_TUNING_ALGORITHM:
"VIZIER_DEFAULT" - HPARAM_TUNING_OBJECTIVES:
["r2_score"]
MAX_PARALLEL_TRIALS ist auf 2 gesetzt, um den Abstimmungsvorgang zu beschleunigen. Da zu zwei Zeitpunkten jeweils 2 Versuche ausgeführt werden, dauert die gesamte Feinabstimmung ungefähr 10 statt 20 serielle Trainingsjobs. Beachten Sie jedoch, dass die beiden gleichzeitigen Versuche nicht von den Trainingsergebnissen des jeweils anderen profitieren können.
Abfrage CREATE MODEL ausführen
So führen Sie die Abfrage CREATE MODEL zum Erstellen und Trainieren des Modells aus:
Klicken Sie in der Google Cloud Console auf Neue Abfrage erstellen.
Geben Sie im obigen Textfeld des Abfrageeditors die folgende GoogleSQL-Abfrage ein.
Klicken Sie auf Ausführen.
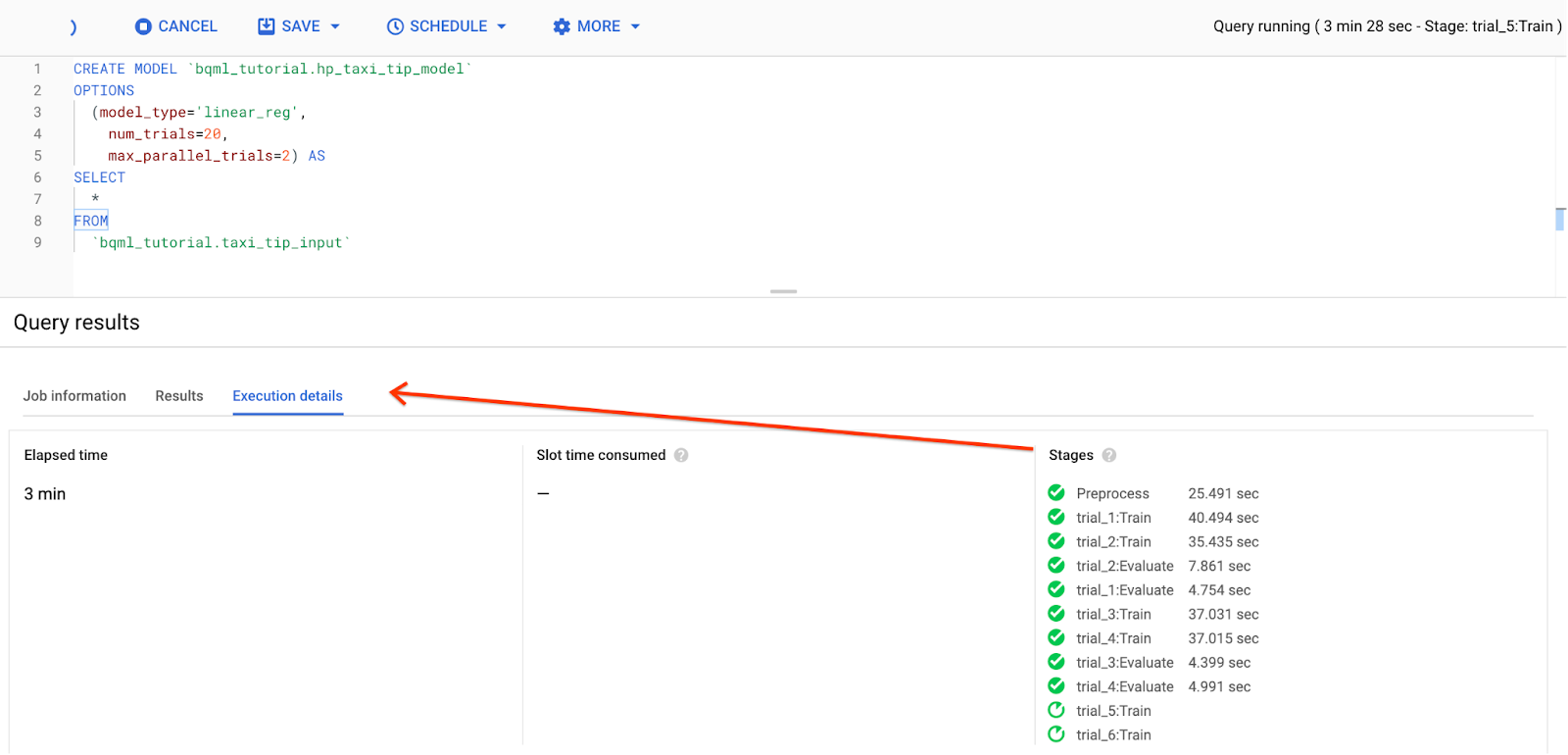
Die Abfrage dauert etwa 17 Minuten. Sie können den Fortschritt der Abstimmung in den Ausführungsdetails unter „Phasen” verfolgen:
Schritt 4: Informationen zu Testversionen abrufen
Mit der Funktion ML.TRIAL_INFO können Sie die Übersicht über alle Tests einschließlich ihrer Hyperparameter, Ziele, Status und der optimalen Testversion abrufen. Das Ergebnis können Sie in der Google Cloud Console sehen, nachdem der SQL-Server ausgeführt wurde.
