Crea modelos de aprendizaje automático en BigQuery ML
En este instructivo, se presenta a los usuarios BigQuery ML a través de la consola de Google Cloud.
BigQuery ML permite a los usuarios crear y ejecutar modelos de aprendizaje automático en BigQuery a través de consultas en SQL y código de Python. El objetivo es democratizar el aprendizaje automático. A fin de lograrlo, se habilita a los profesionales de SQL para que compilen modelos con sus herramientas existentes y se elimina la necesidad de trasladar datos con el fin de aumentar la velocidad de desarrollo.
En este instructivo, se usa el ejemplo Conjunto de datos de muestra de Google Analytics para BigQuery a fin de crear un modelo que prediga si un visitante de un sitio web realizará una transacción. Para obtener más información sobre el esquema del conjunto de datos de Analytics, consulta Esquema de BigQuery Export en el Centro de ayuda de Analytics.
Objetivos
En este instructivo, usarás las siguientes funciones:
- BigQuery ML para crear un modelo de regresión logística binaria con la declaración
CREATE MODEL - La función
ML.EVALUATEpara evaluar el modelo de AA - La función
ML.PREDICTpara hacer predicciones con el modelo de AA
Costos
En este instructivo, se usan componentes facturables de Google Cloud, incluidos los siguientes:
- BigQuery
- BigQuery ML
Para obtener más información sobre los costos de BigQuery, consulta la página Precios de BigQuery.
Para obtener más información sobre los costos de BigQuery ML, consulta los precios de BigQuery ML.
Antes de comenzar
- Accede a tu cuenta de Google Cloud. Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
- BigQuery se habilita de forma automática en proyectos nuevos.
Para activar BigQuery en un proyecto existente, ve a
Habilita la API de BigQuery.
Crea el conjunto de datos
Crea un conjunto de datos de BigQuery para almacenar tu modelo de AA:
En la consola de Google Cloud, ve a la página de BigQuery.
En el panel Explorador, haz clic en el nombre de tu proyecto.
Haz clic en Ver acciones > Crear conjunto de datos.

En la página Crear conjunto de datos, haz lo siguiente:
En ID del conjunto de datos, ingresa
bqml_tutorial.En Tipo de ubicación, selecciona Multirregión y, luego, EE.UU. (varias regiones en Estados Unidos).
Los conjuntos de datos públicos se almacenan en la multirregión
US. Para que sea más simple, almacena tu conjunto de datos en la misma ubicación.Deja la configuración predeterminada restante como está y haz clic en Crear conjunto de datos.

Cree su modelo
A continuación, debes crear un modelo de regresión logística con un conjunto de datos de muestra de Analytics para BigQuery.
SQL
Con la siguiente consulta de GoogleSQL se crea el modelo que debes usar para predecir si un visitante del sitio web hará una transacción.
#standardSQL CREATE MODEL `bqml_tutorial.sample_model` OPTIONS(model_type='logistic_reg') AS SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20160801' AND '20170630'
Además de crear el modelo, cuando ejecutas una consulta que contiene la declaración CREATE MODEL, se entrena el modelo con los datos recuperados por la declaración SELECT de tu consulta.
Detalles de la consulta
La cláusula CREATE MODEL se usa para crear y entrenar el modelo llamado bqml_tutorial.sample_model.
La cláusula OPTIONS(model_type='logistic_reg') indica que está creando un modelo de regresión logística.
Un modelo de regresión logística intenta dividir los datos de entrada en dos clases y presenta la probabilidad de que los datos estén en una de las clases. Por lo general, lo que intentas detectar (por ejemplo, si un correo electrónico es spam) se representa con un 1 y todo lo demás se representa con un 0. Si el modelo de regresión logística da como resultado un 0.9, hay un 90% de probabilidad de que la entrada sea lo que intentas detectar (el correo electrónico es spam).
La declaración SELECT de la consulta recupera las siguientes columnas que usa el modelo para predecir la probabilidad de que un cliente complete una transacción:
totals.transactions: la cantidad total de transacciones de comercio electrónico dentro de la sesión. Si la cantidad de transacciones esNULL, el valor en la columnalabelse establece en0. De lo contrario, se establece como1. Estos valores representan los posibles resultados. Crear un alias con el nombrelabeles una alternativa a la configuración de la opcióninput_label_cols=en la declaraciónCREATE MODEL.device.operatingSystem: el sistema operativo del dispositivo del visitante.device.isMobile: indica si el dispositivo del visitante es un dispositivo móvil.geoNetwork.country: el país de origen de las sesiones, en función de la dirección IP.totals.pageviews: la cantidad total de páginas vistas dentro de la sesión.
La cláusula FROM, bigquery-public-data.google_analytics_sample.ga_sessions_*, indica que estás consultando el conjunto de datos de muestra de Google Analytics.
Este conjunto de datos está en el proyecto bigquery-public-data. Consultas un conjunto de tablas fragmentadas por fecha. Esto se representa con un comodín en el nombre de la tabla: google_analytics_sample.ga_sessions_*.
La cláusula WHERE, _TABLE_SUFFIX BETWEEN '20160801' AND '20170630', limita la cantidad de tablas que analiza la consulta. El período analizado es del 1 de agosto de 2016 al 30 de junio de 2017.
Ejecuta la consulta CREATE MODEL
A fin de ejecutar la consulta CREATE MODEL para crear y entrenar tu modelo, sigue estos pasos:
- En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva. Si este texto no está disponible para hacer clic, el Editor de consultas ya está abierto.

Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL CREATE MODEL `bqml_tutorial.sample_model` OPTIONS(model_type='logistic_reg') AS SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20160801' AND '20170630'
Haz clic en Ejecutar.
La consulta tarda varios minutos en completarse. Una vez completada la primera iteración, tu modelo (
sample_model) aparece en el panel de navegación. Debido a que en la consulta se usa una sentenciaCREATE MODELpara crear un modelo, no se muestran los resultados de la consulta.Puedes observar el modelo en entrenamiento en la pestaña Estadísticas del modelo. En cuanto se completa la primera iteración, la pestaña se actualiza. Las estadísticas se actualizan a medida que se completan las iteraciones.
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Obtén estadísticas de entrenamiento
Para ver los resultados del entrenamiento de modelos, puedes usar la función ML.TRAINING_INFO o puedes ver las estadísticas en la consola de Google Cloud En este instructivo, usarás la consola de Google Cloud.
El aprendizaje automático consiste en crear un modelo que pueda usar datos para hacer una predicción. El modelo no es más que una función que toma datos de entrada y realiza cálculos para producir un resultado, es este caso, una predicción.
Los algoritmos de aprendizaje automático toman varios ejemplos en los que ya se conoce la predicción (como los datos históricos de las compras de los usuarios) y ajustan, de forma iterativa, las ponderaciones en el modelo para que sus predicciones coincidan con los valores reales. Para ello, minimiza qué tan equivocado está el modelo con una métrica llamada “pérdida”.
Se espera que para cada iteración, la pérdida debería disminuir (idealmente a cero). Una pérdida de cero significa que el modelo es 100% preciso.
Para ver las estadísticas de entrenamiento de modelos que se generaron cuando ejecutaste la consulta CREATE MODEL, sigue estos pasos:
En el panel de navegación de la consola de Cloud, en la sección Recursos, expande [PROJECT_ID] > bqml_tutorial y, luego, haz clic en sample_model.
Haz clic en la pestaña Estadísticas del modelo (Model stats). Los resultados deberían verse de la siguiente manera:
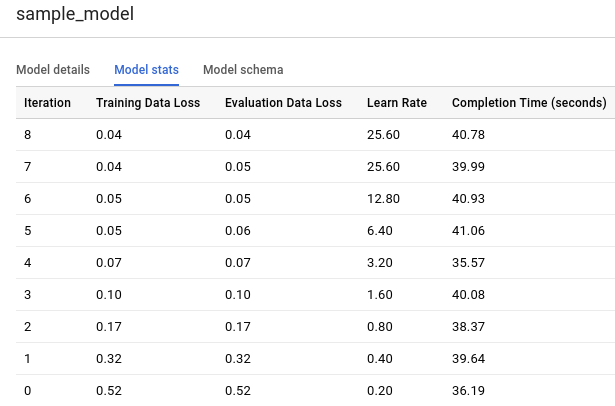
La columna Pérdida de datos de entrenamiento representa la métrica de pérdida calculada después de la iteración dada en el conjunto de datos de entrenamiento. Como se realizó una regresión logística, esta columna es la pérdida logística. La columna Pérdida de datos de evaluación es la misma métrica de pérdida calculada en el conjunto de datos de exclusión (datos que se usan a fin de validar el modelo y, por lo tanto, no se incluyen en el entrenamiento).
BigQuery ML divide los datos de entrada de manera automática en un conjunto de entrenamiento y un conjunto de exclusión para evitar el sobreajuste del modelo. Esto es necesario para que el algoritmo de entrenamiento no se adapte a los datos conocidos de tal forma que luego no generalice a nuevos ejemplos no vistos.
Training Data Loss y Evaluation Data Loss son valores de pérdida promedio de todos los ejemplos en los conjuntos respectivos.
Para obtener más detalles sobre la función
ML.TRAINING_INFO, consulta la referencia de la sintaxis de BigQuery ML.