SELECT * FROM ML.TRIAL_INFO(MODEL `bqml_tutorial.hp_taxi_tip_model`)
Sie können diese SQL-Abfrage ausführen, sobald ein Test abgeschlossen ist. Wenn die Abstimmung in der Mitte beendet wird, bleiben alle bereits abgeschlossenen Tests verfügbar.
Schritt 5: Modell bewerten
Nachdem Sie das Modell erstellt haben, können Sie die Bewertungsmesswerte aller Tests mithilfe der Funktion ML.EVALUATE oder über die Google Cloud Console abrufen.
Führen Sie ML.EVALUATE aus
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.hp_taxi_tip_model`)
Diese SQL-Datei ruft Bewertungsmesswerte für alle Tests ab, die aus den TEST-Daten berechnet wurden. Prüfen Sie den Abschnitt Datenaufteilung, um den Unterschied zwischen ML.TRIAL_INFO-Zielen und ML.EVALUATE-Bewertungsmesswerten zu sehen.
Sie können auch eine bestimmte Testversion bewerten, indem Sie Ihre eigenen Daten angeben. Weitere Informationen finden Sie hier: ML.EVALUATE.
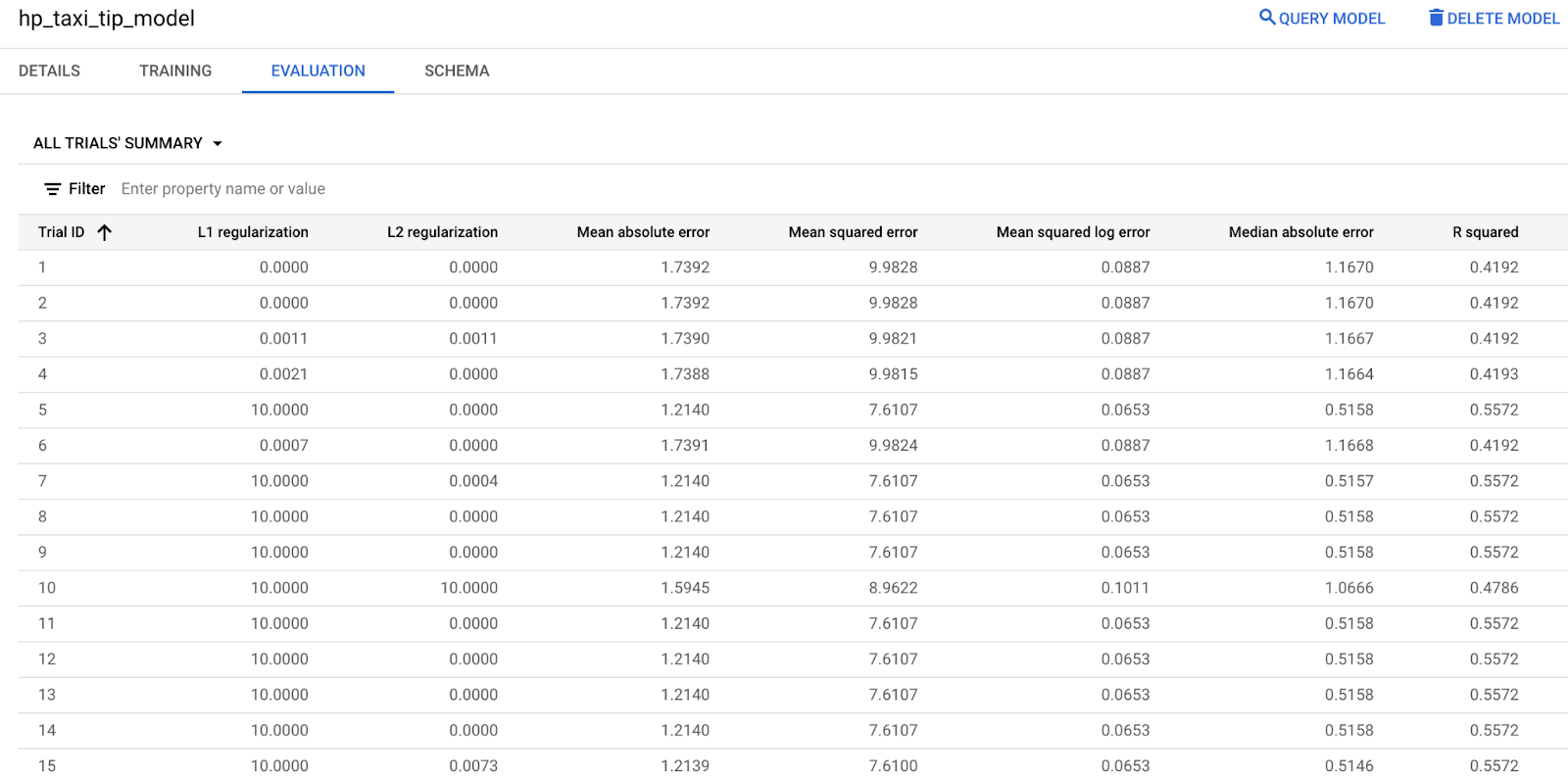
Bewertungsmesswerte über die Google Cloud Console prüfen
Sie können auch Bewertungsmesswerte prüfen, indem Sie den Tab EVALUATION auswählen.
Schritt 6: Modell verwenden, um Taxitipps vorherzusagen
Nachdem Sie Ihr Modell ausgewertet haben, besteht der nächste Schritt darin, den Taxitipp zu prognostizieren.
Die Abfrage zur Vorhersage des Ergebnisses lautet so:
SELECT
*
FROM
ML.PREDICT(MODEL `bqml_tutorial.hp_taxi_tip_model`,
(
SELECT
*
FROM
`bqml_tutorial.taxi_tip_input`
LIMIT 10))
Abfragedetails
Die oberste SELECT-Anweisung ruft alle Spalten einschließlich der Spalte predicted_label ab. Diese Spalte wird von der ML.PREDICT-Funktion generiert.