Evalúa tu modelo
Después de crear tu modelo, evalúas el rendimiento del clasificador con la función ML.EVALUATE. La función ML.EVALUATE evalúa los valores previstos frente a los datos reales. Para calcular las métricas específicas de regresión logística, usa la función de SQL ML.ROC_CURVE o la función bigframes.ml.metrics.roc_curve de BigQuery DataFrames.
En este instructivo, se usa un modelo de clasificación binaria que detecta transacciones. Las dos clases son los valores de la columna label: 0 (sin transacciones) y 1 (transacción realizada).
SQL
La consulta que se usa para evaluar el modelo es la siguiente:
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.sample_model`, ( SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801'))
Detalles de la consulta
La primera sentencia SELECT recupera las columnas de tu modelo.
La cláusula FROM usa la función ML.EVALUATE en el modelo bqml_tutorial.sample_model.
La declaración SELECT anidada de esta consulta y la cláusula FROM son las mismas que las de la consulta CREATE MODEL.
La cláusula WHERE, _TABLE_SUFFIX BETWEEN '20170701' AND '20170801', limita la cantidad de tablas que analiza la consulta. El período analizado es del 1 de julio de 2017 al 1 de agosto de 2017. Estos son los datos que usas para evaluar el rendimiento predictivo del modelo. Se recolectaron en el mes inmediatamente posterior al período comprendido por los datos de entrenamiento.
Ejecuta la consulta ML.EVALUATE
Para ejecutar la consulta ML.EVALUATE que evalúa el modelo, sigue estos pasos:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.sample_model`, ( SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801'))
Haz clic en Ejecutar.
Cuando la consulta finalice, haz clic en la pestaña Results (Resultados) debajo del área de texto de la consulta. Los resultados deberían verse de la siguiente manera:
+--------------------+---------------------+--------------------+--------------------+---------------------+----------+ | precision | recall | accuracy | f1_score | log_loss | roc_auc | +--------------------+---------------------+--------------------+--------------------+---------------------+----------+ | 0.4451901565995526 | 0.08879964301651048 | 0.9716829479411401 | 0.1480654761904762 | 0.07921781778780206 | 0.970706 | +--------------------+---------------------+--------------------+--------------------+---------------------+----------+
Debido a que realizaste una regresión logística, los resultados incluyen las siguientes columnas:
precision: métrica para modelos de clasificación. La precisión identifica la frecuencia con la que un modelo predijo de manera correcta la clase positiva.recall: métrica para los modelos de clasificación que responde a la siguiente pregunta: de todas las etiquetas positivas posibles, ¿cuántas identificó correctamente el modelo?accuracy: la precisión es la fracción de las predicciones que un modelo de clasificación acertó.f1_score: una medida de la precisión del modelo. La puntuación f1 es el promedio armónico de la precisión y la recuperación. El mejor valor de una puntuación f1 es 1. El peor valor es 0.log_loss: la función de pérdida utilizada en una regresión logística. Esta es la medida de qué tan lejos están las predicciones del modelo de las etiquetas correctas.roc_auc: el área bajo la curva ROC. Esta es la probabilidad de que un clasificador tenga más certeza de que un ejemplo positivo elegido al azar sea realmente positivo en comparación con que un ejemplo negativo elegido al azar sea positivo. Para obtener más información, consulta Clasificación en el Curso intensivo de aprendizaje automático.
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Usa el modelo para predecir resultados
Ahora que ya evaluaste tu modelo, el siguiente paso es usarlo para predecir un resultado. Usa tu modelo para predecir la cantidad de transacciones realizadas por los visitantes del sitio web de cada país.
SQL
Esta es la consulta usada para predecir el resultado:
#standardSQL SELECT country, SUM(predicted_label) as total_predicted_purchases FROM ML.PREDICT(MODEL `bqml_tutorial.sample_model`, ( SELECT IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(totals.pageviews, 0) AS pageviews, IFNULL(geoNetwork.country, "") AS country FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801')) GROUP BY country ORDER BY total_predicted_purchases DESC LIMIT 10
Detalles de la consulta
La primera declaración SELECT recupera la columna country y suma la columna predicted_label. Esta columna se genera mediante la función ML.PREDICT.
Cuando usas la función ML.PREDICT, el nombre de la columna de salida para el modelo es predicted_<label_column_name>. Para los modelos de regresión lineal, predicted_label es el valor estimado de label. Para los modelos de regresión logística, predicted_label es la etiqueta más probable, que en este caso es 0 o 1.
La función ML.PREDICT se usa para predecir resultados con tu modelo: bqml_tutorial.sample_model.
La declaración SELECT anidada de esta consulta y la cláusula FROM son las mismas que las de la consulta CREATE MODEL.