Wenn Sie die Funktion ML.PREDICT verwenden, lautet der Ausgabespaltenname für das Modell predicted_label_column_name.
Die Vorhersage wird standardmäßig für den optimalen Test getroffen. Sie können einen anderen Test auswählen, indem Sie den Parameter trial_id angeben.
SELECT
*
FROM
ML.PREDICT(MODEL `bqml_tutorial.hp_taxi_tip_model`,
(
SELECT
*
FROM
`bqml_tutorial.taxi_tip_input`
LIMIT
10),
STRUCT(3 AS trial_id))
Weitere Informationen zur Verwendung von Modellbereitstellungsfunktionen finden Sie unter ML.PREDICT.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
- Sie können das von Ihnen erstellte Projekt löschen.
- Sie können das Projekt aber auch behalten und das Dataset löschen.
Dataset löschen
Wenn Sie Ihr Projekt löschen, werden alle Datasets und Tabellen entfernt. Wenn Sie das Projekt wieder verwenden möchten, können Sie das in dieser Anleitung erstellte Dataset löschen:
Rufen Sie, falls erforderlich, die Seite "BigQuery" in der Google Cloud Console auf.
Wählen Sie im Navigationsbereich das Dataset bqml_tutorial aus, das Sie erstellt haben.
Klicken Sie auf der rechten Seite des Fensters auf Dataset löschen. Das Dataset, die Tabelle und alle Daten werden gelöscht.
Bestätigen Sie im Dialogfeld Dataset löschen den Löschbefehl. Geben Sie dazu den Namen des Datasets (
bqml_tutorial) ein und klicken Sie auf Löschen.
Projekt löschen
So löschen Sie das Projekt:
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Nächste Schritte
- Weitere Informationen über das maschinelle Lernen im Machine Learning Crash Course lesen
- Eine Übersicht über BigQuery ML finden Sie unter Einführung in BigQuery ML.
- Weitere Informationen zur Google Cloud Console finden Sie unter Google Cloud Console verwenden.