La cláusula WHERE, _TABLE_SUFFIX BETWEEN '20170701' AND '20170801', limita la cantidad de tablas que analiza la consulta. El período analizado es del 1 de julio de 2017 al 1 de agosto de 2017. Estos son los datos para los que realizas predicciones. Se recolectaron en el mes inmediatamente posterior al período comprendido por los datos de entrenamiento.
Las cláusulas GROUP BY y ORDER BY agrupan los resultados por país y los ordenan por la suma de las compras previstas en orden descendente.
En este caso, la cláusula LIMIT se usa para mostrar solo los 10 primeros resultados.
Ejecuta la consulta ML.PREDICT
Para ejecutar la consulta que usa el modelo a fin de predecir un resultado, haga lo siguiente:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL SELECT country, SUM(predicted_label) as total_predicted_purchases FROM ML.PREDICT(MODEL `bqml_tutorial.sample_model`, ( SELECT IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(totals.pageviews, 0) AS pageviews, IFNULL(geoNetwork.country, "") AS country FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801')) GROUP BY country ORDER BY total_predicted_purchases DESC LIMIT 10
Haz clic en Ejecutar.
Cuando la consulta finalice, haz clic en la pestaña Results (Resultados) debajo del área de texto de la consulta. Los resultados deberían verse así:
+----------------+---------------------------+ | country | total_predicted_purchases | +----------------+---------------------------+ | United States | 209 | | Taiwan | 6 | | Canada | 4 | | Turkey | 2 | | India | 2 | | Japan | 2 | | Indonesia | 1 | | United Kingdom | 1 | | Guyana | 1 | +----------------+---------------------------+
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Prediga compras por usuario
En este ejemplo, tratas de predecir la cantidad de transacciones que realizará cada visitante de un sitio web.
SQL
Esta consulta es idéntica a la consulta anterior, excepto por la cláusula GROUP BY. Aquí la cláusula GROUP BY, GROUP BY fullVisitorId, se usa para agrupar los resultados por ID de visitante.
Para ejecutar la consulta, haz lo siguiente:
En la consola de Google Cloud, haz clic en el botón Redactar consulta nueva.
Ingresa la siguiente consulta de GoogleSQL en el área de texto del Editor de consultas.
#standardSQL SELECT fullVisitorId, SUM(predicted_label) as total_predicted_purchases FROM ML.PREDICT(MODEL `bqml_tutorial.sample_model`, ( SELECT IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(totals.pageviews, 0) AS pageviews, IFNULL(geoNetwork.country, "") AS country, fullVisitorId FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801')) GROUP BY fullVisitorId ORDER BY total_predicted_purchases DESC LIMIT 10
Haz clic en Ejecutar.
Cuando la consulta finalice, haz clic en la pestaña Results (Resultados) debajo del área de texto de la consulta. Los resultados deberían verse así:
+---------------------+---------------------------+ | fullVisitorId | total_predicted_purchases | +---------------------+---------------------------+ | 9417857471295131045 | 4 | | 2158257269735455737 | 3 | | 5073919761051630191 | 3 | | 7104098063250586249 | 2 | | 4668039979320382648 | 2 | | 1280993661204347450 | 2 | | 7701613595320832147 | 2 | | 0376394056092189113 | 2 | | 9097465012770697796 | 2 | | 4419259211147428491 | 2 | +---------------------+---------------------------+
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Limpia
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en esta página.
- Puedes borrar el proyecto que creaste.
- De lo contrario, puedes mantener el proyecto y borrar el conjunto de datos.
Borra tu conjunto de datos
Borrar tu proyecto quita todos sus conjuntos de datos y tablas. Si prefieres volver a usar el proyecto, puedes borrar el conjunto de datos que creaste en este instructivo:
Si es necesario, abre la página de BigQuery en la consola de Google Cloud.
En el panel de navegación, selecciona el conjunto de datos bqml_tutorial que creaste.
Haz clic en Borrar conjunto de datos en el lado derecho de la ventana. Esta acción borra el conjunto de datos, la tabla y todos los datos.

En el cuadro de diálogo Borrar conjunto de datos, ingresa el nombre del conjunto de datos (
bqml_tutorial) y, luego, haz clic en Borrar para confirmar el comando de borrado.
Borra tu proyecto
Para borrar el proyecto, haz lo siguiente:
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que quieres borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrar el proyecto.
Próximos pasos
- Para obtener más información sobre el aprendizaje automático, consulta el Curso intensivo de aprendizaje automático.
- Para obtener una descripción general de BigQuery ML, consulta Introducción a BigQuery ML.
- Para obtener más información sobre la consola de Google Cloud, consulta Usa la consola de Google Cloud.